Hadoop-HDFS的DataNode介绍及原理
DataNode
DataNode工作机制

1、一个数据块在 DataNode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本
身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2、DataNode 启动后向 NameNode 注册,通过后,周期性(1 小时)的向 NameNode 上
报所有的块信息。
3、心跳是每 3 秒一次,心跳返回结果带有 NameNode 给该 DataNode 的命令如复制块数
据到另一台机器,或删除某个数据块。如果超过 10 分钟+30秒没有收到某个 DataNode 的心跳,则
认为该节点不可用。
4、集群运行中可以安全加入和退出一些机器。
数据完整性
DataNode 节点保证数据完整性的方法。
1、当 DataNode 读取 Block 的时候,它会计算 CheckSum。
2、如果计算后的 CheckSum,与 Block 创建时值不一样,说明 Block 已经损坏。
3、Client 读取其他 DataNode 上的 Block。
4、DataNode 在其文件创建后周期验证 CheckSum。

前两个是常见的奇偶校验,及看1的个数是偶数则校验位为0,个数为奇数则为1;接收到数据后重新计算1的个数并与校验位对比,正确则校验通过;但是这种校验只能校验出单点故障(即一个数据发生变化的情况),对于多点故障则无法正确校验。
Hadoop采用crc校验,能够精确校验出传输数据是否出现变化。
crc(循环冗余检验):发送方机使用某公式计算出被传送数据所含信息的一个值,并将此值附在被传送数据后,接收方计算机则对同一数据进行相同的计算,应该得到相同的结果。如果这两个CRC结果不一致,则说明发送中出现了差错,接收方计算机可要求发送方计算机重新发送该数据。
掉线时限参数设置

<property>
<name>dfs.namenode.heartbeat.recheck-intervalname>
<value>300000value>
property>
<property>
<name>dfs.heartbeat.intervalname>
<value>3value>
property>
需要注意的是 hdfs-site.xml 配置文件中的 heartbeat.recheck.interval 的单位为毫秒,dfs.heartbeat.interval 的单位为秒。
服役新节点
随着业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点。
1、基础环境准备
a.在 hadoop115主机上再克隆一台hadoop116主机
b.修改 IP 地址和主机名称
c.删除原来 HDFS 文件系统留存的文件(/opt/module/hadoop-2.7.2/data和logs),必须保证新节点的data和logs是全新的
d.source 一下配置文件
source /etc/profile
e.启动datanode和nodemanager
hadoop-daemon.sh start datanode
yarn-daemon.sh start nodemanager
查看网页可以知道116已经加入成功了

如果出现 org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server 的问题,查看当前执行start操作的用户是否非bd用户;如果出现失败需要重试的话,需要将data和logs目录删除之后进行重试。
f.检验时候加入成功
在116上传一个liubei文件,然后通过网页查看,出现了116,因此116datanode加入成功

如果数据出现不平衡的情况,可以使用如下命令使集群数据再次平衡
start-balancer.sh
这种方法加入确实是方便,但是有很大的安全隐患,可以对datanode进行白名单限制,只有白名单上的ip才能加入到集群中。
退役旧数据节点
添加白名单
添加到白名单的主机节点,都允许访问 NameNode,不在白名单的主机节点,都会被退出。
配置白名单的具体步骤如下:
1、在 NameNode 的/opt/module/hadoop-2.7.2/etc/hadoop 目录下创建 dfs.hosts 文件
添加如下主机名称(不添加 hadoop116)
hadoop113
hadoop114
hadoop115
2、在 NameNode 的 hdfs-site.xml 配置文件中增加 dfs.hosts 属性
<property>
<name>dfs.hostsname>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hostsvalue>
property>
3、配置文件分发
xsync hdfs-site.xml
4、刷新 NameNode
hdfs dfsadmin -refreshNodes
## 结果如下
Refresh nodes successful
刷新之前

刷新之后

可以看到116已经没有了。
查看刚上传的liubei文件的保存地址如下,发现116上还是存在着这个文件。

5、更新 ResourceManager 节点
yarn rmadmin -refreshNodes
如果数据出现不平衡的情况,可以使用如下命令使集群数据再次平衡
start-balancer.sh
黑名单退役
在黑名单上面的主机都会被强制退出
在配置之前先恢复回原来的状态,即4个DN节点均能正常使用到情况,这里不能通过配置白名单来恢复,因为接下来将会配置黑名单,而黑名单和白名单上不能有相同的地址。
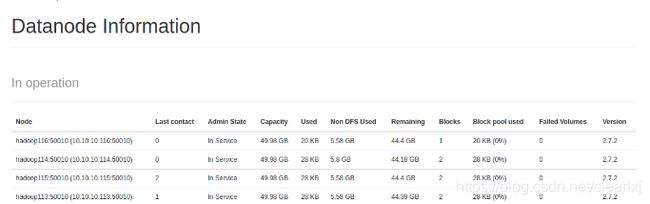
恢复原来的状态需要将hdfs-site.xml中白名单配置删除,并下发到各个服务器,然后执行刷新NameNode的操作。刷新后可以看到116已经进入到了DN管理当中,只是还未启动启动,需要将其启动。

启动之后,查看116已经成功接入集群了。
进行黑名单配置:
1、在 NameNode 的 /opt/module/hadoop-2.7.2/etc/hadoop 目录下创建dfs.hosts.exclude 文件
添加如下主机名称(要退役的节点)
hadoop116
2、在 NameNode 的 hdfs-site.xml 配置文件中增加 dfs.hosts.exclude 属性,并分发到各个服务器
<property>
<name>dfs.hosts.excludename>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts.excludevalue>
property>
3、刷新 NameNode、刷新 ResourceManager
hdfs dfsadmin -refreshNodes
yarn rmadmin -refreshNodes
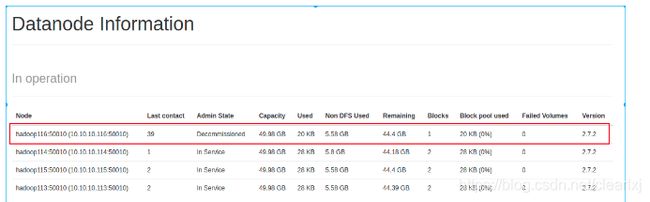
刷新成功之后,查看DN

发现116处于decommission in progress(退役中),此时116正在将自己上面的数据拷贝到别的节点,数据越多退役持续时间越长。

一段时间之后,发现116处于decommissioned (所有块已经复制完成),此时我们去查看liubei文件,可以看到它已经被拷贝到了别的节点。
注意:如果副本数是 3,服役的节点小于等于 3,是不能退役成功的,需要修改副本数后才能退役成功。

4、关闭DataName和NodeManager
hadoop-daemon.sh stop datanode
yarn-daemon.sh stop nodemanager
关闭节点之后116也还会在DN的列表中,需要集群下次启动之后才会将去从列表中去除
如果数据出现不平衡的情况,可以使用如下命令使集群数据再次平衡
start-balancer.sh
这种退役方式温柔,且保证数据能够被其他节点继承,因此退役多考虑这种方式。
DN多目录配置
DataNode 也可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本
修改hdfs-site.xml,并下发到各个服务器,然后进行集群的初始化(先关闭所有进程,再将logs和data删除,最后格式化NameNode(hdfs namenode -format)),最后重新启动集群。
<property>
<name>dfs.datanode.data.dirname>
<value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2value>
property>
进行文件上传,通过到具体目录中查看发现文件只会存在一个文件夹下,也就是说DN的多目录配置是将上传的文件分开存储了,而NN的多目录配置是在各个目录中保存完全相同的数据。