Redis核心技术与实战【学习笔记】 - 21.Redis实现分布式锁
概述
在《20.Redis原子操作》我们提到了应对并发问题时,除了原子操作,还可以通过加锁的方式,来控制并发写操作对共享数据的修改,从而保证数据的正确性。
但是,Redis 属于分布式系统,当有多个客户端需要争抢锁时,我们必须保证,这把锁不能是某个客户端的本地锁。否则其他客户端是无法访问这把锁的。
Redis 本身可以被多个客户端共享访问,正好就是一个共享存储系统,可以用来保存分布式锁。而且 Redis 的读写性能高,可以对应高并发锁操作的场景。
1.单机上的锁和分布式锁的联系和区别
对于单机上运行的多线程来说,锁本身可以用一个变量表示
- 变量值为 0 时,表示没有线程获取锁。
- 变量值为1 时,表示已经有线程获取到锁了。
一个线程调用加锁操作,其实就是检查锁变量是否为 0。如果是 0,就把锁变量值设置为 1,表示获取到锁,如果不是 0,就返回错误信息,表示加锁失败,已有其他线程获取到锁了。而一个线程释放锁操作,其实就是将锁变量的值置为 0,以便其他线程可以用来获取锁。
用一段伪代码来表示加锁和释放锁的操作,其中 lock 为锁变量。
acquire_lock() {
if lock == 0
lock = 1
return 1
else
return 0
}
release_lock() {
lock = 0
return 1
}
和单机删的锁类似,分布式锁同样可以用一个变量来表示。客户端加锁和释放锁的操作逻辑,也和单机上的加锁和释放锁操作逻辑一致:加锁时同样需要判断锁变量的值,根据锁变量值来判断能否加锁成功;释放时,需要把锁变量值设置为 0,表名客户端不再持有锁。
但是,和线程在单机上操作锁不同的是,在分布式场景下,锁变量需要由一个共享存储系统来维护。只有这样,多个客户端才可以通过访问共享存储系统来访问锁变量。相应的,加锁和释放锁的操作就变成了读取、判断和设置共享存储系统中的锁变量。
这样一来,我们就可以得出实现分布式锁的两个要求:
- 要求一:分布式锁的加锁和释放锁的过程,涉及多个操作。所以,在实现分布式锁时,我们需要保证这些锁操作的原子性。
- 要求第二:更新存储系统保存了锁变量,如果共享存储系统发生故障或宕机,那么客户端也就无法进行锁操作。在实现分布式锁时,我们需要考虑保证共享存储系统的可靠性,进而保证锁的可靠性。
2.基于单个 Redis 节点实现分布式锁
作为分布式锁实现过程中的共享存储系统,Redis 可以使用键值对来保存锁变量,在接收和处理不同客户端发送的加锁和释放锁的操作请求。那么,键值对的键和值具体是怎么定的呢?
加锁过程
如下图所示,Redis 使用键值对保存锁变量,以及两个客户端同时请求加锁的操作过程。
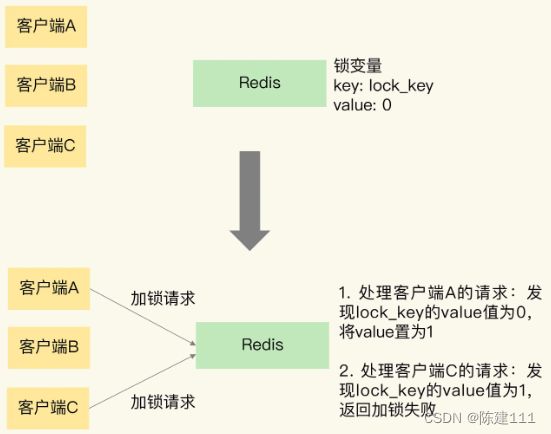
可以看到,Redis 可以使用一个键值对 lock_key:0 来保存锁边量,其中,键是 lock_key,也是锁边变量的名称,锁变量的初始值是 0。
在图中,客户端 A 和 C 同时请求加锁。因为 Redis 使用单线程处理请求,所以,即使客户端 A 和 C 同时把加锁请求发给了 Redis,Redis 也会串行处理他们的请求。
假设 Redis 先处理客户端 A 的请求,读取 lock_key 的值,发现 lock_key 为 0,所以,Redis 就把 lock_key 的 value 值置为 1,表示已经加锁了。紧接着,Redis 处理客户端 C 的请求,此时,Redis 发现 lock_key 的值已经为 1 了,所以就返回加锁失败的信息。
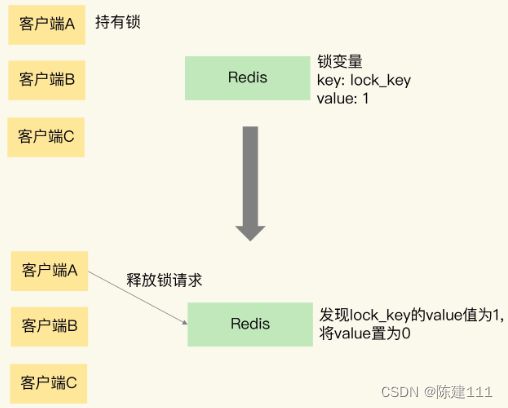
释放锁过程
下图展示的是,客户端 A 请求释放锁的过程。当客户端 A 持有锁时,锁变量 lock_key 的值为 1。客户端 A 执行释放锁操作后,Redis 将 lock_key 的值置为 0,表示已经没有客户端持有锁了。
Redis 分布式锁的原子性保证
《20.Redis原子操作》我们学过了,要想保证操作的原子性,有两种通用的方法,分别是 Redis 单命令操作和使用 Lua 脚本。分布式加锁场景下,如何应用这两个方法呢?
Redis 可以用哪些单命令实现加锁操作
首先是 SETNX 命令,它用于设置键值对的值,这个命令在执行时会判断键值对是否存在,如果不存在,就不做任何设置。
SETNX key value
对于释放锁来说,我们可以在执行完业务逻辑后,使用 DEL 命令删除所变量。不过,你不用担心锁变量被删除后,其他客户端无法请求加锁了。因为 SETNX 命令在执行的时候,如果要设置的键值对不存在,SETNX 会先创建键值对,然后设置它的值。所以释放锁之后,再有客户端请求加锁时,SETNX 命令会创建锁变量的键值对,并设置锁变量的值,完成加锁。
总结来说,可以用 SETNX 和 DEL 命令组合来实现加锁和释放锁操作。
// 加锁
SETNX lock_key 1
// 业务逻辑
DO THINGS
//释放锁
DEL lock_key
不过,用 SETNX 和 DEL 命令组合来实现分布式锁,存在两个潜在风险:
- 第一个风险是,假如某个客户端在执行 SETNX 命令、加锁后,紧接着发生了异常,结果一致没有执行 DEL 命令释放锁。因此,锁就一直被这个客户端持有,其他客户端无法拿到锁,也无法访问共享数据和执行后续操作。
针对这个问题,一个办法是,给锁变量设置一个过期时间。这样一来,即使持有锁的客户端发送了异常,无法主动地释放锁,Redis 也会根据锁变量的过期时间,在锁变量过期后,把它删除。其他客户端在锁变量过期后,就可以重新请求加锁。
- 第二个风险。如果客户端执行了 SETNX 命令加锁后,假设客户端 B 执行了 DEL 命令释放锁,此时 客户端 A 的锁程序就被误释放了。如果客户端 C 正好也在申请加锁,就能获得锁,进而开始操作共享数据。这样一来,客户端 A 和 C 同时在对共享数据进行操作,数据就会被修改错误。
应对第二个风险,需要可以区分来自不同客户端的操作。也就是在加锁操作时,可以让每个客户端给锁变量设置一个唯一值,这里的唯一值可以用来标识当前操作的客户端。在释放锁时,客户端需要判断,当前锁变量的值是否和自已的唯一标识符相等,只有在相等的清理下,才能释放锁。这样,就不会出现误释放的问题了。
在 Redis 中,可以使用 SET 命令,以及 NX 和 EX/PX 的选项,实现加锁操作。
// 加锁,unique_value 作为客户端唯一性的标识
SET lock_key unique_value NX PX 10000
NX:SET 命令的NX选项可以实现类似于 SETNX 的效果,即对于不存在的键值对,它会先创建再设置值,对于已存在的则不做任何操作。
PX 10000:SET 命令的PX选项,可设置键值对的过期时间。另外,key 的存活时间由 seconds 或者 milliseconds 选项值来决定。PX 10000表示 lock_key 会在 10 秒后过期。
因为加锁后,每个客户端都使用了一个标识符,所以在释放锁的过程中,我们需要判断锁变量的值,是否等于执行加锁操作的客户端唯一标识:
// 释放锁 比较unique_value是否相等,避免误释放
if redis.call("get", KEYS[1] == ARGV[1]) then
return redis.call("del", KEYS[1])
else
return 0
end
这是使用 Lua 脚本实现的释放锁操作的伪代码,其中 KEYS[1] 表示 lock_key,ARGV[1] 表示当前客户端的唯一标识,这两个值都是我们在执行 Lua 脚本时作为参数传入的。
最后再执行下面的命令,就可以完成释放锁操作了。
redis-cli --eval lua.script lock_key , unique_value
你可能注意到了,我们在释放锁时,使用了 Lua 脚本,这是因为,释放锁操作的逻辑也包含了读取锁变量、判断值、删除锁变量的多个操作,通过 Redis 的 Lua 脚本,保证了释放锁操作的原子性。
注意的是: 除了上述情况外,还可能会出现的风险:
- 要根据业务的情况,设定好锁的过期时间。锁过期时间设置的太短。线程 A 加锁后,任务还没有执行完,锁变量就过期了。此时,线程 B 通过加锁操作成功获得了锁。 这会导致线程 A 和 线程 B 同时操作了共享数据,导致数据的不一致。
- 避免加锁后业务执行的时间过长。其实和 1 中的风险类似,如果业务执行时间过长,此时锁过期了,也会出现 两个线程同时操作共享数据的问题。
3. 基于 Redis 实现高可靠的分布式锁
要实现高可靠的分布式锁,就不能只依赖单个的命令操作了,我们要按照一定的步骤和规则进行加解锁操作,否则,就可能出现锁无法工作的情况。“一定的步骤和规则”其实就是分布式锁的算法。
为了避免 Redis 实例故障而导致的锁无法工作的问题,Redis 开发者 Antirez 提出了分布式锁算法 Redlock。
Redlock 算法的基本思路,是让客户端和多个独立的 Redis 实例一次请求加锁,如果客户端和半数以上的实例成功的完成加锁操作,那么我们就认为,客户端成功地获得分布式锁了,否则加锁失败。这样一来,及时有单个 Redis 实例发生故障,因为锁变量在其他实例上也有保存,所以,客户端仍然可以正常的进行所操作,锁变量并不会丢失。
看下 Redlock 算法的执行步骤。Redlock 的算法实现需要有 N 个独立的 Redis 实例。接下来,我们可以分成 3 步来完成加锁操作。
-
第一步,客户端获取当前时间。
-
第二步,客户端按顺序依次项 N 个 Redis 实例执行加锁操作。
这里的加锁操作和在单实例上的加锁操作一样,使用了 SET 命令,带上 NX ,EX/PX 选项,以及带上客户端的唯一标识。当然,如果某个 Redis 实例发生故障了,为了保证这种情况下 Redlock 算法能够继续运行,我们需要给加锁设置一个超时时间。如果客户端在和一个 Redis 实例请求加锁时,一直到超时都没有成功,那么此时,客户端会和下一个 Redis 实例继续请求加锁。
加锁操作的超时时间需要远远小于锁的有效时间,一般也就设置几十微妙。 -
第三步,一旦客户端完成了和所有 Redis 实例的加锁,客户端要计算整个加锁操作过程的总耗时。
客户端只有在满足下面的两个条件是,才认为加锁成功。- 条件一:客户端从超过半数(大于等于 N/2 + 1)的 Redis 实例上成功获取到了锁;
- 条件二:客户端获取锁的总耗时没有超过锁的有效时间。
在满足了这两个条件后,我们需要重新计算这把锁的有效时间,计算的结果是锁的最初有效时间减去客户端为获取锁的总耗时。如果锁的超时时间已经来不及完成共享数据的操作了,我们可以释放锁,以免出现还没有完成数据操作,锁就过期了的情况。
当然,如果客户端在和所有实例执行完加锁操作后,没能同时满足这两个条件,那么客户端向所有 Redis 节点发起释放锁的操作。
所以,在实际的业务应用中,如果你想要提升分布式锁的可靠性,就可以通过 Redlock 算法来实现。
小结
分布式锁是由共享存储系统维护的变量,多个客户端可以向共享存储系统发送命令进行加锁或释放锁操作。Redis 作为共享存储系统,可以用来实现分布式锁。
在基于单个 Redis 实例实现分布式锁时,对于加锁操作,我们需要满足三个条件。
- 加锁包括了读取锁变量、检查锁变量和设置锁变量三个操作,但需要已原子操作的方式完成,所以,使用 Set 命令带上 NX 选项来实现加锁。
- 锁变量需要设置过期时间,以免客户端拿到锁后发生异常,导致锁一直无法释放,所以,我们在 SET 命令执行时加上 EX/PX 选项,设置其过期时间。
- 锁变量的值要能区分来不不同客户端的加锁操作,以免在释放锁时,出现误释放操作,所以,我们使用 SET 命令设置锁变量值时,每个客户端设置的值是一个唯一的值,用于标识客户端。
和加锁类型,释放锁也包含了读取锁变量值、判断锁变量值和删除锁变量的三个操作,不过,我们无法使用单个命令来实现,所以采用 Lua 脚本来执行释放锁操作,通过 Redis 原子性的 Lua 脚本,来保证释放锁操作的原子性。
不过,基于单个 Redis 实例实现分布式锁时,会面临实例异常或崩溃的情况,这会导致实例无法提供锁操作,正因为此,Redis 也提供了 Redlock 算法,用来实现基于多个实例的分布式锁。这样一来,锁变量由多个实例维护,及时有实例发生了故障,锁变量仍然是存在的,客户端还是可以完成锁操作。Redlock 算法是实现高可靠分布式锁的一种有效解决方案,你可以在实际应用中把它用起来。
如果为了效率,使用基于单个 Redis 节点的分布式锁即可,此方案缺点是允许锁偶尔失效,优点是简单效率高
如果是为了正确性,业务对于结果要求非常严格,建议使用 Redlock,但缺点是使用比较重,部署成本高
番外
使用单个 Redis 节点(只有一个master)使用分布锁,如果实例宕机,那么无法进行锁操作了。那么采用主从集群模式部署是否可以保证锁的可靠性?
其实也是很难保证的。如果在 master 上加锁成功,此时 master 宕机,由于主从复制是异步的,加锁操作的命令还未同步到 slave,此时主从切换,新 master 节点依旧会丢失锁,对也业务来说相当于锁失效了。
Kaito 大神对分布式锁做了深入的剖析,有兴趣的可以看下《深度剖析:Redis分布式锁到底安全吗?看完这篇文章彻底懂了!》。