爬虫之提取数据xpath/BeautifulSoup/css/正则(re)的基本使用
提取数据常用的三种方法:
1.xpath方法 与lxml的etree配合使用
2.BeautifulSoup
3.正则
备注:主要掌握BeautifulSoup和xpath即可
1.xpath基本使用:
(可以在google浏览器里添加插件XPath Helper,方便验证是否写的对)
知识点
- “/”:就是个分隔符,跟电脑里面路径的分隔符一个意思。
- “//”:表示选择任意位置的某个节点。可理解为“坐飞机,我一下子略过这些路径”
- “@”: 表示选择某个属性。可理解为“定位,锁定”
- " .":表示当前标签
案列1.获得属性内容 这次案例是获取href内容

import requests
from lxml import etree
url="https://blog.csdn.net/weixin_43919632"
res=requests.get(url)
lxml=etree.HTML(res.content.decode("utf-8"))
##1.获取所有class="article-item-box csdn-tracking-statistics"的div标签下的 h4标签下的 标签a。
alist=lxml.xpath("//div[@class='article-item-box csdn-tracking-statistics']/h4/a")
##2.以上一个a标签的基础上,我们获得a标签里的href属性内容
for a in alist:
# 注意理解./ 理解为在a的基础上。 "@href"就是定位href的内容
#这个完整路劲为 //div[@class='article-item-box csdn-tracking-statistics']/h4/a/@href
#取[0]是因为这个返回来的是列表,需要取0 取出来。可以试一下加[0]与不加[0]结果是怎样的
href=a.xpath("./@href")[0]
print(href)
案例2 获取文本内容
import requests
from lxml import etree
url="https://blog.csdn.net/weixin_43919632"
res=requests.get(url)
lxml=etree.HTML(res.content.decode("utf-8"))
alist = lxml.xpath("//div[@class='article-item-box csdn-tracking-statistics']/h4/a")
for a in alist:
#完整路径是这样的 //div[@class='article-item-box csdn-tracking-statistics']/h4/a/text()
#也就是xpath中获取文本内容用text()方法
text=a.xpath("./text()")
#print(text)
#因为上面获取的text经打印出来发现有换行符之类的其他字符,因此再做处理
result=text[-1].strip()
print(result)
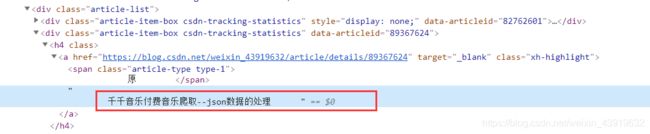
案例二文本获取结果

菜鸟教程请参考:http://www.runoob.com/?s=xpath
2.BeautifulSoup基本使用案例:
#-*encoding:utf-8 *-
#BeautifulSoup 基本使用案例
# 1.获取所有tr标签
# 2.获取第二个tr标签
# 3.获取所有class=“even”的tr标签
# 4.获取所有keywords=python又target=“_blank”的a标签
# 5.获取所有a标签的href属性
# 6.获取文本内容
from bs4 import BeautifulSoup
html="""
职位名称
职位类别
人数
地点
发布时间
GY0-【国际业务部】推荐算法资深工程师(深圳)
技术类
1
深圳
2019-04-13
29777-腾讯云工业行业方案架构师(深圳)
技术类
2
深圳
2019-04-13
22989-腾讯云SDN控制器开发工程师
技术类
1
深圳
2019-04-13
23671-企鹅号数据产品经理(北京)
产品/项目类
1
北京
2019-04-13
TEG09-计算平台研发工程师(深圳)
技术类
2
深圳
2019-04-13
20503-优图运维开发工程师(上海)
技术类
1
上海
2019-04-13
"""
#1.获取所有的tr标签
#soup=BeautifulSoup(html,"lxml")
#使打印出来更美观
#print(soup.prettify())
# trs=soup.find_all("tr")
# for tr in trs:
# print(tr)
#2.获取第二个tr标签
#soup=BeautifulSoup(html,"lxml")
#第二个tr标签
#trs=soup.find_all("tr")[1]
#print(trs)
#limit表示限制的个数
#trs=soup.find_all("tr",limit=5)
#3.获取class=“even”的tr标签
soup=BeautifulSoup(html,"lxml")
#第一种写法
#trs=soup.find_all("tr",attrs={"class":"even"})
#第二种写法,因为class为python的关键字,会与class属性发生冲突,因此python中用class_表示class属性
#trs=soup.find_all("tr",class_="even")
#for tr in trs:
# print(tr)
#4.获取keywords=python&又id="49357"的a标签
# soup=BeautifulSoup(html,"lxml")
# aes=soup.find_all("a",attrs={"keywords":"python&","id":"49357&"})
# print(aes)
# for a in aes:
# print(a)
#5.获取a标签内的href属性
# soup=BeautifulSoup(html,"lxml")
# alist=soup.find_all("a")
# for a in alist:
#像字典当中通过键取相应的值一样
# href=a["href"]
# print(href)
#6.获取文本信息 用string方法获取 xpath当中是用text()获取的
"""
获得字符串的方法:
sting strings stripped_strings 以及 get_text,contents,children方法区别:
1.string 获取某个标签下的字符串,前提是这个标签内只有这个字符串。弊端:当一个标签下有多个换行了的字符串,就不能获取。要用strings方法
2.strings 获取某个某标签下的所有(子孙)字符串(不可以获得注释文本),返回的是个迭代器,也就是需要用for循环,来迭代打印出来
3.get_text 获取某个标签下所有东西,包括一些子孙标签,也有字符串。返回的是字符串和一些标签,不是生成器。(可以获得注释文本)
4.stripped_strings 获取去掉了空白字符的所有字符串,返回的是个生成器。
5.contents是获得包括一些注释的文本,以及一些换行符,返回的是列表
6.children与contents同样,唯一区别是返回的是个生成器,需要遍历
"""
# soup=BeautifulSoup(html,"lxml")
# alist=soup.find_all("a")
# for a in alist:
# print(a.string)
基于BeautifulSoup的css选择器
1.#标签选择器
print (bs.select(‘a’))
2.#类名选择器
print (bs.select(’.css’))
3.#id选择器
print (bs.select(’#css’))
4. #属性选择器
print bs.select(‘a[class=“css”]’)
5. #遍历
for tag in bs.select(‘a’):
print(tag.get_text())
3.正则基本使用:
正则表达式全集,内含常用表达式:http://tool.oschina.net/uploads/apidocs/jquery/regexp.html
笔记:
#--*encoding:utf-8*--
import re
"""
正则的基本使用
"""
#########一.单个元字符的使用##########
#1.匹配某个字符串 以下用match函数,匹配 (缺点:必须字符串开头开始匹配,否则匹配失败)
"""
注意match函数是以开头,开始匹配的
"""
# text="textstring"
# res=re.match("te",text)
"""
group表示将匹配的内容都呈现出来
"""
# print(res.group())
###2 "." 这个点 表示匹配任意字符,除了换行符
# text="hello"
# res=re.match(".",text)
# print(res.group())
###3. "*"匹配任意数量的字符,除去换行符
# text="niaossa1213420--="
"""
'.*'匹配任意长度的任意字符
"""
# res=re.match(".*",text)
# print(res.group())
###3. "\d"这个表示匹配任意的数字,
# text="123"
"""
匹配两个数字
"""
# res=re.match("\d",text)
# print(res.group())
###4.“{m}”表示匹配m个字符,"{m,n}"匹配m-n个数字
# text="12618"
# res=re.match("\d{5}",text)
# print(res.group())
###4.“\D”匹配任意的非数字
# text="hello"
# res=re.match("\D",text)
# print(res.group())
####5.“\s”匹配空白字符(\n(换行符),\t(制表符),\r,空格)
# text=" \t"
# res=re.match("\s",text)
# print(res.group())
###6.“\w”匹配的a-z,A-Z,数字和下划线
# text="_"
# res=re.match("\w",text)
# print(res.group())
###7.“\W”与“\w”相反的
# text="+"
# res=re.match("\W",text)
# print(res.group())
###########二。多个元字符组合使用###########
###8."[]"表示组合的方式,只要符合[]里的,就会匹配
# text="213978-8888888"
"""
这里-前加了\ 因为-是特殊字符,需要转义,
"+"表示匹配一个到多个字符
组合"[\d\-]+"表示匹配数字和-组成的字符串
"""
# res=re.match("[\d\-]+",text)
# print(res.group())
"""
###9.中括号匹配范围数字 [0-9]表示匹配0-9之间的数字,但只能匹配一个数字,
[0-9]+表示匹配0-9之间的一个到多个数字
"""
# text="87"
# res=re.match("[0-9]+",text)
# print(res.group())
###10。以中括号的形式代替\w,
#text="aZ1_"
"""
[a-zA-Z_0-9]匹配满足括号里的内容,但只能匹配到一个字符,
‘[a-zA-Z_0-9]+’匹配到满足[]一个或多个字符
"""
# res=re.match("[a-zA-Z_0-9]",text)
# print(res.group())
"""
"""
#11.search 函数,匹配任意的字符,不需要必须以开头开始匹配
# text="hello,world"
# result=re.search("e",text) #这里并没有以h开头 换做match会报错
# print(result.group())
#11.1^(脱字号,两个意义 1.要以什么字符开头
#
# 11.2 “非”的意思
# /[^a-z\s]/会匹配"my 3 sisters"中的"3 ",此时^的意思是“非”,类似的有
#
# [^a]表示“匹配除了a的任意字符”。
#
# [^a-zA-Z0-9]表示“找到一个非字母也非数字的字符”。
#12.贪婪模式与非贪婪模式
# text="01212817"
# # res=re.search("\d+",text)#匹配结果是01212817 .+表示匹配一个或多个字符,匹配的时候默认贪婪模式,匹配多个
# res=re.search("\d+?",text)#加一个问号,就是非贪婪模式 匹配一个字符.
# print(res.group())
#13.group()分组
# text="apple's price is $100,bnana's price is $99,grape is $1000"
# res=re.search(".*(\$\d+).*(\$\d+).*(\$\d+)",text)
# print(res.group())#获得text全部字符
# print(res.group(1))#获得第一个括号里的内容 即$100
# print(res.group(2))#获得第二个括号里的内容,即$99
# print(res.group(1,2))#将1,2两个进行分组
# print(res.groups())#将所有的获取分成一个组
#14.常用函数
#14.findall 返回列表
# text="apple's price is $100,bnana's price is $99,grape is $1000"
# res=re.findall("\$\d+",text)
# print(res) #不需要加group方法
#14.2
#sub函数
#用来替换字符串
# text="apple's price is $100,bnana's price is $99,grape is $1000"
# res=re.sub("\$\d+",'20',text)
# print(res)
#14.3 compile函数 当正则表达式被重复调用多次的时候,可以先用compile编译,节省效率
# text="the number is 20.5"
# r=re.compile(r"""
# \d+ #小数点前面的数字
# \. #小数点
# \d+ #小数点后面的数字""",re.VERBOSE)
# ret=re.search(r,text)
# print(ret.group())
###########三.案列###############
###1.匹配手机号码
# numlst=["13067789765","15021121768","17602337865","18375885432"]
# for i in numlst:
# result=re.match("1[3578]\d*",i)
# print(result.group())
###2.匹配邮箱
#mailboxlist=["[email protected]","[email protected]"]
# for maibox in mailboxlist:
# result=re.match("\w+@[a-z0-9]+\.+\w{3}",maibox)
# print(result.group())
###匹配网址
# urlst=["https://blog.csdn.net/weixin_43919632",
# "http://blog.csdn.bet/weixin_43919632",
# "ftp://blog.csdn.net/weixin_43919632"]
# for url in urlst:
# #“^”表示取反, "^\t"匹配不是 制表符的字符
# result=re.match("(http://|https://|ftp://)[^\t]+",url)
# print(result.group())
###匹配身份证号
# idlst=["32564534564234542x","32564534564234542X","325645345642345428"]
# for ids in idlst:
# result=re.match("\d{17}[\dxX]+",ids)
# print(result.group())
菜鸟教程参考:http://www.runoob.com/python3/python3-reg-expressions.html
你可能感兴趣的:(python,提取数据)