Netty源码 之 HashedWheelTimer
Netty优化方案
之前总结NioEventLoop以及其他内容时,已经总结了Netty许多优化的设计方案。
1.Selector的优化
(1) 为epoll空转问题提供了解决思路,虽然并没有从根本上解决epoll空转问题,但是使用一个计数器的方式可以减少空转所带来的性能损耗。毕竟epoll空转也是小概率事件
(2) 存储SelectionKey时,优化后的Selector使用的是数组进行存储,而未优化的Selector使用的是Set集合。数组相对Set集合而言,查找的效率更高
2.对象池ObjectPool的引入
目的作用:实现对象的复用,避免对象频繁的创建,销毁。
补充:其实Netty的对象池的实现其实是一种重复造轮子的行为,如果Netty集成了Spring,这个对象池的意义就不大了,因为Spring本身就是原生强大的容器池。
3.Unsafe(JDK原生的Unsafe)的各种操作
使用JDK原生的Unsafe 或 Netty封装的Unsafe,实现对操作系统级别的内存资源的直接操作。
优点:减少数据拷贝和上下文切换,提升了性能
缺点:直接操作操作系统内存,不安全
4.内存池化,实时扩缩容缓冲区:ByteBuf
ByteBuf是对NIO原生ByteBuffer的封装和优化。实现了动态扩容缩容技术,内存池化等一系列优化与封装
还有后续我们要总结的优化方案:
5.HashWheelTimer --->对jdk原生Timer的优化
无论是哪一个Timer其实都是对延迟队列中的定时任务的执行
HashWheelTimer解决的是在海量数据下jdk原生的Timer的时间复杂度(执行时间)大幅度提升的问题,造成性能瓶颈【后续细说】
6.FastThreadLocal --->对jdk原生ThreadLocal的优化
无论是FastThreadLocal还是ThreadLocal,实际上都是一种工具类,这个工具类实现了对线程独享内存中的数据的存或取。
我们把数据存储到对应线程独享的内存中,当需要这块数据的时候,我们从线程对应的内存中取出。这个存储或取出的过程,我们封装了一个类去做:netty使用的是FastThreadLocal,jdk原生的是ThreadLocal。很显然,netty的FastThreadLocal要比jdk原生的ThreadLocal的存或取的效率要快,要高。
HashWheelTimer
HashWheelTimer实际上就是对存储在延迟队列中的定时任务进行执行的操作过程。
HashWheelTimer所做的工作对应到JDK中,等价于JDK的 Timer 或 DelayQueue+ScheduledThreadPool
在对比时,我们重点总结JDK的Timer。
为什么netty需要使用HashWheelTimer,而抛弃jdk原生的Timer?
因为JDK原生的Timer底层使用的是最小堆排序的算法来作为延迟队列的算法,Timer的逻辑存储结构就是一棵小顶堆,物理存储结构是一个数组。当只有少数的定时任务存储到延迟队列时,Timer和HashWheelTimer效率差不多。但是当需要存储几十万个定时任务到延迟队列时,小顶堆的劣势就展现了出来,由于我们需要时刻保证堆顶的元素是优先执行的任务(延迟时间小的任务),当存储几十万个定时任务时,堆是具有非常多层的,每新添加或删除一个定时任务,都需要维护小顶堆的性质,做上滤 或 下滤操作,性能耗费极大。
所以面对海量定时任务下,jdk原生的Timer的时间复杂度极大,时间效率极低,所以netty采用了定制优化的HashWheelTimer。
对于Netty作为双端通信架构而言,定时任务都有哪些?
1.重试:重试操作时,我们需要每隔多久,执行多少次重试
2.心跳:发心跳,多久发一次,发多少次
以上两种其实都是定时任务,都是过了多长时间,或每隔多久去执行一个任务,这个任务就是定时任务。如果说有10万个客户端连接,每一个客户端都实现了重试或心跳机制,那么定时任务就可能高达几十万个。
我们需要把这几十万个定时任务存储到HashWheelTimer所对应的延迟队列中。延迟队列底层物理层面就是使用一个数组来存储,但是延迟队列的逻辑层面的数据结构使用的是一个时间轮的逻辑结构,所依照的算法就是时间轮算法。这种时间轮的算法可以通过精度换取性能,大大的提升了时间效率,降低了时间复杂度。
JDK原生的Timer
总结HashWheelTimer之前,先总结一下Jdk原生的Timer
在java.util包下:
Timer,TimerThread,TaskQueue这三个类是处于同一个类文件中的。

这两句代码执行后,相当于做了三件事:
1.创建了一个定时任务 TimerTask
2.把该定时任务(延迟任务)TimerTask放入到TimerQueue(延迟队列)中
3.TimerThread(定时任务线程)会取出TimerQueue中最近该执行的那一个TimerTask去执行
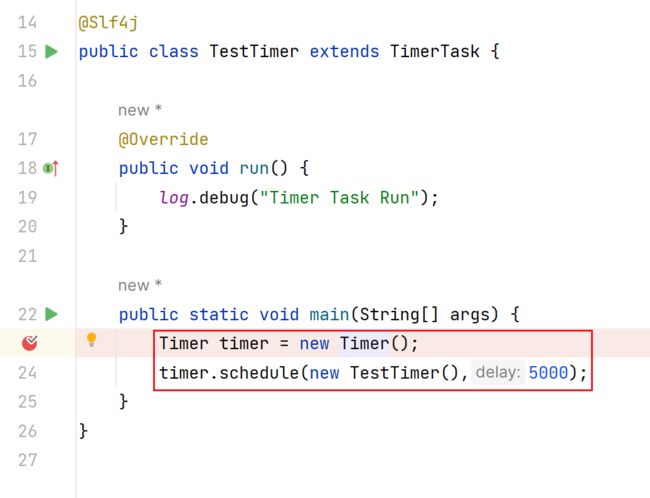
- 编写测试案例,debug JDK原生Timer的源码
package com.messi.netty_source_03.class_10_11;
import lombok.extern.slf4j.Slf4j;
import java.util.Timer;
import java.util.TimerTask;
/**
* @Description TODO
* @Author etcEriksen
* @Date 2024/2/3 8:38
* @Version 1.0
*/
@Slf4j
public class TestTimer extends TimerTask {
@Override
public void run() {
log.debug("Timer Task Run");
}
public static void main(String[] args) {
Timer timer = new Timer();
timer.schedule(new TestTimer(),5000,5000);
}
}
详细剖析一下整个debug源码过程:
1.完成Timer的创建和初始化

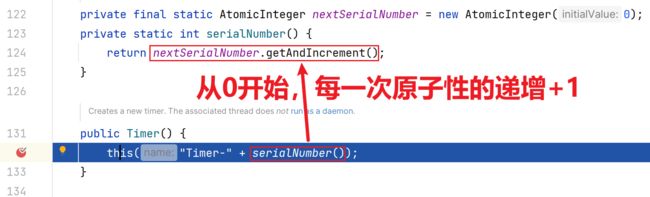



切换到Timer0线程的视角
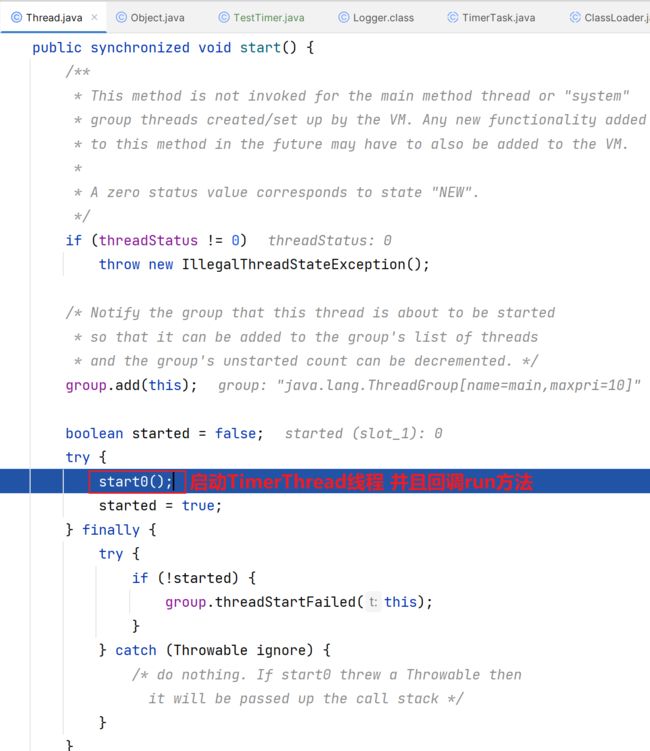
一句start0到底做了什么事情?
实际上就是开启了线程Timer-0,并且执行回调了Timer-0线程的run方法

mainLoop():



3.切换回main主线程


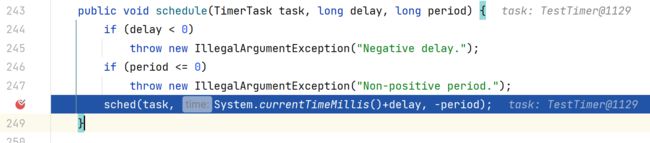

queue.add(task):

fixUp方法:
但是正因为这频繁的维护小顶堆的性质的上滤和下滤操作,当海量定时任务存储到延迟队列时,上滤和下滤操作的时间复杂度变得极高,时间效率极低,所以后续netty才会抛弃Timer,拥抱HashWheelTimer。

queue.notify():
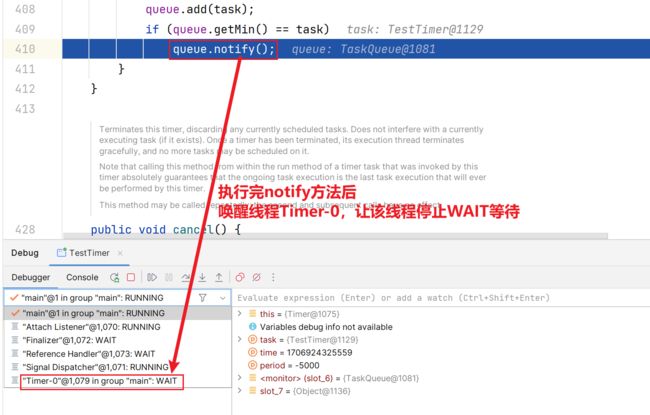

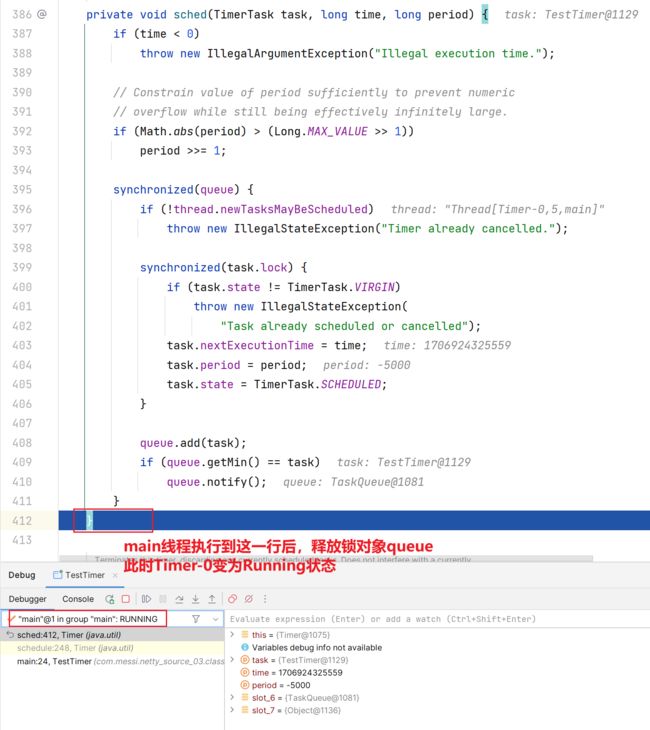
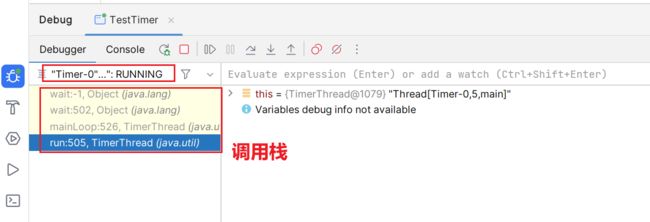
4.切换回Timer-0线程


回调该run方法:

- 二叉树的基础回顾
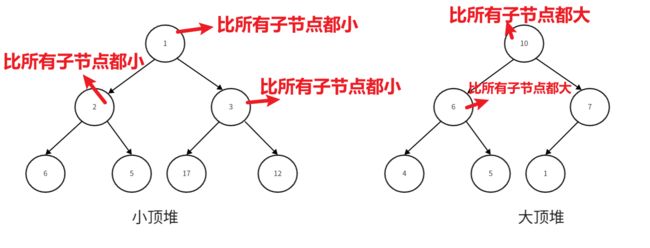
1.大顶堆或小顶堆其实就是一棵完全二叉树的结构
2.完全二叉树与满二叉树:
完全二叉树:上一层没填满节点,则不应该加入到下一层。最后的一层的叶子节点可以不加满,但是应该从左往右依次添加节点。

满二叉树:满二叉树是一棵特殊的完全二叉树,它相比完全二叉树多了一条性质,把最后一层的所有叶子节点都填满!

3.小顶堆和大顶堆
小顶堆:实现最小堆排序算法,根节点是所有节点元素中最小的那一个。并且注意一点:父节点的元素值永远要比所有子节点的元素值要小【递归式】。
小顶堆:实现最大堆排序算法,根节点是所有节点元素中最大的那一个。并且注意一点:父节点的元素值永远要比所有子节点的元素值要大【递归式】。

4.上滤 或 下滤
往大顶堆或小顶堆添加元素时,为维护顶堆的性质,需要使用上滤操作
从大顶堆或小顶堆移除元素时,为维护顶堆的性质,需要使用下滤操作
所谓上滤 或 下滤操作,其实就是维护大顶堆 或 小顶堆的性质而做出的一种操作,把元素移动到它该处在的位置。
5.顶堆的使用场景
优先级队列通常使用小顶堆作为底层数据结构,物理层面使用数组存储,逻辑层面就是使用小顶堆进行存储。优先级队列本身就想着把最先最近应该执行的定时任务放在首位,这样获取快。小顶堆正好把最先最近(元素值最小)的定时任务放在堆顶。当新添加一个定时任务时,会执行上滤操作。当执行完堆顶的定时任务后,需要从小顶堆中移除,移除成功后,需要使用下滤操作维护小顶堆的性质。
- JDK原生Timer的设计 以及 Netty为什么不使用Timer?

如图:

TimerQueue延迟队列对TimerTask定时任务的存储形式:
1.物理层面
使用的是一个默认128大小的数组进行存储。当大小不够时,进行扩容操作,一次扩容一倍

2.逻辑层面
由于单纯的数组遍历查找都是线性的,效率真的太低下。比如说:TimerThread需要取出当前最近执行的TimerTask,可能TimerTask不在第一个位置,此时我们就需要遍历整个延迟队列。如果只有几个TimerTask,那么线性遍历也无所谓,但是当数据量上升后,线性遍历的劣势愈发明显。
所以Timer引入了最小堆排序算法,使用该算法把所有定时任务进行构建出一个小顶堆,最先执行的定时任务放置在小顶堆的顶部。小顶堆的根部永远要优先于子节点先执行。

构建出小顶堆后,每一次TimerThread需要执行的最近的TimerTask实际上就是堆顶元素。但是当一个堆顶元素执行完毕后,我们需要移除该节点元素,由于发生了移除,那么要执行fixDown下滤方法。
很显然下滤方法也需要时间性能去消耗,但是我们知道小顶堆或大顶堆其实就是一个二叉树,二叉树利用二分法来搜索,所以消耗的时间效率一定是低于数组的线性搜索的。

------>但是
虽然JDK原生的Timer设计已经非常巧妙了,在数据量不大的情况下,使用这种二叉堆的逻辑存储结构使得搜索效率大大提升,摆脱了数组的线性搜索。
但是把视线转移到Netty,使用Netty进行开发客户端-服务端的通信基础架构时,断线重连,心跳机制都需要使用到定时任务,单纯对一个客户端而言,可能就有两个以上定时任务,因为重连和心跳都不止一次。
在高并发,用户量大的场景下,假设有10万的个客户端去连接服务端,此时服务端需要处理几十万个定时任务,假设我们还是采用JDK原生的Timer,使用二叉堆中的小顶堆进行存储这几十万个定时任务,可想而知二叉堆的层数有多大!这不是最恐怖的,最恐怖的是:每当我们从小顶堆新增或删除一个定时任务时,我们需要通过上滤或下滤的操作去维护大顶堆 或 小顶堆的性质,几十万定时任务对应得多少层?你上滤 或 下滤的时间成本高不高?时间复杂度会飙升。
所以Netty为保证海量数据用户连接的场景,抛弃JDK原生的Timer,而拥抱HashWheelTimer。后续会详细总结HashWheelTimer。
HashedWheelTimer
HashedWheelTimer是Netty自己依照TimingWheel(时间轮算法)设计的一种定时任务(延迟队列)的解决方案。
HashedWheelTimer肯定也是类似于JDK-Timer的设计:
延迟队列存储定时任务,开启新的异步依次处理延迟队列中当前最近最应该先执行的定时任务。
但是HashWheelTimer延迟队列的存储设计依照的是TimingWheel(时间轮算法)。所以HashedWheelTimer的延迟队列存储定时任务的结构为:1.物理层面:数组存储定时任务 2.逻辑层面:一个时间轮的结构存储定时任务
正是因为时间轮算法的加持,在海量定时任务场景下,Netty的时间处理效率要比JDK-Timer高很多。
TimingWheel(时间轮算法)
TimingWheel(时间轮算法) 是一种思想,它并不局限于Netty的HashWheelTimer所使用。
像Dubbo,大数据框架Akka,Kafka(做的要比Netty更加优秀),定时任务框架Quartz,Linux的crontab
这些框架架构都使用到了TimingWheel这一时间轮算法。
下面我来总结一下TimingWheel时间轮算法的概要和基本算法思想:
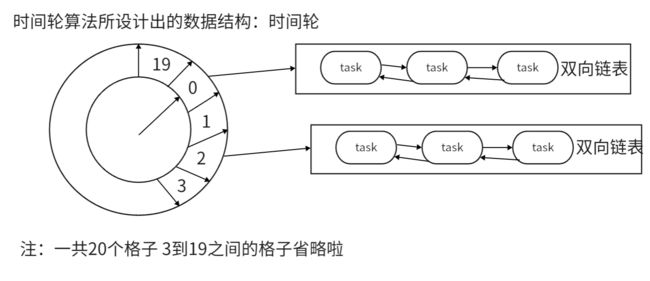
上图中的设计,每一秒作为一个时间间隔,总共20秒,所以就是20个格子。
意思就是延迟或定时在20秒之内的所有任务task都可以存储到这一时间轮数据结构中。
先举一个例子来说:
如果一个taskA是延迟2秒再执行,那么该taskA对象是存储在编号为2的格子的位置,编号为2的格子会对应有一个容器,该容器会维护一个双向链表,我们需要把taskA加入到该双向链表中,但是无需在乎加入到哪里。
如果加入完taskA对象后,此时又加入了一个延迟8秒才会执行的taskB,应该把taskB加入到哪一个格子所对应的双向链表中呢?
答案是:加入到编号为10的格子所对应的容器的双向链表中。
解释一下:时间轮不会从头重新开始,好像是一个指针【其实就是一个线程】,你加完taskA对象后,指针指向编号2,你再延迟8秒加入taskB,那么指针只需要从编号2再往后移动8位指向编号10的位置,在编号10的位置所对应的双向链表加入taskB。这样就大大降低了碰撞,使得分布相对均匀一些。
并且这种直接加入task到双向链表的方式,无需排序,无需维护次序。相比Timer的小顶堆大大提升了搜索效率。
具体总结一下上图时间轮这一数据结构所需要的变量:
1.总块数 wheelSize:上图的总块数为0到19,一共20块
2.每一块所对应的时间间隔 tickMs:1s,所以该时间轮所对应的时间范围为20s
3.当前所处的时间 currentTime:该变量实际上就是指向对应某一时间块的指针。其实就是一个线程来维护。
4.可以存储到时间轮的任务:定时任务 或 延迟任务
- 再举一个例子
现在有一个新需求:周一上午9点执行一个定时任务,周三上午9点执行一个定时任务。
此时我们就不能再使用之前时间间隔为1s的时间轮去做了,因为1s的时间间隔太短了会导致间隔数过多,浪费内存。此时我们就需要调整时间间隔为1h。由此可见,时间轮的时间间隔数是依照具体需求来定制的。设计出时间轮结构如下:

周一上午9点执行一个定时任务:对应找到编号为9的位置,把该定时任务加到该位置所对应的双向链表中
周三上午9点执行一个定时任务:24+24+9=57,对应找到编号为57的位置,把该定时任务加到该位置所对应的双向链表中。
再举一个例子:如果要每周一上午9点,周期性的执行任务,该怎么去设计?
如果按照上述的思路 准备一个365*24的时间轮。
但是实际上用的时间轮的格子就52个,剩余的8000多个时间间隔占了无意义的空间 。
为了解决这个无意义浪费轮子的问题:Netty使用了一种增加圈数的方式来解决超出时间范围的情况。如果超出了时间范围,不采取扩充格子的方式,而是再遇到相同编号位置时,netty给该节点元素一个圈数编号+1。如下图所示:

问题:
1.如上图时间轮的存储结构
逻辑结构(脑子里面思考想的):时间轮 环状结构
物理结构:数组
你可以这样理解:我们依照时间轮算法把物理存储结构的数组进行逻辑化,逻辑化成时间轮环状存储结构
2.时间间隔定义成多大合理?
依照具体需求定制化
3.
从上图构建的情景可知:一个168个时间间隔大小的时间轮,但是只有两个时间间隔是有任务的,其他的时间间隔都是空闲的!
我们知道,双向链表中的任务是通过线程执行的,但是线程需要不断的切换执行不同时间间隔的任务。
因为普通计算机最多16个左右的线程并行,无法保证几百个,几万个时间间隔所对应的任务并行,我们只能通过不断的CPU切换让多个任务实现多线程的并发执行,CPU不断的切换一定会造成CPU资源的紧张。
所以可见,线程是珍贵的资源。
在netty中的设计:
对于空闲没有任务的时间间隔的位置,线程sleep不争抢线程资源。直接让它sleep的好处在于:线程的sleep指的是将当前线程暂时挂起(或阻塞)一段时间,让出CPU资源给其他线程使用。当线程处于睡眠状态时,它将暂停执行,并且不会占用CPU资源,直到指定的时间间隔过去。
对于存在任务的位置,分配线程资源进行并发并行调度执行。
4.如果延迟或定时任务的时间超过 时间轮最大的时间表达封你为,应该如何处理?
两种解决思路:
(1) 加入圈数round。Netty就是这样设计
(2) 分层时间轮:Kafka (效率相比Netty要高)
Kafka的分层时间轮【时间轮算法在Kafka中的体现】


kafka的分层时间轮为什么要比Netty的圈数时间轮效率高?
因为分层时间轮的每一个链表是排好序的,依次挨个执行即可。而Netty的圈数时间轮的每一个间隔所对应的双向链表是无序的,当你找到一个双向链表,你需要自己再去找。
当延迟任务或定时任务处理完毕后,Netty和Kafka的做法就是让线程sleep休眠让出CPU资源给其他线程使用。因为CPU才是真正调度执行的中心,真正的把代码所对应的底层指令交给CPU去运算等各种处理。
当Kafka的分层时间轮不再是 小时 分 秒 怎么办?如何改变分层?
根据具体情况进行区分,如果是小时 分 秒 微秒 纳秒,那么就再增加两层时间轮。如果是小时 分,那么就减少一层时间轮。
记住一点:延迟任务只有移动到最小单位后才会被线程执行,在此之前都是一个被线程不断的移动存储到下一个较小单位位置的双向链表的过程。
- Netty的HashedWheelTimer与Kafka的分层时间轮,谁性能更加优秀?
当Netty的时间轮所表示的范围不够用时,Netty采用的是增加圈数来扩大范围。不同的任务可以存储在同一个编号位置,只是编号不同。举一个之前的例子如下图所示:

而Kafka是确立多层的时间轮,用多层的时间轮来表示完所有的延迟或定时任务。【前面说的很清楚啦】
所以对比可知,Kafka的分层时间轮可以精确的通过延迟任务在不同层次之间的移动来精确的定位,而Netty的HashedWheelTimer的编号法还需要遍历到某一具体位置后再去寻找你所需的那一个编号!多了一个搜索。所以Kafka分层时间轮的性能优于Netty的HashedWheelTimer
- Dubbo对时间轮的设计呢?
类似于Netty。因为Dubbo封装了Netty的协议,所以时间轮设计和Netty差不多。
很多框架对于延迟任务或定时任务的处理都是采用时间轮算法的这种设计去处理的。
Netty的HashedWheelTimer【时间轮算法在Netty中的实现】
Netty的HashedWheelTimer跟Kafka的分层时间轮所利用的思想一致,都是使用时间轮算法进行设计实现的关于定时任务或延迟任务存储和执行的具体解决方案。
HashWheelTimer的应用场景有哪些?
1.心跳检测
2.请求是否超时
3.消息的延迟推送
这三类场景都会使用到定时任务 或 延迟任务,所以都会利用到HashedWheelTimer
- 从宏观上认识HashWheelTimer
Timer接口是Netty自己搞的,不是Jdk的Timer
-------------
看完类结构,接下来要剖析一下HashedWheelTimer的组成结构。
我们知道,HashedWheelTimer完成了对延迟任务 或 定时任务的存储,以及到规定时间后对这些任务的执行
所以,HashedWheelTimer的功能是由多个部分(类)共同去完成的。
任务对象本身会封装成HashedWheelTimerOut
存储任务的功能是由HashedWheelBucket完成
执行任务的功能由Worker线程完成
所以可以得出如下:

以一个代码案例从宏观上分析一下:

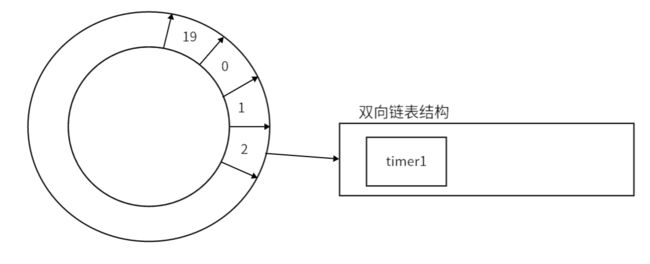
图中申明创建了一个HashWheelTimer对象,该对象是一个时间轮对象。传入的参数含义:设置该时间轮的每一个时间间隔为1s,时间轮一共20个时间间隔。
创建完时间轮对象后,底层会进行初始化HashedWheelTimer的属性结构,初始化创建HashedWheelBucket[],为什么要初始化成一个数组?因为时间轮是一个环状的结构,环状肯定不止一个位置可以存储后续的任务。数组的每一个元素都是HashedWheelBucket,每一个bucket都可以形成一个双向链表,双向链表负责真正的存储所有的任务。并且初始化Worker线程。
然后,timer.newTimeout创建任务对象,给定延迟时间为2s,以及重写的run方法。传这些参数是为了构建任务对象HashedWheelTimerOut。"重写的run方法"就是task任务,"延迟时间为2s"就是执行task的时机确定,这两个元素构建出了HashedWheelTimerOut任务对象。
构建完任务对象HashedWheelTimerOut后,会把该任务对象根据延迟时间或定时任务执行的时间设置大小进行确定存储到HashedWheelBucket数组的哪一个索引位置,确定完存储在哪一个索引后,会把该TimeOut对象存储到索引所对应的双向链表中去。
最终,Worker线程会在确定的时间点去执行相对应的HashedWheelTimeOut任务对象。
--------》
补充1:

tickDuration:时间间隔。代码中给的是1s。默认值是100ms
ticksPerWheel:时间间隔的数量。代码中给的是20个。默认值是512个
所以时间轮默认的周期长度为:100ms*512
补充2:
时间轮执行任务都是整点运行的。
比如说上述代码中给定了:时间间隔为1s,有20个时间间隔。所以可以执行任务的时间点为:1s,2s,3s,4s,5s,........,20s。假设在时间点为1s的时候执行一个任务,执行了0.5s就执行完了,由于只能整点才能执行任务,所以要到2s才能执行任务。此时Netty的设计就是:让线程sleep 0.5s,睡眠就是让出CPU的资源。
补充3:
如果任务耗时过长怎么办?
- 从源码剖析总结HashedWheelTimer
- 测试案例
package com.messi.netty_source_03.class_10_11;
import io.netty.util.HashedWheelTimer;
import io.netty.util.Timeout;
import io.netty.util.TimerTask;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.TimeUnit;
/**
* @Description TODO
* @Author etcEriksen
* @Date 2024/2/4 9:25
* @Version 1.0
*/
@Slf4j
public class TestHashedWheelTimer {
public static void main(String[] args) {
//创建HashedWheelTimer 创建线程,控制Timer的数量
//时间轮间隔为1s,有20个时间间隔,表示的范围为:0~19
HashedWheelTimer timer = new HashedWheelTimer(1, TimeUnit.SECONDS,20);
//添加延迟任务, 延迟时间为2s,所以把该延迟任务存储在编号为2所对应的双向链表中
Timeout timer1 = timer.newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
log.debug("test HashedWheelTimer");
}
}, 2, TimeUnit.SECONDS);
}
}
这段代码执行完毕后,内部结构如图所示:
debug源码流程如下:
1.

2.


createWheel()方法:

这里还包含一个知识点没有提及:为什么时间轮数组HashWheelTimerBucket[]的数组大小必须是2^n?在后续的补充中会总结到!
3.

newTimeout方法:

deadline计算的补充:

重点如下:涉及到多线程的通信


workerThread.start():

执行完start0方法后,就会开启一个新线程!

切换调用栈到start0开启的新线程pool-1-thread-1:

回调workerThread重写的run方法:


切换到回main线程:

总结一下上述线程启动过程中的切换和设计:
HashedWheelTimeout这一任务对象的deadline属性的再描述:

4.下面debug的流程会重点围绕开启的异步新线程:worker线程的run方法展开
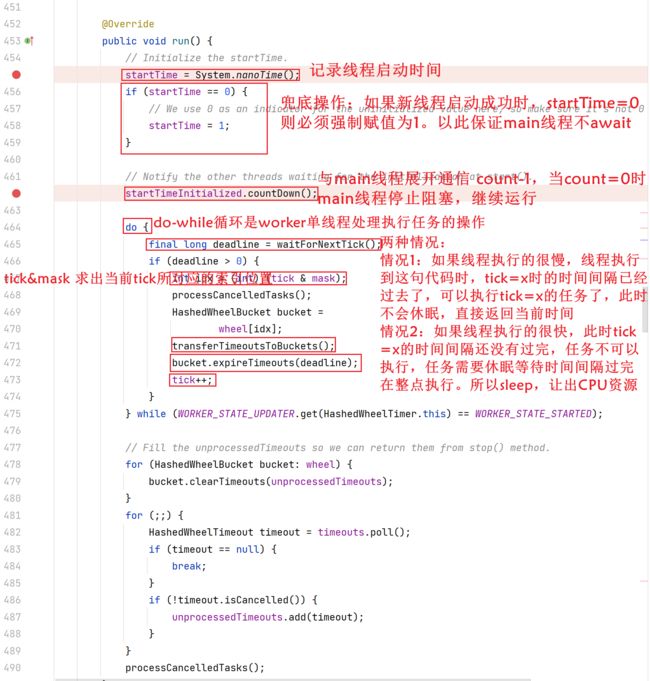
tick:
tick这一属性变量代表是当前worker线程执行到时间轮的第几个时间间隔了。
final long deadline = waitForNextTick():
问题1:为什么要sleep休眠?
回答这个问题前,先回顾一下时间轮的结构:
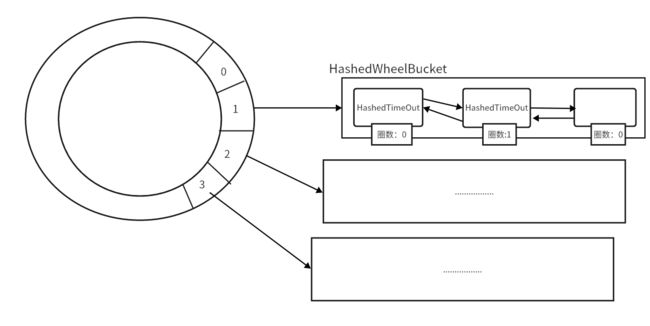
tick代表的是当前执行到哪一个时间间隔了。
如果说线程运行的很快,但是时间轮是分为很多时间间隔的。
比如说时间间隔为:100ms一个格子,由于任务都必须是整点运行。
当运行到100ms时,你线程执行100ms~200ms里面所有的任务:
情况1:如果在150ms时,里面所有的任务都执行完了。此时你再往下运行,你必须休眠50ms等待到第200ms,才能继续执行下一个时间间隔200ms~300ms里面的任务。
情况2:如果说你从100ms开始执行100ms~200ms里面所有的任务,如果执行到250ms才执行完,此时肯定不需要休眠呀,直接return 当前时间距离线程开启时的时间长度即可。
其实说白了,sleep就是为了保证tick和当前运行到的时间间隔相匹配!如果延迟了(线程运行的慢了),也会继续执行,不会丢弃任何一个时间间隔中的任务。如果还未达到整点且待执行任务的时间点的话,那么sleep阻塞休眠等待到对应可以执行的时间点。让出CPU资源,避免线程资源空轮询浪费CPU资源。
问题2:为什么计算long sleepTimeMs时,要(deadline - currentTime + 999999) / 1000000 ?
如果deadline-currentTime=1,只有1纳秒,我们此时加的999999纳秒就排上用场了,就是为了在deadline-currentTime极小且为正数的情况下,依然休眠至少1ms,这样就能保证避免频繁的sleep休眠到唤醒,唤醒到休眠。你思考一下:如果每一次deadline-currentTime=1纳秒,下一次进入到该循环是不是又只休眠1纳秒,我们为什么不一下就休眠1ms,这样把之后的所有休眠一次性休眠完毕,这样节省了后续sleep到唤醒,唤醒到sleep这中间切换状态所浪费的性能!!!

int idx = (int) (tick & mask):
通过tick值 & mask掩码值 求出当前tick所对应的时间间隔轮次数位置。等价于:tick % 数组长度
当tick=0时,idx=0,后续会取到idx=0位置的HashedWheelBucket的双向链表中的所有任务去交给worker线程执行。
transferTimeoutsToBuckets():
取出当前无锁队列中存储的前10万个任务放入到Bucket中
问题1:为什么一次最多加入10万个任务?
因为任务是可以通过newTimeout创建直接存储到无锁队列中的,如果在海量连接的情况下,可能会存储上百个任务到无锁队列中,如果说你一次性全取出来放到bucket的双向链表中,光取的这个过程,是不是就占用极大的时间?对吧。所以设置了一个取出上限,一次最多取10万个任务放到bucket的双向链表中。所以:如果任务多,超过10万个,分批取,一次最多取10万个。
问题2:为什么要取Math.max(calculated,tick)作为ticks的值?一般情况下都是calculated > tick,那么啥时候tick > calculated呢?
为了保证在海量任务加入的情况下,对于未在规定时间执行的任务能够顺利执行!
举个例子:
比如说一共加入了30多万个任务,我们在29万多加入了任务A,delay=1,所以deadline=1。由于一次最多只能加入10万个任务到时间轮中,外层控制tick的值。tick初始值等于0,所以当tick=2的时候,也就是第三次for循环加入任务时,才能加入任务A。很明显,tick=2,deadline=1,tick此时大于deadline。
任务A肯定是没有在规定的delay时间内执行,因为时间轮已经错过idx=1的bucket存储位置。
但是我们仍然需要在下一次马上执行任务A,所以应该取tick=2,而不是deadline,也就是在idx=2的bucket进行加入任务A。
如何保证以上需求的完成呢?通过Math.max(calculated,tick)取二者的最大值才能保证所有的情况的顺利进行
这样做肯定会导致一个问题!部分定时或延迟任务执行的时间不精确!因为我们对于已经过了规定时间执行的任务不采取放弃的手段,而是采用继续存储在下一个时间间隔轮询的bucket中,然后继续执行该任务。这就是典型的精度换安全和效能。
其实本质还是在于worker线程只有一个,只有一个worker线程来处理执行这么多的任务!
一个HashedWheelTimer只对应一个worker线程!但是话说回来,无论有多少worker线程,在海量任务的情况下,上述问题难以避免还是会发生,只不过在多线程的情况下,发生的几率降低了。

bucket.expireTimeouts(deadline):


执行如下的run方法

至此,HashedWheelTimer就总结完毕了。
补充:
为什么时间轮数组HashWheelTimerBucket[]的数组大小必须是2^n?
HashWheelTimer中存储定时任务或延迟任务的是时间轮数组HashWheelTimerBucket[]的每一个HashWheelTimerBucket所对应的双向链表结构。但是Netty有一个定性要求:HashWheelTimerBucket[]数组的大小必须是2的n次方大小!这一点更是验证了HashWheelTimerBucket中Hash的代称。这让人想起HashMap中底层数组也必须是2的n次方大小。其实HashWheelTimer和HashMap底层存储结构真的十分相似,甚至可以说是一模一样。HashWheelTimer是:数组+双向链表,HashMap是:数组+链表+红黑树。HashMap做的要更好一些。
接下来我们探讨一下为什么要使用2的n次方作为数组的大小呢?
见如下两篇博客:
HashMap:为什么容量总是为2的次幂_hashmap的大小为什么指定为2的幂次-CSDN博客
HashMap 容量为2次幂的原因_为什么hashmap是n的2次幂-CSDN博客
原因1.为了效率:
为了让位运算能够恰好代替取模运算,位运算性能更加优秀。
当数组大小为2^n时,哈希值&(数组大小-1) == 哈希值%数组大小。并且最终得到的结果值正好控制在[0,数组大小-1]
为什么位运算效率高于取模运算?
位运算是可以直接是二进制的运算,而取模运算必须是先把编码后的二进制[因为计算机底层识别是二进制]转换成十进制,进行十进制之间的运算
原因2.散列均匀:
我们计算的是任务对象存储在bucket数组的哪一个位置,为了让散列更加均匀,所以采用2的n次方。
见如上文章的案例测试,同一份数据,当数组大小为2的n次方时,哈希值&(数组大小-1) 或 哈希值%数组大小得到的结果要更加分别均匀,不会向某一个索引位置倾斜。
哈希冲突见如下文章:
解决哈希冲突(四种方法)_哈希冲突的解决方法-CSDN博客
无锁多生产者单消费者队列:
![]()
结合Netty通信的场景,如何理解多个生产者,单消费者?
假设只有一个服务端,有多个客户端连接上了。多个客户端可能会有多个定时任务或延迟任务,这些任务都在服务端进行处理,对于多个客户端,服务端需要开启多个线程去处理,也就是一组线程去处理。这多个线程(一组NioEventLoop以及Reactor模型)对应所有客户端连接,多个线程去存储各个客户端所对应的定时任务或延迟任务到该无锁多生产者单消费者队列中。这也就是多生产者!
单消费者也很好理解!在队列中有多个任务需要处理,但是服务端的HashWheelTimer只会开启一个worker线程去处理该无锁多生产者单消费者队列中的所有任务。这也就是单消费者!
多个生产者--->即对应多个线程。单个消费者--->即对应单个线程。
多个线程同时存任务到该无锁队列中 或 worker单线程去处理任务,无锁都保证了过程中的优越性能。