机器学习算法之决策树
原理:基于数据特征进行特征空间的划分,构造树形结构,其中包含两种结点类型,内部结点和叶子结点,内部结点是数据的特征,叶子结点为数据所属的类别。树形结构的实质是if-then规则的集合,不过这个规则集合是互斥且完备的。
步骤:特征选择、决策树生成、决策树剪枝
(1)特征选择:每次选择的特征要具备一定的分类能力,否则没有意义。通常选择的方式有信息增益或信息增益比。
a.信息增益:在知道特征X的情况下,使得类别Y的信息不确定性减少的程度。
十万个为什么之一:什么叫类别不确定性减少的程度?有什么用?
强行解惑:说白了就是通过该特征X的选择,让样本类别尽可能分开了。分开了不就意味着确定了,没分开就是不太确定。
※如果专业一点描述的话,我们首先要引入熵的概念,熵表示了随机变量不确定性的度量。给定一个随机变量X,这个X可能取值是红球、白球······;那么该随机变量的概率分布为![]() ,而该随机变量的熵是
,而该随机变量的熵是![]() n表示随机变量的取值个数,在这里就是2。熵的取值>=0,熵越大不确定性越高。下图1给出了概率分布和熵的关系(我们发现当p为0.5时,熵最大,这里可以这样理解,做一件事情的概率为0.5,也就意味着不确定性太高了,太随机不知道行或者不行,即便是0.51,我都知道可能性有点大;如果概率为0或者1就表示都是确定性的事件咯,那么熵为0):
n表示随机变量的取值个数,在这里就是2。熵的取值>=0,熵越大不确定性越高。下图1给出了概率分布和熵的关系(我们发现当p为0.5时,熵最大,这里可以这样理解,做一件事情的概率为0.5,也就意味着不确定性太高了,太随机不知道行或者不行,即便是0.51,我都知道可能性有点大;如果概率为0或者1就表示都是确定性的事件咯,那么熵为0):
 图1:随机变量分布和熵的关系
图1:随机变量分布和熵的关系
※上面我们有了熵的概念和计算方式,接下来再引入条件熵的概念和计算公式,看官莫急,这都是一些前置知识,了解这些对我们后面对更深层次的概念认知会更加水到渠成。
条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性;具体公式如下(其实就是给定X条件下Y的条件概率分布的熵对X的数学期望):![]()
ps:可能看官会直接 Giao了!!!你在搞什么灰机?熵刚搞明白,你又来个期望。期望就理解成平均就好,只不过这个平均系数是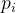 (相加也是1),其实算是加权平均。
(相加也是1),其实算是加权平均。
十万个为什么之二:为什么要求期望?
强行解惑:因为我们给定的随机变量X是一个分布的形式(X取值为红球/白球),至于具体分布的每一项都是以概率的形式存在的,那么显然条件熵也是在加权概率下的熵咯!
OK!到目前我们的前置知识就说完了,两点---熵和条件熵;我们还只给出了信息增益的直观说法,那么具体运算方式的重头戏我们将一一介绍!

以上便是信息增益的定义,H(D)是集合的经验熵,也就是集合D所属各项类别的分布熵,公式(1)给出它的计算示例,H(D|A)表示在特征A的给定条件下,集合D所属各项类别的条件熵;还记得我们上面说的条件熵公式,首先是特征A给定条件下的数据集分布期望(特征A对数据集的划分,每个特征可能有k个取值,比如年龄有幼年、老年那么就把数据集分为老年一批和幼年一批),然后再把期望概率作用在各个特征A下具体的类别熵分布;公式(2)给出示例;特征A给定下的信息增益越大表示分类的不确定性越小,也就越容易分类,其实H(D)对所有的特征来说都是常数,信息增益越大,那么H(D|A)越小,也就意味着A带来的熵越小,就越确定,那自然越容易分类。因此每次我们都计算所有特征对应的信息增益,然后选择信息增益最大的特征来进行决策树生成。
 公式(1)
公式(1)
 公式(2)
公式(2)
给下:
给一个具体的例题巩固一下:





b.信息增益率:由于信息增益将偏好于取值较多的特征,即一般特征取值较多,那么对应的信息增益也越大(特征取值越多,划分的越开)。比如把序号作为特征,那么每个序号可以唯一的划分开一个样本。
概念:特征A对训练数据集D的信息增益与训练数据集D关于特征A的值的熵之比,其中![]() ,n是特征A取值的个数(年龄:青年、老年):
,n是特征A取值的个数(年龄:青年、老年):![]()
(2)决策树生成:ID3/C4.5
ID3:通过选择信息增益最大的特征来对建立子结点【对整个特征选择,再计算各部分的划分,是多叉树】,再对子节点递归进行该操作(去除该特征后剩余的特征);直到所有结点信息增益都很小或者没有结点特征时,决策树建立完毕【每次划分过程中子节点的类别为该结点样本中包含的最大类别】。 注:ID3只有树的建立没有剪枝操作,因此容易过拟合。
例子巩固:

C4.5:通过选择信息增益率最大的特征来对建立子结点,其它和ID3相同(有剪枝操作)
(3)决策树剪枝
决策树剪枝,我们不禁思考的问题是为什么要剪枝?因为在决策树的生成过程中,我们通过对特征的选取尽力去拟合训练数据集,恨不得每个分支都有一个特征去划分数据集,最后把每个样本都单独放到一个叶子结点中(训练集正确率100%),可是我们不是要的训练集精确率呀,而是它在后续数据中的泛化能力,正所谓”没有两片完全一样的树叶“,那么你学习到的规则又怎么去泛化这些数据呢;这就是过拟合现象。通过剪枝将学习到或者划分过细的分支剪掉;把子树变成叶子结点去构造更简单并且在训练集效果也不错的树。
关键点:应该以什么作为剪或者不剪的依据呢,这里采用的是极小化决策树整体的损失函数,设树T的叶子结点个数为|T|,t是树T的叶子结点(每个叶子结点都是由一些样本组成,样本最多类别就是该叶子结点的类别),该叶节点有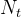 个样本点,其中k类的样本样本点有
个样本点,其中k类的样本样本点有 个,
个,![]() 为叶节点t上经验熵,
为叶节点t上经验熵,![]() 为参数,则决策树的损失函数为:
为参数,则决策树的损失函数为:

李姐一下:其实给出上面的式子,本很简洁很清晰的公式对于初学者来说就是狠狠攻击,什么玩意又经验熵又叶子结点样本个数的,还加个超参数α,看官别急,让我们娓娓道来,让我们直观理解
![]() 的话,第一项是
的话,第一项是![]() ,似乎是对所有叶子上的样本的一个定量计算,一项是该叶子节点的样本个数,一项是该叶子结点的经验熵;熵反应了类别划分的不确定性,如果越小表示划分的越开,也就越好【和损失函数的作用不谋而合】。因为是由
,似乎是对所有叶子上的样本的一个定量计算,一项是该叶子节点的样本个数,一项是该叶子结点的经验熵;熵反应了类别划分的不确定性,如果越小表示划分的越开,也就越好【和损失函数的作用不谋而合】。因为是由 个样本共同产生的结果,直接用乘该熵的值为全部叶子结点样本的熵(这样理解,应该比较合理,仅仅是这样理解)。α|T|是一个正则项,用来控制模型的复杂度,叶子结点越多,树的复杂度就越高,因此加这个正则项的目的是,树尽量简单而且损失也要小!α越大,则|T|越小,相反;则|T|越大;起到权衡树复杂度和损失的作用。
个样本共同产生的结果,直接用乘该熵的值为全部叶子结点样本的熵(这样理解,应该比较合理,仅仅是这样理解)。α|T|是一个正则项,用来控制模型的复杂度,叶子结点越多,树的复杂度就越高,因此加这个正则项的目的是,树尽量简单而且损失也要小!α越大,则|T|越小,相反;则|T|越大;起到权衡树复杂度和损失的作用。
流程:计算每个结点的经验熵,然后从决策树的叶节点开始,递归的向上回缩,如果由叶子结点回缩到其父节点,损失变小,那么就进行剪枝;然后父节点变成叶子结点。


CART:分类回归树
简介:CART是在给定输入随机变量X条件下输出随机变量Y的条件概率分布的学习方法,它的特点是假设每个决策树是由二叉树组成的,内部结点特征的取值为“是”和“否”;即递归的二分每一个特征。
1.回归树的生成

其中输入x是多维特征向量,y为连续数值。

其中I为指示函数,表示属于该集合或不属于,因此最终回归树模型表示了对于不同划分空间输入各维度取值的叠加。
十万个为什么之一:那这样一棵回归树需要怎么构造呢?构造的依据是什么?
强行解惑:我们上面说回归树对应着对输入空间的划分,然后每个划分单元上有一个具体的输出值,而我们的输入其实就是![]() :一个多维的特征向量;输入空间的划分便是对各个输入维度的划分。因此很自然的方式就是对输入中的
:一个多维的特征向量;输入空间的划分便是对各个输入维度的划分。因此很自然的方式就是对输入中的![]() 取值来划分区间。比如大于或者小于!那么现在引申出来的问题就是依次选择哪个维度进行划分和该维度划分的阈值如何确定?确定完了之后,如何评价我们的划分方式效果怎么样(充当损失函数的作用)?经过这么一套组合拳下来,大家可能已经对CART回归树的决策流程有了大致的了解,那下面我们细细品味这道开胃菜!
取值来划分区间。比如大于或者小于!那么现在引申出来的问题就是依次选择哪个维度进行划分和该维度划分的阈值如何确定?确定完了之后,如何评价我们的划分方式效果怎么样(充当损失函数的作用)?经过这么一套组合拳下来,大家可能已经对CART回归树的决策流程有了大致的了解,那下面我们细细品味这道开胃菜!
(1)输入空间划分

以上我们给出了输入空间划分的方式,那么哪种划分方式是最好的呢?这个问题也就是“强行解惑”阶段说的“评价我们的划分方式效果怎么样?”,这里选择的是对输入空间单元的取值和标签y的平方误差;即

具体的:

其中c是该空间单元的取值,该值应该满足使该单元的所有平方误差值最小;这里比较符合直觉的取值为该单元所有训练集标签的平均值。即:

综合上述所说,具体的回归树生成流程为:

2.分类树的生成
原理:利用具体特征取值的基尼指数进行二叉树结点的划分,从而完成分类树的生成。
基尼指数:基尼指数和熵类似,同样反应了某件事件的不确定性,基尼指数越大不确定性越大,因此在选择特征值的基尼指数时,选择较小的进行结点划分。



来个例子巩固一下:

通过上述操作,我们便通过基尼指数,生成一个完整的二叉决策树,但此时的树完全拟合训练数据,容易产生过拟合,我们需要进行剪枝的操作;很自然的想法就是把一些划分太细的分支删除掉,让它从局部子树变成一个叶子结点(类别)。CART剪枝主要分为以下两个过程:
(1)从生成的决策树T,不断从低端向上剪枝,每一次剪枝都生成一个树 (i=1,2,...,n)
(i=1,2,...,n)
(2)对每个子树使用交叉验证法在验证集上测试,从中选择最优子树。
关键点:既然要对树进行剪枝,那么不禁燃气心头的问题是“剪枝的依据是什么?”,说白了就是“什么时候要剪?什么时候不剪?”,其实,剪枝依据还是根据子树的损失函数;具体点来说就是根据衡量下面这个公式:
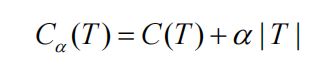
C(T)是任意子树T带来训练数据的预测误差(基尼指数),其中|T|是树T的叶子结点个数,很显然我们希望上述公式尽可能的小,也就是C(T)小一些,|T|也小一点,当然就是树简单点。α>=0,权衡训练数据的拟合程度与模型的复杂度。α较大时,树就偏小,α较小时,树偏大。


通过上面的推导,我们知道了α取值的权衡点,该值限定了剪枝前后,损失相同的临界条件;我们剪枝的目的是,剪枝之后损失变小,我们看g(t)的描述,“该值表示了剪枝后整体损失函数的减少的程度”;是不是有点云里雾里的?既然是减少的程度,那么g(t)肯定是>=0的值了α=g(t),α>=0,由g(t)的分母大于0,那么我们得到C(t)>C(T_t)【C(t)剪枝后的训练损失】;咦~~,不对劲呀,怎么剪枝之后损失变大了,可是这里却说的是损失减少的程度,我怎么看着像是损失增加的程度呢?其实细细品一品,这个损失只是整体损失的一部分(我们还限定了正则项呀,这是树规模的表示,也是一部分损失哦!)。通过g(t)的取值,我们已经明确知道,剪枝前后的两部分整体损失相同(g(t)=α,前面已经分析了结论),这两部分损失都相同了,C(t)又带来的是反方向增益(损失变大了),那可不就是在反方向的增益下,整体损失函数的减少程度(剪枝之后,才有这种损失相同的效果,不剪就没有,其实是树的规模的损失更小,才能均衡到两部分整体损失相同);下一个关键的点是每次选择最小的g(t)进行剪枝,也就是每次选择损失减少程度最小的子树剪枝;说白了就是,带不带你,损失差不多,没减多少;那我还是剪了吧,剪了树更简单。【并且从小的开始剪,还不会落下其它树的情况】
吼吼吼!到了这里整个决策树关键点就介绍完咯!撒花!!!