树状 _ 层次 结构数据的数据库表设计对比及使用
最近在做项目管理的项目,其中有层级关联,多模块情况,感觉平时的树状数据库设计不太行,所以了解了一下,这篇文章总结的很好
树状结构或层次结构的数据在企业应用里非常常见,例如公司的组织架构、文档库的目录结构、仓库的库位组织以及物件的分类等等。
通常的树状图是一种数据结构。把它叫做 “树” 是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
它具有以下的特点:每个结点有零个或多个子结点;没有父结点的结点称为根结点;每一个非根结点有且只有一个父结点;除了根结点外,每个子结点可以分为多个不相交的子树。
树结构是一种非线性存储结构,存储的是具有 “一对多” 关系的数据元素的集合。
本文对计算机数据库表模型中常见的对树状 / 层次结构数据的几种设计进行介绍、对比:
- 邻接表模型
- 路径枚举模型
- 闭包表模型
- 嵌套集模型
邻接表模型
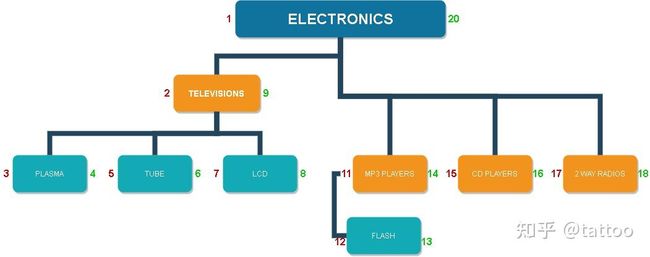
在设计树状结构的数据库表的时候,大部分开发者会下意识的选择邻接表(Adjacency List)模型。例如:

CREATE TABLE category(
category_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(20) NOT NULL,
parent INT DEFAULT NULL
);
INSERT INTO category VALUES(1,'ELECTRONICS',NULL),(2,'TELEVISIONS',1),(3,'TUBE',2),
(4,'LCD',2),(5,'PLASMA',2),(6,'PORTABLE ELECTRONICS',1),(7,'MP3 PLAYERS',6),(8,'FLASH',7),
(9,'CD PLAYERS',6),(10,'2 WAY RADIOS',6);
SELECT * FROM category ORDER BY category_id;
+-------------+----------------------+--------+
| category_id | name | parent |
+-------------+----------------------+--------+
| 1 | ELECTRONICS | NULL |
| 2 | TELEVISIONS | 1 |
| 3 | TUBE | 2 |
| 4 | LCD | 2 |
| 5 | PLASMA | 2 |
| 6 | PORTABLE ELECTRONICS | 1 |
| 7 | MP3 PLAYERS | 6 |
| 8 | FLASH | 7 |
| 9 | CD PLAYERS | 6 |
| 10 | 2 WAY RADIOS | 6 |
+-------------+----------------------+--------+
在上面的分类表里,我们定义了分类 ID(category_id)、分类名称(name)以及父分类 ID(parent)三个字段。
这里有一个真相是,上面这种简单的邻接表模型不是一种归一化(Nomalized)的结构。归一化的简短定义是,所有数据冗余都已被删除,并且不会出现数据异常。在一个归一化的数据模型里,数据应该是 “一事、一地、一次”(one simple fact, in one place, one time),即一件事只在一处记录一次,以及一次只在一处记录一件事。
归一化表的第一个特征是只记录一件事,而前面的做法是在一个表里既记录了分类的名称,也记录了分类的层级关系,是一个混合对象。正确的做法是用两个表,一个记录分类的各种属性,一个记录分类之间的从属关系。
归一化表的第二个特征是每个事实都出现在 “一地”(即,它属于一个表的一行),但是邻接表每个节点的子树可以位于多行中。归一化表第三个特征是每个事实在架构中出现 “一次”(即,希望避免数据冗余)。如果同时违反了这两个条件,我们可能遇到异常。
下面列举一些由邻接表模型产生的非归一化行为。
比如新建分类和更改分类,如果不小心写错了 parent,那么很容易构造一个环形从属关系:
INSERT INTO category VALUES(11,'TV123',3);
UPDATE category SET parent=11 WHERE name='TUBE';
这里 TV123 和 TUBE 就互为父分类了。
或者:
INSERT INTO category VALUES(12,'TV456',12);
这里 TV456 为自己的父分类了。
另外简单邻接表模型不支持从属关系的继承,删除某行会将树拆分为几个较小的树,例如:
DELETE FROM category WHERE name='PORTABLE ELECTRONICS';

最后,我们需要保留表中的树结构。我们需要确保结构中只有一个 NULL,而简单的邻接表模型不能防止多个 NULL 或循环从属关系。问题在于邻接表模型实际上可以是任何图形,而树是图形的特殊情况,因此我们需要对邻接表模型加上限制条件,以确保只有一棵树。
获取邻接表全树
SELECT t1.name AS lev1, t2.name as lev2, t3.name as lev3, t4.name as lev4
FROM category AS t1
LEFT JOIN category AS t2 ON t2.parent = t1.category_id
LEFT JOIN category AS t3 ON t3.parent = t2.category_id
LEFT JOIN category AS t4 ON t4.parent = t3.category_id
WHERE t1.name = 'ELECTRONICS';
+-------------+----------------------+--------------+-------+
| lev1 | lev2 | lev3 | lev4 |
+-------------+----------------------+--------------+-------+
| ELECTRONICS | TELEVISIONS | TUBE | NULL |
| ELECTRONICS | TELEVISIONS | LCD | NULL |
| ELECTRONICS | TELEVISIONS | PLASMA | NULL |
| ELECTRONICS | PORTABLE ELECTRONICS | MP3 PLAYERS | FLASH |
| ELECTRONICS | PORTABLE ELECTRONICS | CD PLAYERS | NULL |
| ELECTRONICS | PORTABLE ELECTRONICS | 2 WAY RADIOS | NULL |
+-------------+----------------------+--------------+-------+
6 rows in set (0.00 sec)
以上 SQL 通过自连接(self-join)实现了全树的信息获取。这种方法的弊病很明显,有多少层,就得套多少自连接,这在旧版的 MySQL 中是唯一的办法,因为它不支持递归。
在 Oracle 中可以通过 connect by 语法来实现递归查询,在 MySQL 8 中使用 SQL-99 标准的 CTE (common table expression) 语法里的 RECURSIVE 来实现递归:
WITH RECURSIVE T1(category_id,name,parent) AS (
SELECT * FROM category T0 WHERE
T0.parent IS NULL -- ANCHOR MEMBER
UNION ALL
SELECT T2.category_id,T2.name,T2.parent FROM category T2, T1 -- RECURSIVE MEMBER
WHERE T2.parent = T1.category_id
)
SELECT * FROM T1;
+-------------+----------------------+--------+
| category_id | name | parent |
+-------------+----------------------+--------+
| 1 | ELECTRONICS | NULL |
| 2 | TELEVISIONS | 1 |
| 6 | PORTABLE ELECTRONICS | 1 |
| 3 | TUBE | 2 |
| 4 | LCD | 2 |
| 5 | PLASMA | 2 |
| 7 | MP3 PLAYERS | 6 |
| 9 | CD PLAYERS | 6 |
| 10 | 2 WAY RADIOS | 6 |
| 8 | FLASH | 7 |
+-------------+----------------------+--------+
递归执行过程如下:
- 查找 parent IS NULL 的第一种类别,我们可以得到 ELECTRONICS;
- 接着查找 parent = ELECTRONICS 的第二类电器种类,可以看出我们可以得到 TELEVISIONS 和 PORTABLE ELECTRONICS;
- 接着查找 parent = TELEVISIONS 和 parent = PORTABLE ELECTRONICS,我们可以得到第三类电器分别是 PLASMA,MP3 PLAYERS,CD PLAYERS,2 WAY RADIOS,TUBE,LCD;
- 接着继续查找属于第三类电器种类的产品,最后得到 FLASH;
- 执行完毕。
众所周知递归的效率是比较低的,递归查询的问题是随着数据量的增加、层级的增加,递归的嵌套层数也会增加,所以到后面我们会不得不对这些查询进行优化。
获取邻接表子树
WITH RECURSIVE T1 AS (
SELECT * FROM category T0 WHERE
T0.name = 'TELEVISIONS' -- ANCHOR MEMBER
UNION ALL
SELECT T2.category_id,T2.name,T2.parent FROM category T2, T1 -- RECURSIVE MEMBER
WHERE T2.parent = T1.category_id
)
SELECT * FROM T1;
+-------------+-------------+--------+
| category_id | name | parent |
+-------------+-------------+--------+
| 2 | TELEVISIONS | 1 |
| 3 | TUBE | 2 |
| 4 | LCD | 2 |
| 5 | PLASMA | 2 |
+-------------+-------------+--------+
通过 MySQL 8 下使用 CTE 递归查询。使用自连接的方式这里就不赘述了,与全树类似。
获取邻接表叶节点
SELECT t1.name FROM category AS t1
LEFT JOIN category as t2
ON t1.category_id = t2.parent
WHERE t2.category_id IS NULL;
+--------------+
| name |
+--------------+
| TUBE |
| LCD |
| PLASMA |
| FLASH |
| CD PLAYERS |
| 2 WAY RADIOS |
+--------------+
以上通过判断没有子节点获取所有叶子节点。
获取邻接表完整单路径
SELECT t1.name AS lev1, t2.name as lev2, t3.name as lev3, t4.name as lev4
FROM category AS t1
LEFT JOIN category AS t2 ON t2.parent = t1.category_id
LEFT JOIN category AS t3 ON t3.parent = t2.category_id
LEFT JOIN category AS t4 ON t4.parent = t3.category_id
WHERE t4.name = 'FLASH';
+-------------+----------------------+-------------+-------+
| lev1 | lev2 | lev3 | lev4 |
+-------------+----------------------+-------------+-------+
| ELECTRONICS | PORTABLE ELECTRONICS | MP3 PLAYERS | FLASH |
+-------------+----------------------+-------------+-------+
以上通过自连接获取一条完整路径。
这种方法的主要限制是,层次结构中的每个级别都需要一个自连接,并且随着连接复杂性的增加,每个级别的添加都会降低性能。
在 MySQL 8 以后同样使用 CTE 来递归查找:
WITH RECURSIVE T1(category_id,name,parent) AS (
SELECT * FROM category T0 WHERE
T0.name = 'FLASH' -- ANCHOR MEMBER
UNION ALL
SELECT T2.category_id,T2.name,T2.parent FROM category T2, T1 -- RECURSIVE MEMBER
WHERE T2.category_id = T1.parent
)
SELECT * FROM T1;
+-------------+----------------------+--------+
| category_id | name | parent |
+-------------+----------------------+--------+
| 8 | FLASH | 7 |
| 7 | MP3 PLAYERS | 6 |
| 6 | PORTABLE ELECTRONICS | 1 |
| 1 | ELECTRONICS | NULL |
+-------------+----------------------+--------+
添加节点
邻接表里添加节点比较方便,直接 Insert 一条记录即可,只需要注意父节点要设置正确。
删除节点
删除叶节点,即没有子节点的节点是很简单的,直接 Delete 即可。但是如果要删除中间节点,为了防止出现孤立子树,我们需要确定删除中间节点后其原有的子节点如何处理:
- 一种方式是直接找到删除的中间节点的原父节点,让它成为其子节点的新父节点,即所谓爷爷收养孙子;
- 一种是提升某一个子节点(所谓长子)为新的父节点,将其它子节点的父节点重新指向这个新父节点,所谓父业子承;
- 还有一种就是把相关的中间节点的子树全部删掉,这就是灭门了……
删除子树
删除邻接表的一个子树,一般是知道父节点,然后递归找到所有子节点并一一删除。这也能通过一个 ON DELETE CASCADE 级联删除的外键约束来自动完成这个过程。
WITH RECURSIVE T1 AS (
SELECT * FROM category T0 WHERE
T0.name = 'TELEVISIONS' -- ANCHOR MEMBER
UNION ALL
SELECT T2.category_id,T2.name,T2.parent FROM category T2, T1 -- RECURSIVE MEMBER
WHERE T2.parent = T1.category_id
)
DELETE FROM category WHERE category_id IN (SELECT category_id FROM T1);
总结
在纯 SQL 中使用邻接表模型是比较直观,但隐含一些困难的。我们需要给邻接表加上限制以防止前面描述到的问题,其中一些限制可以通过使用客户端代码或存储过程来解决。由于需要用到递归来实现子节点的查询,对于数据量比较大的树,其查询效率会比较低。
路径枚举模型
路径枚举(Path Enumeration)模型通过一个字符串字段记录保存从根节点到本节点经过的所有节点枚举。
创建一个表,为了方便就把人员信息和路径信息放在一起了。
CREATE TABLE Personnel_OrgChart(
emp_name CHAR(10) NOT NULL,
emp_id CHAR(1) NOT NULL PRIMARY KEY,
path_string VARCHAR(500) NOT NULL
);
INSERT INTO Personnel_OrgChart
VALUES('Albert','A','A'),('Bert','B','AB'),
('Chuck','C','AC'),('Donna','D','ACD'),
('Eddie','E','ACE'),('Fred','F','ACF');
SELECT * FROM Personnel_OrgChart ORDER BY emp_id;
+----------+--------+-------------+
| emp_name | emp_id | path_string |
+----------+--------+-------------+
| Albert | A | A |
| Bert | B | AB |
| Chuck | C | AC |
| Donna | D | ACD |
| Eddie | E | ACE |
| Fred | F | ACF |
+----------+--------+-------------+
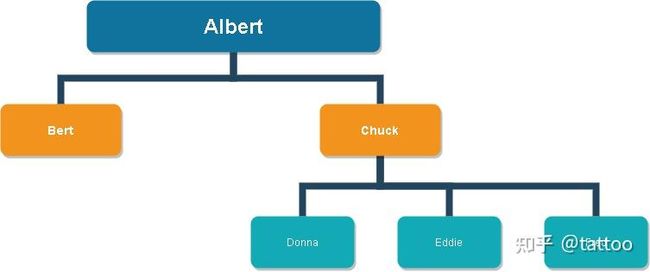
路径枚举模型的特点是通过将所有祖先的信息联合成一个字符串,并保存为每个节点的一个属性。字符串的构建根据喜好或需要。上面的 path_string 也可以写成’A/C/E’ 或’A_C_E’ 这样的。emp_id 也可以是数字,例如 ‘1/3/5’ 。
路径枚举模型的问题与邻接表类似,在没有限制的情况下可能出现’ACEA’ 这样的回环路径,删除一个中间节点可能造成孤立子树,而且插入中间节点会导致多个节点的路径需要修改。
获取路径枚举表子树
一般开发者会直接的使用下面的语句来获取某个子树:
SELECT * FROM Personnel_OrgChart WHERE path_string LIKE '%C%';
+----------+--------+-------------+
| emp_name | emp_id | path_string |
+----------+--------+-------------+
| Chuck | C | AC |
| Donna | D | ACD |
| Eddie | E | ACE |
| Fred | F | ACF |
+----------+--------+-------------+
这里的问题是使用通配符 % 查找会扫描整个表,对于数据很多的表来说速度就很慢了。
获取路径枚举表父节点
SELECT P2.*
FROM Personnel_OrgChart AS P1,
Personnel_OrgChart AS P2
WHERE P1.emp_id = 'F'
AND POSITION(P2.path_string IN P1.path_string)= 1;
+----------+--------+-------------+
| emp_name | emp_id | path_string |
+----------+--------+-------------+
| Albert | A | A |
| Chuck | C | AC |
| Fred | F | ACF |
+----------+--------+-------------+
添加节点
在路径枚举表中添加叶节点比较简单,直接插入一条数据即可:
INSERT INTO Personnel_OrgChart VALUES('Gary','G','ABG');
但是如果要插入到某个节点之前,那么被插入的节点和其子节点的路径都需要修改,例如在 Chuck 上面插入 Gary 作为 Chuck 父节点:
INSERT INTO Personnel_OrgChart VALUES('Gary','G','AG');
UPDATE Personnel_OrgChart SET path_string = REPLACE(path_string, 'AC', 'AGC') WHERE path_string LIKE 'AC%';
SELECT * FROM Personnel_OrgChart;
+----------+--------+-------------+
| emp_name | emp_id | path_string |
+----------+--------+-------------+
| Albert | A | A |
| Bert | B | AB |
| Chuck | C | AGC |
| Donna | D | AGCD |
| Eddie | E | AGCE |
| Fred | F | AGCF |
| Gary | G | AG |
+----------+--------+-------------+
删除节点
与添加节点类似,删除叶节点比较简单,直接删除记录即可:
DELETE FROM Personnel_OrgChart WHERE path_string = 'AGCD';
但如果要删除某个中间节点,例如 Chuck,那么我们与邻接表一样需要确定原来 Chuck 的子节点们该如何处理。
- 一种方式是直接找到删除的中间节点的原父节点,让它成为其子节点的新父节点,即所谓爷爷收养孙子;
- 一种是提升某一个子节点(所谓长子)为新的父节点,将其它子节点的父节点重新指向这个新父节点,所谓父业子承;
- 还有一种就是把相关的中间节点的子树全部删掉,这就是灭门了……
以下 SQL 采用第一种方式处理:
DELETE FROM Personnel_OrgChart WHERE emp_id = 'C';
UPDATE Personnel_OrgChart SET path_string = REPLACE(path_string, 'C', '') WHERE path_string LIKE '%C%';
SELECT * FROM Personnel_OrgChart;
+----------+--------+-------------+
| emp_name | emp_id | path_string |
+----------+--------+-------------+
| Albert | A | A |
| Bert | B | AB |
| Donna | D | AGD |
| Eddie | E | AGE |
| Fred | F | AGF |
| Gary | G | AG |
+----------+--------+-------------+
删除子树
知道某个节点,删除其子树与获取子树方式类似,使用 % 通配符即可:
DELETE FROM Personnel_OrgChart WHERE path_string LIKE '%G%';
将已有邻接表转换为路径枚举表
我们实际的 OA 数据库里有一个汇报关系表,是一个邻接表模型,它大致的字段如下(为了方便我用的临时表 APPROVAL_GROUP_TEMP):
CREATE TABLE `APPROVAL_GROUP_TEMP` (
`ID` decimal(8,0) NOT NULL,
`FATHERID` decimal(8,0) DEFAULT NULL, -- 上级ID
`APPROVALGROUPNAME` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL, -- 名称
`SHOWFLAG` decimal(1,0) DEFAULT '1', -- 状态(1::启用,0:禁用,2:删除)
PRIMARY KEY (`ID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
我们构建一个路径枚举表:
CREATE TABLE `AG_PathEnum` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`node` varchar(100) NOT NULL, -- 名称
`nodeid` INT(10) COMMENT '节点ID',
`path_string` VARCHAR(500) NOT NULL COMMENT '相隔层级,>=1',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
然后使用下面的 CTE SQL 将邻接表的关系转换到路径枚举表里面(只转换启用的 SHOWFLAG=1):
INSERT INTO AG_PathEnum(node,nodeid,path_string)
WITH RECURSIVE T1(node,nodeid,path_string) AS
(
SELECT
T0.APPROVALGROUPNAME AS node,
T0.ID AS nodeid,
CAST(T0.ID AS char(500)) AS path_string
FROM APPROVAL_GROUP_TEMP AS T0 WHERE T0.SHOWFLAG = 1
UNION ALL
SELECT
C.APPROVALGROUPNAME AS node,
C.ID AS nodeid,
CONCAT(T1.path_string,"/",C.ID) AS path_string
FROM APPROVAL_GROUP_TEMP C, T1
WHERE C.FATHERID = T1.nodeid AND C.SHOWFLAG = 1
)
SELECT * FROM T1 WHERE T1.path_string LIKE '16060%' GROUP BY T1.nodeid,T1.node,T1.path_string ORDER BY T1.nodeid
运行后:
SELECT * FROM AG_PathEnum;
+-----+---------------------------------+--------+-------------------------------------------------+
| id | node | nodeid | path_string |
+-----+---------------------------------+--------+-------------------------------------------------+
| 1 | 公司总部 | 16060 | 16060 |
| 2 | 研发中心 | 16062 | 16060/16062 |
| 3 | 发行中心 | 16064 | 16060/16064 |
| 4 | 管理中心 | 16066 | 16060/16066 |
| 5 | 人力资源部 | 16700 | 16060/16066/16883/16700 |
| 6 | 法务部 | 16701 | 16060/16066/16883/16701 |
| 7 | 财务部 | 16702 | 16060/16066/16883/16702 |
| 8 | 总裁办 | 16705 | 16060/16066/16705 |
| 9 | 发行技术部 | 16711 | 16060/16064/16711 |
| 10 | 创新中心 | 16721 | 16060/16721 |
| 11 | 原创IP部 | 16789 | 16060/16721/16789 |
| 12 | BU财务管理部 | 16871 | 16060/16066/16883/16702/16871 |
| 13 | 直属员工 | 16880 | 16060/16880 |
| 14 | 直属员工 | 16881 | 16060/16062/16881 |
| 15 | 某某某直属员工 | 16883 | 16060/16066/16883 |
| 16 | 直属员工 | 16885 | 16060/16066/16883/16701/16885 |
| 17 | 直属员工 | 16886 | 16060/16066/16883/16702/16886 |
| 18 | 直属员工 | 16889 | 16060/16066/16705/16889 |
| 19 | 直属员工 | 16895 | 16060/16064/16711/16895 |
| 20 | 直属员工 | 16904 | 16060/16721/16904 |
| 21 | 证券部 | 17100 | 16060/16066/16883/17100 |
| 22 | 直属员工 | 17101 | 16060/16066/16883/17100/17101 |
| 23 | 商务部 | 17180 | 16060/16064/17180 |
| 24 | 直属员工 | 17181 | 16060/16064/17180/17181 |
| 25 | 公共关系与政府事务部 | 17400 | 16060/16066/16883/17400 |
| 26 | 采购部 | 17540 | 16060/16066/16883/17540 |
| 27 | 直属员工 | 17541 | 16060/16066/16883/17540/17541 |
| 28 | 行政部 | 17728 | 16060/16066/16883/16700/17728 |
| 29 | 人力信息部 | 17750 | 16060/16066/16883/16700/17750 |
| 30 | 直属员工 | 17751 | 16060/16066/16883/16700/17750/17751 |
| 31 | 薪酬福利部 | 17752 | 16060/16066/16883/16700/17752 |
| 32 | 直属员工 | 17753 | 16060/16066/16883/16700/17752/17753 |
| 33 | 培训发展部 | 17756 | 16060/16066/16883/16700/17756 |
| 34 | 直属员工 | 17757 | 16060/16066/16883/16700/17756/17757 |
| 35 | 企业文化部 | 18566 | 16060/16066/16883/16700/18566 |
| 36 | 直属员工 | 18567 | 16060/16066/16883/16700/18566/18567 |
| 37 | 渠道部 | 18660 | 16060/16064/36071/20640/18660 |
| 38 | 公益部 | 18780 | 16060/16066/16883/18780 |
| 39 | 直属员工 | 18781 | 16060/16066/16883/18780/18781 |
| 40 | 蓝图 | 18840 | 16060/18840 |
| 41 | 直属员工 | 18841 | 16060/18840/18841 |
| 42 | 事业支援中心 | 18842 | 16060/18840/38840/18842 |
| 43 | 直属员工 | 18843 | 16060/18840/38840/18842/18843 |
| 44 | 某某神奇项目组 | 18854 | 16060/16062/21322/18854 |
| 45 | 直属员工 | 18855 | 16060/16062/21322/18854/18855 |
| 46 | 程序组 | 18902 | 16060/16062/21322/18854/38854/18902 |
| 47 | 直属员工 | 18903 | 16060/16062/21322/18854/38854/18902/38906/18903 |
| 48 | 策划组 | 18904 | 16060/16062/21322/18854/38856/18904 |
| 49 | 直属员工 | 18905 | 16060/16062/21322/18854/38856/18904/18905 |
| 50 | 美术组 | 18906 | 16060/16062/21322/18854/38856/58855/18906 |
| 51 | 直属员工 | 18907 | 16060/16062/21322/18854/38856/58855/18906/18907 |
-- ...以下省略
总结
路径枚举的设计方式能够很方便地根据节点的层级排序,因为路径中分隔两边的节点间的距离永远是 1,因此通过比较路径字符串长度就能知道层级的深浅。但也有如下缺点:
1、不能确保路径的格式总是正确或者路径中的节点确实存在(中间节点被删除的情况,无外键约束);
2、要依赖高级程序代码来维护路径中的字符串,并且验证字符串的正确性的开销很大;
3、路径 VARCHAR 的长度很难确定。无论 VARCHAR 的长度设为多大,都存在不能够无限扩展的情况。
闭包表模型
闭包表(Closure Table)是一种通过空间换时间的模型,它是用一个专门的关系表(其实这也是我们推荐的归一化方式)来记录树上节点之间的层级关系以及距离。
CREATE TABLE `NodeInfo` (
`node_id` INT NOT NULL AUTO_INCREMENT,
`node_name` VARCHAR (255),
PRIMARY KEY (`node_id`)
) DEFAULT CHARSET = utf8mb4;
CREATE TABLE `NodeRelation` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`ancestor` INT(10) UNSIGNED NOT NULL DEFAULT '0' COMMENT '祖先节点',
`descendant` INT(10) UNSIGNED NOT NULL DEFAULT '0' COMMENT '后代节点',
`distance` TINYINT(3) UNSIGNED NOT NULL DEFAULT '0' COMMENT '相隔层级,>=1',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_anc_desc` (`ancestor`,`descendant`),
KEY `idx_desc` (`descendant`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT = '节点关系表'
为了防止插入数据出错,我们需要一个存储过程:
CREATE DEFINER = `root`@`localhost` PROCEDURE `AddNode`(`_parent_name` varchar(255),`_node_name` varchar(255))
BEGIN
DECLARE _ancestor INT(10) UNSIGNED;
DECLARE _descendant INT(10) UNSIGNED;
DECLARE _parent INT(10) UNSIGNED;
IF NOT EXISTS(SELECT node_id From NodeInfo WHERE node_name = _node_name)
THEN
INSERT INTO NodeInfo (node_name) VALUES(_node_name);
SET _descendant = (SELECT node_id FROM NodeInfo WHERE node_name = _node_name);
INSERT INTO NodeRelation (ancestor,descendant,distance) VALUES(_descendant,_descendant,0);
IF EXISTS (SELECT node_id FROM NodeInfo WHERE node_name = _parent_name)
THEN
SET _parent = (SELECT node_id FROM NodeInfo WHERE node_name = _parent_name);
INSERT INTO NodeRelation (ancestor,descendant,distance) SELECT ancestor,_descendant,distance+1 FROM NodeRelation WHERE descendant = _parent;
END IF;
END IF;
END;
然后我们插入一些数据,这里以在论坛里发帖回帖为例:
CALL OrgAndUser.AddNode(NULL,'这是主贴');
CALL OrgAndUser.AddNode('这是主贴','回复主贴1');
CALL OrgAndUser.AddNode('回复主贴1','回复:回复主贴1');
CALL OrgAndUser.AddNode('这是主贴','回复:这是主贴,啥意思');
CALL OrgAndUser.AddNode('这是主贴','回复:挺有意思');
CALL OrgAndUser.AddNode('回复:挺有意思','Reply:回复:挺有意思');
CALL OrgAndUser.AddNode('回复:这是主贴,啥意思','第3层?');
CALL OrgAndUser.AddNode('第3层?','不对,我才是第3层');
SELECT * FROM NodeInfo;
+---------+-----------------------------------+
| node_id | node_name |
+---------+-----------------------------------+
| 1 | 这是主贴 |
| 2 | 回复主贴1 |
| 3 | 回复:回复主贴1 |
| 4 | 回复:这是主贴,啥意思 |
| 5 | 回复:挺有意思 |
| 6 | Reply:回复:挺有意思 |
| 7 | 第3层? |
| 8 | 不对,我才是第3层 |
+---------+-----------------------------------+

前面的存储过程会在关系表里插入每条贴子与自身和它上级贴子的关系以及距离:
SELECT * FROM NodeRelation;
+----+----------+------------+----------+
| id | ancestor | descendant | distance |
+----+----------+------------+----------+
| 1 | 1 | 1 | 0 |
| 2 | 2 | 2 | 0 |
| 3 | 1 | 2 | 1 |
| 4 | 3 | 3 | 0 |
| 5 | 2 | 3 | 1 |
| 6 | 1 | 3 | 2 |
| 8 | 4 | 4 | 0 |
| 9 | 1 | 4 | 1 |
| 10 | 5 | 5 | 0 |
| 11 | 1 | 5 | 1 |
| 12 | 6 | 6 | 0 |
| 13 | 5 | 6 | 1 |
| 14 | 1 | 6 | 2 |
| 16 | 7 | 7 | 0 |
| 17 | 4 | 7 | 1 |
| 18 | 1 | 7 | 2 |
| 20 | 8 | 8 | 0 |
| 21 | 7 | 8 | 1 |
| 22 | 4 | 8 | 2 |
| 23 | 1 | 8 | 3 |
+----+----------+------------+----------+
获取闭包表全树或子树
SELECT n3.node_name FROM NodeInfo n1
INNER JOIN NodeRelation n2 ON n1.node_id = n2.ancestor
INNER JOIN NodeInfo n3 ON n2.descendant = n3.node_id
WHERE n1.node_id = 1 AND n2.distance != 0;
+-----------------------------------+
| node_name |
+-----------------------------------+
| 回复主贴1 |
| 回复:回复主贴1 |
| 回复:这是主贴,啥意思 |
| 回复:挺有意思 |
| Reply:回复:挺有意思 |
| 第3层? |
| 不对,我才是第3层 |
+-----------------------------------+
SELECT n3.node_name FROM NodeInfo n1
INNER JOIN NodeRelation n2 ON n1.node_id = n2.ancestor
INNER JOIN NodeInfo n3 ON n2.descendant = n3.node_id
WHERE n1.node_name = '回复:这是主贴,啥意思' AND n2.distance != 0;
+---------------------------+
| node_name |
+---------------------------+
| 第3层? |
| 不对,我才是第3层 |
+---------------------------+
通过关联表的父子关系,去掉自指的记录,使用内连接获取所有子节点。
获取闭包表叶节点
SELECT n1.node_id, n1.node_name FROM NodeInfo n1
INNER JOIN NodeRelation n2 ON n1.node_id = n2.ancestor
GROUP BY n1.node_id, n1.node_name
HAVING COUNT(n2.ancestor) = 1;
+---------+-----------------------------+
| node_id | node_name |
+---------+-----------------------------+
| 3 | 回复:回复主贴1 |
| 6 | Reply:回复:挺有意思 |
| 8 | 不对,我才是第3层 |
+---------+-----------------------------+
叶节点的特征是没有子节点,所以它的 ID 只会在关联表的 ancestor 字段出现一次,就是自指的那一次。
获取闭包表父节点
SELECT n1.* FROM NodeInfo AS n1
INNER JOIN NodeRelation n2 on n1.node_id = n2.ancestor
WHERE n2.descendant = 8;
+---------+-----------------------------------+
| node_id | node_name |
+---------+-----------------------------------+
| 8 | 不对,我才是第3层 |
| 7 | 第3层? |
| 4 | 回复:这是主贴,啥意思 |
| 1 | 这是主贴 |
+---------+-----------------------------------+
从关系表来倒查,因为关系表里每个节点与其所有上级的关系都记录了。
添加节点
参考前面的存储过程 AddNode(_parent_name, _node_name)。
删除节点
删除叶节点比较简单,除了在 NodeInfo 表里删除一条记录以外,在关系表 NodeRelation 里把 descendant 值为该叶节点 node_id 的记录都删掉。
DELETE FROM NodeInfo WHERE node_id = 8;
DELETE FROM NodeRelation WHERE descendant = 8;
但是如果要删除中间节点,与前面讨论过的模型一样,需要确定如何处理其子节点或子树。
- 一种方式是直接找到删除的中间节点的原父节点,让它成为其子节点的新父节点,即所谓爷爷收养孙子;
- 一种是提升某一个子节点(所谓长子)为新的父节点,将其它子节点的父节点重新指向这个新父节点,所谓父业子承;
- 还有一种就是把相关的中间节点的子树全部删掉,这就是灭门了……
删除子树
DELETE FROM NodeInfo WHERE node_id = 4;
DELETE FROM NodeRelation AS n1 WHERE n1.descendant IN (SELECT a.descendant FROM (SELECT n2.descendant FROM NodeRelation AS n2 WHERE n2.ancestor = 4) AS a);
SELECT * FROM NodeRelation;
+----+----------+------------+----------+
| id | ancestor | descendant | distance |
+----+----------+------------+----------+
| 1 | 1 | 1 | 0 |
| 2 | 2 | 2 | 0 |
| 3 | 1 | 2 | 1 |
| 4 | 3 | 3 | 0 |
| 5 | 2 | 3 | 1 |
| 6 | 1 | 3 | 2 |
| 10 | 5 | 5 | 0 |
| 11 | 1 | 5 | 1 |
| 12 | 6 | 6 | 0 |
| 13 | 5 | 6 | 1 |
| 14 | 1 | 6 | 2 |
+----+----------+------------+----------+
注意第二条删除语句里,不能直接使用 DELETE FROM NodeRelation AS n1 WHERE n1.descendant IN (SELECT n2.descendant FROM NodeRelation AS n2 WHERE n2.ancestor = 4); ,MySQL 会报错:ERROR 1093 (HY000): You can't specify target table 'n1' for update in FROM clause。这是因为在 MySQL 中,不能通过嵌套子查询来直接删除或者修改记录,需要通过别名来指定嵌套子查询作为一个临时表。
将已有邻接表转换为闭包表
我们实际的 OA 数据库里有一个汇报关系表,是一个邻接表模型,它大致的字段如下(为了方便我用的临时表 APPROVAL_GROUP_TEMP):
CREATE TABLE `APPROVAL_GROUP_TEMP` (
`ID` decimal(8,0) NOT NULL,
`FATHERID` decimal(8,0) DEFAULT NULL, -- 上级ID
`APPROVALGROUPNAME` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL, -- 名称
`SHOWFLAG` decimal(1,0) DEFAULT '1', -- 状态(1::启用,0:禁用,2:删除)
PRIMARY KEY (`ID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
我们构建一个闭包表:
CREATE TABLE `AG_Closure` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`node` varchar(100) NOT NULL, -- 名称
`ancestor` INT(10) UNSIGNED NOT NULL DEFAULT '0' COMMENT '祖先节点',
`descendant` INT(10) UNSIGNED NOT NULL DEFAULT '0' COMMENT '后代节点',
`distance` TINYINT(3) UNSIGNED NOT NULL DEFAULT '0' COMMENT '相隔层级,>=1',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_anc_desc` (`ancestor`,`descendant`),
KEY `idx_desc` (`descendant`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
然后使用下面的 CTE SQL 将邻接表的关系转换到闭包表里面(只转换启用的 SHOWFLAG=1):
INSERT INTO AG_Closure(node,ancestor,descendant,distance)
WITH RECURSIVE T1(node,ancestor,descendant,distance) AS
(
SELECT
APPROVALGROUPNAME AS node,
ID AS ancestor,
ID AS descendant,
0 AS distance
FROM APPROVAL_GROUP_TEMP WHERE SHOWFLAG=1
UNION ALL
SELECT
C.APPROVALGROUPNAME AS node,
T1.ancestor AS ancestor,
C.ID AS descendant,
T1.distance + 1 AS distance
FROM APPROVAL_GROUP_TEMP C, T1
WHERE C.FATHERID = T1.descendant AND C.SHOWFLAG = 1
)
SELECT * FROM T1 ORDER BY T1.descendant
运行后:
SELECT * FROM AG_Closure;
+------+---------------------------------+----------+------------+----------+
| id | node | ancestor | descendant | distance |
+------+---------------------------------+----------+------------+----------+
| 1 | 公司总部 | 16060 | 16060 | 0 |
| 2 | 研发中心 | 16062 | 16062 | 0 |
| 3 | 研发中心 | 16060 | 16062 | 1 |
| 4 | 发行中心 | 16064 | 16064 | 0 |
| 5 | 发行中心 | 16060 | 16064 | 1 |
| 6 | 管理中心 | 16066 | 16066 | 0 |
| 7 | 管理中心 | 16060 | 16066 | 1 |
| 8 | 人力资源部 | 16700 | 16700 | 0 |
| 9 | 人力资源部 | 16883 | 16700 | 1 |
| 10 | 人力资源部 | 16066 | 16700 | 2 |
| 11 | 人力资源部 | 16060 | 16700 | 3 |
| 12 | 法务部 | 16701 | 16701 | 0 |
| 13 | 法务部 | 16883 | 16701 | 1 |
| 14 | 法务部 | 16066 | 16701 | 2 |
| 15 | 法务部 | 16060 | 16701 | 3 |
| 16 | 财务部 | 16702 | 16702 | 0 |
| 17 | 财务部 | 16883 | 16702 | 1 |
| 18 | 财务部 | 16066 | 16702 | 2 |
| 19 | 财务部 | 16060 | 16702 | 3 |
| 20 | 总裁办 | 16705 | 16705 | 0 |
| 21 | 总裁办 | 16066 | 16705 | 1 |
| 22 | 总裁办 | 16060 | 16705 | 2 |
| 23 | 发行技术部 | 16711 | 16711 | 0 |
| 24 | 发行技术部 | 16064 | 16711 | 1 |
| 25 | 发行技术部 | 16060 | 16711 | 2 |
| 26 | 创新中心 | 16721 | 16721 | 0 |
| 27 | 创新中心 | 16060 | 16721 | 1 |
| 28 | 原创IP部 | 16789 | 16789 | 0 |
| 29 | 原创IP部 | 16721 | 16789 | 1 |
| 30 | 原创IP部 | 16060 | 16789 | 2 |
| 31 | BU财务管理部 | 16871 | 16871 | 0 |
| 32 | BU财务管理部 | 16702 | 16871 | 1 |
| 33 | BU财务管理部 | 16883 | 16871 | 2 |
| 34 | BU财务管理部 | 16066 | 16871 | 3 |
| 35 | BU财务管理部 | 16060 | 16871 | 4 |
| 36 | 直属员工 | 16880 | 16880 | 0 |
| 37 | 直属员工 | 16060 | 16880 | 1 |
| 38 | 直属员工 | 16881 | 16881 | 0 |
| 39 | 直属员工 | 16062 | 16881 | 1 |
| 40 | 直属员工 | 16060 | 16881 | 2 |
| 41 | 某某某直属员工 | 16883 | 16883 | 0 |
| 42 | 某某某直属员工 | 16066 | 16883 | 1 |
| 43 | 某某某直属员工 | 16060 | 16883 | 2 |
-- ...以下省略
总结
闭包表模型通过使用关系表存储树结构的整个路径,从而能够在不使用递归的情况下快速的查询。但存储整个路径会产生巨大的存储需求,从而成倍地增加存储大小。添加节点的复杂度较高,需要重新计算受影响的节点前后代或距离。
参考:
Tree 闭包表
数据库 - 闭包表
嵌套集模型
嵌套集(Nested Set)模型的算法也叫做预排序遍历树算法 MPTT(Modified Preorder Tree Taversal)。
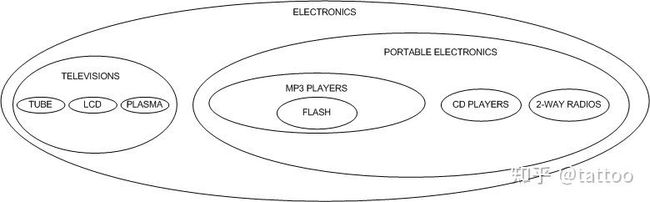
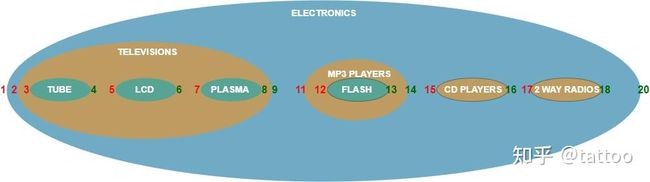
在嵌套集的表里我们会有 lft 和 rgt 两个字段,分别用来记录遍历整个集合或整棵树时,一个节点的左右边到根节点左边的距离。
CREATE TABLE nested_category (
category_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(20) NOT NULL,
lft INT NOT NULL,
rgt INT NOT NULL
);
INSERT INTO nested_category VALUES
(1,'ELECTRONICS',1,20),(2,'TELEVISIONS',2,9),
(3,'TUBE',3,4),(4,'LCD',5,6),(5,'PLASMA',7,8),
(6,'PORTABLE ELECTRONICS',10,19),(7,'MP3 PLAYERS',11,14),
(8,'FLASH',12,13),(9,'CD PLAYERS',15,16),
(10,'2 WAY RADIOS',17,18);
SELECT * FROM nested_category ORDER BY category_id;
+-------------+----------------------+-----+-----+
| category_id | name | lft | rgt |
+-------------+----------------------+-----+-----+
| 1 | ELECTRONICS | 1 | 20 |
| 2 | TELEVISIONS | 2 | 9 |
| 3 | TUBE | 3 | 4 |
| 4 | LCD | 5 | 6 |
| 5 | PLASMA | 7 | 8 |
| 6 | PORTABLE ELECTRONICS | 10 | 19 |
| 7 | MP3 PLAYERS | 11 | 14 |
| 8 | FLASH | 12 | 13 |
| 9 | CD PLAYERS | 15 | 16 |
| 10 | 2 WAY RADIOS | 17 | 18 |
+-------------+----------------------+-----+-----+
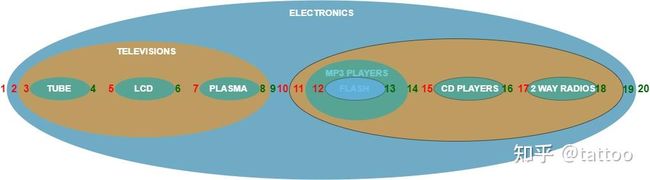
如果我们用集合的图来看的话,根节点左边初始为 1,那么从左向右划过所有子集,碰到集合边缘时计数加 1,各个子集(即节点)的左右边的数就一目了然的出来了。
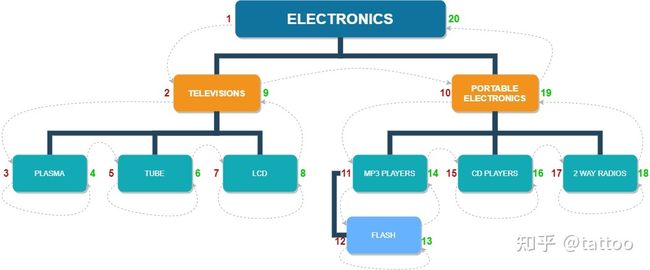
换成用树形结构展示,那么从根节点左边沿着树枝向下走,碰到一个子节点就该子节点左边就加 1,若子节点为叶子节点时就转到节点右边向上、向右走,子节点右边也加 1,这样遍历整棵树,每个节点左右边的数值也就出来了。
获取嵌套集全树或子树
SELECT node.name
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND parent.name = 'ELECTRONICS'
ORDER BY node.lft;
+----------------------+
| name |
+----------------------+
| ELECTRONICS |
| TELEVISIONS |
| TUBE |
| LCD |
| PLASMA |
| PORTABLE ELECTRONICS |
| MP3 PLAYERS |
| FLASH |
| CD PLAYERS |
| 2 WAY RADIOS |
+----------------------+
-- 查询子树
SELECT node.name
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND parent.name = 'PORTABLE ELECTRONICS'
ORDER BY node.lft;
+----------------------+
| name |
+----------------------+
| PORTABLE ELECTRONICS |
| MP3 PLAYERS |
| FLASH |
| CD PLAYERS |
| 2 WAY RADIOS |
+----------------------+
只需要查询左右值在父节点左右值之间的记录即可。
获取嵌套集父节点
SELECT parent.name FROM
nested_category AS node,
nested_category AS parent
WHERE node.lft > parent.lft AND node.rgt < parent.rgt
AND node.name = 'LCD'
ORDER BY parent.lft DESC
LIMIT 1
+-------------+
| name |
+-------------+
| TELEVISIONS |
+-------------+
子节点的左右值一定在父节点的左右值之间。这里只是获取了直接上级节点,如果去掉 LIMIT 1,那么此节点的上级节点就都可以获取。
获取嵌套集叶节点
SELECT name
FROM nested_category
WHERE rgt = lft + 1;
+--------------+
| name |
+--------------+
| TUBE |
| LCD |
| PLASMA |
| FLASH |
| CD PLAYERS |
| 2 WAY RADIOS |
+--------------+
叶子节点的右值只比左值多步长的值(这里是 1)。
获取嵌套集完整单路径
SELECT parent.name
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND node.name = 'FLASH'
ORDER BY parent.lft;
+----------------------+
| name |
+----------------------+
| ELECTRONICS |
| PORTABLE ELECTRONICS |
| MP3 PLAYERS |
| FLASH |
+----------------------+
可以看到与邻接表相比,它不需要递归。
获取嵌套集节点深度
SELECT node.name, (COUNT(parent.name) - 1) AS depth
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
GROUP BY node.name
ORDER BY depth;
+----------------------+-------+
| name | depth |
+----------------------+-------+
| ELECTRONICS | 0 |
| PORTABLE ELECTRONICS | 1 |
| TELEVISIONS | 1 |
| 2 WAY RADIOS | 2 |
| CD PLAYERS | 2 |
| MP3 PLAYERS | 2 |
| PLASMA | 2 |
| LCD | 2 |
| TUBE | 2 |
| FLASH | 3 |
+----------------------+-------+
通过按名称归并后对父节点数量进行计数,我们可以获得节点的深度值。我们还可以通过这种方式来具象化的展示节点关系:
SELECT CONCAT( REPEAT('--', COUNT(parent.name) - 1), node.name) AS name, node.lft
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
GROUP BY node.name, node.lft
ORDER BY node.lft;
+------------------------+-----+
| name | lft |
+------------------------+-----+
| ELECTRONICS | 1 |
| --TELEVISIONS | 2 |
| ----TUBE | 3 |
| ----LCD | 5 |
| ----PLASMA | 7 |
| --PORTABLE ELECTRONICS | 10 |
| ----MP3 PLAYERS | 11 |
| ------FLASH | 12 |
| ----CD PLAYERS | 15 |
| ----2 WAY RADIOS | 17 |
+------------------------+-----+
获取子树深度
SELECT node.name, (COUNT(parent.name) - (sub_tree.depth2 + 1)) AS depth
FROM nested_category AS node,
nested_category AS parent,
nested_category AS sub_parent,
(
SELECT node2.name, (COUNT(parent2.name) - 1) AS depth2
FROM nested_category AS node2,
nested_category AS parent2
WHERE node2.lft BETWEEN parent2.lft AND parent2.rgt
AND node2.name = 'PORTABLE ELECTRONICS'
GROUP BY node2.name
ORDER BY depth2
) AS sub_tree
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND node.lft BETWEEN sub_parent.lft AND sub_parent.rgt
AND sub_parent.name = sub_tree.name
GROUP BY node.name, sub_tree.depth2
ORDER BY depth;
+----------------------+-------+
| name | depth |
+----------------------+-------+
| PORTABLE ELECTRONICS | 0 |
| 2 WAY RADIOS | 1 |
| CD PLAYERS | 1 |
| MP3 PLAYERS | 1 |
| FLASH | 2 |
+----------------------+-------+
这里用了两个自连接实现了获取任意子节点的子树的功能,对根节点也适用。
如果给上面的 SQL 加上 HAVING depth < 2,我们就可以获得某个节点的所有子节点但不包含更深的孙子节点的结果:
SELECT node.name, (COUNT(parent.name) - (sub_tree.depth2 + 1)) AS depth
FROM nested_category AS node,
nested_category AS parent,
nested_category AS sub_parent,
(
SELECT node2.name, (COUNT(parent2.name) - 1) AS depth2
FROM nested_category AS node2,
nested_category AS parent2
WHERE node2.lft BETWEEN parent2.lft AND parent2.rgt
AND node2.name = 'PORTABLE ELECTRONICS'
GROUP BY node2.name
ORDER BY depth2
) AS sub_tree
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND node.lft BETWEEN sub_parent.lft AND sub_parent.rgt
AND sub_parent.name = sub_tree.name
GROUP BY node.name, sub_tree.depth2
HAVING depth < 2
ORDER BY depth;
+----------------------+-------+
| name | depth |
+----------------------+-------+
| PORTABLE ELECTRONICS | 0 |
| 2 WAY RADIOS | 1 |
| CD PLAYERS | 1 |
| MP3 PLAYERS | 1 |
+----------------------+-------+
这种功能对只展开第一层而不展开后续层次的情况很有用。
以上的 SQL 在 MySQL 8 中也可以用 CTE 语法来写:
WITH sub_tree AS (SELECT node2.name, (COUNT(parent2.name) - 1) AS depth2
FROM nested_category AS node2,
nested_category AS parent2
WHERE node2.lft BETWEEN parent2.lft AND parent2.rgt
AND node2.name = 'PORTABLE ELECTRONICS'
GROUP BY node2.name
ORDER BY depth2)
SELECT node.name, (COUNT(parent.name) - (sub_tree.depth2 + 1)) AS depth
FROM nested_category AS node,
nested_category AS parent,
nested_category AS sub_parent,
sub_tree
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND node.lft BETWEEN sub_parent.lft AND sub_parent.rgt
AND sub_parent.name = sub_tree.name
GROUP BY node.name, sub_tree.depth2
HAVING depth < 2
ORDER BY depth;
添加节点
嵌套集的节点添加比邻接表复杂不少,因为需要重新计算受影响的节点左右值。这里我们有一个存储过程,它根据父节点 ID 和新节点属性来添加新节点并重新计算受影响的节点左右值。
CREATE DEFINER = `root`@`localhost` PROCEDURE `AddNestedSetNode`(`parent_id` INT,`node_name` VARCHAR(20))
BEGIN
DECLARE _rgt INT;
DECLARE step INT;
SET step = 1;
SET autocommit=0;
IF EXISTS(SELECT category_id From nested_category WHERE category_id = parent_id)
THEN
START TRANSACTION;
SET _rgt = (SELECT rgt FROM nested_category WHERE category_id = parent_id);
UPDATE nested_category SET rgt = rgt + 2 * step WHERE rgt >= _rgt;
UPDATE nested_category SET lft = lft + 2 * step WHERE lft >= _rgt;
INSERT INTO nested_category(name, lft, rgt) values(node_name, _rgt, _rgt + step);
COMMIT;
END IF;
END;
我们尝试添加一个根节点下的子节点:
CALL OrgAndUser.AddNestedSetNode(1,'GAME CONSOLE');
SELECT * FROM nested_category;
+-------------+----------------------+-----+-----+
| category_id | name | lft | rgt |
+-------------+----------------------+-----+-----+
| 1 | ELECTRONICS | 1 | 22 |
| 2 | TELEVISIONS | 2 | 9 |
| 3 | TUBE | 3 | 4 |
| 4 | LCD | 5 | 6 |
| 5 | PLASMA | 7 | 8 |
| 6 | PORTABLE ELECTRONICS | 10 | 19 |
| 7 | MP3 PLAYERS | 11 | 14 |
| 8 | FLASH | 12 | 13 |
| 9 | CD PLAYERS | 15 | 16 |
| 10 | 2 WAY RADIOS | 17 | 18 |
| 11 | GAME CONSOLE | 20 | 21 |
+-------------+----------------------+-----+-----+
再添加一个 FLASH 的子节点:
CALL OrgAndUser.AddNestedSetNode(8,'ABC FLASH');
SELECT * FROM nested_category;
+-------------+----------------------+-----+-----+
| category_id | name | lft | rgt |
+-------------+----------------------+-----+-----+
| 1 | ELECTRONICS | 1 | 24 |
| 2 | TELEVISIONS | 2 | 9 |
| 3 | TUBE | 3 | 4 |
| 4 | LCD | 5 | 6 |
| 5 | PLASMA | 7 | 8 |
| 6 | PORTABLE ELECTRONICS | 10 | 21 |
| 7 | MP3 PLAYERS | 11 | 16 |
| 8 | FLASH | 12 | 15 |
| 9 | CD PLAYERS | 17 | 18 |
| 10 | 2 WAY RADIOS | 19 | 20 |
| 11 | GAME CONSOLE | 22 | 23 |
| 12 | ABC FLASH | 13 | 14 |
+-------------+----------------------+-----+-----+
SELECT CONCAT( REPEAT('--', COUNT(parent.name) - 1), node.name) AS name, node.lft
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
GROUP BY node.name, node.lft
ORDER BY node.lft;
+------------------------+-----+
| name | lft |
+------------------------+-----+
| ELECTRONICS | 1 |
| --TELEVISIONS | 2 |
| ----TUBE | 3 |
| ----LCD | 5 |
| ----PLASMA | 7 |
| --PORTABLE ELECTRONICS | 10 |
| ----MP3 PLAYERS | 11 |
| ------FLASH | 12 |
| --------ABC FLASH | 13 |
| ----CD PLAYERS | 17 |
| ----2 WAY RADIOS | 19 |
| --GAME CONSOLE | 22 |
+------------------------+-----+
删除节点
删除嵌套集的节点与前面其它模型稍有不同,在我们的例子里,假设删除 PORTABLE ELECTRONICS 节点而其它节点不做改动,我们看看会有什么结果:
仅以 lft 和 rgt 数值来说,原来的 PORTABLE ELECTRONICS 节点的子节点会天然的变为 ELECTRONICS 的子节点而不会出现孤立子树:
下面是删除嵌套集叶节点的存储过程,这里重新计算受影响的节点左右值(其实我们知道不重新计算应该也没影响)。
CREATE DEFINER = `root`@`localhost` PROCEDURE `DeleteNestedSetLeaf`(`node_id` INT)
BEGIN
DECLARE _lft INT;
DECLARE _rgt INT;
DECLARE step INT;
DECLARE width INT;
SET step = 1;
SET autocommit=0;
IF EXISTS(SELECT category_id From nested_category WHERE category_id = node_id AND rgt = lft + step)
THEN
START TRANSACTION;
SELECT rgt,lft,(rgt-lft+step) INTO @_rgt,@_lft,@width FROM nested_category WHERE category_id = node_id;
DELETE FROM nested_category WHERE lft BETWEEN @_lft AND @_rgt;
UPDATE nested_category SET rgt = rgt - @width WHERE rgt > @_rgt;
UPDATE nested_category SET lft = lft - @width WHERE lft > @_rgt;
COMMIT;
END IF;
END;
我们删除前面添加的 GAME CONSOLE(ID 为 11):
CALL OrgAndUser.DeleteNestedSetLeaf(11);
SELECT CONCAT( REPEAT('--', COUNT(parent.name) - 1), node.name) AS name, node.lft
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
GROUP BY node.name, node.lft
ORDER BY node.lft;
+------------------------+-----+
| name | lft |
+------------------------+-----+
| ELECTRONICS | 1 |
| --TELEVISIONS | 2 |
| ----TUBE | 3 |
| ----LCD | 5 |
| ----PLASMA | 7 |
| --PORTABLE ELECTRONICS | 10 |
| ----MP3 PLAYERS | 11 |
| ------FLASH | 12 |
| --------ABC FLASH | 13 |
| ----CD PLAYERS | 17 |
| ----2 WAY RADIOS | 19 |
+------------------------+-----+
删除子树
CREATE DEFINER = `root`@`localhost` PROCEDURE `DeleteNestedSetSubtree`(`node_id` INT)
BEGIN
DECLARE _lft INT;
DECLARE _rgt INT;
DECLARE step INT;
DECLARE width INT;
SET step = 1;
SET autocommit=0;
IF EXISTS(SELECT category_id From nested_category WHERE category_id = node_id)
THEN
START TRANSACTION;
SELECT rgt,lft,(rgt-lft+step) INTO @_rgt,@_lft,@width FROM nested_category WHERE category_id = node_id;
DELETE FROM nested_category WHERE lft BETWEEN @_lft AND @_rgt;
UPDATE nested_category SET rgt = rgt - @width WHERE rgt > @_rgt;
UPDATE nested_category SET lft = lft - @width WHERE lft > @_rgt;
COMMIT;
END IF;
END;
我们删除 FLASH(ID 为 8) 及其子树:
CALL OrgAndUser.DeleteNestedSetSubtree(8);
SELECT CONCAT( REPEAT('--', COUNT(parent.name) - 1), node.name) AS name, node.lft
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
GROUP BY node.name, node.lft
ORDER BY node.lft;
+------------------------+-----+
| name | lft |
+------------------------+-----+
| ELECTRONICS | 1 |
| --TELEVISIONS | 2 |
| ----TUBE | 3 |
| ----LCD | 5 |
| ----PLASMA | 7 |
| --PORTABLE ELECTRONICS | 10 |
| ----MP3 PLAYERS | 11 |
| ----CD PLAYERS | 13 |
| ----2 WAY RADIOS | 15 |
+------------------------+-----+
参考:
- Managing Hierarchical Data in MySQL
- Joe Celko’s Trees and hierarchies in SQL for smarties (ISBN 1-55860-920-2)
将已有邻接表转换为嵌套集表
我们实际的 OA 数据库里有一个汇报关系表,是一个邻接表模型,它大致的字段如下(为了方便我用的临时表 APPROVAL_GROUP_TEMP):
CREATE TABLE `APPROVAL_GROUP_TEMP` (
`ID` decimal(8,0) NOT NULL,
`FATHERID` decimal(8,0) DEFAULT NULL, -- 上级ID
`APPROVALGROUPNAME` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL, -- 名称
`SHOWFLAG` decimal(1,0) DEFAULT '1', -- 状态(1::启用,0:禁用,2:删除)
PRIMARY KEY (`ID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
我们构建一个嵌套集表:
CREATE TABLE `AG_Stack` (
`stack_top` int NOT NULL,
`node` varchar(100) NOT NULL, -- 名称
`lft` int DEFAULT NULL,
`rgt` int DEFAULT NULL,
`nodeid` int NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
然后使用下面的存储过程将邻接表的关系转换到嵌套集表里面(只转换启用的 SHOWFLAG=1):
CREATE DEFINER=`root`@`localhost` PROCEDURE `AdjToNested`()
DETERMINISTIC
BEGIN
DECLARE lft_rgt INTEGER;
DECLARE max_lft_rgt INTEGER;
DECLARE current_top INTEGER;
DECLARE step INTEGER;
SET step = 1;
SET lft_rgt = 2;
SET max_lft_rgt = 2 * (SELECT COUNT(*) FROM APPROVAL_GROUP_TEMP);
SET current_top = 1;
-- Clear Stack
DELETE FROM AG_Stack;
-- Insert 1st record, push 1 to stack
INSERT INTO AG_Stack
SELECT 1, APPROVALGROUPNAME, 1, max_lft_rgt, id
FROM APPROVAL_GROUP_TEMP
WHERE fatherid = -1;
-- Remove the 1st record from Old table
DELETE FROM APPROVAL_GROUP_TEMP WHERE fatherid = -1;
-- If there are still records
WHILE lft_rgt <= max_lft_rgt - 1 AND current_top > 0 DO
IF EXISTS (SELECT *
FROM AG_Stack AS S1, APPROVAL_GROUP_TEMP AS T1
WHERE S1.nodeid = T1.fatherid AND T1.SHOWFLAG = 1
AND S1.stack_top = current_top)
THEN BEGIN
-- Each time process 1 record
INSERT INTO AG_Stack SELECT (current_top + 1), T1.APPROVALGROUPNAME, lft_rgt, NULL, T1.id
FROM AG_Stack AS S1, APPROVAL_GROUP_TEMP AS T1
WHERE S1.nodeid = T1.fatherid AND T1.SHOWFLAG = 1
AND S1.stack_top = current_top LIMIT 1;
DELETE FROM APPROVAL_GROUP_TEMP
WHERE id = (SELECT nodeid
FROM AG_Stack
WHERE stack_top = (current_top + 1) AND lft = lft_rgt);
SET current_top = current_top + 1;
SET lft_rgt = lft_rgt + step;
END;
ELSEIF current_top >= 0 THEN BEGIN
UPDATE AG_Stack
SET rgt = lft_rgt,
stack_top = - stack_top
WHERE stack_top = current_top;
SET lft_rgt = lft_rgt + step;
SET current_top = current_top - 1;
END;
END IF;
END WHILE;
END;
运行后:
CALL AdjToNested();
SELECT * FROM AG_Stack;
+-----------+---------------------------------+-------+-------+--------+
| stack_top | node | lft | rgt | nodeid |
+-----------+---------------------------------+-------+-------+--------+
| -1 | 公司总部 | 1 | 68202 | 16060 |
| -2 | 研发中心 | 2 | 41052 | 16062 |
| -3 | 直属员工 | 52 | 102 | 16881 |
| -3 | 研发管理部 | 152 | 1702 | 19340 |
| -4 | 直属员工 | 202 | 252 | 19341 |
| -4 | 业务流程管理组 | 302 | 452 | 19720 |
| -5 | 直属员工 | 352 | 402 | 19721 |
| -4 | 业务标准管理组 | 502 | 652 | 19722 |
| -5 | 直属员工 | 552 | 602 | 19723 |
| -4 | 业务执行专家组 | 702 | 1652 | 19724 |
| -5 | 策划专家组 | 752 | 902 | 19342 |
| -6 | 直属员工 | 802 | 852 | 19343 |
| -5 | 程序专家组 | 952 | 1102 | 19344 |
| -6 | 直属员工 | 1002 | 1052 | 19345 |
| -5 | 美术专家组 | 1152 | 1302 | 19346 |
| -6 | 直属员工 | 1202 | 1252 | 19347 |
| -5 | 项目管理专家组 | 1352 | 1502 | 19348 |
| -6 | 直属员工 | 1402 | 1452 | 19349 |
| -5 | 直属员工 | 1552 | 1602 | 19725 |
| -3 | 某某工作室 | 1752 | 3002 | 19496 |
| -4 | XXX项目组 | 1802 | 2952 | 19800 |
| -5 | 策划组 | 1852 | 2002 | 20740 |
-- ...以下省略
性能比较
这里比较一下不同模型类似数据量下的性能。
优化前
这里除了闭包表的关联表都未加索引。
获取全树:
SET @@profiling = 0;
SET @@profiling_history_size = 0;
SET @@profiling_history_size = 100;
SET @@profiling = 1;
-- 邻接表
WITH RECURSIVE T1(ID,APPROVALGROUPNAME,FATHERID) AS (
SELECT T0.ID,T0.APPROVALGROUPNAME,T0.FATHERID FROM APPROVAL_GROUP T0 WHERE
T0.FATHERID = -1 AND SHOWFLAG=1
UNION ALL
SELECT T2.ID,T2.APPROVALGROUPNAME,T2.FATHERID FROM APPROVAL_GROUP T2, T1
WHERE T2.FATHERID = T1.ID AND SHOWFLAG=1
)
SELECT * FROM T1;
-- 路径枚举表
SELECT nodeid,node FROM AG_PathEnum WHERE path_string LIKE '16060/%';
-- 闭包表
SELECT n3.ID,n3.APPROVALGROUPNAME FROM APPROVAL_GROUP n1
INNER JOIN AG_Closure n2 ON n1.ID = n2.ancestor
INNER JOIN APPROVAL_GROUP n3 ON n2.descendant = n3.ID
WHERE n1.FATHERID = -1 AND n2.distance != 0;
-- 嵌套集
SELECT node.node,node.nodeid
FROM AG_Stack AS node,
AG_Stack AS parent
WHERE node.lft > parent.lft AND node.rgt < parent.rgt
AND parent.lft = 1
ORDER BY node.lft;
-- 查看性能
SHOW PROFILES;
+----------+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 1 | 0.01553425 | WITH RECURSIVE T1(ID,APPROVALGROUPNAME,FATHERID) AS ( SELECT T0.ID,T0.APPROVALGROUPNAME,T0.FATHERID FROM APPROVAL_GROUP T0 WHERE T0.FATHERID = -1 AND SHOWFLAG=1 UNION ALL SELECT T2.ID,T2.APPROVALGROUPNAME,T2.FATHERID FROM APPROVAL_GROUP T2, T1 WHERE T2.FATHERID = T1.ID AND SHOWFLAG=1 ) SELECT |
| 2 | 0.00199475 | SELECT nodeid,node FROM AG_PathEnum WHERE path_string LIKE '16060/%' |
| 3 | 0.01929400 | SELECT n3.ID,n3.APPROVALGROUPNAME FROM APPROVAL_GROUP n1
INNER JOIN AG_Closure n2 ON n1.ID = n2.ancestor
INNER JOIN APPROVAL_GROUP n3 ON n2.descendant = n3.ID
WHERE n1.FATHERID = -1 AND n2.distance != 0 |
| 4 | 0.00121350 | SELECT node.node,node.nodeid FROM AG_Stack AS node, AG_Stack AS parent WHERE node.lft > parent.lft AND node.rgt < parent.rgt AND parent.lft = 1 ORDER BY node.lft |
+----------+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
可以看到嵌套集的查询速度对比邻接表是数量级上的快,600 多条数据快了 10 倍;相较闭包表,嵌套集的速度也是快上 6 倍左右。而在没有优化的情况下,嵌套集与路径枚举表的速度差不多。
用 explain 语句分析一下四条 SQL,路径枚举表只用了 1 次简单查询,嵌套集 2 次,闭包表 3 次,邻接表 4 次。而且邻接表包含 1 个复杂查询、一个临时表的子查询和 2 个联合查询,其它模型都是简单查询(SIMPLE)。因为邻接表、路径枚举表和嵌套集都没有加索引,所以 type 都是 ALL 即全表扫描。
-- 邻接表
EXPLAIN
WITH RECURSIVE T1(ID,APPROVALGROUPNAME,FATHERID) AS (
SELECT T0.ID,T0.APPROVALGROUPNAME,T0.FATHERID FROM APPROVAL_GROUP T0 WHERE
T0.FATHERID = -1 AND SHOWFLAG=1
UNION ALL
SELECT T2.ID,T2.APPROVALGROUPNAME,T2.FATHERID FROM APPROVAL_GROUP T2, T1
WHERE T2.FATHERID = T1.ID AND SHOWFLAG=1
)
SELECT * FROM T1;
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
| 1 | PRIMARY | | NULL | ALL | NULL | NULL | NULL | NULL | 616 | 100.00 | NULL |
| 2 | DERIVED | T0 | NULL | ALL | NULL | NULL | NULL | NULL | 2467 | 1.00 | Using where |
| 3 | UNION | T1 | NULL | ALL | NULL | NULL | NULL | NULL | 24 | 100.00 | Recursive |
| 3 | UNION | T2 | NULL | ALL | NULL | NULL | NULL | NULL | 2467 | 1.00 | Using where; Using join buffer (hash join) |
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
-- 路径枚举表
EXPLAIN
SELECT nodeid,node FROM AG_PathEnum WHERE path_string LIKE '16060/%';
+----+-------------+-------------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | AG_PathEnum | NULL | ALL | NULL | NULL | NULL | NULL | 683 | 11.11 | Using where |
+----+-------------+-------------+------------+------+---------------+------+---------+------+------+----------+-------------+
-- 闭包表
EXPLAIN
SELECT n3.ID,n3.APPROVALGROUPNAME FROM APPROVAL_GROUP n1
INNER JOIN AG_Closure n2 ON n1.ID = n2.ancestor
INNER JOIN APPROVAL_GROUP n3 ON n2.descendant = n3.ID
WHERE n1.FATHERID = -1 AND n2.distance != 0;
+----+-------------+-------+------------+--------+---------------+---------------+---------+--------------------------+------+----------+------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+---------------+---------------+---------+--------------------------+------+----------+------------------------------------+
| 1 | SIMPLE | n1 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 2467 | 10.00 | Using where |
| 1 | SIMPLE | n2 | NULL | ref | uniq_anc_desc | uniq_anc_desc | 4 | OrgAndUser.n1.ID | 5 | 90.00 | Using index condition; Using where |
| 1 | SIMPLE | n3 | NULL | eq_ref | PRIMARY | PRIMARY | 4 | OrgAndUser.n2.descendant | 1 | 100.00 | Using where |
+----+-------------+-------+------------+--------+---------------+---------------+---------+--------------------------+------+----------+------------------------------------+
-- 嵌套集
EXPLAIN
SELECT node.node,node.nodeid
FROM AG_Stack AS node,
AG_Stack AS parent
WHERE node.lft > parent.lft AND node.rgt < parent.rgt
AND parent.lft = 1
ORDER BY node.lft;
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------+
| 1 | SIMPLE | parent | NULL | ALL | NULL | NULL | NULL | NULL | 683 | 10.00 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | node | NULL | ALL | NULL | NULL | NULL | NULL | 683 | 11.11 | Using where; Using join buffer (hash join) |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------+
优化后
这里对几个模型分别加上检索字段的索引:
-- 邻接表
CREATE UNIQUE INDEX APPROVAL_GROUP_TEMP_ID_IDX USING BTREE ON APPROVAL_GROUP_TEMP (ID);
CREATE INDEX APPROVAL_GROUP_TEMP_FATHERID_IDX USING BTREE ON APPROVAL_GROUP_TEMP (FATHERID);
CREATE INDEX APPROVAL_GROUP_TEMP_SHOWFLAG_IDX USING BTREE ON APPROVAL_GROUP_TEMP (SHOWFLAG);
-- 路径枚举
CREATE UNIQUE INDEX AG_PathEnum_path_string_IDX USING BTREE ON AG_PathEnum (path_string);
-- 闭包表
CREATE INDEX AG_Closure_ancestor_IDX USING BTREE ON AG_Closure (ancestor);
CREATE INDEX AG_Closure_descendant_IDX USING BTREE ON AG_Closure (descendant);
CREATE INDEX AG_Closure_distance_IDX USING BTREE ON AG_Closure (distance);
-- 嵌套集
CREATE UNIQUE INDEX AG_Stack_lft_IDX USING BTREE ON AG_Stack (lft);
CREATE UNIQUE INDEX AG_Stack_rgt_IDX USING BTREE ON AG_Stack (rgt);
重新执行前面的全树查询,SHOW PROFILES 的结果是:
+----------+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 12 | 0.00990250 | WITH RECURSIVE T1(ID,APPROVALGROUPNAME,FATHERID) AS (
SELECT T0.ID,T0.APPROVALGROUPNAME,T0.FATHERID FROM APPROVAL_GROUP T0 WHERE
T0.FATHERID = -1 AND SHOWFLAG=1
UNION ALL
SELECT T2.ID,T2.APPROVALGROUPNAME,T2.FATHERID FROM APPROVAL_GROUP T2, T1
WHERE T2.FATHERID = T1.ID AND SHOWFLAG=1
)
SELECT |
| 13 | 0.00184200 | SELECT nodeid,node FROM AG_PathEnum WHERE path_string LIKE '16060/%' |
| 14 | 0.00384525 | SELECT n3.ID,n3.APPROVALGROUPNAME FROM APPROVAL_GROUP n1
INNER JOIN AG_Closure n2 ON n1.ID = n2.ancestor
INNER JOIN APPROVAL_GROUP n3 ON n2.descendant = n3.ID
WHERE n1.FATHERID = -1 AND n2.distance != 0 |
| 15 | 0.00235000 | SELECT node.node,node.nodeid
FROM AG_Stack AS node,
AG_Stack AS parent
WHERE node.lft > parent.lft AND node.rgt < parent.rgt
AND parent.lft = 1
ORDER BY node.lft |
+----------+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
看起来路径枚举与嵌套集差距不大,嵌套集反而比未优化前慢了一倍,这个应该与数据库的缓存及构建索引有关,再次运行同样的 SQL 就更快了。
我们再比较一下寻找父节点的性能:
-- 路径枚举
SELECT P2.* FROM AG_PathEnum AS P1, AG_PathEnum AS P2
WHERE P1.nodeid = 18903 AND POSITION(P2.path_string IN P1.path_string)= 1 ORDER BY P2.nodeid;
-- 嵌套集
SELECT parent.node,parent.nodeid FROM
AG_Stack AS node,
AG_Stack AS parent
WHERE node.lft > parent.lft AND node.rgt < parent.rgt
AND node.nodeid = 18903
ORDER BY parent.lft DESC;
SHOW PROFILES;
+----------+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 19 | 0.00192450 | SELECT P2.* FROM AG_PathEnum AS P1, AG_PathEnum AS P2
WHERE P1.nodeid = 18903 AND POSITION(P2.path_string IN P1.path_string)= 1 ORDER BY P2.nodeid |
| 20 | 0.00111425 | SELECT parent.node,parent.nodeid FROM
AG_Stack AS node,
AG_Stack AS parent
WHERE node.lft > parent.lft AND node.rgt < parent.rgt
AND node.nodeid = 18903
ORDER BY parent.lft DESC |
+----------+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
差距也不大。
总结
树状或层次结构的数据在数据库里的设计,以上的四种模型为久经考验的常用模型。
| 是否归一化 | 是否无限深度 | 查询需要递归 | 需要几个表 | 增删改是否简单 | 性能 | |
|---|---|---|---|---|---|---|
| 邻接表 | 否 | 是 | 是 | 1 | 是 | 低 |
| 路径枚举 | 否 | 否 | 否 | 1 | 一般 | 高 |
| 闭包表 | 是 | 是 | 否 | 2 | 一般 | 一般 |
| 嵌套集 | 是 | 是 | 否 | 1 | 一般 | 高 |
- 是否归一化:邻接表和路径枚举表因为可能出现回环路径,所以不是归一化的模型,需要通过编程实现归一化;
- 是否无限深度:路径枚举表的路径长度有限,对一些深度需求很高的数据模型就不合适;
- 查询是否需要递归:邻接表只能通过递归来实现全树搜索,其它模型则不需要
- 需要几个表:闭包表需要额外的关系表,即通过空间换时间
- 增删改是否简单:邻接表只需要对一条记录操作即可,路径枚举表和闭包表都需要对关联的节点进行操作,嵌套集也需要重新计算修改节点的后续节点左右值
- 性能:如上测试,邻接表性能因为递归的原因最差,路径枚举和嵌套集因为简单查询及优化后性能都很好,闭包表查询的表多、次数较多,故性能一般
原文地址 zhuanlan.zhihu.com