渗透测试-信息打点与架构分析细节梳理
渗透测试-信息打点与架构分析细节梳理
为了保障信息安全,我在正文中会去除除靶场环境的其他任何可能的敏感信息
什么是网站架构
网站架构包括网站的方方面面,下面是常见的内容:
-
前端(Front-End): 使用React、Angular、Vue等前端框架进行页面构建。前端框架可以帮助组织和管理页面的结构,提高开发效率,同时提供更好的用户交互体验。
-
后端(Back-End): 使用Node.js、Django、Ruby on Rails等后端框架。后端框架用于处理业务逻辑、数据库交互和服务器端的功能,提供API供前端调用。
-
数据库: 使用MySQL作为关系型数据库,或者MongoDB作为非关系型数据库。数据库的选择取决于数据结构和访问模式,关系型数据库适用于复杂的关联数据,而非关系型数据库适用于文档型数据存储。
-
服务器: 使用Nginx或Apache作为Web服务器,同时可能使用Tomcat或其他应用服务器来运行后端应用程序。Web服务器负责接收用户请求并将其转发给后端应用服务器,应用服务器处理业务逻辑。
-
负载均衡(Load Balancer): 使用负载均衡器,如HAProxy或NGINX。负载均衡器可以分配流量到多个服务器,以确保各服务器负载均衡,提高网站的可用性和性能。
-
缓存系统: 使用Memcached或Redis作为缓存系统。缓存系统可以存储常用的数据,减轻数据库负担,提高响应速度。
-
安全性: 使用SSL证书来加密数据传输,配置防火墙规则来防御恶意攻击。安全性是网站架构中至关重要的一部分,确保用户数据的保密性和完整性。
-
扩展性: 通过水平扩展,增加服务器数量,或者通过垂直扩展,提升服务器性能。扩展性确保网站能够适应不断增长的用户和流量,保持高性能和稳定性。
-
日志记录和分析: 使用ELK Stack(Elasticsearch、Logstash、Kibana)进行日志分析。日志记录和分析可以帮助监测性能,识别问题并进行及时的优化。
-
版本控制: 使用Git进行版本控制。版本控制确保团队能够协同工作,跟踪代码变更,同时提供回滚和历史记录功能。
-
中间件(Middleware): 使用消息队列中间件,如RabbitMQ或Kafka。中间件在不同组件之间传递信息,帮助解耦系统,提高系统的可维护性和灵活性。
中间件/服务器/Web容器
概念与常见例子:
-
Web 服务器(Web Server):
- 概念: Web 服务器是一个软件或硬件,用于接收和响应来自客户端浏览器的 HTTP 请求。它主要负责处理静态资源(如 HTML、CSS、JavaScript 文件)的请求,并将它们发送给客户端。常见的 Web 服务器包括 Apache HTTP Server、Nginx、Microsoft IIS 等。
- 作用: 处理 HTTP 请求,发送静态内容,以及管理网络连接。
-
Web 中间件(Web Middleware):
- 概念: Web 中间件是位于客户端和服务器端之间的软件,用于处理特定的业务逻辑、请求过滤、认证、授权等。它在应用服务器和客户端之间起到中介作用,提供一些额外的功能,例如负载均衡、缓存、安全性等。
- 作用: 提供附加的服务和功能,增强应用的性能和安全性。常见的 Web 中间件包括反向代理服务器、负载均衡器、Web Application Firewall 等。
-
Web 容器(Web Container):
- 概念: Web 容器是一种运行在服务器上的应用程序环境,用于托管和执行 web 应用程序。它支持执行服务器端脚本、处理动态内容和与应用程序服务器通信。通常,Web 容器也被称为 Servlet 容器,因为它最常用于托管 Java Servlets。
- 作用: 提供一个运行环境,支持 web 应用程序的执行,处理动态内容,以及与应用服务器的交互。
区别:
- Web 服务器 vs. Web 中间件: Web 服务器主要处理 HTTP 请求,提供静态内容,而 Web 中间件提供额外的服务和功能,例如负载均衡、安全性等。
- Web 中间件 vs. Web 容器: Web 中间件通常是通用性的,提供各种服务,而 Web 容器更专注于托管和执行 web 应用程序,尤其是处理动态内容。
拓展资料:
在实际应用中,这些概念通常会交叉使用,特别是在复杂的 web 应用程序架构中。例如,一个 web 应用程序可能同时使用 Nginx(Web 服务器和反向代理,也可视为中间件)和 Tomcat(作为 Servlet 容器)来构建完整的架构。
在一些情况下,类似 Apache 等 Web 服务器可以在容器中运行,而中间件(例如反向代理、负载均衡器)负责调控流量和提供额外的服务。这种方式的部署很常见,特别是在使用容器编排工具如 Kubernetes(K8s)的场景中。
在 Kubernetes 中,你可以将整个应用程序打包成一个或多个容器,并在集群中运行这些容器。每个容器可以包含一个特定的组件,比如 Apache 服务器或其他 Web 服务器。然后,你可以使用 Kubernetes 的服务和负载均衡功能来管理这些容器,并通过添加中间件组件(例如 Ingress 控制器)来处理流量的路由、负载均衡等任务。
部署 Apache 服务器容器:
- 你可以创建一个 Docker 镜像,其中包含 Apache 服务器及其配置。
- 将这个 Docker 镜像部署到 Kubernetes 中,以创建一个运行 Apache 服务器的容器实例。
使用 Ingress 控制器进行流量调控:
- 部署一个 Ingress 控制器,它是 Kubernetes 中的一个中间件组件,负责处理外部流量的路由。
- 配置 Ingress 控制器,使其将特定的流量路由到 Apache 服务器容器。
中间件负责调控:
- 在这个示例中,Ingress 控制器可以被视为中间件,它负责调控流量、提供负载均衡等功能。
这种部署方式的好处在于,可以更灵活地管理和调整每个组件,而不必将所有功能都打包到一个容器中。这使得应用程序更易于扩展、维护和升级。
基础信息获取
基本架构,系统信息,应用信息,人员信息,防护措施,其他泄露
信息越是充足,胜算越有把握
通吃方法-不一定准确
搜索常见的网站架构如以下例子:
| 技术栈 | 组件 |
|---|---|
| WordPress,Drupal等 | Web服务器: Apache(或Nginx),编程语言: PHP,数据库: MySQL(或其他) |
| IIS 服务器 | Web服务器: IIS,编程语言: ASP,.NET(C#),数据库: SQL Server(或其他) |
| MEAN 栈 | 数据库: MongoDB,服务器框架: Node.js与Express.js,前端框架: AngularJS(或Angular) |
| Java | 编程语言: Java,应用服务器: Tomcat(或其他),数据库: MySQL、PostgreSQL、Oracle等 |
判断程序语言与服务器软件
- URL尾缀程序信息:尾缀为php,jsp等等,不过现在大多数网站会做路由或前后端分离,可能会看不出来
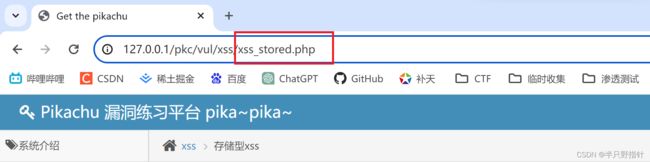
- 数据包请求内容,通常情况下Sever字段和set-Cookie等等与后端交互字段会出现关键信息

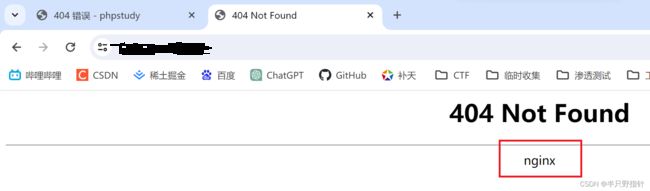
- 引发错误页面进行判断
- 在招聘网站搜索目标厂商,这种方法算是比较抽象的
通常情况下,我们可以通过厂商再找什么样的开发人员,来确定其站点的开发语言,通过其简历要求来判断可能的架构信息,毕竟你招个Java的开发大佬,也不太现实叫他来写PHP吧
判断数据库与服务器
判断数据库除了对应上面的通吃方法之外,就只剩下了端口服务扫描或其他引擎搜索,在得到扫描端口结果后也能发现服务器的些许踪迹,通常我们会借助第三方工具,如在线扫描等:

为何端口扫描判断服务开闭有时不够准确?
端口扫描通常通过发送网络请求到目标设备的特定端口,并根据收到的响应来判断端口是否开放。然而,有时端口扫描的准确性可能受到一些因素的影响,使判断不够准确。以下是一些可能的原因:
- 防火墙设置: 目标设备上的防火墙可能会阻止对某些端口的扫描请求。这可以是因为网络管理员的安全策略,为了防范恶意扫描或攻击。
- 过滤器和IPS/IDS设备: 网络中的过滤器、入侵检测系统(IDS)和入侵防御系统(IPS)等安全设备可能会检测到端口扫描活动并采取防御措施,包括丢弃扫描请求或生成虚假响应。
- 服务伪装: 有些服务可能会伪装其响应,使其看起来像其他服务或端口关闭。这可以是为了防止被扫描者发现真实的服务版本和漏洞。
- 反欺骗技术: 一些网络设备可能采用反欺骗技术,例如低级别的TCP连接回应,以混淆扫描器。这使得扫描器难以区分端口的真实状态。
- 动态端口分配: 一些服务使用动态端口分配,它们的端口在运行时动态分配,而不是固定的。这使得端口扫描器难以预测服务监听的确切端口。
- 响应延迟: 有时网络或目标设备的响应可能受到延迟的影响,这可能导致扫描器未能及时收到响应,从而导致对端口状态的错误判断。
- 主机蜜罐: 恶意攻击者可能在网络中设置蜜罐(Honeypot)来引诱扫描者。蜜罐通常模拟易受攻击的系统,而实际上可能是监控设备,会故意提供虚假的端口开放信息。
- **CDN分发:**有些大型网站使用CDN分发技术后,你的扫描有可能只是扫描的分发内容的服务器,需要真实IP才有可能扫描到服务,另外也不排除站库分离等架构干扰
判断OS类型
一般来讲服务器的OS都是Linux,Windows的较为少见
- 通过大小写判断服务端的OS类型,如下所示,我的本地linux网站改大写会出现访问失败的情况
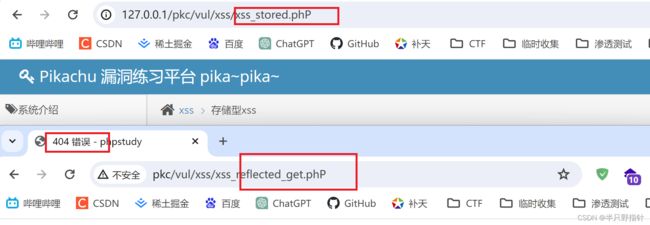
注意:此方法不一定准确,有的中间件等会对大小写有处理,还有网站路由的建立也会影响
- 通过TTL值判断OS的类型
这个方法也不准确,因为这个玩意是可以根据需求进行修改的
操作系统的 TTL(Time To Live)值是 IP 数据包在网络上通过路由器时递减的数值,通常以秒为单位。不同的操作系统和设备对 TTL 的初始值有一些差异。请注意,TTL 的值不同于设备之间传递的实际时间,而是表示数据包在网络上可以经过的最大跃点数。
以下是一些常见操作系统的 TTL 初始值:
| 操作系统 | 初始 TTL 值 |
|---|---|
| Windows | 128 |
| Linux/Unix | 64 |
| macOS | 64 |
| Cisco IOS | 255 |
| FreeBSD | 64 |
| AIX | 60 |
| Solaris | 255 |
| HP-UX | 60 |
| Juniper Junos | 64 |
| Android | 64 |
| iOS (iPhone) | 64 |
这些值是一般性的估计,实际上可能有一些变化,特别是在特定设备和操作系统的配置中。不同的网络设备和操作系统可能会设置不同的初始 TTL 值。在进行网络分析或故障排除时,了解不同操作系统的 TTL 值可以帮助判断数据包的路径和经过的路由器数量。
使用Wappalyzer插件
上述信息手动识别过于繁琐,使用插件更加方便
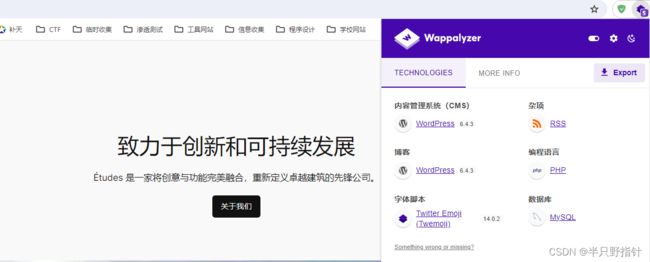
获取网站可能的源码
- 基于开源CMS搭建网站,如以下三位常客:
| CMS | 官网 |
|---|---|
| WordPress | https://wordpress.com/zh-cn/ |
| Durpal | https://www.drupal.org/ |
| Joomla | https://www.joomla.org/ |
有可能会在页脚暴露
- 闭源售卖产品,可以到一些售卖站进行查找,记得根据类型有自己的关键字
- 自主研发的网站
绝大数较大厂商的站点都是自主研发,几乎没有可能泄露,此时考虑的则是源码泄露问题或者其开发人员的编写习惯,比如一个不小心推到托管网站了,或者说有些人提前帮你搞出来了:
请记住,违法的事情千万不要做,没钱去干
Java开发都行(bushi

其他公开信息搜集
- 搜集目标的公众号等公开信息
| 信息点 | 描述 |
|---|---|
| 公众号或内部通信 | 有可能出现员工统一活动平台,像高校事务大厅那样的平台 |
| 企业备案查询 | 有可能出现联系方式或其他可能的遗留信息 |
| 公开联系方式 | QQ,微信客服等,搞不好出弱口令也是可能的 |
| 网盘资源 | 部分管理人员可能会在网盘中共享一些文件,搞不好也有源码泄露和社工信息 |
| 招聘要求 | 根据人员要求猜架构等等 |
| 企业服务器提供商 | 备案有时候挺方便的。。。。 |
| 项目招标情况 | 有可能会出现大量的泄露信息,不过少见 |
| 企业信用与个人征信 | 也是社工信息泄露了 |
| 网页注释 | 有些开发人员的习惯可能会导致测试信息泄露,如果接口未关闭,可能有戏 |
| whois信息 | 基本操作了,讲真备案有时候挺方便的。。。。 |
| 挖掘子域名等等 | 有时候你会发现主站是Java,但是会出现小站是PHP,世界上最好的语言一出现,八成有戏 |
Google搜索语法
| 语法 | 描述 |
|---|---|
site: |
指定域名 |
intext: |
正文中存在关键字的网页 |
intitle: |
标题中存在关键字的网页 |
info: |
一些基本信息 |
inurl: |
URL存在关键字的网页 |
filetype: |
搜索指定文件类型 |
取得源码的多种方式
-
网站管理员可能会将备份文件等作为压缩包放在网站根目录,这时候我们大多数情况下可以使用目录爆破来获取可能存在的目录
-
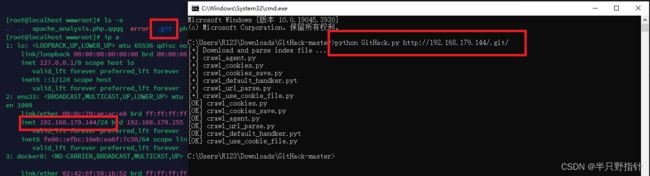
在网站开发时通常会使用分支管理工具git或者svn,我们可以通过对应的分支管理文件将整个网站的源码扒下来,例如git我们可以利用githack(对应也有svnhack)来获得源码:
- 部分网站可能使用mac或其他压缩软件(解压后存在一个索引文件)进行手动部署,那么也有可能会造成源码泄露,对应也有还原工具
- github上有时候多逛逛会有惊喜,下面是常用语法
| 语法 | 描述 |
|---|---|
filename:example.txt |
搜索特定文件 |
extension:php |
搜索特定文件类型 |
code keyword |
搜索代码中包含的关键字 |
language:python |
搜索指定语言的项目 |
user:username |
搜索指定用户的项目 |
org:organization |
搜索包含某个组织的项目 |
path:/path/to/code |
搜索特定路径下的文件或项目 |
stars:>100 |
搜索星标数量大于等于某个值的项目 |
pushed:>2022-01-01 |
搜索更新时间在某个时间之后的项目 |
repo:example* |
搜索以某个关键字开头的项目 |
in:readme keyword |
搜索包含某个关键字的README文件 |
language:python stars:>50 |
组合多个搜索条件 |
- composer.json文件泄露
composer.json 文件是 PHP 项目中使用 Composer 工具的配置文件。Composer 是 PHP 的依赖管理器,用于管理项目中的依赖关系,例如库和框架。composer.json 文件定义了项目的依赖项、自动加载规则、脚本和其他配置信息。
网络架构信息获取
一般来讲企业一般会将机房内网的一台或几台机器,通过nat技术映射到外网出口,使得我们从外部探测只能摸到外网出口,此时我们需要摸清这个映射出来的暴露面关联了哪些服务,开放了哪些应用协议:ssh,ftp,redis,telnet协议等,能不能通过这些协议摸到运维人员,或者说能不能找到较为隐蔽的资产,例如暴露在外的缓存服务器等等,通过某一薄弱资产进行横向移动。需要注意的是,内容分发网络CDN、WAF、防火墙和负载均衡将会影响我们的判断。
常用的工具有:
super ping:常用于识别CDN服务,从中找到的重复ip就有可能是真实ip
Masscan:常用于探测端口服务,与应用协议
Wafw00f:用于对web应用进行防火墙识别,针对于某些防火墙有特殊的绕过方法
Nmap:常用于端口扫描,应用协议识别与内网主机存活探测
lbd:用于进行负载均衡,广域网负载均衡,应用层负载均衡识别
绕过CDN找寻真实IP
CDN内容分发网络用于分发主站的各种数据,它的存在可能会干扰我们找寻真实IP,通常有以下策略进行绕过操作:
- 超级ping域名,出现的重复IP有可能就是真实IP
- 子域名查询,因为CDN只会分发指定的域名,如果说子域名与主站在同一IP上解析,那么就能够找到真实的IP
- 如果有机会,可以得到CDN服务的管理入口和权限也可以
- 通过存在的可能的邮件服务器进行寻找,一般邮件服务器都是内部服务器,大概率是不会使用CDN的
- 通过CDN分发区域入手,通过国外的DNS等进行访问,如果在CDN加速服务区域外,那么就可以找到真实IP,因为请求的可能就是目标主机
- 遗留文件的内容泄露,如phpinfo文件,将会暴漏服务器的真实IP,如果服务器处于内网看到的将会是内网中的地址
- 利用ssrf漏洞让目标来访问我们的傀儡服务器,解析过后就是真实的IP

移动端资产搜集
移动端信息收集涉及的方面与前面的区别不大,不过多一个反编译资产收集(借助反编译软件抓取调用接口),也涉及到软件加壳等技术
常用的工具有:
AppInfoScanner:https://github.com/kelvinBen/AppInfoScanner
Fiddler:用于抓取软件数据封包分析
FOFA:在获取软件的资源后,搜索标志资源将可能获得一些隐秘资产
FOFA的常见语法
FOFA(Focus on Finding Attackers)是一款专注于网络安全的搜索引擎,它的主要作用是帮助安全研究人员、渗透测试人员和安全管理员快速有效地查找与目标相关的网络资产和信息。FOFA的搜索引擎不同于一般的搜索引擎,它专注于收集和索引与网络安全相关的信息,包括设备、服务、协议、漏洞等
| 语法 | 描述 |
|---|---|
| host | 搜索指定域名或 IP 地址 |
| port | 搜索指定端口的设备 |
| protocol | 搜索指定协议的设备(如 HTTP、FTP) |
| city | 搜索指定城市的设备 |
| country | 搜索指定国家的设备 |
| asn | 搜索指定自治系统号的设备 |
| header | 搜索指定 HTTP 头信息的设备 |
| banner | 搜索指定服务 banner 的设备 |
| cert | 搜索指定 SSL 证书信息的设备 |
| cidr | 搜索指定 CIDR 范围的设备 |
| ip | 搜索指定 IP 地址的设备 |
| domain | 搜索指定域名的设备 |
| title | 搜索网页标题包含指定关键词的设备 |
| header | 搜索 HTTP header 中包含指定关键词的设备 |
| body | 搜索网页内容中包含指定关键词的设备 |
UAKE的常见语法
| 语法 | 说明 | 范例 |
|---|---|---|
| ip | 支持检索单个IP、CIDR地址段、支持IPv6地址 | ip:“1.1.1.1” ip: “1.1.1.1/16” |
| domain | 网站域名信息 | domain:“360.cn” |
| port | 单一端口 | port:“80” |
| ports | 同时开放多端口 | ports:“80,8080,8000” |
| service | 协议和服务 | service:“http” |
| services | 协议和服务 | services:“rtsp,https,telnet” |
| cert | SSL\TLS证书信息 | cert:“baidu.com” cert:“TLSv1.2” |
| country | 位置和属地 | country:“China” |
| province | 位置和属地 | province:“shanxi” province:“Inner Mongolia” |
| city | 位置和属地 | city:“beijing” |
其他工具推荐
坤舆:https://github.com/knownsec/Kunyu
finger:https://github.com/EASY233/Finger
灯塔:https://github.com/TophantTechnology/ARL
水泽:https://github.com/0x727/ShuiZe_0x727