LightGBM特征重要性和可视化
在机器学习方面,模型性能在很大程度上取决于特征选择和对每个特征重要性的理解。LightGBM是微软开发的一种高效的梯度提升框架,由于其处理各种机器学习任务的速度和准确性而广受欢迎。LightGBM以其卓越的速度和内存效率,在众多领域中找到了实际应用。它能够有效地处理大规模数据处理,这使得它在金融,电子商务和医疗保健等行业中不可或缺,这些行业需要快速分析大量数据集。
什么是LightGBM?
LightGBM是Light Gradient Boosting Machine的缩写,是一个高性能、分布式、高效的梯度提升框架,专注于基于树的学习算法。它由Microsoft开发,广泛用于分类和回归任务。LightGBM被设计为内存高效和高度优化,使其成为机器学习从业者的热门选择。
特征重要性
特征重要性就像指南针,引导您穿过数据的迷宫。通过了解哪些因素在引导模型的预测,您可以就优先考虑哪些功能做出明智的决策,增强模型的可解释性,并微调模型以实现最佳性能。LightGBM提供了功能的重要性,使其成为一个更强大的工具。
LightGBM提供了两种主要类型的特征重要性分数:“分裂”和“增益”。
- 分裂功能重要性:此类型测量使用某个特征在模型中的所有树中拆分数据的次数。它有助于确定决策过程中最常涉及的特征。
- 增益功能重要性:另一方面,增益重要性量化了通过使用特定特征进行分割而实现的模型准确性的提高。它提供了一个更丰富的特征重要性视图,因为它也考虑了分割的质量。
选择正确的特征重要性类型取决于您的具体问题和目标。如果您想快速了解哪些功能最常用,“Split” 重要性是合适的。但是,如果您想要更有信息量和更准确的特征重要性度量,建议使用“Gain”重要性,因为它会考虑拆分的质量。
可视化LightGBM特征重要性
首先,确保您安装了LightGBM:
pip install lightgbm
让我们一步一步地分解所提供的代码:
步骤1:导入库
在此步骤中,我们导入代码将使用的必要库:
- 用于构建梯度增强框架的lightgbm
- matplotlib.pyplot用于创建绘图
- sklearn.datasets导入乳腺癌数据集进行分类
- train_test_split、numpy和pandas执行数据预处理
#Importing Necessary Libraries
import pandas as pd
import numpy as np
import lightgbm as lgb
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
步骤2:创建LightGBM数据集
在这里,创建了一个名为train_data的LightGBM数据集。该数据集专门用于训练LightGBM模型。它使用以下输入构建:
- X_train:假设此变量包含训练特征数据(即,独立变量)。
- y_train:假设该变量包含相应的目标标签(即,因变量或要预测的值)。
# Loading the Breast Cancer Dataset
cancer = load_breast_cancer()
# Creating dataframe
df = pd.DataFrame(np.c_[cancer['data'], cancer['target']], columns = np.append(cancer['feature_names'], ['target']))
## Features
X = df.drop(['target'], axis =1)
## Target
y = df['target']
# Splitting the dataset in test and train datasets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 0)
# Creating the dataframe
train_data = lgb.Dataset(X_train, label = y_train)
步骤3:定义模型参数
在这一步中,定义了一个名为params的字典。这个字典保存了各种配置参数,这些参数将用于设置LightGBM模型。以下是每个参数的含义:
- objective 指定模型的目标
- metric 指定模型在训练期间应优化的评估度量
- boosting_type 表示LightGBM中使用的boosting类型。gbdt是Gradient Boosting Decision Trees的缩写,这是LightGBM中可用的一种增强方法。
这些参数定义了如何训练和评估模型。
# Define parameters for the model
params = {
"objective": "binary",
"metric": "binary_logloss",
"boosting_type": "gbdt",
"learning_rate" : 0.1
}
步骤4:训练LightGBM模型
在此步骤中,使用lgb.train函数训练LightGBM模型。
- params 是前面定义的模型配置参数,作为第一个参数传递。
- train_data 是LightGBM训练数据集,作为第二个参数提供。
- num_boost_round=5 指定训练期间的提升轮或迭代的数量。该模型被训练了5轮,每一轮都涉及向集成添加一个决策树。
在此步骤之后,模型变量包含训练的LightGBM模型。
# Train the LightGBM model
model = lgb.train(params, train_data, num_boost_round=5)
输出
[LightGBM] [Info] Number of positive: 249, number of negative: 149
[LightGBM] [Warning] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000248 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 3978
[LightGBM] [Info] Number of data points in the train set: 398, number of used features: 30
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.625628 -> initscore=0.513507
[LightGBM] [Info] Start training from score 0.513507
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
步骤5:绘制特征重要性
最后,代码使用lgb.plot_importance函数和Matplotlib可视化特征重要性。以下是此步骤的每个部分的作用:
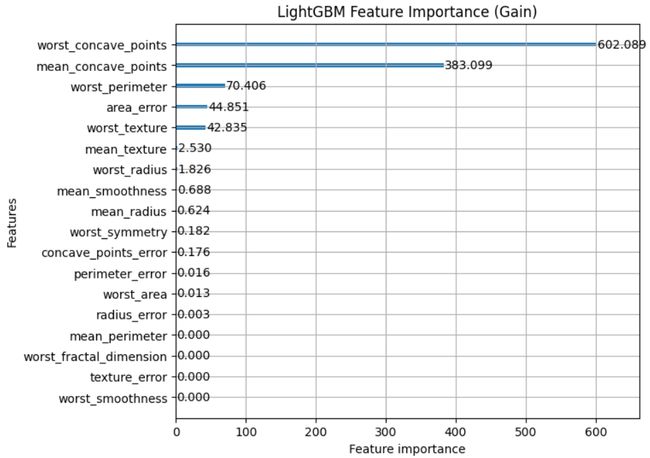
- lgb.plot_importance(model,importance_type=“gain”,figsize=(7,6),title=“LightGBM Feature Importance(Gain)”)基于训练的LightGBM模型生成特征重要性图。它将重要性类型指定为“gain”,该类型基于使用每个特征在决策树中进行分割所获得的准确性增益来计算特征重要性。它还设置图片大小并提供打印标题。
- lgb.plot_importance(model,importance_type=“split”,figsize=(7,6),title=“LightGBM Feature Importance(Split)”)基于"split“度量创建特征重要性图。该指标衡量了在训练过程中使用某个特征来分割决策树中的数据的频率,这有助于评估该特征在决策中的重要性。
使用gain绘制特征重要性
# Plot feature importance using Gain
lgb.plot_importance(model, importance_type="gain", figsize=(7,6), title="LightGBM Feature Importance (Gain)")
plt.show()
输出
使用split绘制特征重要性
# Plot feature importance using Split
lgb.plot_importance(model, importance_type="split", figsize=(7,6), title="LightGBM Feature Importance (Split)")
plt.show()
输出
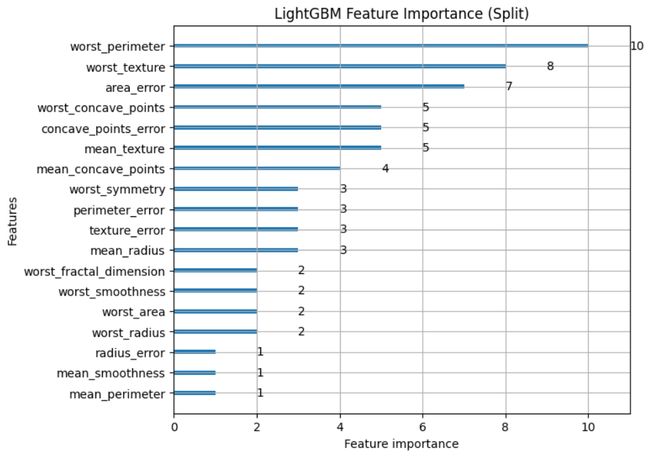
由此产生的图提供了对LightGBM模型预测中最具影响力的特征的见解,有助于特征选择和模型解释。
该代码演示了导入库、准备LightGBM数据集、定义模型参数、训练LightGBM回归模型以及使用“gain”方法可视化特征重要性的完整过程。
使用LightGBM的优势
LightGBM为机器学习任务提供了几个优势:
- 速度:LightGBM非常快,内存效率高,适用于大型数据集。
- 准确性:它经常在各种机器学习竞赛和现实世界的应用中取得最先进的结果。
- 并行和分布式训练:LightGBM支持并行和分布式训练,实现更快的模型开发。
- 正则化:它提供了内置的L1和L2正则化来防止过拟合。
- 特征重要性:全面的特征重要性分析有助于更好地理解模型和选择特征。
此外,LightGBM的高预测精度在欺诈检测、信用评分和推荐系统等应用中备受追捧,这些应用中精度至关重要。在医疗保健领域,LightGBM有助于疾病预测和患者风险分层,同时在情感分析和文本分类等自然语言处理任务方面表现出色。除此之外,它在图像分类,异常检测,甚至优化搜索引擎排名方面都很有价值。凭借其多功能性和速度,LightGBM继续在不同的领域和数据驱动的应用程序中产生重大影响。
结论
LightGBM的特征重要性工具为您的模型行为提供了有价值的见解,并有助于做出明智的决策。对特征重要性的有效可视化和解释有助于模型调试、特征选择和更深入地了解数据。
理解和可视化特征重要性可以大大增强您的机器学习项目,LightGBM的速度和准确性使其成为数据科学工具包中的宝贵工具。但是,必须注意多重共线性,并为您的特定问题选择适当的特征重要性类型,以充分利用LightGBM的潜力。