堆(Heap)、栈(Stack)
前言
堆(Heap)、栈(Stack)在不同的场景下,代表不同的含义。
(1)程序内存布局场景下,堆(Heap)、栈(Stack)代表两种内存管理方式;
(2)数据结构场景下,堆(Heap)、栈(Stack)表示两种常用的数据结构;
一、程序内存中的堆(Heap)、栈(Stack)
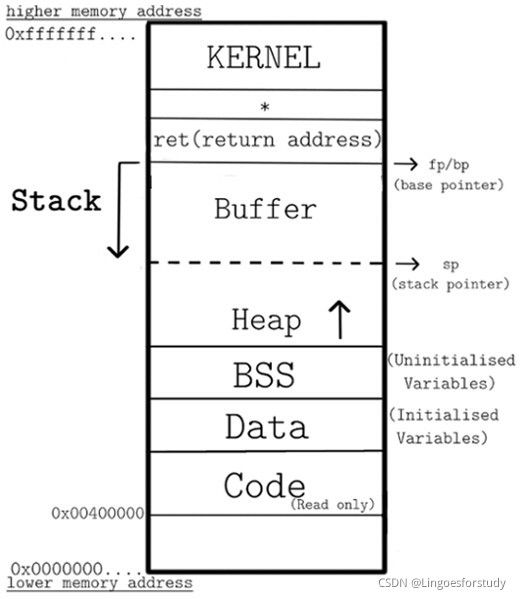
Code、Data、BSS——在编译时确定;保存基本代码和数据的区域。
BSS:保存未初始化的数据;
Data:保存初始化数据
1、堆(Heap)
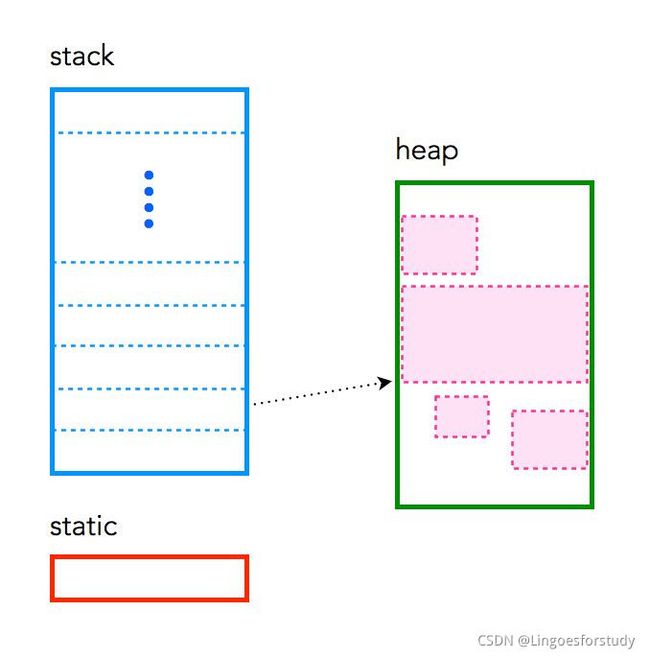
堆(Heap)内存放的数据地址是不连续的;
堆(Heap)中的地址是由低到高的;
堆(Heap)由程序员分配和释放;如果没有被人工释放,程序结束时由OS回收;所以堆heap中存储的数据如果没有被释放,则其生命周期等同于程序的声明周期。
堆(Heap)由程序员使用内存分配函数(malloc 函数)来申请任意多少的内存,使用完之后再由程序员自己负责使用内存释放函数( free 函数)来释放内存。
也就是说,动态内存的整个生存期是由程序员自己决定的。
频繁分配和释放(malloc / free)不同大小的堆Heap空间势必会造成内存空间的不连续,从而造成大量碎片,导致程序效率降低
堆(Heap)上内存法分配过程:
- 操作系统有一个记录空闲内存地址的链表
- 当系统收到程序的申请时会遍历此链表,寻找第一个空间>所申请空间的堆heap节点
- 然后将该节点从空闲链表中删除
- 将该节点的空间分配给程序
注意:
(1)对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小。这样,代码中的delete语句才能正确释放本内存空间;
(2)找到的堆heap节点大小不一定正好=申请的大小,系统会自动地将多余的那部分重新放入空闲链表中。
2、栈(Stack)
栈(Stack)按分配方式分为两种:静态栈和动态栈;
- 静态栈:由编译器分配完成,比如局部变量
- 动态栈:由alloca()函数进行分配,由编译器进行释放。(alloca函数可移植性很差)
栈(Stack)内存中存放着函数的参数值、局部变量等;
栈(Stack)中存储的数据生命周期随着函数的执行完成而结束;
栈(Stack)内存地址是由高到低的;
3、总结
堆Heap与栈Stack是操作系统对进程占用内存空间的两种管理方式,它们的区别主要如下:
(1)管理方式不同:栈Stack由系统自动分配释放,无需人工控制;堆Heap由程序员申请和释放,容易产生内存内存泄露;
(2)空间大小不同:每个进程拥有的栈Stack大小远远小于堆Heap的大小;程序员可申请的堆Heap大小为系统的虚拟内存大小;
(3)地址顺序不同:堆Heap内存地址由低到高,栈Stack内存地址由高到低;
(4)存放内容不同
二、数据结构中的堆(Heap)、栈(Stack)
1、堆(Heap)
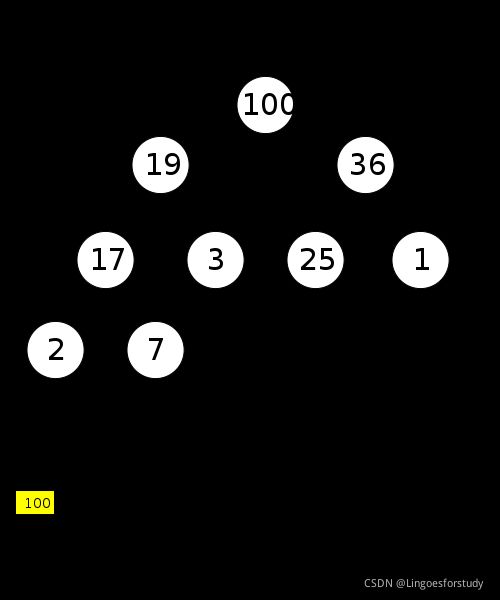
堆Heap是一种特殊的基于树的数据结构,它本质上是一个几乎完整的树,它满足堆属性。其中树是一颗完整的二叉树。
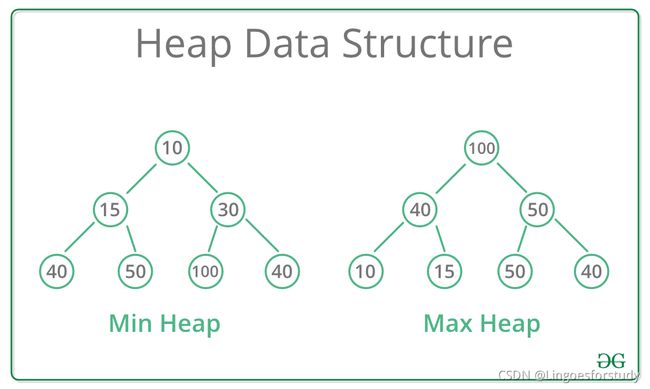
通常,堆Heap可以有两种类型:
- Max-Heap:存放在根结点的键必须是在其所有子节点的键中最大;
- Min-Heap:存放在根结点的键必须是在其所有子节点的键中最小;
注意:对于该二叉树中的所有子树,相同的属性必须递归为真。
堆的常见实现是二叉堆,其中树是二叉树。
2、栈(Stack)
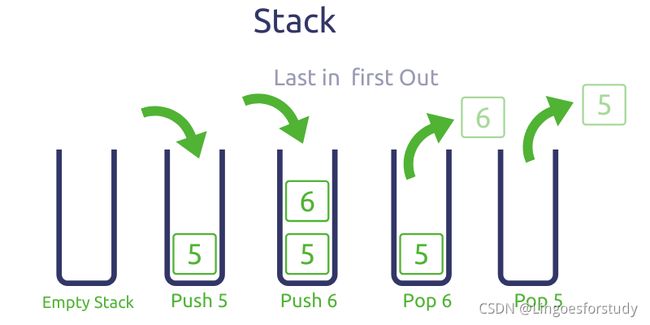
栈(Stack)是一种先进后出的数据结构。
栈(Stack)分为:顺序栈、链式栈。
区别:顺序栈中的元素地址连续,链式栈中的元素地址不连续。
栈是一种线性结构,所以可以使用数组或链表(单向链表、双向链表或循环链表)作为底层数据结构。
使用数组实现的栈叫做顺序栈;使用链表实现的栈叫做链式栈。
