全世界 LoRA 训练脚本,联合起来!
我们把 Replicate 在 SDXL Cog 训练器中使用的枢轴微调 (Pivotal Tuning) 技术与 Kohya 训练器中使用的 Prodigy 优化器相结合,再加上一堆其他优化,一起对 SDXL 进行 Dreambooth LoRA 微调,取得了非常好的效果。你可以在 diffusers 上找到 我们使用的训练脚本,或是直接 在 Colab 上 试着运行一下。
如果你想跳过技术讲解直接上手,可以使用这个 Hugging Face Space,通过简单的 UI 界面用我们精选的超参直接开始训练。当然,你也可以尝试干预这些超参的设置。
概述
使用 Dreambooth LoRA 微调后的 Stable Diffusion XL(SDXL) 模型仅需借助少量图像即可捕获新概念,同时保留了 SDXL 出图美观高质的优势。更难得的是,虽然微调结果令人惊艳,其所需的计算和资源消耗却相当低。你可在 此处 找到很多精彩的 SDXL LoRA 模型。
本文我们将回顾一些流行的、可以让你的 LoRA 微调更出色的实践和技术,并展示如何使用 diffusers 来运行或训练你自己的 LoRA 模型!
拾遗: LoRA (Low Rank Adaptation,低阶适配) 是一种可用于微调 Stable Diffusion 模型的技术,其可用于对关键的图像/提示交叉注意力层进行微调。其效果与全模型微调相当,但速度更快且所需计算量更小。要了解有关 LoRA 工作原理的更多信息,请参阅我们之前的文章 - 使用 LoRA 进行 Stable Diffusion 的高效参数微调。
枢轴微调
枢轴微调 技术巧妙地将 文本逆化 与常规的扩散模型微调相结合。以 Dreambooth 为例,进行常规 Dreambooth 微调时,你需要选择一个稀有词元作为触发词,例如“一只 sks 狗” 中的 sks 。但是,因为这些词元原本就来自于词表,所以它们通常有自己的原义,这就有可能会影响你的结果。举个例子,社区之前经常使用 sks 作为触发词,但实际上其原义是一个武器品牌。
为了解决这个问题,我们插入一个新词元到模型的文本编码器中,而非重用词表中现有的词元。然后,我们优化新插入词元的嵌入向量来表示新概念,这种想法就是文本逆化,即我们对嵌入空间中的新词元进行学习来达到学习新概念的目的。一旦我们获得了新词元及其对应的嵌入向量,我们就可以用这些词元嵌入向量来训练我们的 Dreambooth LoRA,以获得两全其美的效果。
训练
使用 diffusers 的新训练脚本,你可以通过设置以下参数来进行文本逆化训练。
--train_text_encoder_ti
--train_text_encoder_ti_frac=0.5
--token_abstraction="TOK"
--num_new_tokens_per_abstraction=2
--adam_weight_decay_text_encoder-
train_text_encoder_ti开启文本逆化训练,用于训练新概念的嵌入向量。
-
train_text_encoder_ti_frac指定何时停止文本逆化 (即停止文本嵌入向量的更新,仅继续更新 UNet)。中途定轴 (即仅在训练前半部分执行文本逆化) 是 cog sdxl 使用的默认设置,我们目前的实验也验证了其有效性。我们鼓励大家对此参数进行更多实验。
-
token_abstraction即概念标识符,我们在提示文本中用该词描述我们希望训练的概念。该标识符词元会用在实例提示、验证提示或图像描述文本中。这里我们选择TOK作为概念标识符,如 “TOK 的照片”即为一个含有概念标识符的实例提示。注意,--token_abstraction只是一个占位符,因此,在训练之前我们需要用一个新词元来代替TOK并对其进行训练 (举个例子,训练时“一张TOK的照片”会变成“一张token_abstraction与实例提示、验证提示和自定义提示 (如有) 中的标识符相一致。
-
num_new_tokens_per_abstraction表示每个token_abstraction对应多少个新词元 - 即需要向模型的文本编码器插入多少个新词元并对其进行训练。默认设置为 2,我们鼓励大家对不同取值进行实验并分享你们的发现!
-
adam_weight_decay_text_encoder用于为文本编码器设置与 UNet 不同的权重衰减。
自适应优化器
在训练或微调扩散模型 (或与此相关的任何机器学习模型) 时,我们使用优化器来引导模型依循最佳的收敛路径 - 收敛意味着我们选择的损失函数达到了最小值,我们认为损失函数达到最小值即说明模型已习得我们想要教给它的内容。当前,深度学习任务的标准 (也是最先进的) 优化器当属 Adam 和 AdamW 优化器。
然而,这两个优化器要求用户设置大量的超参 (如学习率、权重衰减等),以此为收敛铺平道路。这可能会导致我们需要不断试验各种超参,最后常常因为耗时过长而不得不采用次优超参,从而导致次优结果。即使你最后试到了理想的学习率,但如果学习率在训练期间保持为常数,仍然可能导致收敛问题。一些超参可能需要频繁的更新以加速收敛,而另一些超参的调整又不能太大以防止振荡。真正是“摁了葫芦起了瓢”。为了应对这一挑战,我们引入了有自适应学习率的算法,例如 Adafactor 和 Prodigy。这些方法根据每个参数过去的梯度来动态调整学习率,借此来优化算法对搜索空间的遍历轨迹。
我们的关注点更多在 Prodigy,因为我们相信它对 Dreambooth LoRA 训练特别有用!
训练
--optimizer="prodigy"使用 Prodigy 时,缺省学习率可以设置如下:
--learning_rate=1.0对扩散模型特别是其 LoRA 训练有用的设置还有:
--prodigy_safeguard_warmup=True
--prodigy_use_bias_correction=True
--adam_beta1=0.9
# 注意,以下超参的取值与默认值不同:
--adam_beta2=0.99
--adam_weight_decay=0.01在使用 Prodigy 进行训练时,你还可以对其他超参进行调整 (如: --prodigy_beta3 、prodigy_de Couple 、prodigy_safeguard_warmup ),本文不会对这些参数进行深入研究,你可以移步 此处 以了解更多信息。
其他好做法
除了枢轴微调以及自适应优化器之外,还有一些可以影响 LoRA 模型质量的其他技巧,所有这些技巧都已在最新的 diffusers 训练脚本中了。
独立设置文本编码器和 UNet 的学习率
社区发现,在优化文本编码器时,为其设置专有的学习率 (与 UNet 学习率独立) 所得模型的生成质量会更好 - 特别地,文本编码器需要 较低 的学习率,因为它一般过拟合 更快 。
-
在使用枢轴微调时,为 UNet 和文本编码器设置不同的学习率是已被证明了的 - 此时,为文本编码器设置更高的学习率更好。
-
但请注意,当使用 Prodigy (或一般的自适应优化器) 时,我们一开始可以让所有训练参数的初始学习率相同,让优化器自行调节。很神吧✨!
训练
--train_text_encoder
--learning_rate=1e-4 #unet
--text_encoder_lr=5e-5--train_text_encoder 启用文本编码器全模型训练 (即文本编码器的权重都参与更新,而不是仅仅优化文本逆化新词元的嵌入 ( --train_text_encoder_ti ))。如果你希望文本编码器的学习率始终与 --learning_rate 一致,可设 --text_encoder_lr=None 。
自定义描述文本
虽然通过对一组配有相同实例提示的图像进行训练也可以获得良好的结果,如“一张 的人像照片”或 “ 的风格”等。但对多幅图像使用相同的描述文本有可能会导致次优结果。具体效果取决于很多因素,包括待学习概念的复杂性、模型原本对该概念的“熟悉程度”,以及训练集捕获新概念的效果如何。

训练
想要使用自定义描述文本,首先需要安装 datasets 库,如下:
!pip install datasets要加载自定义图像描述文本,我们需要训练集的目录结构遵循 datasets 库的 ImageFolder 结构,其包含图像及每张图像对应的描述文本。
-
方式 1:
从 hub 中选择一个已包含图像及其对应提示的数据集 - 如 LinoyTsaban/3d_icon。现在要做的就是在训练参数中指定数据集的名称及文本列的名称 (在本例中列名为 "prompt"):
--dataset_name=LinoyTsaban/3d_icon
--caption_column=prompt-
方式 2:
你还可以使用自己的图像并为其添加描述文本。此时,你可以借助 这个 Colab Notebook 来用 BLIP 自动为图像生成描述文本,或者你可以在元数据文件中手动创建描述文本。后面的事情就和方式 1 一样了,将 --dataset_name 设为文件夹路径, --caption_column 设为描述文本所对应的列名。
最小信噪比 Gamma 加权
训练扩散模型通常会遇到收敛缓慢的问题,部分是由于各时间步之间的优化方向相互冲突。Hang 等人 通过引入简单的最小信噪比 Gamma 法来缓解此问题。该方法根据钳位信噪比调整每个时间步的损失权重,以有效平衡各时间步之间的冲突。
-
做小信噪比加权策略在小数据集上效果可能并不明显; 其对较大的数据集效果会更明显。
-
不同 � 值的效果比较: 你可在 这个 wandb 项目页面 上比较不同的
snr_gamma值 (5.0、1.0 及 None) 下的训练损失曲线。

训练
如欲使用最小信噪比 Gamma 法,推荐设置如下:
--snr_gamma=5.0默认情况下 --snr_gamma=None ,即不启用。启用 --snr_gamma 时,建议取值为 5.0。
图像样本重复次数
此参数指的是数据集中的图像在训练集中重复的次数。其与 epoch 的不同之处在于,图像首先被重复,然后才被打乱。
训练
要启用重复,只需将其设为一个大于 1 的整数:
--repeats默认情况下, --repeats=1 ,即不重复。
训练集创建
-
俗话说得好 - “垃圾进,垃圾出”,虽然仅需少量图像即可轻松训练一个好的 Dreambooth LoRA,但训练图像的质量对微调模型影响很大。
-
一般来说,在对特定对象或主题进行微调时,我们希望确保训练集中包含尽可能多样的关于该对象或主题的图像,且这些图像应尽量与后续应用场景相关。
-
例如,如果想让模型学到有关下面这个红色背包的知识: (该图来自 google/dreambooth 数据集)
-
我觉得后面用户有可能给一个某人背着包的提示,因此训练集中最好有下面这样的样本:

这样就能在训练时匹配推理时的应用场景,因此模型推理时就更容易外推至该类场景或者设定。
再举个例子 , 在 人脸 数据上进行训练时,在准备数据集时需要特别注意以下几点:
-
应尽可能选择 高分辨率、高画质 的图像。模糊或低分辨率的图像不利于微调结果。
-
在训练特定人物的人脸时,建议训练集中不要出现其他人的脸,因为我们不想对目标人脸产生模糊的概念。
-
特写照片 对于最终产生真实感的效果很重要,但是同时也应该包含好的全身照片,以提高对不同姿势/构图的泛化能力。
-
我们建议 避免纳入离拍摄主体较远的照片,因为此类图像中的大多数像素与我们希望优化的概念无关,模型可以从中学习的东西不多。
-
避免重复的背景/服装/姿势 —— 在灯光、姿势、背景和面部表情方面力求 多样性。多样性越大,LoRA 就越灵活、越通用。
-
先验保留损失先验保留损失是一种使用模型自己生成的样本来帮助其学习如何生成更多样化的图像的方法。由于这些图像样本与你提供的图像属于同一类,因此它们可以帮助模型保留已习得的有关该类的信息,并习得如何使用已知的该类的信息来形成新的组合。
用于正则化的真实图像 VS 模型生成的图像选择类图像时,你可以在合成图像 (即由扩散模型生成) 和真实图像之间进行选择。支持使用真实图像的理由是它们提高了微调模型的真实感。另一方面,有些人也会认为使用模型生成的图像可以更好地保留模型习得的 知识 及审美。
-
名人相 - 这主要与用于训练的描述文本或实例提示有关。当使用“令牌标识符 + 基础模型所知道的与待训练任务相似的公众人物”进行提示时,我们发现一些案例的微调效果得到了改善。
使用先验保留损失进行 训练:
--with_prior_preservation
--class_data_dir
--num_class_images
--class_prompt--with_prior_preservation - 启用先验保留训练--class_data_dir - 包含类图像的文件夹的路径--num_class_images - 先验保留损失所需的最小类图像数。如果 --class_data_dir 中没有足够的图像,则用 --class_prompt 采样出更多的图像。
实验与结果
讲了这么多,该挽起袖子试试了。我们在不同的任务 (风格化、人脸及特定对象) 上尝试了上述技术的不同组合。
为了减小超参搜索空间,我们使用一些流行配置作为起点,并基于此进行调整以达成效果。
Huggy Dreambooth LoRA
首先,我们想为 Huggy 微调一个 LoRA 模型,这意味着既要教会模型相应的艺术风格,同时还要教会它特定的角色。在这个例子中,我们制作了一个高质量的 Huggy 吉祥物数据集 (我们使用的是 Chunte-Lee 的艺术作品),该数据集包含 31 张图像及其对应的描述文本。

配置:
--train_batch_size = 1, 2,3, 4
-repeats = 1,2
-learning_rate = 1.0 (Prodigy), 1e-4 (AdamW)
-text_encoder_lr = 1.0 (Prodigy), 3e-4, 5e-5 (AdamW)
-snr_gamma = None, 5.0
-max_train_steps = 1000, 1500, 1800
-text_encoder_training = regular finetuning, pivotal tuning (textual inversion)-
文本编码器全模型微调 VS 枢轴微调 - 我们注意到枢轴微调取得了比文本编码器全模型微调更好的结果,且无需微调文本编码器的权重。
-
最小信噪比 Gamma 加权
-
我们比较了关闭
snr_gamma训得的 版本 1 以及使用snr_gamma = 5.0训得的 版本 2。
-
这两个版本都使用了以下参数 (但版本 2 多了一个
snr_gamma)
--pretrained_model_name_or_path="stabilityai/stable-diffusion-xl-base-1.0" \
--pretrained_vae_model_name_or_path="madebyollin/sdxl-vae-fp16-fix" \
--dataset_name="./huggy_clean" \
--instance_prompt="a TOK emoji"\
--validation_prompt="a TOK emoji dressed as Yoda"\
--caption_column="prompt" \
--mixed_precision="bf16" \
--resolution=1024 \
--train_batch_size=4 \
--repeats=1\
--report_to="wandb"\
--gradient_accumulation_steps=1 \
--gradient_checkpointing \
--learning_rate=1e-4 \
--text_encoder_lr=3e-4 \
--optimizer="adamw"\
--train_text_encoder_ti\
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--rank=32 \
--max_train_steps=1000 \
--checkpointing_steps=2000 \
--seed="0" \
-
AdamW 及 Prodigy 优化器
-
我们比较了使用
optimizer=prodigy训练的 版本 1 及使用optimizer=adamW训练的 版本 2。两个版本都使用枢轴微调进行训练。
-
使用
optimizer=prodigy进行训练时,我们将初始学习率设置为 1。而对 adamW,我们使用了 cog-sdxl 中用于枢轴微调的默认学习率 (learning_rate为1e-4,text_encoder_lr为3e-4),因为我们能够使用它们重现出较好的效果。

-
所有其他训练参数和设置均相同。具体如下:
--pretrained_model_name_or_path="stabilityai/stable-diffusion-xl-base-1.0" \
--pretrained_vae_model_name_or_path="madebyollin/sdxl-vae-fp16-fix" \
--dataset_name="./huggy_clean" \
--instance_prompt="a TOK emoji"\
--validation_prompt="a TOK emoji dressed as Yoda"\
--output_dir="huggy_v11" \
--caption_column="prompt" \
--mixed_precision="bf16" \
--resolution=1024 \
--train_batch_size=4 \
--repeats=1\
--report_to="wandb"\
--gradient_accumulation_steps=1 \
--gradient_checkpointing \
--train_text_encoder_ti\
--lr_scheduler="constant" \
--snr_gamma=5.0 \
--lr_warmup_steps=0 \
--rank=32 \
--max_train_steps=1000 \
--checkpointing_steps=2000 \
--seed="0" \Y2K 网页设计 LoRA
我们再探讨另一个例子,这次用另一个数据集,该数据集是我们从互联网上抓取的 27 个 20 世纪 90 年代和 21 世纪初的网页截图 (相当复古):
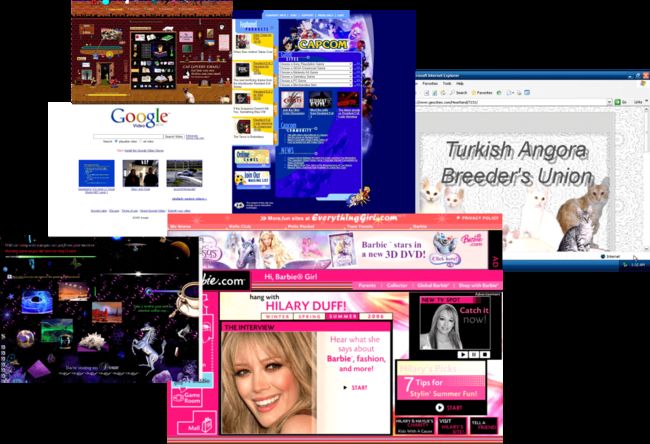
配置:
–rank = 4,16,32
-optimizer = prodigy, adamW
-repeats = 1,2,3
-learning_rate = 1.0 (Prodigy), 1e-4 (AdamW)
-text_encoder_lr = 1.0 (Prodigy), 3e-4, 5e-5 (AdamW)
-snr_gamma = None, 5.0
-train_batch_size = 1, 2, 3, 4
-max_train_steps = 500, 1000, 1500
-text_encoder_training = regular finetuning, pivotal tuning与前例略有不同,虽然我们使用的训练图像大致相同 (~30 张),但我们注意到,对于这种风格的 LoRA,在 Huggy LoRA 效果很好的设置对于网页风格来说表现出了过拟合。如下:
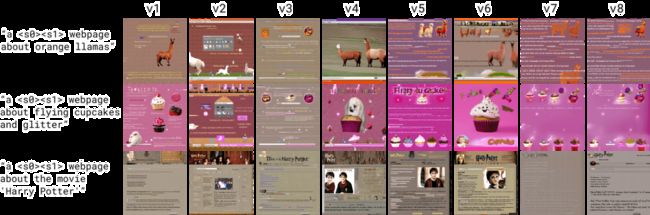
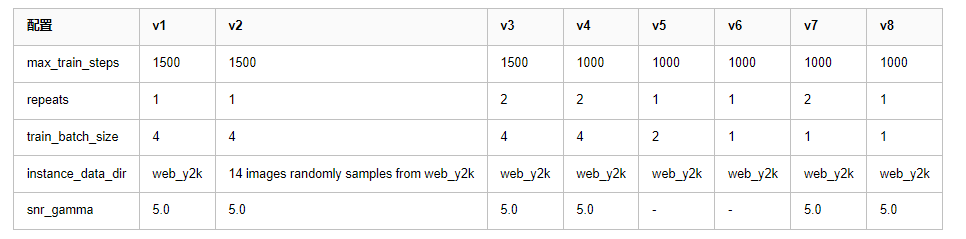
对于 v1,我们选择了训练 Huggy LoRA 时的最佳配置作为起点 - 显然过拟合了。因此我们尝试在下一个版本中通过调整 --max_train_steps 、 --repeats 、 --train_batch_size 以及 --snr_gamma 来解决这个问题。更具体地说,我们基于这四个配置迭代了 8 个版本,如下 (所有其余配置保持不变):
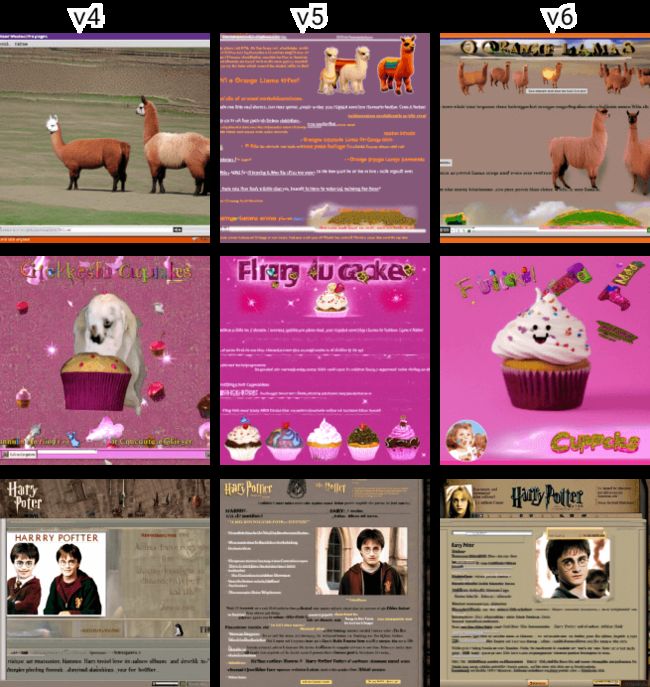
我们发现 v4、v5 及 v6 可以达到最佳的折衷效果:
人脸 LoRA
在人脸图像上进行训练时,我们的目标是让 LoRA 生成尽可能真实且与目标人物相似的图像,同时又能够很好地泛化至训练集中未见过的背景和构图。本例中,我们聚合了多个 Linoy 脸部数据集 (每个数据集含 6-10 张图像),其中包括一组同时拍摄的特写照片、不同场合的照片集 (不同的背景、灯光和服装) 以及全身照。
我们深知,如果由于照明/分辨率/聚焦上的问题导致图像的质量偏低,此时较少的高质图像比较多的低质图像的微调效果更好 - 少即是多,务必选择最好的照片来训练模型!
配置:
rank = 4,16,32, 64
optimizer = prodigy, adamW
repeats = 1,2,3,4
learning_rate = 1.0 , 1e-4
text_encoder_lr = 1.0, 3e-4
snr_gamma = None, 5.0
num_class_images = 100, 150
max_train_steps = 75 * num_images, 100 * num_images, 120 * num_images
text_encoder_training = regular finetuning, pivotal tuning-
先验保留损失
与通常的做法相反,我们发现使用生成的类图像会降低与目标人脸的相似性及生成图像的真实性。
我们利用从 unsplash 下载的开源图像创建了真实肖像的 数据集。现在,你也可以在我们创建的新 训练空间 中用上它!
当使用真实图像数据集时,我们注意到语言漂移更少 (即模型不会将“女人/男人”一词仅与经过训练的面孔相关联,而是可以生成不同的人) ; 同时在输入含经训练的人脸相关词元的提示词情况下,其生成又能保证真实感及整体质量。
-
秩
我们比较了秩设为 4、16、32 和 64 等不同值时的 LoRA。在这些实验中,我们发现秩为 64 的 LoRA 生成的图像磨皮效果更强,并且皮肤纹理看上去不太真实。
因此,在后面的实验以及 LoRA ease 空间 上,我们都把秩默认设为 32。
-
训练步数
尽管仅需很少高质图像 (在我们的例子中为 6) 就能达到好的训练效果,但我们仍需要确定模型训练的理想步数。
基于训练图像数,我们尝试了几种不同的乘数: 6 x75 = 450 步 / 6 x100 = 600 步 / 6 x120 = 720 步。
如下图所示,初步结果表明,使用 120 倍乘数效果较好 (如果数据集足够多样而不会过拟合,训练集中最好不要有相似的照片)

上图显示了使用 3 个训得的 LoRA (除了 --max_train_steps 之外的所有参数都保持相同) 生成的图像,具体配置如下:
rank = 32
optimizer = prodigy
repeats = 1
learning_rate = 1.0
text_encoder_lr = 1.0
max_train_steps = 75 * num_images, 100 * num_images, 120 * num_images
train_text_encoder_ti
with_prior_preservation_loss
num_class_images = 150推理
使用上述技术训练的模型的推理应该与任何其他训练器训得的模型的推理方式相同,不同之处在于,当我们进行枢轴微调时,除了 LoRA 的 *.safetensors 权重之外,还有经过训练的新词元及其文本嵌入模型的 *.safetensors 。为了对这些进行推理,我们在加载 LoRA 模型的方式上加了 2 个步骤:
-
从 Hub 下载经过训练的嵌入模型 (默认文件名为
{model_name}_emb.safetensors)
import torch
from huggingface_hub import hf_hub_download
from diffusers import DiffusionPipeline
from safetensors.torch import load_file
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
variant="fp16",
).to("cuda")
# download embeddings
embedding_path = hf_hub_download(repo_id="LinoyTsaban/web_y2k_lora", filename="web_y2k_emb.safetensors", repo_type="model")
-
将嵌入模型加载到文本编码器中
# load embeddings to the text encoders
state_dict = load_file(embedding_path)
# notice we load the tokens , as "TOK" as only a place-holder and training was performed using the new initialized tokens -
# load embeddings of text_encoder 1 (CLIP ViT-L/14)
pipe.load_textual_inversion(state_dict["clip_l"], token=["", ""], text_encoder=pipe.text_encoder, tokenizer=pipe. tokenizer)
# load embeddings of text_encoder 2 (CLIP ViT-G/14)
pipe.load_textual_inversion(state_dict["clip_g"], token=["", ""], text_encoder=pipe.text_encoder_2, tokenizer=pipe. tokenizer_2) -
加载你的 LoRA 并输入提示!
# normal LoRA loading
pipe.load_lora_weights("LinoyTsaban/web_y2k_lora", weight_name="pytorch_lora_weights.safetensors")
prompt="a webpage about an astronaut riding a horse"
images = pipe(
prompt,
cross_attention_kwargs={"scale": 0.8},
).images
# your output image
images[0] 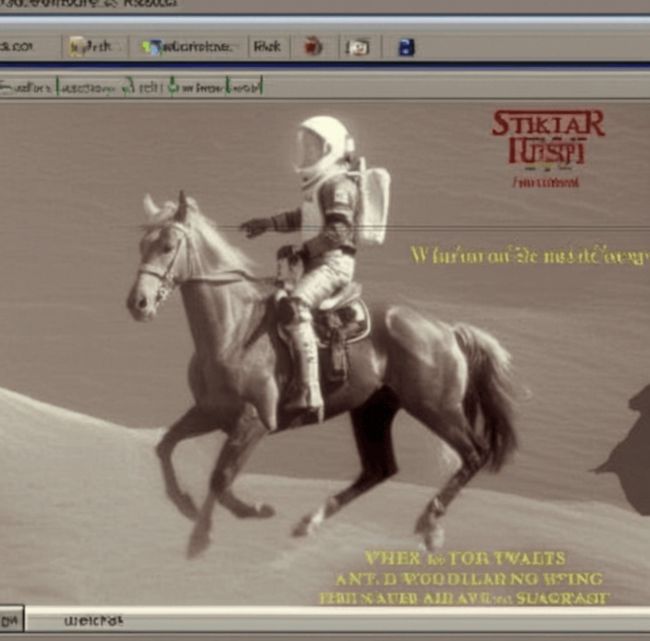
Comfy UI / AUTOMATIC1111 推理
最新的脚本完全支持 Comfy UI 和 AUTOMATIC1111 格式的文本逆化模型加载!
AUTOMATIC1111 / SD.Next
在 AUTOMATIC1111/SD.Next 中,我们同时加载 LoRA 和文本嵌入模型。
-
LoRA : 除了
diffusers格式之外,该脚本还将同时生成 WebUI 格式的 LoRA,其文件名为{your_lora_name}.safetensors。随后,你可以将其放入models/Lora目录中。
-
嵌入 :
diffusers和 WebUI 的嵌入文件格式相同。你可以直接下载已训练模型的{lora_name}_emb.safetensors文件,并将其放入embeddings目录中。
然后,你可以输入提示 a y2k_emb webpage about the movie Mean Girls lora:y2k:0.9 来运行推理。你可以直接使用 y2k_emb 词元,也可以通过使用 (y2k_emb:1.2) 来增加其权重。
ComfyUI
在 ComfyUI 中,我们会同时加载 LoRA 和文本嵌入。
-
LoRA : 除了
diffusers格式之外,该脚本还将训练 ComfyUI 兼容的 LoRA,其文件名为{your_lora_name}.safetensors。然后,你可以将其放入models/Lora目录中。然后,你需要加载 LoRALoader 节点并将其与你的模型和 CLIP 连接起来,详见 LoRA 加载官方指南
-
嵌入 : diffusers 和 WebUI 的嵌入格式相同。你可以直接下载已训练的模型的
{lora_name}_emb.safetensors文件,并将其放入models/embeddings目录中,并在你的提示中以embedding:y2k_emb的方式使用它,详见 加载嵌入模型的官方指南。
下一步
更多功能,即将推出!我们正在努力为我们的训练脚本添加更多高级功能,以允许用户施加更多的控制力,并支持更灵活的使用。如果你觉得哪些功能对你有帮助,请告诉我们!
多概念 LoRA
Shah 等人在最近的一项 工作 引入了 ZipLoRAs - 一种将多个独立训练的不同风格或主题 LoRA 模型合并起来的方法,以支持以用户指定的任意风格生成用户指定的任意主题图像。mkshing 实现了此方法的一个开源复现,见 此处,其使用了我们新改进的 脚本。
文章转载自:HuggingFace
原文链接:https://www.cnblogs.com/huggingface/p/18008827
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构