挑战杯 python+opencv+机器学习车牌识别
0 前言
优质竞赛项目系列,今天要分享的是
基于机器学习的车牌识别系统
学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题介绍
1.1 系统简介
车牌识别这个系统,虽然传统,古老,却是包含了所有这四个特侦的一个大数据技术的缩影.
在车牌识别中,你需要处理的数据是图像中海量的像素单元;你处理的数据不再是传统的结构化数据,而是图像这种复杂的数据;如果不能在很短的时间内识别出车牌,那么系统就缺少意义;虽然一副图像中有很多的信息,但可能仅仅只有那一小块的信息(车牌)以及车身的颜色是你关心,而且这些信息都蕴含着巨大的价值。也就是说,车牌识别系统事实上就是现在火热的大数据技术在某个领域的一个聚焦,通过了解车牌识别系统,可以很好的帮助你理解大数据技术的内涵,也能清楚的认识到大数据的价值。
1.2 系统要求
- 它基于openCV这个开源库,这意味着所有它的代码都可以轻易的获取。
- 它能够识别中文,例如车牌为苏EUK722的图片,它可以准确地输出std:string类型的"苏EUK722"的结果。
- 它的识别率较高。目前情况下,字符识别已经可以达到90%以上的精度。
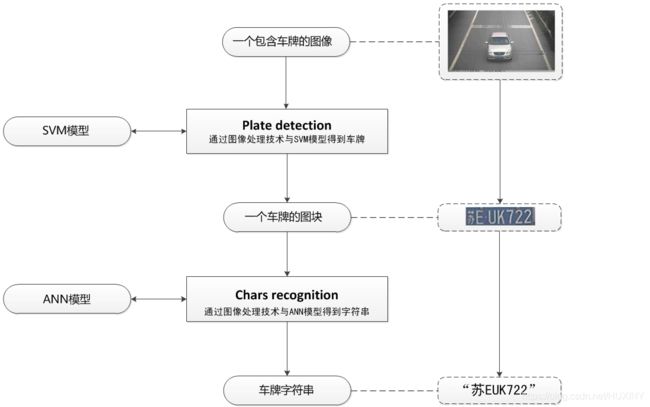
1.3 系统架构
整体包含两个系统:
- 车牌检测
- 车牌字体识别(中文 + 数字 + 英文)
整体架构如下:
2 实现方式
2.1 车牌检测技术
车牌检测(Plate Detection):
对一个包含车牌的图像进行分析,最终截取出只包含车牌的一个图块。这个步骤的主要目的是降低了在车牌识别过程中的计算量。如果直接对原始的图像进行车牌识别,会非常的慢,因此需要检测的过程。在本系统中,我们使用SVM(支持向量机)这个机器学习算法去判别截取的图块是否是真的“车牌”。
车牌检测这里不详细说明, 只贴出opencv图像处理流程, 需要代码的可以留下邮箱

使用到的图像处理算法
- 高斯模糊
- 灰度化处理
- Sobel算子(边缘检测)
- 开操作
- 闭操作
- 仿射变换
- 霍姆线性检测
- 角度矫正
2.2 车牌识别技术
字符识别(Chars Recognition):
有的书上也叫Plate
Recognition,我为了与整个系统的名称做区分,所以改为此名字。这个步骤的主要目的就是从上一个车牌检测步骤中获取到的车牌图像,进行光学字符识别(OCR)这个过程。其中用到的机器学习算法是著名的人工神经网络(ANN)中的多层感知机(MLP)模型。最近一段时间非常火的“深度学习”其实就是多隐层的人工神经网络,与其有非常紧密的联系。通过了解光学字符识别(OCR)这个过程,也可以知晓深度学习所基于的人工神经网路技术的一些内容。
我们这里使用深度学习的方式来对车牌字符进行识别, 为什么不用传统的机器学习进行识别呢, 看图就知道了:

图2 深度学习(右)与PCA技术(左)的对比
可以看出深度学习对于数据的分类能力的优势。
这里博主使用生成对抗网络进行字符识别训练, 效果相当不错, 识别精度达到了98%
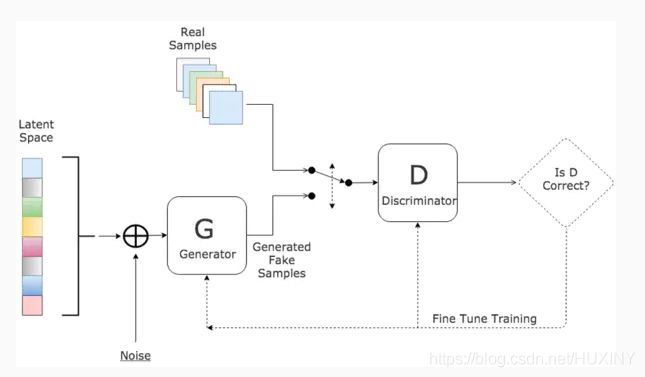
2.3 SVM识别字符
定义
class SVM(StatModel):
def __init__(self, C = 1, gamma = 0.5):
self.model = cv2.ml.SVM_create()
self.model.setGamma(gamma)
self.model.setC(C)
self.model.setKernel(cv2.ml.SVM_RBF)
self.model.setType(cv2.ml.SVM_C_SVC)
#训练svm
def train(self, samples, responses):
self.model.train(samples, cv2.ml.ROW_SAMPLE, responses)
调用方法,喂数据
def train_svm(self):
#识别英文字母和数字
self.model = SVM(C=1, gamma=0.5)
#识别中文
self.modelchinese = SVM(C=1, gamma=0.5)
if os.path.exists("svm.dat"):
self.model.load("svm.dat")
训练,保存模型
else:
chars_train = []
chars_label = []
for root, dirs, files in os.walk("train\\chars2"):
if len(os.path.basename(root)) > 1:
continue
root_int = ord(os.path.basename(root))
for filename in files:
filepath = os.path.join(root,filename)
digit_img = cv2.imread(filepath)
digit_img = cv2.cvtColor(digit_img, cv2.COLOR_BGR2GRAY)
chars_train.append(digit_img)
#chars_label.append(1)
chars_label.append(root_int)
chars_train = list(map(deskew, chars_train))
chars_train = preprocess_hog(chars_train)
#chars_train = chars_train.reshape(-1, 20, 20).astype(np.float32)
chars_label = np.array(chars_label)
print(chars_train.shape)
self.model.train(chars_train, chars_label)
车牌字符数据集如下


这些是字母的训练数据,同样的还有我们车牌的省份简写:


核心代码
predict_result = []
roi = None
card_color = None
for i, color in enumerate(colors):
if color in ("blue", "yello", "green"):
card_img = card_imgs[i]
gray_img = cv2.cvtColor(card_img, cv2.COLOR_BGR2GRAY)
#黄、绿车牌字符比背景暗、与蓝车牌刚好相反,所以黄、绿车牌需要反向
if color == "green" or color == "yello":
gray_img = cv2.bitwise_not(gray_img)
ret, gray_img = cv2.threshold(gray_img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
#查找水平直方图波峰
x_histogram = np.sum(gray_img, axis=1)
x_min = np.min(x_histogram)
x_average = np.sum(x_histogram)/x_histogram.shape[0]
x_threshold = (x_min + x_average)/2
wave_peaks = find_waves(x_threshold, x_histogram)
if len(wave_peaks) == 0:
print("peak less 0:")
continue
#认为水平方向,最大的波峰为车牌区域
wave = max(wave_peaks, key=lambda x:x[1]-x[0])
gray_img = gray_img[wave[0]:wave[1]]
#查找垂直直方图波峰
row_num, col_num= gray_img.shape[:2]
#去掉车牌上下边缘1个像素,避免白边影响阈值判断
gray_img = gray_img[1:row_num-1]
y_histogram = np.sum(gray_img, axis=0)
y_min = np.min(y_histogram)
y_average = np.sum(y_histogram)/y_histogram.shape[0]
y_threshold = (y_min + y_average)/5#U和0要求阈值偏小,否则U和0会被分成两半
wave_peaks = find_waves(y_threshold, y_histogram)
#for wave in wave_peaks:
# cv2.line(card_img, pt1=(wave[0], 5), pt2=(wave[1], 5), color=(0, 0, 255), thickness=2)
#车牌字符数应大于6
if len(wave_peaks) <= 6:
print("peak less 1:", len(wave_peaks))
continue
wave = max(wave_peaks, key=lambda x:x[1]-x[0])
max_wave_dis = wave[1] - wave[0]
#判断是否是左侧车牌边缘
if wave_peaks[0][1] - wave_peaks[0][0] < max_wave_dis/3 and wave_peaks[0][0] == 0:
wave_peaks.pop(0)
#组合分离汉字
cur_dis = 0
for i,wave in enumerate(wave_peaks):
if wave[1] - wave[0] + cur_dis > max_wave_dis * 0.6:
break
else:
cur_dis += wave[1] - wave[0]
if i > 0:
wave = (wave_peaks[0][0], wave_peaks[i][1])
wave_peaks = wave_peaks[i+1:]
wave_peaks.insert(0, wave)
#去除车牌上的分隔点
point = wave_peaks[2]
if point[1] - point[0] < max_wave_dis/3:
point_img = gray_img[:,point[0]:point[1]]
if np.mean(point_img) < 255/5:
wave_peaks.pop(2)
if len(wave_peaks) <= 6:
print("peak less 2:", len(wave_peaks))
continue
part_cards = seperate_card(gray_img, wave_peaks)
for i, part_card in enumerate(part_cards):
#可能是固定车牌的铆钉
if np.mean(part_card) < 255/5:
print("a point")
continue
part_card_old = part_card
w = abs(part_card.shape[1] - SZ)//2
part_card = cv2.copyMakeBorder(part_card, 0, 0, w, w, cv2.BORDER_CONSTANT, value = [0,0,0])
part_card = cv2.resize(part_card, (SZ, SZ), interpolation=cv2.INTER_AREA)
#part_card = deskew(part_card)
part_card = preprocess_hog([part_card])
if i == 0:
resp = self.modelchinese.predict(part_card)
charactor = provinces[int(resp[0]) - PROVINCE_START]
else:
resp = self.model.predict(part_card)
charactor = chr(resp[0])
#判断最后一个数是否是车牌边缘,假设车牌边缘被认为是1
if charactor == "1" and i == len(part_cards)-1:
if part_card_old.shape[0]/part_card_old.shape[1] >= 7:#1太细,认为是边缘
continue
predict_result.append(charactor)
roi = card_img
card_color = color
break
return predict_result, roi, card_color#识别到的字符、定位的车牌图像、车牌颜色
2.4 最终效果
最后算法部分可以和你想要的任何UI配置到一起:
可以这样 :

也可以这样:

甚至更加复杂一点:

最后
更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate