Opencv学习笔记——特征匹配
文章目录
- Brute-Force蛮力匹配
- 1对1的匹配
- k对最佳匹配
- 随机抽样一致算法(Random sample consensus,RANSAC)
- 单应性矩阵
Brute-Force蛮力匹配
通过SIFT算法可以得到图像关键点,通过比较两张图像的关键点,也就是比较关键点向量之间的差异,Brute-Force蛮力匹配通过比较特征向量,离得最近的特征向量也就是最相似的。默认的是用归一化的欧氏距离。
bf = cv2.BFMatcher(crossCheck=True)
crossCheck为True的意思是当我A到C的距离最近时,C到A的距离也最近,那么我们认为这个特征是匹配的,我的C的是距离B最近的,那么这个时候我们认为A和C是不匹配的
1对1的匹配
import cv2
import numpy as np
import matplotlib.pyplot as plt
#显示函数
def show(name,img):
cv2.imshow(name,img)
cv2.waitKey(0)
cv2.destroyAllWindows()
#读入图像
img1 = cv2.imread('D:/box.png')
img2 = cv2.imread('D:/box_in_scene.png')
#sift算法实例化
sift = cv2.SIFT_create()
#提取特征点和特征向量
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
bf = cv2.BFMatcher(crossCheck=True)
#1对1匹配
matches = bf.match(des1, des2)
#将检测结果从大到小进行排序
matches = sorted(matches, key=lambda x: x.distance)
img3 = cv2.drawMatches(img1, kp1, img2, kp2, matches[:10], None,flags=2)
show('img3',img3)
效果:

k对最佳匹配
k对最佳匹配是指,每一个特征点在另一张图片上都会有k个最匹配的点存在,例如k=2,它会给每个特征点画两根匹配线。通过对比可以过滤掉一部分点。如果需要更快速完成操作,可以尝试使用cv2.FlannBasedMatcher。
代码:
#读入图像
img1 = cv2.imread('D:/box.png')
img2 = cv2.imread('D:/box_in_scene.png')
#sift算法实例化
sift = cv2.SIFT_create()
#提取特征点和特征向量
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
bf = cv2.BFMatcher()
#k对最佳匹配,knnMatch中的k是一共有几组匹配
matches = bf.knnMatch(des1, des2, k=2)
#将检测结果从大到小进行排序
good = []
for m, n in matches:
if m.distance < 0.5 * n.distance:
good.append([m])
img3 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,good,None,flags=2)
show('img3',img3)
效果:
随机抽样一致算法(Random sample consensus,RANSAC)
随机抽样一致算法(RANdom SAmple Consensus,RANSAC)。它采用迭代的方式从一组包含离群的被观测数据中估算出数学模型的参数。 RANSAC是一个非确定性算法,在某种意义上说,它会产生一个在一定概率下合理的结果,而更多次的迭代会使这一概率增加。
选择初始样本点进行拟合,给定一个容忍范围,不断进行迭代
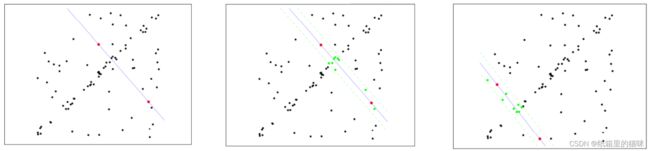
每一次拟合后,容差范围内都有对应的数据点数,找出数据点个数最多的情况,就是最终的拟合结果

单应性矩阵
具体可以看《单应性矩阵、本质矩阵》