【云原生进阶之PaaS中间件】第三章Kafka-4.3.1-broker 工作流程

1 kafka broker
1.1 kafka broker 工作流程
这一部分大体了解下kafka Broker的工作流程,看一下zookeeper在kafka broker工作中发挥的作用,那些重要数据在zookeeper中存储。
1.1.1 zookeeper存储kafka的信息
zookeeper在kafka中扮演了重要的角色,kafka使用zookeeper进行元数据管理,保存broker注册信息,包括主题(Topic)、分区(Partition)信息等,选择分区leader,在低版本kafka消费者的offset信息也会保存在zookeeper中。如图使用zookeeper客户端PrettyZoo查看内容如下:

启动zookeeper客户端.
[atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkCli.sh通过命令查看kafka相关信息.
[zk: localhost:2181(CONNECTED) 2] ls /kafka
1.1.2 kafka在zookeeper上存储的brokers节点信息
kafka在zookeeper上存储的brokers节点信息如下:

其中
- /brokers/ids/[0...n]:是使用临时节点存储在线的是各个服务节点的信息,当下线后自动删除;
{
"listener_security_protocol_map" : {
"PLAINTEXT" : "PLAINTEXT"
},
"endpoints" : [ "PLAINTEXT://192.168.31.32:9091" ],
"jmx_port" : -1,
"features" : { },
"host" : "192.168.31.32",
"timestamp" : "1646557610504",
"port" : 9091,
"version" : 5
}- /brokers/seqid:辅助生成的brokerId,当用户没有配置broker.id时,ZK会自动生成一个全局唯一的id。
- /brokers/topics/{topicName}:持久化数据节点存储topic的分区副本分配信息。在/brokers/topics/{topicName}//partitions/0/state中记录了leader和isr队列的内容。
{
"controller_epoch" : 5,
"leader" : 3,
"version" : 1,
"leader_epoch" : 4,
"isr" : [ 2, 3 ]
}其中_transaction_offsets,是事务存储的节点。
- Consumers节点,0.9版本之前用于保存offset信息,0.9版本之后offset存储在kafka主题中。
- Controller和/Controller_epoch节点
- /controller:保存控制器(broker的leader, 这里的leader要和副本的leader区分开,这里的leader是kafka集群中所有broker的leader)对应的brokerId信息等
- /controller_epoch:这里用来解决脑裂问题,存放的是一个整形值(纪元编号,也称为隔离令牌)
- /config/topics:存储动态修改主题级别的配置信息
- /config/clients:存储动态修改客户端级别的配置信息
- /config/changes:动态修改配置时存储相应的信息
- /admin/delete_topics:在对主题进行删除操作时保存待删除主题的信息
- /isr_change_notification:保存Kafka副本ISR列表发生变化时通知的相应路径
1.1.3 kafka broker 的总体工作流程

(1)查看/kafka/brokers/ids路径上的节点。
[zk: localhost:2181(CONNECTED) 2] ls /kafka/brokers/ids
[0, 1, 2](2)查看/kafka/controller路径上的数据。
[zk: localhost:2181(CONNECTED) 15] get /kafka/controller
{
"version":1,
"brokerid":0,
"timestamp":"1637292471777"
}(3)查看/kafka/brokers/topics/first/partitions/0/state路径上的数据。
[zk: localhost:2181(CONNECTED) 16] get /kafka/brokers/topics/first/partitions/0/state
{
"controller_epoch":24,
"leader":0,
"version":1,
"leader_epoch":18,
"isr":[0,1,2]
}(4)停止hadoop104上的kafka。
[atguigu@hadoop104 kafka]$ bin/kafka-server-stop.sh(5)再次查看/kafka/brokers/ids路径上的节点。
[zk: localhost:2181(CONNECTED) 3] ls /kafka/brokers/ids
[0, 1](6)再次查看/kafka/controller路径上的数据。
[zk: localhost:2181(CONNECTED) 15] get /kafka/controller
{
"version":1,
"brokerid":0,
"timestamp":"1637292471777"
}(7)再次查看/kafka/brokers/topics/first/partitions/0/state路径上的数据。
[zk: localhost:2181(CONNECTED) 16] get /kafka/brokers/topics/first/partitions/0/state
{
"controller_epoch":24,
"leader":0,
"version":1,
"leader_epoch":18,
"isr":[0,1]
}(8)启动hadoop104上的kafka。
[atguigu@hadoop104 kafka]$ bin/kafka-server-start.sh -daemon ./config/server.properties(9)再次观察(1)、(2)、(3)步骤中的内容。
1.1.4 broker的重要参数

1.2 文件存储
1.2.1 文件存储机制
在kafka中主题(Topic)是一个逻辑上的概念,分区(partition)是物理上的存在的。每个partition对应一个log文件,该log文件中存储的就是Producer生产的数据。Producer生产的数据会被不断追加到该log文件末端。为防止log文件过大导致数据定位效率低下,kafka采用了分片和索引机制,将每个partition分为多个segment,每个segment包括.index文件、.log文件和.timeindex等文件。这些文件位于文件夹下,该文件命名规则为:topic名称+分区号。

上图对应的是某一个主题的文件结构图,一个主题是对应多个分区,一个分区对应一个日志(Log),如果只通过一个log文件记录的话,这就会导致日志过大,导致数据定位效率低下,所以kafka采用了分片和索引机制。
kafka引入了日志分段(LogSegment),将日志分为多个较小的文件;Log会存储在配置的log.dirs文件夹内,而每个LogSegment由三个文件组成:偏移量索引文件(.index后缀)、时间戳的索引文件(.timeindex后缀)和消息数据文件(.log后缀);注意这里面还有一个leader-epoch-checkpoint文件,保存的是Leader Epoch的值(解决副本数据一致性需要)。
目录结构如下:
├── long-topic-0
├── 00000000000000000000.index
├── 00000000000000000000.log
├── 00000000000000000000.timeindex
├── 00000000000000000113.index
├── 00000000000000000113.log
├── 00000000000000000113.timeindex
└── leader-epoch-checkpoint分段文件名规则:分区的第一个segment是从0开始的,后续每个segment文件名为上一个segment文件最后一条消息的offset,ofsset的数值最大为64位(long类型),20位数字字符长度,没有数字用0填充。
log文件默认写满1G后,会进行log rolling形成一个新的分段(segment)来记录消息,这里面的分段大小取决于:log.segment.bytes参数决定。
index和timeindex文件在刚使用时会分配10M的大小,当进行log rolling后,它会修剪为实际的大小,所以看到前几个索引文件的大小,只有几百K。
查看log文件内容的方法:
./bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.log --print-data-log

查看这些文件是一些乱码信息,因为生产者上传时是有序列化,只有通过相同的反序列化后可以看到不乱码的,现在在kafka使用工具来查看,如下:
[atguigu@hadoop102 first1-0]$ kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.index
Dumping ./00000000000000000000.index
offset: 0 position: 0
Mismatches in :/opt/module/kafka/datas/first1-0/./00000000000000000000.index
Index offset: 0, log offset: 9[atguigu@hadoop102 first1-0]$ kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.log
Dumping ./00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 9 count: 10 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1655729494741 size: 201 magic: 2 compresscodec: none crc: 925683915 isvalid: true
baseOffset: 10 lastOffset: 19 count: 10 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 201 CreateTime: 1655729580577 size: 201 magic: 2 compresscodec: none crc: 2811645235 isvalid: true
baseOffset: 20 lastOffset: 29 count: 10 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 402 CreateTime: 1655732822744 size: 211 magic: 2 compresscodec: none crc: 2145363516 isvalid: true
baseOffset: 30 lastOffset: 31 count: 2 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 613 CreateTime: 1655736655333 size: 89 magic: 2 compresscodec: none crc: 2438774302 isvalid: true
baseOffset: 32 lastOffset: 33 count: 2 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 702 CreateTime: 1655736655349 size: 89 magic: 2 compresscodec: none crc: 3832231783 isvalid: true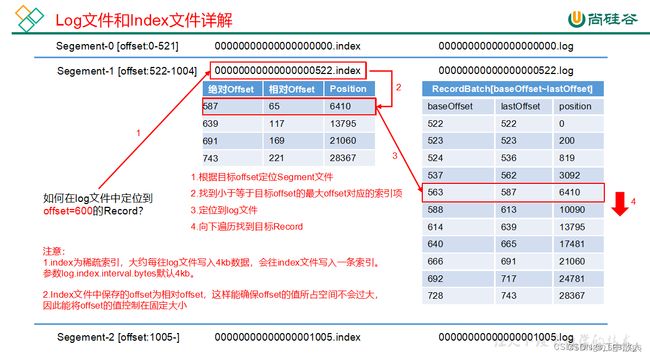
说明:日志存储参数配置

1.2.2 log、timeindex和index文件的对应关系
当log文件写入4k(这里可以通过log.index.interval.bytes设置)数据,就会写入一条索引信息到index文件中,这样的index索引文件就是一个稀疏索引,它并不会每条日志都建立索引信息。
log日志文件是顺序写入,大体上由message+实际offset+position组成,而索引文件的数据结构则是由相对offset(4byte)+position(4byte)组成。
当kafka查询一条offset对应实际消息时,可以通过index进行二分查找,获取最近的低位offset,然后从低位offset对应的position开始,从实际的log文件中开始往后查找对应的消息。

时间戳索引文件,它的作用是可以查询某一个时间段内的消息,它的数据结构是:时间戳(8byte)+ 相对offset(4byte),如果要使用这个索引文件,先要通过时间范围找到对应的offset,然后再去找对应的index文件找到position信息,最后在遍历log文件,这个过程也是需要用到index索引文件的。
1.2.3 文件清理策略
从上面知道消息数据会被不断追加到该log文件末端,这就会面临一个问题,就是log文件越来越大,磁盘空间是一定的,那么此时kakfa可以通过配置log.cleanup.policy参数,默认是delete(删除,按照一定的保留策略直接删除不符合条件的日志分段LogSegment),另一个是compact(压缩,日志压缩就是根据key来保留最后一条消息)两种。
1.2.3.1 delete删除
kafka中默认的日志保存时间为7天,可以通过调整如下参数修改保存时间。
- log.retention.hours:最低优先级小时,默认7天
- log.retention.minutes:分钟
- log.retention.ms:最高优先级毫秒
- log.retention.check.interval.ms:负责设置检查周期,默认5分钟
- file.delete.delay.ms:延迟执行删除时间
- log.retention.bytes:当设置为-1时表示运行保留日志最大值(相当于关闭);当设置为1G时,表示日志文件最大值
具体的保留日志策略有三种:
- 基于时间策略
日志删除任务会周期检查当前日志文件中是否有保留时间超过设定的阈值来寻找可删除的日志段文件集合;这里需要注意log.retention参数的优先级:log.retention.ms > log.retention.minutes > log.retention.hours,默认只会配置log.retention.hours参数,值为168即为7天。
删除过期的日志段文件,并不是简单的根据日志段文件的修改时间计算,而是要根据该日志段中最大的时间戳来计算的,首先要查询该日志分段所对应的时间戳索引文件,查找该时间戳索引文件的最后一条索引数据,如果时间戳大于0就取值,否则才会使用最近修改时间。
在删除的时候先从Log对象所维护的日志段的跳跃表中移除要删除的日志段,用来确保已经没有线程来读取这些日志段;接着将日志段所对应的所有文件,包括索引文件都添加上.deleted的后缀;最后交给一个以delete-file命名的延迟任务来删除这些以.deleted为后缀的文件,默认是1分钟执行一次,可以通过file.delete.delay.ms来配置。
- 基于日志大小策略
日志删除任务会周期性检查当前日志大小是否超过设定的阈值(log.retention.bytes,默认是-1,表示无穷大),来寻找可删除的日志段文件集合。
- 基于日志起始偏移量
该策略判断依据是日志段的下一个日志段的起始偏移量 baseOffset是否小于等于 logStartOffset,如果是,则可以删除此日志分段。
这里说一下logStartOffset,一般情况下,日志文件的起始偏移量 logStartOffset等于第一个日志分段的 baseOffset,但这并不是绝对的,logStartOffset的值可以通过 DeleteRecordsRequest请求、使用 kafka-delete-records.sh 脚本、日志的清理和截断等操作进行修改。
思考:如果一个segment中有一部分数据过期,一部分没有过期,怎么处理?
答案是,继续保留

1.2.3.2 compact压缩
日志压缩对于有相同key的不同value值,只保留最后一个版本。如果应用只关心 key对应的最新 value值,则可以开启 Kafka相应的日志清理功能,Kafka会定期将相同 key的消息进行合并,只保留最新的 value值。

1.3 高效读写数据机制
kafka之所以可以快速读写的原因如下:
1)Kafka本身是分布式集群,可以采用分区技术,并行度高
2)读数据采用稀疏索引,可以快速定位要消费的数据
3)顺序写磁盘
4)页缓冲和零拷贝
Kafka的producer生产数据,要写入到log文件中,写的过程是一直追加到文件末端,为顺序写。官网有数据表明,同样的磁盘,顺序写能到600M/s,而随机写只有100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。



1.3.1 页缓冲技术
在 Kafka 中,大量使用了 PageCache, 这也是 Kafka 能实现高吞吐的重要因素之一。
首先看一下读操作,当一个进程要去读取磁盘上的文件内容时,操作系统会先查看要读取的数据页是否缓冲在PageCache 中,如果存在则直接返回要读取的数据,这就减少了对于磁盘 I/O的 操作;但是如果没有查到,操作系统会向磁盘发起读取请求并将读取的数据页存入 PageCache 中,之后再将数据返回给进程,就和使用redis缓冲是一个道理。
接着写操作和读操作是一样的,如果一个进程需要将数据写入磁盘,操作系统会检查数据页是否在PageCache 中已经存在,如果不存在就在 PageCache中添加相应的数据页,接着将数据写入对应的数据页。另外被修改过后的数据页也就变成了脏页,操作系统会在适当时间将脏页中的数据写入磁盘,以保持数据的一致性。
1.3.2 零拷贝技术
零拷贝并不是不需要拷贝,而是减少不必要的拷贝次数,通常使用在IO读写过程中。常规应用程序IO过程如下图,会经过四次拷贝:
- 数据从磁盘经过DMA到内核的Read Buffer;
- 内核态的Read Buffer到用户态应用层的Buffer;
- 用户态的Buffer到内核态的Socket Buffer;
- Socket Buffer到网卡的NIC Buffer;
从上面的流程可以知道内核态和用户态之间的拷贝相当于执行两次无用的操作,之间切换也会花费很多资源;当数据从磁盘经过DMA 拷贝到内核缓存(页缓存)后,为了减少CPU拷贝的性能损耗,操作系统会将该内核缓存与用户层进行共享,减少一次CPU copy过程,同时用户层的读写也会直接访问该共享存储,本身由用户层到Socket缓存的数据拷贝过程也变成了从 内核到内核的CPU拷贝过程,更加的快速,这就是零拷贝,IO流程如下图。

Java的JDK NIO中方法transferTo()方法就能够实现零拷贝操作,这个实现依赖于操作系统底层的sendFile()实现的:
public void transferTo(long position, long count, WritableByteChannel target);底层调用的是:
#include
ssize_t sendfile(int out_fd, int in_fd, off_t offset, size_t count); 但是需要注意零拷贝和系统底层有很大的关系,所以是否可以进行零拷贝的系统调用的看具体的操作系统是否实现。下面看一下Java nio的零拷贝例子:
import java.io.*;
import java.nio.channels.FileChannel;
public class ZeroCopy {
public static void main(String[] args) {
File source = new File("G:/source.zip");
File target = new File("G:/target.zip");
NioZeroCopy(source, target);
}
public static void NioZeroCopy(File source, File target) {
try (
FileChannel sourceChannel = new FileInputStream(source).getChannel();
FileChannel targetChannel = new FileOutputStream(target).getChannel();
) {
for(long count = sourceChannel.size(); count > 0;) {
long transfer = sourceChannel.transferTo(sourceChannel.position(), count, targetChannel);
sourceChannel.position(sourceChannel.position() + transfer);
count -= transfer;
}
} catch (IOException e) {
System.out.println("异常:" + e.getMessage());
}
}
}1.4 kafka broker的leader选举
1.4.1 leader选举的种类
这里需要先明确一个概念leader选举,因为kafka中涉及多处选举机制,容易搞混,kafka由三个方面会涉及到选举:
- broker(控制器)选leader
- 分区多副本选leader
- 消费者选leader
本文会讲述Broker选leader和分区选leader的过程,后面将消费者的时候在说消费者选leader的过程。
1.4.2 Broker选举过程
在kafka集群中由很多的broker(也叫做控制器),但是他们之间需要选举出一个leader,其他的都是follower。broker的leader有很重要的作用,诸如:创建、删除主题、增加分区并分配leader分区;集群broker管理,包括新增、关闭和故障处理;分区重分配(auto.leader.rebalance.enable=true,后面会介绍);分区leader选举。
下面看一下Broker的leader选举过程和故障处理

如图可以大概描述如下:
- 集群中第一个启动的broker会在zookeeper中创建临时节点/controller来让自己成为控制器,当其他的broker启动也会在zookeeper中创建临时节点/controller,但是会发现节点已经存在,此时会受到一个异常,此时就会在zookeeper中创建一个watch对象,方便这些broker接受leader的变更消息;
- 如果主leader因为网络问题与zookeeper断开连接或者发生异常退出了,其他的broker就可以通watch接收到控制器的变更通知,开始尝试去创建临时节点/controller,如果有一个broker创建成功了,就和上面说的一样,其他的broker也会收到异常通知,此时就说明集群中broker的leader已经确定,其他的broker只能创建watch对象了;
- 集群中broker的leader发生异常退出,在选举出新的leader之后,会检测这个异常的broker上面是否有分区副本的leader,如果有就是发起分区的leader选举,选出新的分区leader,然后更新ISR队列数据;
1.4.3 脑裂问题
1.4.3.1 什么是脑裂
说起脑裂,那么什么是脑裂,出字面意思上理解,就是一分为二有了多个脑袋。在分布式系统的高可用情况下很容易出现这种问题,简单来说就是因为网络或者其他的原因导致leader出现假死状态,此时会触发leader选举,这样就会出现两个leader进而产生一系列问题。
kafka broker的leader相当于整个kafka集群的master,负责很多重要的工作(上文有,此处不再累述),broker是通过抢占的方式在zookeeper中注册临时节点/controller来时实现的,先到先得。由于zookeeper的临时节点的有效性是通过session来判断的,若在session timeout时间内,controller所在的broker断开,就会触发重新选举。
1.4.3.2 那么发生脑裂又会什么影响?
从上文可以知道,broker的leader主要是用于管理主题的,那些发生脑裂之后创建主题、增加分区的操作都会报错;但是现有的主题的读写是不影响的,这是因为读写是获取分区的元数据在任意一个broker中都可以拿到。
1.4.3.3 发生脑裂的情况?
broker的leader进行GC的时间超过zookeeper session timeout;broker的leader发生网络故障。
1.4.3.4 kafka的解决方案
为了解决Controller脑裂问题,zookeeper中有一个持久节点/controller_epoch,存放的是一个整形值的epoch number(纪元编号,也称为隔离令牌),集群中每选举一次控制器,就会通过Zookeeper创建一个数值更大的epoch number,如果有broker收到比这个epoch数值小的数据,就会忽略消息。
1.4.4 羊群效应
在早期的kafka版本中,如果宕机的那个Broker上的Partition比较多, 会造成多个Watch被触发,造成集群内大量的调整,导致大量网络阻塞,这种羊群效应会导致zookeeper过载的隐患。之后kafka有一个controller的概念(也就是broker的leader)来对分区副本的状态进行管理,当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本。当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息。
在使用zookeeper的分布式中,这种脑裂和羊群效应都是不可避免的。
1.4.5 触发leader选举
现阶段的kakfa集群中,只需要broker的leader在zookeeper去注册相应的监听器,其他的broker很少去监听zookeeper的数据变化,但是每个broker还是需要对/controller进行监听;当/controller节点发生数据变化的时候,每个broker都会更新自身内存中保存的activeControllerId。
当/controller节点被删除时,集群中的broker会进行选举,如果broker在节点被删除前是控制器的话,在选举前还需要有一个下线的操作(关闭相应的资源,比如关闭状态机、注销相应的监听器等)。如果有特殊需要,可以手动删除/controller节点来触发新一轮的选举。当然关闭控制器所对应的broker以及手动向/controller节点写入新的brokerid的所对应的数据同样可以触发新一轮的选举。
参考链接
Kafka基本原理详解-CSDN博客
这是最详细的Kafka应用教程了 - 掘金
Kafka : Kafka入门教程和JAVA客户端使用-CSDN博客
简易教程 | Kafka从搭建到使用 - 知乎
kafka简介-CSDN博客
Kafka 架构及基本原理简析
kafka是什么
再过半小时,你就能明白kafka的工作原理了(推荐阅读)
Kafka 设计与原理详解
Kafka【入门】就这一篇! - 知乎
kafka简介_kafka_唏噗-华为云开发者联盟
kafka详解
Kafka 设计与原理详解_kafka的设计初衷不包括-CSDN博客
kafka学习知识点总结(三)
Kafka知识总结之Broker原理总结_kafka broker-CSDN博客
深度解析kafka broker网络模型运行原理_kafka broker原理-CSDN博客
Kafka源码分析及图解原理之Broker端