Vchain:可验证的查询
Vchain:可验证的查询
- 总体概述
- 论文核心内容
- 全文内容概述
-
- 密码学名词解释
- 传统的区块链模型
- Vchain模型
- 从三大方向研读本文
-
- 一、查询的正确性
- 二、查询效率高——Boolean range查询
-
- 在区块中添加额外的ADS
- Ⅰ 时间窗口查询
- 从Boolean类型查询拓展到Range查询
- Ⅱ 订阅查询
- 二、查询效率高——批量验证
- 三、查询成本低
总体概述
本文于2019年7月发表在顶会SIGMOD,题目为《vChain: Enabling Verifiable Boolean Range Queries over Blockchain Databases》,来自香港浸会大学。2020年本团队在SIGMOD再投一篇vchain会议论文,展示了他们的研究进展并确定了vchain的实用性。
本文希望设计出一个能够满足各种类型的查询,且保证查询结果正确、查询效率高的新型框架;行业内的数据库巨头公司也在纷纷致力于开发研究基于区块链的数据库,并设计成比较综合的关键字查询模式。
论文核心内容
现在查询区块链中数据的需求越来越大,论文提出vChain框架,减轻用户查询的存储、计算成本,并保证查询结果的完整性。主要是提出了摘要数据结构AttDigest、块内块间索引和IP树索引结构。
全文内容概述
密码学名词解释
想比较通透的读懂本论文,需要了解一点密码学的基础知识,包括非对称加密技术,双线性配对(Bilinear Pairing),多重集(Multiset),密码学累加器。接下来简单介绍一下。
- 密码学累加器
累加器可利用哈希函数的性质生成一个短的承诺,利用承诺可以验证一些证明。累加器的重要性质是,它可以用来证明集合不相交。Merkle tree就是一个最简单的累加器。累加器分为动态的和静态的:
- 动态累加器:当有元素加入或者移除时,commitment和membership proofs可以进行有效更新(所谓有效更新,是指更新的代价应与已累加的元素数量无关。)
- 静态累加器:当有元素加入或者移除时,commitment和membership proofs需总体重新生成,无法进行有效更新。
另外,vector commitment(VC)具有与累加器完全相同的功能,但是对应的元素是有序的。
-
多重集
多重集是数学中的一个概念,是集合概念的推广。在一个集合中,相同的元素只能出现一次,因此只能显示出有或无的属性。在多重集之中,同一个元素可以出现多次。
举例来说,{1,2,3}是一个集合,而{1,1,1,2,2,3}是一个多重集。其中元素1的重数是3,2的重数是2,3的重数是1。{1,1,1,2,2,3}的元素个数是6。多重集中的元素是没有顺序分别的。 -
双线性配对:Bilinear Pairing
定义:一个双线性映射是由两个向量空间上的元素,生成第三个向量空间上一个元素之函数,并且该函数对每个参数都是线性的。理解:若B:V×W→X是一个双线性映射,则V固定,W可变时,W到X的映射是线性的,W固定,V可变时,V到X的映射也是线性的,也就是说保持双线性映射中的任意一个参数固定,另一个参数对X的映射都是线性的。
双线性配对是多集累加器的基本操作,用于生成一对公私钥对。 -
非对称加密
非对称加密是使用公钥/私钥对中的公钥来加密明文,然后使用对应的私钥来解密密文的过程。 非对称加密也称为公钥加密。 与此相对的,对称加密使用相同一组密钥来加密和解密数据。 -
密码学函数
全文的使用的函数的安全性是由密码学保证的。如下所示:
- KeyGen(1λ) → (sk, pk),产生公钥pk和密钥sk。
- Setup(X, pk) → acc(X),输入多重集X和公钥pk,计算出累加器的值- acc(X)。具体怎么计算的可以暂时放下。
- ProveDisjoint(X1,X2, pk) → π,输入两个多重集(这两个多重集中的元素是没有交集的)和一个公钥,输出证明π。顾名思义,这个函数是用来生成两个多重集没有交集的证明。
- VerifyDisjoint(acc(X1), acc(X2), π, pk) → {0, 1},这个函数用来验证两个多重集X1和X2是否有交集,如果输出为1,表示没有交集。
传统的区块链模型
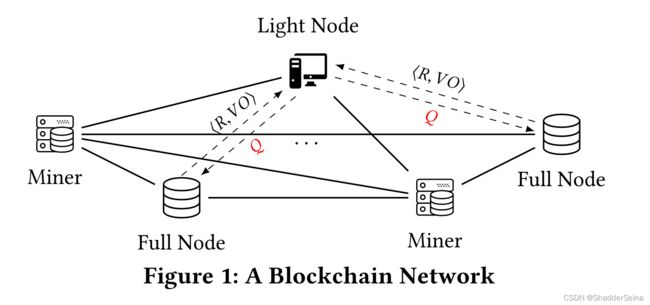
上图表示区块链的网络模型,其中有三种类型的节点:全节点、矿工和轻节点(矿工是一种具有强大算力的全节点)。全节点和矿工保存着区块链的完整数据集;轻节点只保存区块链的头部数据(包含共识证明和加密哈希值),而不存储具体的各种数据记录。轻节点想查询数据时,向全节点发送查询Q,全节点向用户返回R和VO,R表示查询Q的结果,VO(verifiable object)是由服务提供者(Service Provider,SP)构造的,用于让轻节点验证查询结果是否被是否漏查。
基础版本的方案存在三个主要缺点,一是轻节点查询的keys需要在建立Merkle Tree的时候建立好。如果想让它支持任意的属性查询的功能,需要很大的构建成本;二是Merkle Tree不支持属性集合的验证;三是在区块和区块之间,使用Merkle Tree不能做到聚集批量验证,无法做到效率优化。
现行的模型下轻节点想要确保数据库上查询的完整性,就需要完全下载整个网络的交易数据集。巨大的存储、计算、带宽开销使得这个做法不现实。为了让轻节点能够仅仅只做查询就可以返回可信的数据,Vchain采用了验证查询处理来确保结果的完整性。
Vchain模型

整个模型有三种成员:(i)矿工,(ii)服务提供商(SP)和(iii)普通查询用户。矿工和SP维护整个区块链数据库的完整节点。查询用户是一个仅保存块头的轻节点。矿工负责构建共识证明,并向区块链添加新区块。SP为轻量级用户提供查询服务。
存储在区块链中的数据按时间顺序建立对象块序列{ o1,o2,····,on }。每个对象Oi 的格式定义为 ⟨ ti,Vi,Wi ⟩,可以理解成为链上的一笔一笔交易。t 表示时间戳,V 表示一个多维向量,保存一个或多个数字类型的属性,W表示存储多个属性的集合。图示中,q1是时间窗口查询,q2q3是订阅查询。
从三大方向研读本文
研究区块链的可验证查询方向,无非是通过优化验证来保证查询的效率和可靠性。从大的角度来说,大致可三类:要求查询正确、要求查询的效率高、要求查询的开销低。以下为将本文从这三个方向分类后得到的结论:
- 查询正确
- 查询效率高
①支持Boolean range查询(具体分为时间窗口和订阅查询)
Ⅰ时间窗口查询 q:< [ t1,t2 ],[ 1,2 ],a >
Ⅱ订阅查询 q:< —,[ 1,2 ],a∨b >
②支持批量验证 - 查询成本低
一、查询的正确性
- 借助密码学原理保证查询正确(非对称加密、双线性配对、多重集等),使用密码学函数加密。
- 在查询过程中,SP会检查区块链中的ADS,并构建一个验证对象(VO),其中包含结果的验证信息,并将VO与结果一起返回给用户。用户可以根据VO确定查询结果的可靠性和完整性。
- 轻节点用户查询的完整性可以借助存储在块头中的ObjectHash进行身份验证。
轻节点接收到查询结果之后,首先需要非篡改验证:自己根据所接收到的数据构建并计算出一个hash值,并与区块头的Merkle Tree的根节点的hash值对比,如果结果相等表示验证通过。对于与查询条件不匹配的数据对象,轻节点调用函数VerifyDisjoint()来验证查询结果。
为什么轻节点调用了VerifyDisjoint函数就能够验证数据对象确实是不匹配的呢?需要注意,轻节点本地就拥有AttDigesti这个字段,不需要向服务提供者查询,因为他保存在区块头中。AttDigest是由矿工在打包区块的时候调用函数AttDigesti = acc({ })生成的。
从上面我们可以看出,SP都向轻节点发送了哪些数据:(1)匹配查询条件的数据对象(2)不匹配查询条件的证明π值和不匹配的某一个属性W,目的是告诉用户正是这个字段跟数据对象没有交集。
二、查询效率高——Boolean range查询
在区块中添加额外的ADS
Vchain提出在区块头中额外增在一份基于累加器的可验证的数据结构(ADS),这个ADS可以在轻节点用户查询后返回一个VO,供用户认证结果的完整。新的ADS也支持对任意查询属性(包括数字属性和集值属性)进行动态聚合。
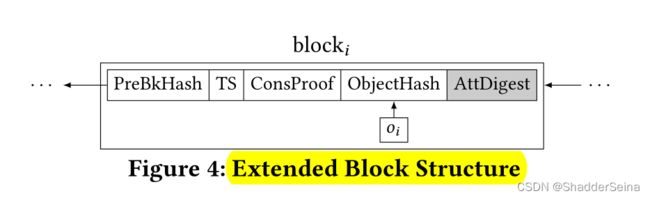
图示中,ConsProof的生成通常基于计算PreBkHash和MerkleRoot,也可以说ConsProof是矿工需要计算的nonce,使得hash(PreBkHash | T S | MerkleRoot | nonce) ≤ Z。Z代表挖矿的难度,一旦矿工找到nonce,则可以广播至全网,发布到区块链上。
在区块头增加字段AttDigest(摘要),有三点用处:第一,能够概括一个数据对象的属性W,证明一个对象是否满足轻节点所提交的查询。如果对象不满足查询条件,只需要返回这个AttDigest字段,而不需要返回整个数据对象给用户。第二,AttDigest字段的大小都是固定的。第三,AttDigest支持不同区块、不同对象的聚合操作,从而实现批量验证。
AttDigest字段的构造方法为:
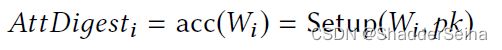
他所支持的密码学函数ProveDisjoint(·)和VerifyDisjoint(·)可以快速构造一个查询不匹配的证明,这样仅仅返回一个AttDigest摘要和一份证明就可以向用户返回查询不匹配结果,并向用户确保这个查询是真实可信的。
Ⅰ 时间窗口查询
- 时间窗口查询
举例q=〈[2018-05, 2018-06], [10, +∞], send:1FFYc ∧ receive:2DAAf〉,表示查询时间范围为[2018-05, 2018-06],数字在[10, +∞]之间,且在W集合中满足谓语表达式send:1FFYc ∧ receive:2DAAf的数据。其中send:1FFYc ∧ receive:2DAAf 字段表示既存在发送地址中有1FFYc字节的也存在接收地址有2DAAf字节的。
从Boolean类型查询拓展到Range查询
保存在区块链中的对象数据表示形式为
- 将数字转化成二进制的形式
- 将一个数字转化成二进制前缀元素,函数表示为trans(·),比如4可以表示为二进制100,所以trans(4) = {1∗, 10∗, 100}. 星号表示通配符。对于数组,比如(4,2)的二进制为(100, 010),前缀转化为:
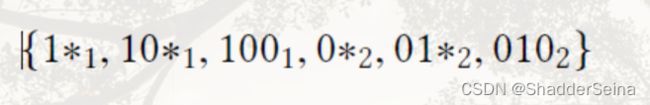
其中下标1和2表示数据维度。
按照上述方法,[0,7]范围内一个维度的二进制前缀树为下图所示:
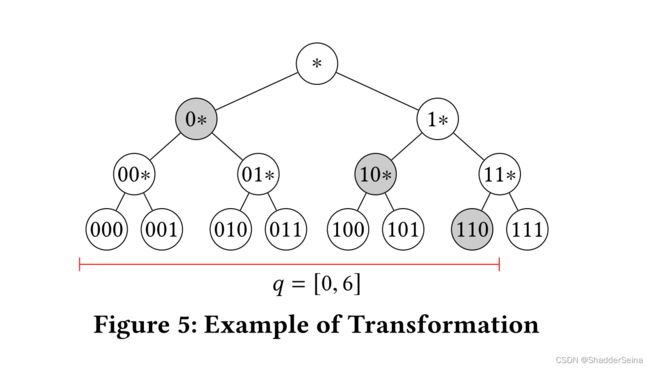
所以对于q查询的数组范围(0,6),可以在这棵树上的叶子节点上红色区间表示出来。然后,我们确定{0∗, 10∗, 110}这三个灰色的点,使之恰好能够覆盖这些叶子节点,这三个灰色的节点就是我们想要的。(0,6)转换成Boolean查询的公式则为:0 ∗ ∨10 ∗ ∨110。
再举个例子,对于数字4,trans(4) = {1∗, 10∗, 100},很容易确定它是在[0, 6]范围内的。这个是一维的,二维的呢?比如Range查询 [(0, 3), (6, 4)],第一维度的区间是【0,6】;第二维度的区间是【3,4】。所以很明显的,对于某一个查询q=(4,2),分别表示查询的第一维度为4,第二维度为2,是不在查询范围[(0, 3), (6, 4)] 内的,因为2不在第二维度【3,4】范围中。
这样子就将数字类型的Range查询拓展到了非数字类型的Boolean查询。它有一个缺点,那就是,只有整数才能被转化。
Ⅱ 订阅查询
-
VChain系统提供了可以订阅的查询的功能。传统的数据库查询为,已经存在数据,我们提交查询,然后接收结果。这里面的可订阅查询服务的执行顺序相反,服务提供者先收集用户注册的查询语句,在未来如果有数据对象匹配这些查询条件,就将该数据对象发送给相应的用户。具体分为如下操作:
(1)服务提供者收集用户的查询语句,建立索引。
(2)当有数据对象到来,就通过索引查找所有满足条件的查询。
(3)将该数据对象发给对应的用户,同时发送那些不匹配的数据对象的不匹配证明。 -
如何建立这样一个索引?
我们知道,查询处理的大部分开销来自于在SP上为不匹配的对象生成证明。但是我们可以通过设计索引节省这个开销。本文设计了反向前缀树(IP树)加速同时处理大量订阅查询。
在设计前缀树组件时,有两个重要的文件:Range条件反转文件(RCIF)和Boolean条件反转文件(BCIF)。RCIF其实就是一个表格,表格有查询的编号qi和其覆盖的类型(full表示全覆盖,partial表示部分覆盖)。我们会事先确定一个节点的数值空间S,比如图中N1的数值空间S是[(0,2),(1,3)],对应左上角的表格树的红色虚线框部分,x数轴对应的第一维的数据范围(在本例中第一维数据是0和1),y轴对应的是第二维的数据范围(本例中是2和3),N1的范围表示成红色虚线框的部分。下图中二维坐标系只是对右侧IP树(Inverted Prefix Tree)中每个节点RCIF确定的一个便于理解的补充。通过这个表格树,我们很清晰得知道查询的数值范围是否覆盖(全覆盖或部分覆盖)了该节点的数值空间。
在使用RCIF确定好是全覆盖q还是部分覆盖q后,BCIF对RCIF中的全覆盖的那些查询的属性集进行扩展(不包括部分覆盖的那些查询)。BCIF中的第一列是查询条件属性集,第二列是其对应的查询。当有新数据对象到来,只需要遍历四分树,查找RCIF表格所有full的查询,并且如果满足BCIF表格中的条件,就表示数据对象满足查询条件。
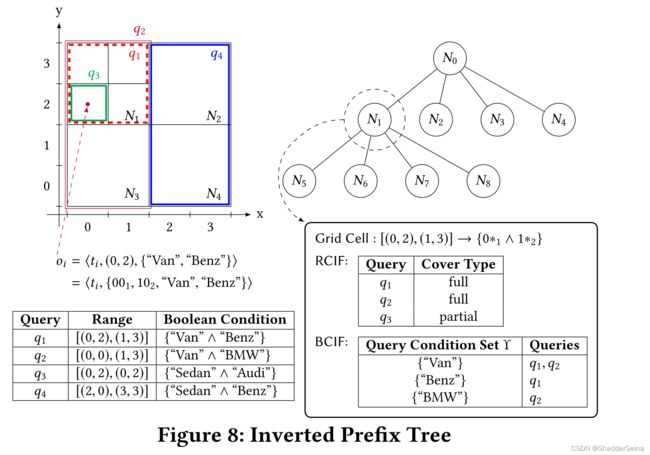
如下是一个例子:

二、查询效率高——批量验证
批量验证可以加快认证速度,本文开发了两个新索引来聚合块内(Intra)、块间(Inter)的数据记录,以实现高效的查询验证。块间采用跳表,块内则生成最大父节点。对于不符合查询条件的记录,则构造不匹配证明Π。
-
块内(Intra)索引:块内索引可以聚合多个对象并提高性能。
总体思想:父节点中的W集合是子节点集合的总和,所以当父节点的W集合不满足查询条件时,所有的子节点都不满足。这样子就可以节省了递归二叉树的时间。具体如下:(1)作者把交集最大的两个叶子节点生成一个父节点,然后一层层往上生长,直到根节点。(2)在非叶子节点的W匹配查询条件,还需要递归直到叶子节点,因为叶子节点才是一份份需要查到的数据。
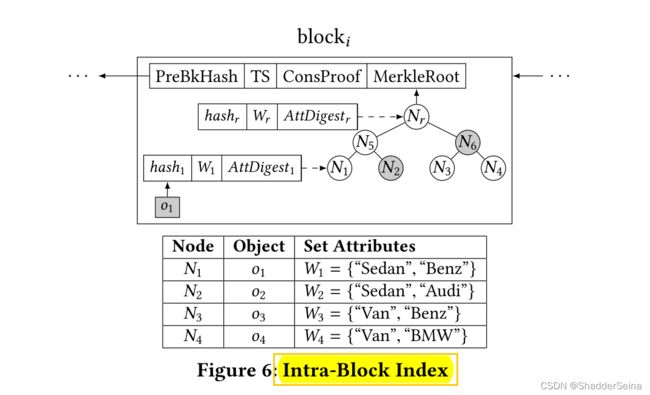
图示中的MerkleRoot是二叉Merkle树的根哈希。每个树节点有三个字段:hash、聚合属性W和聚合属性摘要AttDigest。他们的定义如下所示(其中“ | ”是字符串串联运算符 ):
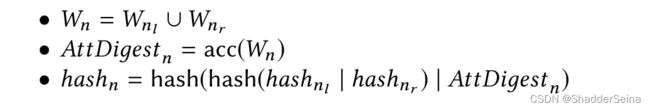
为了提高查询效率,本文采用Jaccard相似性系数最大化每个节点下对象的相似性。上图给的例子,作者将N1和N2聚类到一块,N3和N4聚类一起,然后对聚类中元素两两结合往上构造二叉树。另一方面,树的构建首选可以提高查询效率的平衡树。 -
块间(Inter)索引
块间索引用到了跳表这个数据结构,以指数形式跳过以前的块数。(例如跳过先前的2、4、8块)。跳表数据结构形如下图:

每个跳表维护三个数据:PreSkippedHashLk 、WLk、AttDigestLk。使用额外的字段SkipListRoot,其定义为:
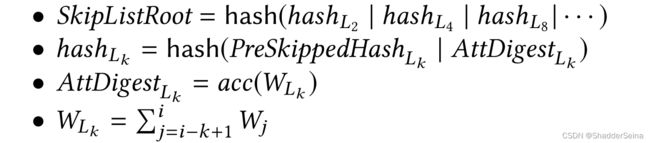
总体思路:WLk存储了前面的所有W字段,跳跃步长为k(k取的是2的n次幂),存在包含关系。所以我们从右边所示的队列L的最下端开始,判断对应的W是否匹配查询条件,如果不匹配,就表示其所跳过的区块都不匹配查询条件,因此就不需要继续往上遍历了。图示中,先检索最长步长为4的块,如果匹配,则说明4之前的属性集合里面有符合的值,再对半跳转到步长为2的块,继续查询。
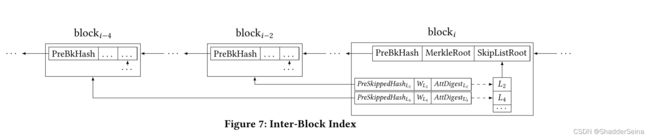
通俗的举例,假如有9个区块,按他2的n次幂跳表,会跳到8。第一种情况是8不匹配,也不能返回VO,因为9还没查,还得往上查完9才能确定。第二种情况是8查到了,就跳到4,4查到了,再跳到2。如果4 匹配,2不匹配,说明这个数据在4号或者3号区块里面,再往上逐个查。知道确定到某个准确的区块位置。
三、查询成本低
- 设计固定大小的AttDigest摘要字段,返回用户的数据更小,开销更低。
- 采用特殊的订阅查询索引(IP树)减小返回不匹配结果验证的成本。