Spring Boot集成百度UidGenerator雪花算法使用以及自定义starter封装UidGenerator支持原生DB、Redis、自定义方式获取workID介绍
一、前言
当下系统开发过程中,普遍会采用分布式微服务架构,在此技术背景下,分布式ID的生成和获取就成为一个不得不考虑的问题。常见的分布式ID生成策略有基于数据库号段模式、UUID、基于Redis、基于zookeeper、雪花算法(snowflake)等方案,这其中雪花算法由于其简单、独立、易用的特性,被众多技术选型推荐。
雪花算法 (SnowFlake),是 Twitter 开源的分布式 id 生成算法,可以不用依赖任何第三方工具进行自动增长的数字类型的ID生成;雪花算法的核心逻辑是使用一个 64 bit 的 long 型的数字作为全局唯一 ID。
![]()
我们先看一下雪花算法生成的ID构成逻辑:雪花算法生成的唯一ID均为正数,所以这 64 个 bit 中,其中 1 个 bit 是不用的(第一个 bit 默认都是 0),然后用其中的 41 bit 作为毫秒数,用 10 bit 作为工作机器 id,12 bit 作为序列号。
-
1个bit, 必须取值为0。因为二进制中第一个bit为1代表整体是负数,而生成的分布式id是正数,因此第一个bit恒为0。
-
41 bit 作为毫秒数:雪花算法初始化时,会指定一个起始时间,算法执行时,会根据机器时间和指定的起始时间差值进行计算存储到41bit的毫秒数中,
2^41 - 1 = 2199023255551毫秒,2199023255551 / 1000 / 60 / 60 / 24 / 365 ≈ 69.73年,所以雪花算法根据设置的起始时间可以使用大概69年。 -
10 bit 作为工作机器 id:在分布式架构下,应用会部署到不同的机器节点上,为了防止不同的机器生成的雪花算法ID重复,引入了机器ID的概念,2^10,可以支持
1024个机器。 -
12 bit 作为序列号:这12bit的数字,是指1毫秒内生成的ID数量,2^12,支持每个节点每个毫秒生成
4096个ID。
当算法请求执行时,snowflake算法先基于二进制位的运算方式生成一个64bit的long类型的id, 其中第一个bit设为0,接着41个bit,采用当前时间戳和初始化时间差值,然后5个bit设置机房id, 后5个bit设置机器id,最后进行判断,当前机房的这台机器在这毫秒内,是第几个请求,并给当前请求赋予一个累加的序号,作为最后的12个bit. 最终得到一个唯一的id.
有人说雪花算法生成的ID递增规律不明显?看同一毫秒内的数据,可能更加明显一些。
有人说雪花算法为什么要设置起始时间,直接取系统时间不行吗?由上面描述可以发现,雪花算法最多大概支持69年,1970 + 69 = 2039年,这样2039年以后雪花算法使用就到期了。
上面说了雪花算法的好处,但是雪花算法就没有问题吗?问题肯定是有的,雪花算法最大的问题就是时间回拨问题。所谓时间回拨,就是雪花算法需要依赖机器所在时间生成ID,比如在昨天生成了一些ID,今天将机器时间调成跟昨天一样,这样某一个时刻41bit存的毫秒数,和之前生成ID的时候一样,导致生成的ID出现重复的问题。那有什么解决方案吗?可以,就是使用百度UidGenerator。
二、百度UidGenerator
1. 介绍
百度UidGenerator是基于snowflake算法思想实现的,但与原始算法不同的地方在于,UidGenerator支持自定义时间戳、工作机器id(workId)以及序列号等各个组成部分的位数,并且工作机器id采用用户自定义的生成策略。百度uid-generator有两种实现方式: DefaultUidGenerator和CachedUidGenerator。从性能和时间回拨问题考虑,一般都是考虑CachedUidGenerator类实现。
更多了解可以参考:https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
我这里截部分官方文档图片:

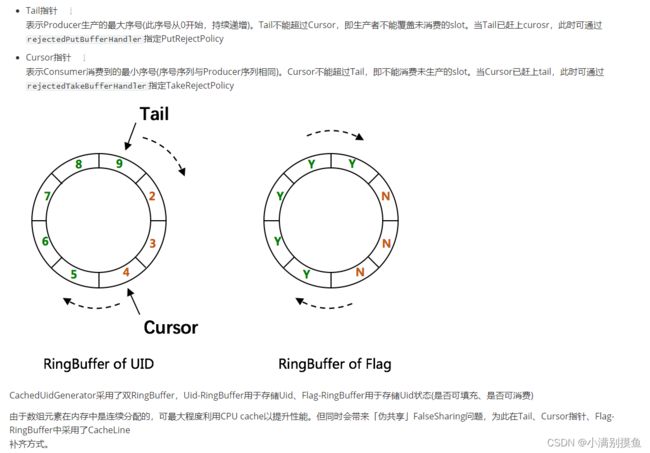
2. springboot集成UidGenerator
我们先试用一下原生的UidGenerator的功能,体验一下UidGenerator方便之处。
1. 引入UidGenerator相关依赖
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>com.xfvape.uidgroupId>
<artifactId>uid-generatorartifactId>
<version>0.0.4-RELEASEversion>
<exclusions>
<exclusion>
<artifactId>mybatisartifactId>
<groupId>org.mybatisgroupId>
exclusion>
<exclusion>
<artifactId>mybatis-springartifactId>
<groupId>org.mybatisgroupId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>2.3.0version>
dependency>
<dependency>
<groupId>com.mysqlgroupId>
<artifactId>mysql-connector-jartifactId>
<version>8.2.0version>
dependency>
dependencies>
2. 执行初始化SQL
原生UidGenerator是需要依赖数据库ID自增的机制,防止workID重复的。
DROP TABLE IF EXISTS WORKER_NODE;
CREATE TABLE WORKER_NODE
(
ID BIGINT NOT NULL AUTO_INCREMENT COMMENT 'auto increment id',
HOST_NAME VARCHAR(64) NOT NULL COMMENT 'host name',
PORT VARCHAR(64) NOT NULL COMMENT 'port',
TYPE INT NOT NULL COMMENT 'node type: ACTUAL or CONTAINER',
LAUNCH_DATE DATE NOT NULL COMMENT 'launch date',
MODIFIED TIMESTAMP NOT NULL COMMENT 'modified time',
CREATED TIMESTAMP NOT NULL COMMENT 'created time',
PRIMARY KEY(ID)
)
COMMENT='DB WorkerID Assigner for UID Generator',ENGINE = INNODB;
3. 声明UidGeneratorConfig配置类
import com.xfvape.uid.impl.CachedUidGenerator;
import com.xfvape.uid.worker.DisposableWorkerIdAssigner;
import com.xfvape.uid.worker.WorkerIdAssigner;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@MapperScan(basePackages = "com.xfvape.uid.worker.dao")
public class UidGeneratorConfig {
@Bean
public CachedUidGenerator cachedUidGenerator(WorkerIdAssigner disposableWorkerIdAssigner) {
CachedUidGenerator cachedUidGenerator = new CachedUidGenerator();
cachedUidGenerator.setWorkerIdAssigner(disposableWorkerIdAssigner);
// 时间戳位数
cachedUidGenerator.setTimeBits(29);
// 机器位数
cachedUidGenerator.setWorkerBits(21);
// 每毫秒生成序号位数
cachedUidGenerator.setSeqBits(13);
//从初始化时间起起, 可以使用8.7年
cachedUidGenerator.setEpochStr("2024-02-05");
return cachedUidGenerator;
}
@Bean
public DisposableWorkerIdAssigner disposableWorkerIdAssigner() {
DisposableWorkerIdAssigner disposableWorkerIdAssigner = new DisposableWorkerIdAssigner();
return disposableWorkerIdAssigner;
}
}
4. 将WORKER_NODE.xml拷贝到项目中
WORKER_NODE.xml在uid-generator依赖的META-INF目录下:
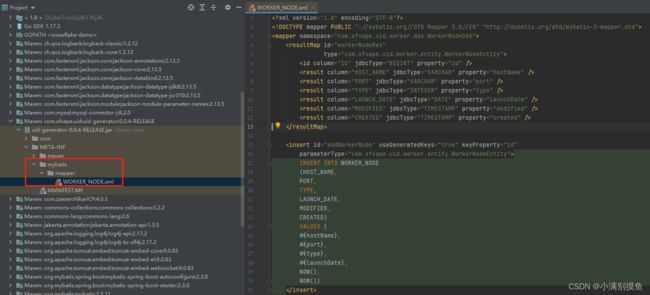
拷贝到项目中resource/mybatis目录下:
5. 配置数据库连接信息
server:
port: 7090
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/uid
username: root
password: root
mybatis:
mapper-locations: classpath*:/mybatis/*.xml
6. 运行并测试
-
测试代码:
@RestController public class HelloController { @Autowired private CachedUidGenerator cachedUidGenerator; @GetMapping("getUid") public long hello() { return cachedUidGenerator.getUID(); } } -
测试结果:
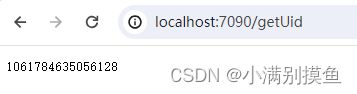
-
数据库:
至此,springboot集成UidGenerator生成ID就完成了。
三、UidGenerator自定义增强workID获取
大家有没有发现一个问题,原生的UidGenerator是强依赖数据库的,虽然可以保证workID不重复,却减少了灵活性,比较很多项目是没有使用数据库的,其实,UidGenerator也是支持大家自定义workID获取逻辑的,下面我们就封装一下UidGenerator,自定义一个starter,支持数据库、Redis、自定义workID三种方式。
1. 创建一个springboot项目,导入相关依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.7.18version>
<relativePath/>
parent>
<groupId>com.jhxgroupId>
<artifactId>jhx-snowflake-spring-boot-starterartifactId>
<version>1.0.0-SNAPSHOTversion>
<name>jhx-snowflake-spring-boot-startername>
<description>jhx-snowflake-spring-boot-starterdescription>
<properties>
<java.version>1.8java.version>
properties>
<dependencies>
<dependency>
<groupId>com.xfvape.uidgroupId>
<artifactId>uid-generatorartifactId>
<version>0.0.4-RELEASEversion>
<exclusions>
<exclusion>
<artifactId>mybatis-springartifactId>
<groupId>org.mybatisgroupId>
exclusion>
<exclusion>
<artifactId>mybatis