C语言排序问题总结一(冒泡排序、插入排序、选择排序)
一、冒泡排序
冒泡排序是一种简单的排序算法,它重复地遍历要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。这个过程会重复进行,直到没有再需要交换,也就是说该数列已经排序完成。
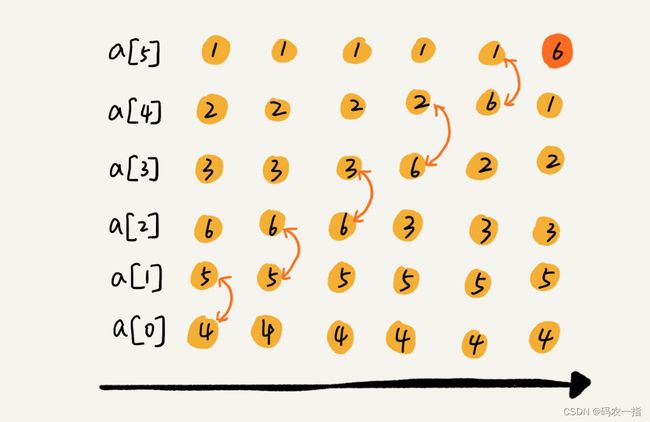
原理阐述:
冒泡排序的基本思想是通过重复地“冒泡”过程,使得较大的元素逐渐移动到数列的一端,较小的元素则移动到另一端。具体步骤如下:
-
从数列的第一轮开始,首先比较相邻的两个元素,如果第一个元素比第二个元素大(假设按升序排序),则交换它们的位置。
-
经过第一轮的比较和交换,最大的元素会被交换到数列的末尾。
-
在随后的每一轮中,由于最大的元素已经被移到数列的最后,所以下一轮会比较剩下的元素,并会找到第二大的元素,将其移动到倒数第二个位置。
-
这个过程会一直重复,每轮都会减少需要比较的元素个数,直到整个数列只有一个元素,也就是完全排序。
-
为了优化冒泡排序,可以使用一个标志位来记录在某一轮是否发生了交换。如果在某一轮中没有元素交换,说明数列已经是有序的,可以提前结束排序。
总的来说,冒泡排序是一种简单的排序算法,它通过重复地比较和交换相邻元素的位置,逐步地将数列中的元素按照预定的顺序(升序或降序)排列好。尽管冒泡排序在某些情况下效率不高,但在某些特定的场景下,例如当排序的元素个数很少时,冒泡排序仍然是一个可行的选择。
代码展示:
#include
void bubblesort(int arr[], int n) {
int i, j, temp;
for (i = 0; i < n - 1; i++) {
for (j = 0; j < n - i - 1; j++) {
if (arr[j] > arr[j + 1])//交换arr[j]和arr[j + 1]
{
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
int main() {
int arr[] = { 23,67,4,36,8,674,56 };
int n = sizeof(arr) / sizeof(arr[0]); //计算数组中元素的个数
bubblesort(arr, n); //调用函数,进行冒泡排序
printf("sorted array:\n"); //输出排序之后的数组
for (int i = 0; i < n; i++) {
printf("%5d", arr[i]);
}printf("\n");
return 0;
} 在这个例子中,bubbleSort函数接受一个整数数组和一个表示数组大小的整数作为参数。然后,它使用两层嵌套循环来比较相邻的元素并在必要时交换它们。这个过程一直持续到整个数组都被排序。在main函数中,我们创建了一个包含未排序元素的数组,调用bubbleSort函数对其进行排序,然后打印出排序后的数组。
二、插入排序
插入排序是一种简单的排序算法,其工作原理是通过构建有序序列,对于未排序的数据,在已排序序列中从后向前扫描,找到相应位置并插入。在实现上,插入排序通常采用in-place排序,即只需用到O(1)的额外空间的排序。这意味着插入排序是一种原地(in-place)排序算法,不需要额外的存储空间来完成排序。
插入排序的基本步骤如下:
- 选择一个元素作为基准点,通常是最左侧的元素。
- 从基准点的右侧开始,逐个将元素与基准点进行比较。
- 如果发现比基准点小的元素,立即将其与基准点之前的元素进行交换,直到该元素到达它应该在的位置。
- 对于基准点右侧已经排好序的元素,重复步骤2和3,直到整个数组排序完成。
插入排序的平均时间复杂度是O(n^2),在最坏情况下也是O(n^2)。这是因为在最坏的情况下,每次都需要将元素与所有已排序的元素进行比较,才能找到正确的插入位置。然而,如果输入数组接近有序状态,插入排序的性能会显著提升,最好情况下的时间复杂度可以达到O(n)。
插入排序是稳定的排序算法,即相等的元素的顺序不会改变。此外,插入排序非常适合于少量数据的排序,因为它实现简单,并且在对小规模数据进行排序时可以快速完成。
需要注意的是,虽然插入排序对于某些情况下的数据有很好的性能,但对于大规模数据来说,它并不是最有效的排序算法,因为它的最坏情况和平均情况时间复杂度都是O(n^2),这在数据量增大时会导致性能问题。因此,在实际应用中,对于大型数据集的排序,通常会采用更高效的排序算法,如快速排序、归并排序或堆排序等。

代码展示:
#include
void insertionsort(int arr[],int n) {
int i, j, key;
for (i = 1; i < n; i++) {
j = i - 1;
key = arr[i];
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j--;
}arr[j + 1] = key;
}
}
int main() {
int arr[] = { 12, 11, 13, 5, 6 };
int n = sizeof(arr) / sizeof(arr[0]);
insertionsort(arr, n);
printf("Sorted array: \n");
for (int i = 0; i < n; ++i)
printf("%d ", arr[i]);
printf("\n");
return 0;
} 在这个例子中,insertionsort函数接受一个整数数组和一个表示数组大小的整数作为参数。然后,它使用两层嵌套循环来将每个元素插入到已排序的部分的正确位置。这个过程一直持续到整个数组都被排序。在main函数中,我们创建了一个包含未排序元素的数组,调用insertionsort函数对其进行排序,然后打印出排序后的数组。
三、选择排序
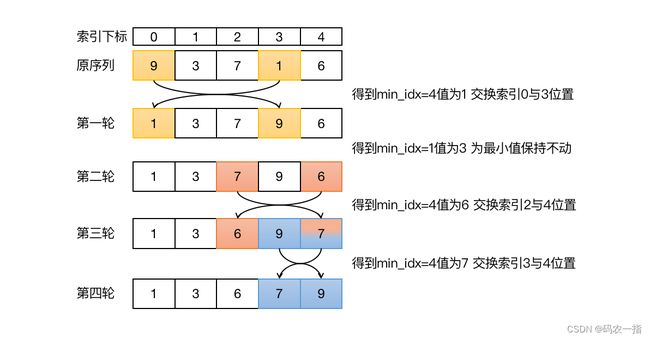
选择排序是一种简单的排序算法,它的基本原理是通过循环选择并交换元素来达到排序的目的。下面详细介绍选择排序的原理和步骤:
-
初始状态:选择排序开始时,数组是未排序的。
-
第一轮选择:从数组的第一个元素开始,遍历数组,找到最小的元素。这个元素可以是数组的第一个元素,也可能是后面的某个元素。找到最小元素后,将它与数组的第一个元素交换位置。
-
后续轮次:在第一轮找最小元素并交换后,第二轮从剩下的元素中找到最小元素,与数组的第二个元素交换。这个过程持续进行,直到第n-1轮,找到最后一个元素的位置。
-
结束条件:当只剩下一个元素,即所有元素都已经排序到位时,选择排序结束。
选择排序的特点是每一趟从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有待排序的数据元素排完。
选择排序是不稳定的排序方法,所谓不稳定是指如果存在两个或更多的相等的元素,选择排序可能会改变它们的原有顺序。
在选择排序中,最好情况是数组已经是部分排序的,最坏情况和平均情况的时间复杂度都是O(n^2),其中n是数组的长度。空间复杂度是O(1),因为除了输入数组本身,选择排序只需要常数级别的额外空间。
代码展示:
#include
void swap(int* a, int* b)//这里用了指针,可以思考一下为什么
{
int temp = *a;
*a = *b;
*b = temp;
}
void selectionsort(int arr[], int n) {
int i, j;
for (i = 0; i < n - 1; i++) {
int min = i;
for (j = i + 1; j < n; j++) {
if (arr[min] > arr[j]) {
min = j;
}
}swap(&arr[min], &arr[i]);
}
}
int main() {
int arr[] = { 23,56,78,5,43,2,257,98 };
int n = sizeof(arr) / sizeof(arr[0]);
selectionsort(arr, n);
printf("Sorted array: \n");
for (int i = 0; i < n; ++i)
printf("%d ", arr[i]);
printf("\n");
return 0;
}