一文读懂ElasticSearch底层原理
一、ES基本概念介绍
1.ES简介
ES是一个分布式、可扩展的、近实时的,有数据搜索、分析与存储的引擎。支持全文搜索、结构化搜索、半结构化搜索、数据分析、地理位置和对象间关联关系搜索等功能。
近实时:非实时,数据不是实时最新的。
其底层基于Lucene,但Lucene比较复杂,面向普通应用开发者而言,易用性不是很好,同时对于目前的主流分布式架构支持也不好,所以就诞生了ES。
ES使用Java编写,它的内部使用Lucene做索引与搜索,隐藏了Lucene的复杂性,面向开发者暴露了即使不同编程语言也基本一致的API和Client,方便大家将搜索功能快速植入到日常应用中。
2.ES使用场景
(1)全文检索
ES的主要应用场景之一,类似于Google搜索,百度搜索和维基百科等,对全文关键字进行检索。
(2)日志分析
海量数据进行近实时的处理,对复杂的日志进行分析,得到我们想要的结果
(3)复杂条件查询
数据量很大,又需要各种条件查询,实时的返回查询数据结果,如管理后台
(4)相似搜索,模糊匹配,地理位置聚合等
3.ES基本概念
(1)文档(Document)
是在ES中可以被索引的基本单位,以JSON标识,类似于关系数据库中的一行
(2)类型(Type)
表示一类相似的文档,作为一个元数据来实现逻辑划分,类似于关系数据库中的表
(3)索引(Index)
索引是具有相似特征的文档的集合,类似于关系数据库中的数据库。
4.ES的节点、分片
默认情况下,每个索引由5个主要分片组成,每份主要分片又有一个副本,一共10个分片。
分片是ES所处理的最小单元,一份分片是Lucene的索引,包含倒排索引的文件目录,分片仅保存了全部数据中的一部分。
副本分片是主分片的拷贝,副本分片作为硬件故障时数据的备份,并为搜索和返回文档等读操作提供服务。副本分片可以提高可用性和性能。
默认的,文档在分片上均匀分布,通过文档ID字符串的散列决定分布到哪个分片,每份分片拥有相同的散列范围,接收新文档的机会均等。一旦目标分片确定,接收请求的节点将文档转发到该分片所在的节点,随后索引操作在所有目标分片的所有副本分片中进行。
写索引只能写在主分片上,然后同步到副本分片,ES写入哪个分片是由文档ID的hash值决定的,公式如下:
shard = hash(routing) % number_of_primary_shards

一次文档写入流程大致如下:
(1)客户端向节点2(协调节点)发送写请求,通过路由计算公式得到分片值为0,则文档应该写到主分片0上
(2)协调节点将请求转发到分片0所在的节点1上,节点1接收请求并写入到磁盘
(3)并发将数据复制到节点2的副本分片0(节点2上的0分片为副本分片)上,通过锁解决数据冲突,一旦所有副本都报告成功,则节点1向协调节点报告成功,协调节点向客户端报告成功。
5.倒排索引
倒排索引是一种类似于HashMap的数据结构,不会直接存储字符串,而是将每个文档拆分为单个搜索词,然后将每个搜索词映射到这些搜索词出现过的文档。
| id | content |
| 1 | elasticsearch in action |
| 2 | redis in action |
如上表标识我们关系型数据库中的两条数据,转变为倒排索引的形式则为(词频主要是查询时打分使用):
| content | id | 词频 |
| elasticsearch | 1 | id1->1次 |
| redis | 2 | id2->1次 |
| in | 1,2 | id1->1次 id2->1次 |
| action | 1,2 | id1->1次 id2->1次 |
二、分析数据
分析是在文档发送并加入倒排索引之前,ES在其主体上进行的操作。在文档被加入索引之前,ES让每个被分析字段经过一系列的处理步骤。
(1)字符过滤:使用字符过滤器转变为字符
(2)文本切分:将文本切分为单个或多个分词
(3)分词过滤:使用分词过滤器转变每个分词
(4)分词索引:将这些分词存储到索引中

三、数据写入
数据的写入最终是要写到ES磁盘上,但是如果每次写数据都直接更新磁盘,磁盘的I/O消耗会非常应用性能,当写数据量大的时候就会造成ES停顿卡死,查询也会受到严重影响,ES就无法成为近实时搜索引擎了。
1.分段存储
索引文件被拆分为多个子文件,每个子文件叫做段。
每一个段本身都是一个倒排索引,并且段具有不变性,一旦索引的数据被写入磁盘,就不可再修改。在底层采用了分段的存储模式,使它在读写时几乎完全避免了锁的出现,大大提升了读写性能。
段被写入到磁盘后会生成一个提交点,提交点是一个用来记录所有提交后 段信息的文件。一个段一旦拥有了提交点,就说明这个段只有读的权限,失去了写的权限。相反,当段在内存中时,就只有写的权限,而不具备读数据的权限,意味着不能被检索。
索引文件分段存储并且不可修改,那么新增、更新和删除如何处理呢?
(1)新增:数据是新的,所以只需要对当前文档新增一个段就可以了
(2)删除:由于不可修改,所以对于删除操作,不会把文档从旧的段中移除而是通过新增一个.del文件,文件中会列出这些被删除文档的段信息。这个被标记删除的文档仍然可以被查询匹配到,但它会在最终结果被返回前从结果集中移除。
(3)更新:不能修改旧的段来反映文档的更新,其实更新相当于是由删除和新增这两个动作组成。会将旧的文档会标记.del文件,然后文档的新版本被索引到一个新的段中。可能两个版本的文档都会被一个查询匹配到,但被删除的那个旧版本文档在结果集返回前就会被移除。
2.刷新(refresh)
每当有新增的数据时,就将其先写入到内存中,在内存和磁盘之间是文件系统缓存(以下操作都是在文件系统缓存中进行),当达到默认的时间(1秒钟)或者内存的数据达到一定量时,会触发一次刷新(refresh),将内存中的数据生成到一个新的段上并缓存到文件缓存系统上,稍后再被刷新到磁盘中并生成提交点。
 -》
-》 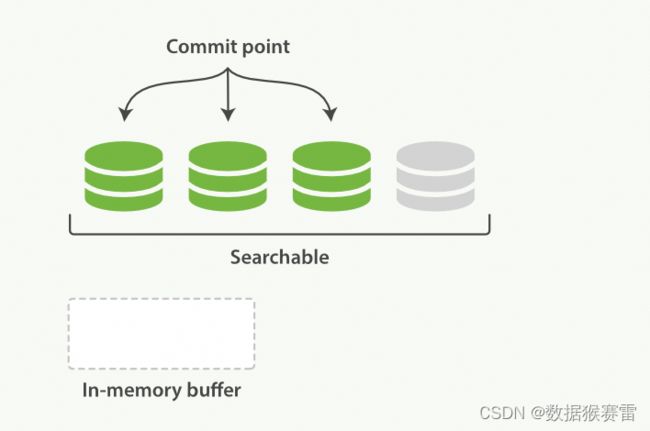
如上,数据会优先写入到内存缓存中,此时新写入的数据还不可以被检索,这也是为什么ES被称为近实时检索的原因,随着数据不断写入,ES会将内存缓存中的数据刷新到一个新的段中,这时新写的数据就可以被检索了。
3.冲刷(flush)
将内存中的分段提交到磁盘的过程叫做冲刷,在数据没有冲刷到磁盘之前,此时新写入的数据还在内存中,如果这时系统断电或者出现宕机异常,如果保证数据不会丢失?
ES增加了一个translog,或者叫事务日志,在每一次对ES进行操作时均进行了日志记录。

数据refresh的时候,内存中的缓存数据被请求,但是事务日志不会。

数据flush到磁盘之后,段被全量提交到磁盘,事务日志被清空。

当满足以下条件之一就会触发刷新操作。
(1)内存缓冲区已满
(2)自上次flush后超过了一定的时间
(3)事务日志达到了一定的阈值
4.段合并(merge)
段合并主要有两个目的:将分段的总数量保持在受控的范围内,保障查询的性能,因为每个搜索请求都必须轮流检查每个段,所以段越多,搜索也就越慢。第二个是真正的删除文档。
合并的最终目的是提升搜索的性能并均衡I/O和CPU计算能力。
合并发生在写入、更新或删除文档的时候,所以合并的越多,更新操作的成本就越高。

四、数据查询
1.索引优化

ES为了能快速找到某个term,先将所有的term排个序,然后根据二分法查找term,时间复杂度为logN,就像通过字典查找一样,这就是term dictionary。现在再看起来,似乎和传统数据库通过B-Tree的方式类似。
但是如果term太多,term dictionary也会很大,放内存不现实,于是有了term index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一棵树。这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。
2.FST压缩
为了让内存中可以存储更多数据,ES在内存中用FST方式压缩term index,FST有两个优点:
(1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间
(2)查询速度快。O(len(str))的查询时间复杂度
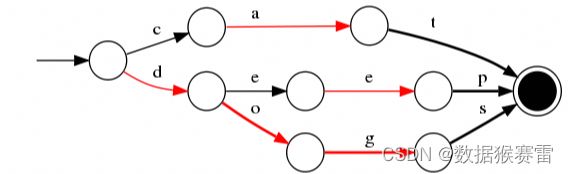
FST压缩率一般在3倍~20倍之间,相对于TreeMap/HashMap的膨胀3倍,内存节省就有9倍到60倍。
3.打分机制
ES使用搜索词条的频率以及它有多常见来影响得分,简单介绍为:一个词条出现在某个文档中的次数越多,就越相关;但是如果该词条出现在不同文档的次数越多,就越不相关。这一点称为TF-IDF(TF是词频,IDF是逆文档频率)。
比如搜索词条“the score”,单词the几乎出现在所有文档中,所有the不重要,如果不适用逆文档频率,那么the关键词将覆盖单词score的频率。
五、其他
1.Master选举
集群中可能会有多个可以成为,此时就要进行master选举,保证只有一个当选master。如果有多个node当选为master,则集群会出现脑裂,脑裂会破坏数据的一致性,导致集群行为不可控,产生各种非预期的影响。
为了避免产生脑裂,ES采用了常见的分布式系统思路,投票机制,保证选举出的master被多数节点认可,以此来保证只有一个master。配置名称:discovery.zen.minimum_master_nodes,为了避免脑裂,这个配置一般配置为sum(node)/2+1,保证超过一半的节点投票了主节点。
2.选举谁
public static int compare(MasterCandidate c1, MasterCandidate c2) {
// we explicitly swap c1 and c2 here. the code expects "better" is lower in a sorted
// list, so if c2 has a higher cluster state version, it needs to come first.
int ret = Long.compare(c2.clusterStateVersion, c1.clusterStateVersion);
if (ret == 0) {
ret = compareNodes(c1.getNode(), c2.getNode());
}
return ret;
}如上面源码所示,先根据节点的clusterStateVersion比较,clusterStateVersion越大,优先级越高。clusterStateVersion相同时,进入compareNodes,其内部按照节点的Id比较(Id为节点第一次启动时随机生成)。
为什么要有排序逻辑,主要是避免每次选举的节点不一致,导致达不到minimum_master_nodes数量,不要出现都想当master而选不出来的情况。
3.怎么保证不脑裂
基本原则还是多数派的策略,如果必须得到多数派的认可才能成为Master,那么显然不可能有两个Master都得到多数派的认可。
上述流程中,master候选人需要等待多数派节点进行join后才能真正成为master,就是为了保证这个master得到了多数派的认可。上述流程在绝大部份场景下没问题,听上去也非常合理,但是却是有bug的。
因为上述流程并没有限制在选举过程中,一个Node只能投一票,那么什么场景下会投两票呢?比如Node_B投Node_A一票,但是Node_A迟迟不成为Master,Node_B等不及了发起了下一轮选主,这时候发现集群里多了个Node_0,Node_0优先级比Node_A还高,那Node_B肯定就改投Node_0了。假设Node_0和Node_A都处在等选票的环节,那显然这时候Node_B其实发挥了两票的作用,而且投给了不同的人。
那么这种问题应该怎么解决呢,比如raft算法中就引入了选举周期(term)的概念,保证了每个选举周期中每个成员只能投一票,如果需要再投就会进入下一个选举周期,term+1。假如最后出现两个节点都认为自己是master,那么肯定有一个term要大于另一个的term,而且因为两个term都收集到了多数派的选票,所以多数节点的term是较大的那个,保证了term小的master不可能commit任何状态变更(commit需要多数派节点先持久化日志成功,由于有term检测,不可能达到多数派持久化条件)。这就保证了集群的状态变更总是一致的。
4.批量操作提升性能
Elasticssearch提供批量操作(插入,更新,删除),批量操作的API是_bulk,此功能非常强大,因为它提供了一种非常有效的机制,可以尽可能快地进行多个操作,并尽可能少地进行网络往返。批量查询使用mget。