手把手教你基于 FastGPT 搭建个人知识库
前言 大家好,我是潇潇雨声。我发现在使用 GPT 时,尽管它能够生成一些小红书文案和日志,但内容常常显得空洞缺乏深度。今天我想分享一个解决这个问题的方法,那就是基于开源项目 FastGPT[1]。
我们可以通过向 GPT 提供一些有针对性的资料,然后让 AI 根据这些文档进行交互式对话,回答我们的问题。虽然回答的质量可能不会达到极高水平,但至少可以提高一定的质量下限。这就有点像使用 GPT 进行有针对性的训练。
接下来,我将带你安装并使用 FastGPT。
FastGPT
官方简介
❝FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!
❞
知识库核心流程图
一,安装 FastGPT
- 安装 Docker
如果没有安装 Docker 可以参考我之前写的 手把手教你在 windows 上安装 Dcoker
- 创建配置文件
- 创建 docker-compose.yml
# 非 host 版本, 不使用本机代理
# (不懂 Docker 的,只需要关心 OPENAI_BASE_URL 和 CHAT_API_KEY 即可!)
version: '3.3'
services:
pg:
image: ankane/pgvector:v0.5.0 # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.5.0 # 阿里云
container_name: pg
restart: always
ports: # 生产环境建议不要暴露
- 5432:5432
networks:
- fastgpt
environment:
# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果
- POSTGRES_USER=username
- POSTGRES_PASSWORD=password
- POSTGRES_DB=postgres
volumes:
- ./pg/data:/var/lib/postgresql/data
mongo:
image: mongo:5.0.18
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18 # 阿里云
container_name: mongo
restart: always
ports: # 生产环境建议不要暴露
- 27017:27017
networks:
- fastgpt
environment:
# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果
- MONGO_INITDB_ROOT_USERNAME=username
- MONGO_INITDB_ROOT_PASSWORD=password
volumes:
- ./mongo/data:/data/db
fastgpt:
container_name: fastgpt
image: ghcr.io/labring/fastgpt:latest # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:latest # 阿里云
ports:
- 3000:3000
networks:
- fastgpt
depends_on:
- mongo
- pg
restart: always
environment:
# root 密码,用户名为: root
- DEFAULT_ROOT_PSW=1234
# 中转地址,如果是用官方号,不需要管。务必加 /v1
- OPENAI_BASE_URL=https://api.openai.com/v1
- CHAT_API_KEY=替换成你的OPENAI-KEY
- DB_MAX_LINK=5 # database max link
- TOKEN_KEY=any
- ROOT_KEY=root_key
- FILE_TOKEN_KEY=filetoken
# mongo 配置,不需要改. 如果连不上,可能需要去掉 ?authSource=admin
- MONGODB_URI=mongodb://username:password@mongo:27017/fastgpt?authSource=admin
# pg配置. 不需要改
- PG_URL=postgresql://username:password@pg:5432/postgres
volumes:
- ./config.json:/app/data/config.json
networks:
fastgpt:
「注意:需要将 CHAT_API_KEY 的值换成自己 openai key。」
- 再创建 config.json
{
"SystemParams": {
"pluginBaseUrl": "",
"vectorMaxProcess": 15,
"qaMaxProcess": 15,
"pgHNSWEfSearch": 100
},
"ChatModels": [
{
"model": "gpt-3.5-turbo-1106",
"name": "GPT35-1106",
"price": 0,
"maxContext": 16000,
"maxResponse": 4000,
"quoteMaxToken": 2000,
"maxTemperature": 1.2,
"censor": false,
"vision": false,
"defaultSystemChatPrompt": ""
},
{
"model": "gpt-3.5-turbo-16k",
"name": "GPT35-16k",
"maxContext": 16000,
"maxResponse": 16000,
"price": 0,
"quoteMaxToken": 8000,
"maxTemperature": 1.2,
"censor": false,
"vision": false,
"defaultSystemChatPrompt": ""
},
{
"model": "gpt-4",
"name": "GPT4-8k",
"maxContext": 8000,
"maxResponse": 8000,
"price": 0,
"quoteMaxToken": 4000,
"maxTemperature": 1.2,
"censor": false,
"vision": false,
"defaultSystemChatPrompt": ""
},
{
"model": "gpt-4-vision-preview",
"name": "GPT4-Vision",
"maxContext": 128000,
"maxResponse": 4000,
"price": 0,
"quoteMaxToken": 100000,
"maxTemperature": 1.2,
"censor": false,
"vision": true,
"defaultSystemChatPrompt": ""
}
],
"QAModels": [
{
"model": "gpt-3.5-turbo-16k",
"name": "GPT35-16k",
"maxContext": 16000,
"maxResponse": 16000,
"price": 0
}
],
"CQModels": [
{
"model": "gpt-3.5-turbo",
"name": "GPT35",
"maxContext": 4000,
"maxResponse": 4000,
"price": 0,
"functionCall": true,
"functionPrompt": ""
},
{
"model": "gpt-4",
"name": "GPT4-8k",
"maxContext": 8000,
"maxResponse": 8000,
"price": 0,
"functionCall": true,
"functionPrompt": ""
}
],
"ExtractModels": [
{
"model": "gpt-3.5-turbo-1106",
"name": "GPT35-1106",
"maxContext": 16000,
"maxResponse": 4000,
"price": 0,
"functionCall": true,
"functionPrompt": ""
}
],
"QGModels": [
{
"model": "gpt-3.5-turbo-1106",
"name": "GPT35-1106",
"maxContext": 1600,
"maxResponse": 4000,
"price": 0
}
],
"VectorModels": [
{
"model": "text-embedding-ada-002",
"name": "Embedding-2",
"price": 0.2,
"defaultToken": 700,
"maxToken": 3000
}
],
"ReRankModels": [],
"AudioSpeechModels": [
{
"model": "tts-1",
"name": "OpenAI TTS1",
"price": 0,
"voices": [
{ "label": "Alloy", "value": "alloy", "bufferId": "openai-Alloy" },
{ "label": "Echo", "value": "echo", "bufferId": "openai-Echo" },
{ "label": "Fable", "value": "fable", "bufferId": "openai-Fable" },
{ "label": "Onyx", "value": "onyx", "bufferId": "openai-Onyx" },
{ "label": "Nova", "value": "nova", "bufferId": "openai-Nova" },
{ "label": "Shimmer", "value": "shimmer", "bufferId": "openai-Shimmer" }
]
}
],
"WhisperModel": {
"model": "whisper-1",
"name": "Whisper1",
"price": 0
}
}
- 启动
在 docker-compose.yml 同级目录下执行
- 拉取镜像
docker-compose pull
- 运行容器
docker-compose up -d
二,使用 FastGPT
- 访问
浏览器通过http://localhost:3000/进行访问

登录用户名为 root,密码为 docker-compose.yml 环境变量里设置的 DEFAULT ROOT PSW,默认是 1234.
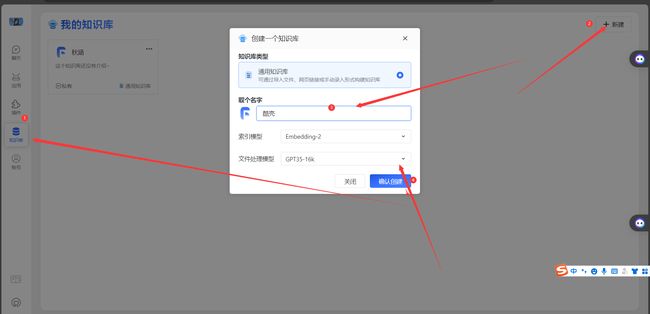
- 新建知识库
新建一个知识库,这里我是专门的存储酷壳网站上的文章,所以就命名为酷壳。
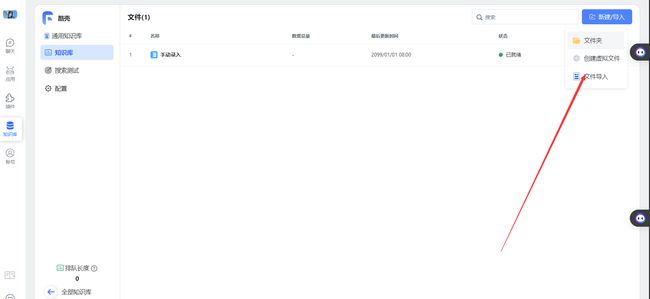
- 导入文档
通过文件导入已经下载好的文章


确认后就开始将当前数据转化为向量数据
这两篇文章字数可能破完了,完全导入好,所花费的时间可能会有半个小时乃至一个小时.....,由于文本限制问题,按照固定字数拆分若干个数据集
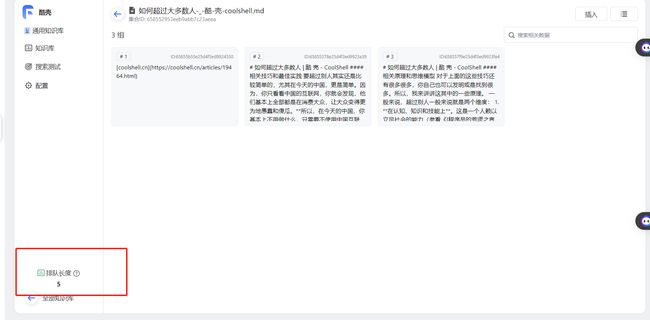
这是已经拆分好的,还有 5 个在排队,先测试一下。
- 使用知识库
新建一个应用
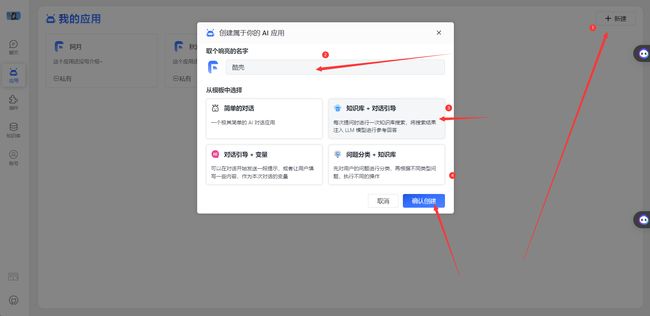
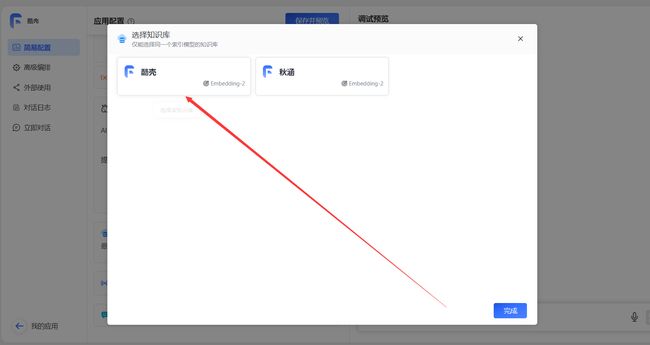
- 绑定刚刚的知识库

- 开始对话,效果展示如下:

这里有个小问题,

翻译如下:您已经超过了每分钟请求的限制次数。对于您的账户(org-FPtm4iWkzMglOZn9J06QAK6F)中的 text-embedding-ada-002 模型来说,每分钟的请求限制是 3 次,您已经使用了 3 次请求,但是您又发送了 1 次请求,所以您需要等待 20 秒后再试。您可以访问https://platform.openai.com/account/rate-limits了解更多信息。如果您在账户https://platform.openai.com/account/billing中添加了付款方式,您可以增加您的请求限制。
粗略的理解,一分钟只能处理三次请求,可以尝试设置多个 key 进行轮询,来解决上述的问题。
如果觉得我的分享对您有帮助,请关注我。创作不易,您的三连就是对我最大的支持。

Reference
[1]FastGPT: https://github.com/labring/FastGPT
本文由 mdnice 多平台发布