如何提高SSD内部的并行性:增加带宽?提供多种路径?设计新架构?

00 简介
本次分享的四篇文章分别为:
-
Networked SSD: Flash Memory Interconnection Network for High-Bandwidth SSD. (MICRO 22)
-
Venice: Improving Solid-State Drive Parallelism at Low Cost via Conflict-Free Accesss. (ISCA 23)
-
Decoupled SSD: Rethinking SSD Architecture through Network-based Flash Controllers. (ISCA 23)
-
MQSim: A Framework for Enabling Realistic Studies of Modern Multi-Queue SSD Devices. (FAST 18)
随着现代数据密集型应用的日益增长,对固态硬盘(SSD, solid-state drive)性能和容量的需求不断提高。而SSD控制器和存储芯片(如2D/3D NAND闪存芯片)之间的通信成为许多应用程序的关键性能瓶颈。
现代SSD采用多通道共享总线架构,在处理多个I/O请求期间经常发生路径冲突,而且I/O请求(I/O requests)过程与垃圾回收(GC, garbage collection)过程由于系统资源的争用会相互干扰,这极大限制了SSD的并行性、降低了SSD的性能。因此,如何处理好各I/O请求过程中的路径冲突问题和I/O请求与垃圾回收的干扰问题是提高SSD并行性和性能的关键。本文从几个不同角度提供了解决方案,并介绍了一个SSD模拟器——MQSim。
01 背景
1.1 I/O请求过程中的路径冲突问题
如图1所示的是经典的SSD架构,其中SSD控制器和NAND闪存芯片之间进行通信时使用多通道共享总线结构。SSD控制器中每个闪存通道控制器(Flash Channel Controller)通过一条闪存通道共享总线连接到多个闪存芯片(Flash Chips),每个闪存芯片只有一个通道(或路径)与某个闪存控制器通信。
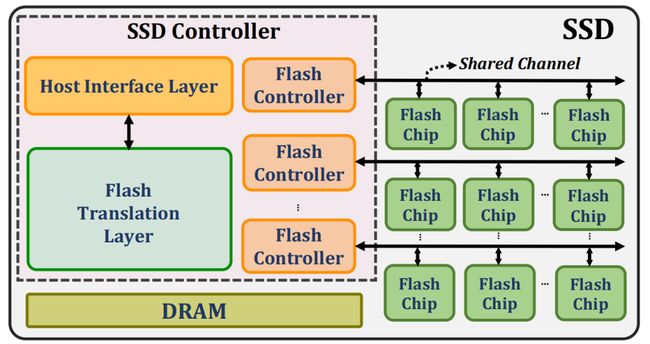
图1 现代SSD架构示意图
由于连接到同一闪存控制器的闪存芯片共享同一闪存共享通道/路径,那么如果该路径被一个 I/O 请求占用,则其它的 I/O 请求需要等待该路径空闲时才能使用。如图2显示了当两个I/O请求分别发生在同一/不同闪存通道的两个闪存芯片时I/O读请求的服务时间线;当两个I/O请求发生在不同的闪存通道(NAND Channel)时,由于不共享通道不会产生路径冲突问题;而在同一闪存通道中发生多个I/O读时,后一个I/O读需要等待前一个完成后才能开始,可见路径共享导致路径冲突问题。
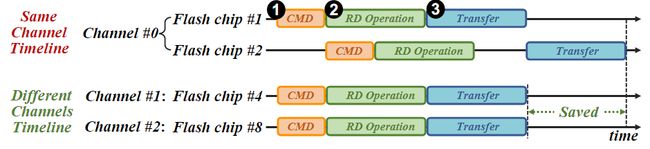
图2 位于不同闪存芯片的两个读请求的服务时间线
1.2 I/O请求与垃圾回收过程中的干扰问题
闪存以页为单位进行读写,以块为单位进行擦除,并且闪存不能覆盖写,必须先擦除再写入,这就导致无效数据块(或垃圾块)的出现,为了提高SSD的性能和寿命,垃圾回收(GC)成为一项重要任务。垃圾回收首先确定需要擦除的数据块,接着将该数据块上的有效数据写入另一空闲闪存块,最后对该数据块进行擦除操作。

图3 执行GC过程中有效数据移动
图3展示了现代SSD系统执行垃圾回收(GC)时内部有效数据的移动过程:①闪存控制器向对应的闪存芯片发送读命令,读取有效的闪存页至ECC中进行解码,完成错误检测(可能纠错);②将读取的数据页缓存到DRAM;③FTL向闪存控制器发出写操作,将数据页写入空闲的目标闪存晶圆;由此可见,垃圾回收GC操作本质上是后端不同闪存芯片之间的数据移动,但是在执行过程中需要占用系统总线、DRAM等前端系统资源,可能对I/O请求产生干扰。于是作者进行实验对这种干扰程度进行量化分析。
图4展示了GC对I/O请求产生干扰的实验数据,由图可知,在触发GC操作后I/O的带宽以及I/O请求对系统总线的占用率急剧下降。
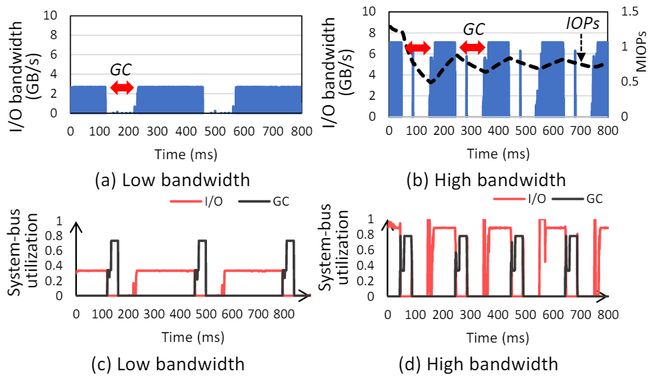
图4 I/O带宽和系统总线利用率
02 设计一:通过增加闪存通道带宽来缓解路径冲突问题
2.1 packetized SSD(pSSD)核心思想
下文内容来源于论文《Networked SSD: Flash Memory Interconnection Network for High-Bandwidth SSD》,发表于MICRO 2022。
这种方法主要通过分组SSD技术实现,将闪存通道的带宽增加到原来的两倍。分组SSD(pSSD,packetized SSD)架构利用分组通信接口来增加闪存通道的有效带宽,可以在不引入额外信号或提高信号速率的情况下,将有效带宽提高约2倍。
pSSD方法在闪存控制器和闪存芯片之间使用数据包进行通信,不采用专用控制信号,需要改变闪存通道控制器和闪存接口来支持分组通信(packetized communication)。如下图,闪存命令控制器保持不变,主要的区别在于引入了分组,在信号到达闪存之前,在接口引入适当的数据包头,这种方法在不利用传统控制信号的情况下,将通信信号(或带宽)的数量有效地增加了约2倍。

图5 传统机制和改进的基于分组方法的接口框图
03 设计二:通过提供路径多样性来解决路径冲突问题
3.1 packetized-network SSD(pnSSD)核心思想
下文内容来源于论文《Networked SSD: Flash Memory Interconnection Network for High-Bandwidth SSD》,发表于MICRO 2022。
pSSD利用packetized interface增加的带宽来增加闪存通道带宽,将闪存通道互连带宽提高了2倍,而pnSSD则是保持闪存通道带宽与基线SSD相同,但将带宽划分一部分创建垂直总线通道(v-channel),使得同一行内的所有闪存芯片相互连接,同一列内的闪存芯片也相互连接,在闪存芯片之间提供直接通信。
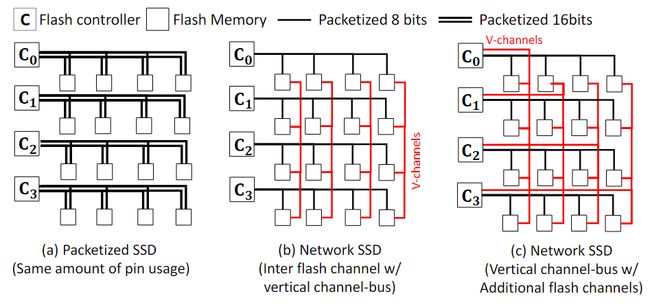
图6 不同闪存互连结构
pnSSD方法基于Omnibus拓扑,提供了与pSSD相同的闪存通道控制器和闪存芯片带宽。主要区别在于带宽是分区的——闪存芯片带宽分为水平和垂直总线通道,控制器带宽也分为单个垂直和单个水平通道。与pSSD相比,pnSSD在路径多样性方面有两个优势——闪存到闪存的直接通信和从闪存到闪存通道控制器的多条路径。
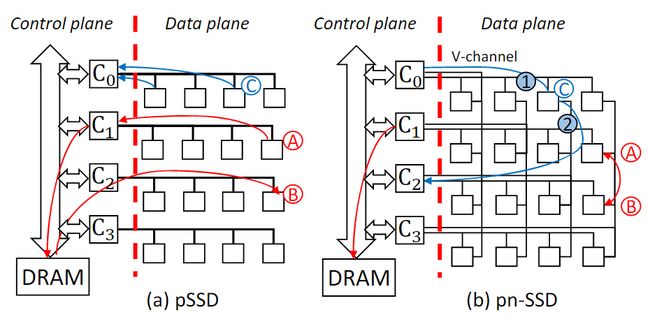
图7 比较pSSD和基于Omnibus拓扑的pnSSD
3.2 Venice核心思想
下文内容来源于论文《Venice: Improving Solid-State Drive Parallelism at Low Cost via Conflict-Free Accesss》,发表于ISCA 23。
该论文首先对之前解决闪存路径冲突问题的方法进行了评估,包括:pSSD、pnSSD、NoSSD等,实验相关数据见下图。
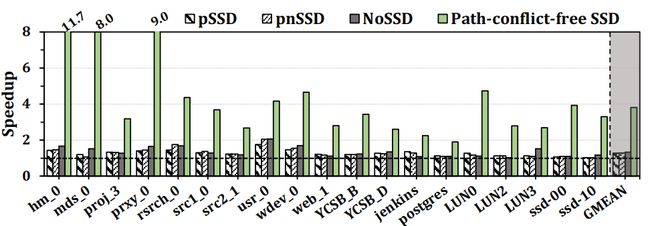
图8 之前的方法与无路径冲突SSD在性能优化的SSD配置上对比
从图中可见,虽然NoSSD 优于pSSD 和pnSSD,但NoSSD 的性能仍然远低于无路径冲突SSD,主要原因是NoSSD不能有效地利用路径的多样性。因此,虽然以前的方法以巨大的成本开销提高了SSD 的性能,但它们都没有有效地解决路径冲突问题,并且它们的性能和无路径冲突的SSD 之间仍存在较大差距。于是该论文提出一种机制——Venice,通过在SSD控制器和闪存芯片之间引入低成本的互连网络,利用路径多样性来解决NAND路径冲突问题。
Venice采用了三个关键技术:
-
在不改变闪存芯片设计的情况下,在每个闪存芯片旁边加一个简单的路由芯片(router chip);
-
路径预留技术(path reservation technique),在开始数据传输之前,为I/O请求保留一条从闪存控制器到目标闪存芯片的路径;
-
通过全自适应路由算法(fully-adaptive routing algorithm)有效利用路径多样性来解决路径冲突问题。
该方法低成本的关键是使路由器与闪存芯片分离,引入闪存节点(由一个闪存芯片和一个单独的路由芯片组成)概念,无需修改闪存芯片内部结构。
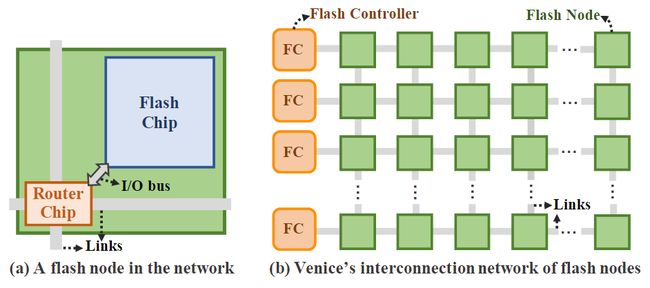
图9 Venice的低成本互连网络
为了确保I/O请求在传输不会在互连网络中发生路径冲突,Venice 在数据开始传输之前为每个I/O请求保留了从闪存控制器到目标闪存芯片之间的无冲突路径。Venice通过发送一个探测包来识别和保留路径。对于给定的 I/O 请求,Venice 检查与目标闪存芯片最接近的闪存控制器是否可用,如果不可用则使用其它最近的空闲闪存控制器。
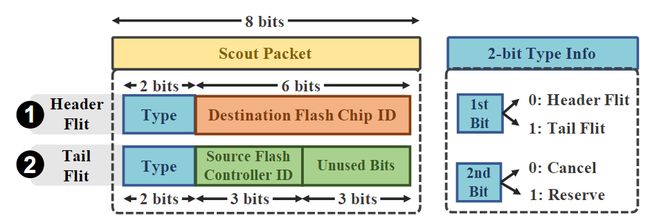
图10 探测包的结构
源闪存控制器发送探测包,以识别和保留到目标芯片的路径,期间使用路由算法(非最小全自适应路由算法)将探测包从源闪存控制器路发送到目标闪存芯片,并保留探测包到达目标节点的互连网络链路,当探测包到达目标闪存芯片时,Venice已经保留了无冲突的前向和后向路径,接着使用反向路径将探测包发送回源闪存控制器。一旦源闪存控制器接收到探测包,它就会使用这条保留的路径为该 I/O请求的数据传输服务。
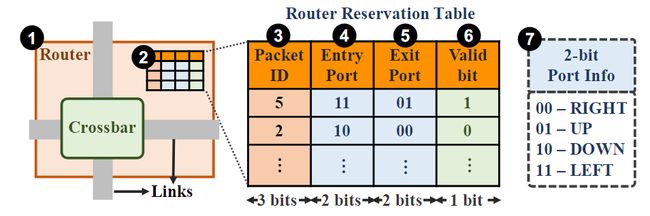
图11 Venice闪存节点互连网络中的路由器结构
下图展示了Venice的非最小全自适应路由算法如何在闪存节点的互连网络中找到一个无冲突的路径的例子。
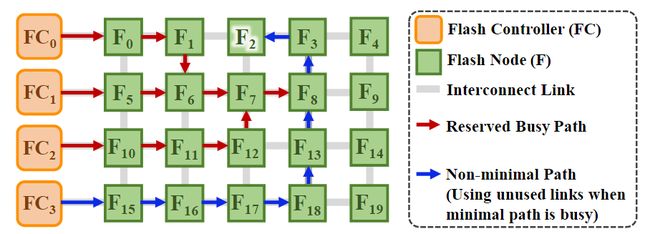
图12 利用非最小全自适应路由算法寻找无冲突路径的示例
如果探测包在路径预留过程中无法在当前路由器上找到空闲链路,该路由器将启用取消模式(cancel mode),这将通过删除路由预留表中对应的条目来取消预留。接着探测包沿着路径回溯到先前遍历的路由器(即上游路由器),根据路由算法的适应性,探测包既可以尝试上游路由中的不同空闲输出链路,也可以进一步回溯(即上游路由的上游路由器)。如果探测包在回溯过程中无法找到空闲的链路,则探测包可以在不保留路径的情况下返回源闪存控制器。
该论文使用最先进的开源 SSD 模拟器 MQSim来评估Venice,对两种 SSD 配置进行建模:(1)基于三星 ZNAND SSD的性能优化配置,以及(2)基于三星 PM9A3 SSD的成本优化配置。下表提供了评估中使用的两种配置和 Venice 设计参数的详细信息。
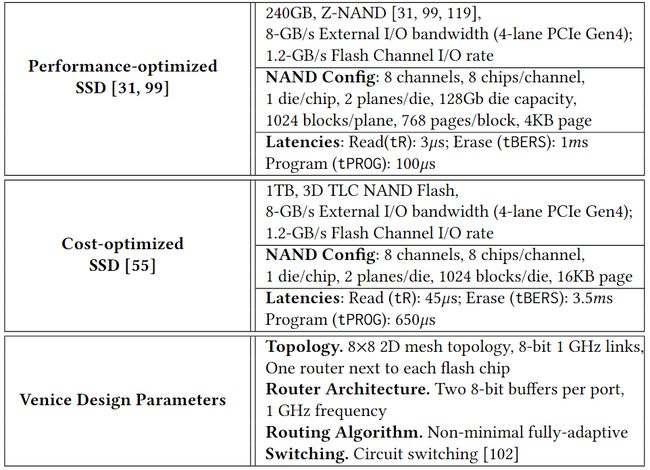
表1 评估配置及Venice参数
该论文将Venice和四种之前的方法(包括Baseline SSD、pSSD、pnSSD、NoSSD)及理想的无路径冲突的SSD(假设每个闪存芯片都有一个直接且独立的通道与S闪存控制器通信)进行比较。
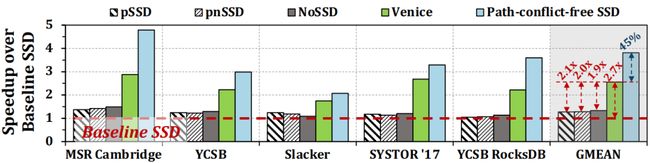
图13 基于性能优化的SSD配置下几种方法对比
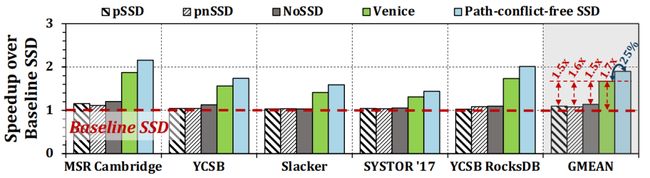
图14 基于成本优化的SSD配置下几种方法对比
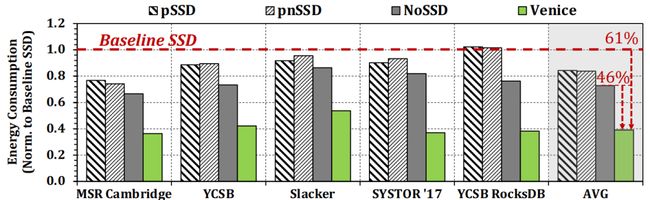
图15 在不同工作负载上能耗对比
实验结果表明,与基线SSD相比,Venice 在多种的工作负载上性能平均提高了 2.65×/1.67 倍,能耗平均提高了61%。此外,可以利用Venice提供的路径多样性来有效地并行调度主机I/O请求和GC相关的请求。
04 设计三:通过一种分离式SSD架构来解决I/O与GC的干扰
4.1 decoupled SSD(dSSD)核心思想
下文内容来源于论文《Decoupled SSD: Rethinking SSD Architecture through Network-based Flash Controllers》,发表于ISCA 23。
增加系统总线带宽可以缓解GC与I/O请求之间的干扰问题,在一定程度上提高了SSD性能,但是它没有从根本上解决GC和I/O请求过程中的资源占用问题。该论文提出了一种分离式的SSD(dSSD, decoupled SSD)架构,将SSD控制器端和闪存部分分离,解决两者在SSD前端系统资源的争用问题。
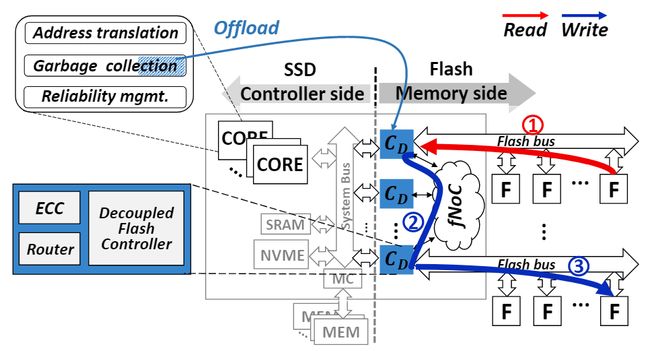
图16 dSSD的架构图
这种分离式SSD架构和原来的主要硬件区别在于分离式闪存控制器(C_D,decoupled flash controller)和闪存控制器片上网络(fNoC, flash controller network-on-chip),其中每个分离式闪存控制器内部都有一个ECC用于检测/纠正数据传输过程中的位错误以及一个片上硬件路由(router)用于控制器之间的通信,而引入fNoC是用于实现位于不同闪存通道上闪存芯片的直接通信。
利用dSSD架构,此时垃圾回收过程中有效数据的移动如图16所示:①从闪存芯片中读取需要的数据页并将其暂存在分离式闪存控制器(C_D)中,进行错误检测/纠正;②通过fNoC将这些数据页发送到目标闪存芯片对应的分离式闪存控制器中;③通过闪存总线通道将数据页写入目标闪存晶圆/块;该过程不需要SSD前端的支持就完成了闪存端内部的数据移动。
该论文使用独立模式下的Simple-SSD模拟器,利用Booksim互连模拟器来模拟fNoC。该论文假设SSD已经被充分使用,模拟器中已触发垃圾回收,I/O请求充分利用了SSD内部带宽的情况下,比较不同架构配置(见下表)下执行GC时的性能:只提高系统总线带宽(BW)、基础分离式SSD架构(dSSD)、在闪存控制器之间采用专用总线不采用片上网络的分离式架构(dSSD_b)和采用片上网络的完整的分离式架构(dSSD_f)。

表2 实验中不同架构配置
该论文的实验基于多种合成和真实的I/O负载,这里只展示部分实验结果,实验结果表明,分离式SSD将I/O 带宽提高42.7%以上,GC性能提升 63.8%,同时平均实现了大约31.4倍的尾部延迟改进。
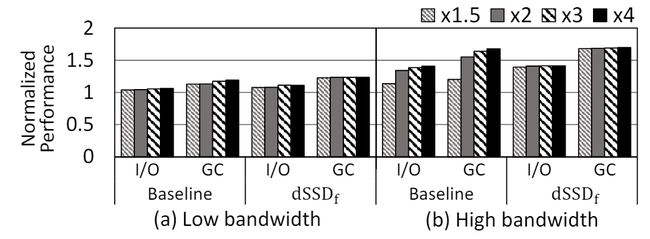
图17 不同前端系统总线带宽配置下I/O和GC的性能情况
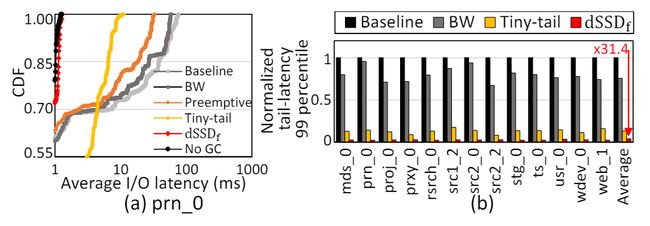
图18 平均尾部延迟改进
05 SSD模拟器——MQSim介绍
内容来源于论文《MQSim: A Framework for Enabling Realistic Studies of Modern Multi-Queue SSD Devices》,发表于FAST 18。
该论文首先揭示导致已有SSD模拟器无法准确模拟真正SSD性能的三个缺陷:无法模拟新协议(例如NVMe)的关键特性;之前的模拟器通常不能准确地描述SSD maintenance algorithms(如垃圾收集)的影响,因为它们不能快速准确地模拟实际SSD中显著改变这些算法行为的稳态条件;之前的模拟器没有完整的模拟I/O请求的端到端延迟,这可能在使用新兴非易失性闪存技术的ssd报告的不一致。这三个缺陷导致采用现有的模拟器得到的结果与SSD的实际性能相差很大。
该论文首先研究了当flow在真实的MQSim上与其他flow并发执行时flow的性能如何变化。

图19 flow在四个真实MQSim上以不同强度并发执行
从图中得出结论:(1)每个flow的相对强度显著影响每个flow的吞吐量;(2)当并发运行flow的相对强度不同时,具有fairness control的MQSim(如SSD-D)的性能与没有fairness control的MQSim不同。因此,为了准确地模拟MQSim的性能,SSD模拟器需要模拟多个队列并使用多个并发运行的flow。
请求延迟是MQ-SSD性能的一个关键因素,它会影响应用程序在I/O请求上停留的时间。从将I/O请求插入主机提交队列到将响应从MQ-SSD设备发送回完成队列,I/O请求的端到端延迟包括七个不同的部分,如图20所示。

图20 NAND闪存MQ-SSD中4 kB读请求的时序图
现有的SSD模拟器只对端到端延迟的通常被认为的主要部分进行模拟。步骤5和6被认为是端到端请求处理中最耗时的部分。然而对于一些I/O请求,FTL请求处理可能并不总是可以忽略不计,有时甚至与闪存读取访问时间相当。例如,如果FTL使用页面级地址映射,那么没有局部性的工作负载会在缓存映射表(CMT, cached mapping table)中出现大量的不命中。如果CMT未命中,则用户读取操作暂停,直到从SSD后端读取映射数据并传输到前端,这可能导致图4a中步骤3的延迟大幅增加,甚至可能比步骤5和6的延迟总和还要长。在MQ-SSD中,随着并发执行的I/O flow数量增加,对CMT的争用也会增加,从而导致CMT失败的数量增加。
因此改该论文引入了一个新的模拟器——MQSim,它可以准确地模拟现代SSD和传统的基于SATA的SSD的性能,MQSim支持现有模拟器没有的的三个重要特征:多队列支持(Multi-Queue Support)、稳态行为的快速建模(Steady-State Behavior)、完整的端到端的请求延迟(Real End-to-End Latency)模拟。

实验验证了MQSim的性能测试结果与四个真实的SSD的实际性能仅相差6%-18%。
06 总结
本文对如何处理好各I/O请求过程中的路径冲突问题解决了三种解决方案:通过增加闪存通道带宽的pSSD、通过在闪存通道控制器和闪存之间提供多种路径的pnSSD、在闪存之间提供互连网络的Venice; 对如何缓解I/O请求与垃圾回收的干扰问题提供了两种解决方案:Venice和分离式架构decoupled SSD,并介绍了一个支持多队列、快速建模稳态行为和能模拟完整的端到端的请求延迟的SSD模拟器——MQSim。
