【AutoML】AutoKeras 数据清洗与简单提纯
从上一章节可知,数据已经从 4 个数据源获取过来并已全部入库。目前数据库共分出 11 张表,如下图:
mysql> use phw2_industry_bot;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+-------------------------------+
| Tables_in_phw2_industry_bot |
+-------------------------------+
| baike_dataset_train |
| baike_dataset_valid |
| cmedqa_dataset_answer_train |
| cmedqa_dataset_question_train |
| cmedqa_dataset_train |
| huatuo_dataset_lite_train |
| huatuo_dataset_total_test |
| huatuo_dataset_total_train |
| huatuo_dataset_total_valid |
| paddle_dataset_train |
| paddle_dataset_valid |
+-------------------------------+
11 rows in set (0.01 sec)
mysql>
有了这 11 张表之后,接下来就要为每一个数据源做初步的数据清洗操作,我的思路大致如下:
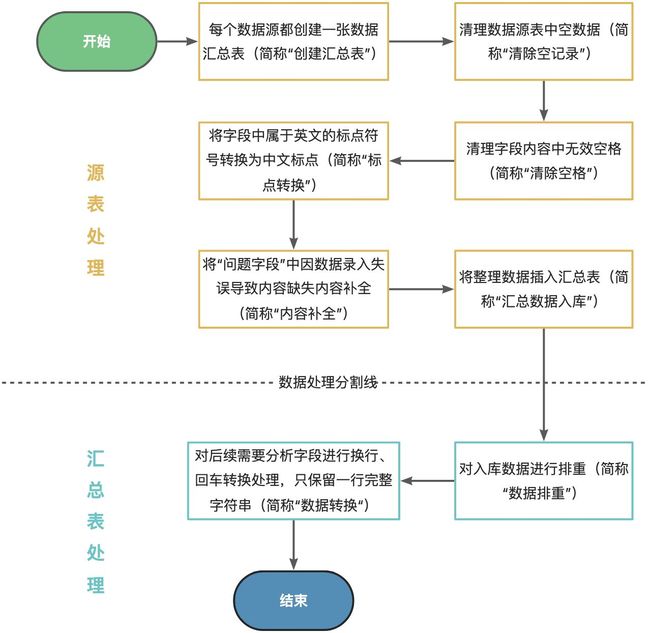
- 将数据源表中关键字段内容“为空”的数据清理掉。一般来说关键字段不应该为空,或许是 txt 在源数据导出的时候错位了,或许字段数据做脱敏时出现误操作了…这些都说不准的,但的确存在这种情况出现,因此删除掉这些空数据还是有必要的;
- 将字段中无效空格清理掉。由于部分数据源是通过爬虫收集回来的(可以看得出来数据源作者是通过爬虫得到的数据),出现无用空格也实属正常,但是做训练的时候最好就不要保留这些多余的空格了,因此需要对整个字段进行“去空格”操作。那遇到“有效空格”怎么办?额…暂时先不考虑吧,在我这里“有效空格”情况太少,不要花太多时间去考虑那 1% 的可能性,先将实打实的东西做出来先;
- 将字段中哪些英文标点全部转换为中文的。正确来说是将所有英文的保留关键字(标点、字符串)全部替换成中文全角,这个就不多说了;
- 将问题中缺失问题补全。这个其实应该叫问题调整。有的问题是会出现“追问”的情况的,譬如:_“我家宝宝腿和脚一抓就起小疙瘩,特痒。请问是不是荨麻疹?怎么治疗?”偏偏不巧的是这个问题的第二问还被截断了,如:“我家宝宝腿和脚一抓就起小疙瘩,特痒。请问是不是荨麻疹?怎么”_这个时候就要进行调整,将第二个问的内容给删除掉,保证一个问题的内容是完整的;
- 在数据进入汇总表之后就要做一次排重的操作。因为数据有可能来自 train 表,也有可能来自 valid 表,因此出现两条相同数据的情况还是会存在的,这里排重做一下处理;
- 最后进行一下换行的处理。就像我刚才说的,数据源有可能是爬虫得来的,因此换行、回车这些格式会有很大可能被保留下来的,为了保证数据读取的完整性取消所有换行;
这一套流程下来后基本能将数据中一眼看出的“不规范”内容清洗掉,经过初步清洗后的数据将会等待“提纯”(或许这里的清洗条件还不够细致,欢迎各位给我提一些更细致的清洗规则,帮助我逐步完善这套清洗流程)。下面将以 baike 数据集为例,对应上面的流程图逐步进行说明。
1. 数据清洗
1.1 创建汇总表
CREATE TABLE `baike_dataset` (
`ID` BIGINT NOT NULL AUTO_INCREMENT,
`CATEGORY` VARCHAR(128) NOT NULL COMMENT '标签分类',
`QUESTION` TEXT NOT NULL COMMENT '问题内容',
`ANSWER` LONGTEXT NOT NULL COMMENT '回答内容',
`FLAG` INT NOT NULL DEFAULT 0,
PRIMARY KEY (`ID`),
INDEX `IDX_BD_CATEGORY` (`CATEGORY` ASC) VISIBLE)
ENGINE = MyISAM
DEFAULT CHARACTER SET = utf8mb4
COLLATE = utf8mb4_unicode_ci
COMMENT = '百科数据集(用于数据训练)';
由于训练只关注 Q(QUESTION) & A(ANSWER)两个字段,因此汇总表并不需要太多字段,其中 QUESTION 采用 Text 数据类型,而 ANSWER 采用 LongText 数据类型。之所以 ANSWER 字段用了 LongText 类型是为了保证外部数据能被字段全部保存。
此外,由于 ANSWER 字段中会存在 emoji 表情,因此汇总表将采用 utf8mb4 编码并使用 utf8mb4_unicode_ci 进行排序比较。当然了这个表也是读多写少,因此数据库引擎肯定是选 MyISAM 的。
1.2 清除空记录
-- 先清理没有回答(ANSWER)的内容
-- baike_dataset_train 表
DELETE FROM baike_dataset_train WHERE answer IS NULL OR answer = '';
-- baike_dataset_valid 表
DELETE FROM baike_dataset_valid WHERE answer IS NULL OR answer = '';
由于汇总表中所有字段都必须非空,因此需要将 ANSWER 字段为空的记录先删除。既然没有回答那么这条记录就没有意义了。
1.3 清除空格
-- 将字段中多余的空白内容清除
-- baike_dataset_train 表
UPDATE baike_dataset_train a SET a.title = TRIM(a.title),a.desc = TRIM(a.desc),a.answer = TRIM(a.answer);
-- baike_dataset_valid 表
UPDATE baike_dataset_valid a SET a.title = TRIM(a.title),a.desc = TRIM(a.desc),a.answer = TRIM(a.answer);
UPDATE baike_dataset_valid a SET a.title = replace(a.title,' ',''),a.desc = replace(a.desc,' ',''),a.answer = replace(a.answer,' ','');
若原表中内容出现空格,会影响程序的统一处理,如:字符串截取、数据分割、数据提取等等,因此需要将关键字段的内容中空格内容先清理掉。
1.4 标点转换
-- 将字段中英文标点符号转换为中文标点符号(包括“,”、“?”和“!”)
-- baike_dataset_train 表
UPDATE baike_dataset_train a SET a.title = replace(a.title,',',','),a.desc = replace(a.desc,',',','),a.answer = replace(a.answer,',',',');
UPDATE baike_dataset_train a SET a.title = replace(a.title,'?','?'),a.desc = replace(a.desc,'?','?'),a.answer = replace(a.answer,'?','?');
UPDATE baike_dataset_train a SET a.title = replace(a.title,'!','!'),a.desc = replace(a.desc,'!','!'),a.answer = replace(a.answer,'!','!');
-- baike_dataset_valid 表
UPDATE baike_dataset_valid a SET a.title = replace(a.title,',',','),a.desc = replace(a.desc,',',','),a.answer = replace(a.answer,',',',');
UPDATE baike_dataset_valid a SET a.title = replace(a.title,'?','?'),a.desc = replace(a.desc,'?','?'),a.answer = replace(a.answer,'?','?');
UPDATE baike_dataset_valid a SET a.title = replace(a.title,'!','!'),a.desc = replace(a.desc,'!','!'),a.answer = replace(a.answer,'!','!');
因为英文标点有可能会引起关键字或者分词错误,因此需要将内容中关于英文的标点符号全部先转换为中文样式。
1.5 内容补全和汇总数据入库
-- 将原表数据整理之后插入汇总表 baike_dataset 中
-- baike_dataset_train 表
-- 1. 先找到不是“。”、“?”、“!”和“)”结尾的所有记录,并且整理好 title 和 desc 字段后将两个字段内容融合,将最终结果插入到汇总表 baike_dataset 中
INSERT INTO baike_dataset (CATEGORY,QUESTION,ANSWER)
SELECT a.category, CONCAT(REVERSE(SUBSTR(REVERSE(a.title) FROM INSTR(REVERSE(a.title),',')+1)),'。',a.desc) title_desc,a.answer
FROM baike_dataset_train a
WHERE LENGTH(a.title) > 0 AND (SUBSTRING(a.title, - 1) != '。' AND SUBSTRING(a.title, - 1) != '?' AND SUBSTRING(a.title, - 1) != '!' AND SUBSTRING(a.title, - 1) != ')');
-- 2. 将 1 中条件作为数据集“反面”用于数据集中的排除,将剩余的数据集进行整理并插入到汇总表 baike_dataset 中
INSERT INTO baike_dataset (CATEGORY,QUESTION,ANSWER)
SELECT a.category,CONCAT(a.title,'。',a.desc) title_desc,a.answer FROM baike_dataset_train a WHERE ID NOT IN (
SELECT ID
FROM baike_dataset_train a
WHERE LENGTH(a.title) > 0 AND (SUBSTRING(a.title, - 1) != '。' AND SUBSTRING(a.title, - 1) != '?' AND SUBSTRING(a.title, - 1) != '!' AND SUBSTRING(a.title, - 1) != ')'));
-- baike_dataset_valid 表
-- 3. 先找到不是“。”、“?”、“!”和“)”结尾的所有记录,并且整理好 title 和 desc 字段后将两个字段内容融合,将最终结果插入到汇总表 baike_dataset 中
INSERT INTO baike_dataset (CATEGORY,QUESTION,ANSWER)
SELECT a.category, CONCAT(REVERSE(SUBSTR(REVERSE(a.title) FROM INSTR(REVERSE(a.title),',')+1)),'。',a.desc) title_desc,a.answer
FROM baike_dataset_valid a
WHERE LENGTH(a.title) > 0 AND (SUBSTRING(a.title, - 1) != '。' AND SUBSTRING(a.title, - 1) != '?' AND SUBSTRING(a.title, - 1) != '!' AND SUBSTRING(a.title, - 1) != ')');
-- 4. 将 3 中条件作为数据集“反面”用于数据集中的排除,将剩余的数据集进行整理并插入到汇总表 baike_dataset 中
INSERT INTO baike_dataset (CATEGORY,QUESTION,ANSWER)
SELECT a.category,concat(a.title,'。',a.desc) title_desc,a.answer FROM baike_dataset_valid a WHERE ID NOT IN (
SELECT ID
FROM baike_dataset_valid a
WHERE LENGTH(a.title) > 0 AND (SUBSTRING(a.title, - 1) != '。' AND SUBSTRING(a.title, - 1) != '?' AND SUBSTRING(a.title, - 1) != '!' AND SUBSTRING(a.title, - 1) != ')'));
先通过查询获取到标题内容,标题内容可能会存在被截断的可能性,因此需要根据最后一个“,”进行文字回溯,遇到第一个“,”后以此为下标,保留第一个字符串开始到这个下标为止的所有字符串,并且与描述字段相结合形成新的“问题”内容,最后将这部分数据整理出来插入到汇总表。
1.6 数据排重
-- 删除汇总表中重复的记录
DELETE FROM baike_dataset
WHERE id IN (SELECT e.id FROM
(SELECT d.question, d.answer, MIN(d.id) id FROM
(SELECT * FROM baike_dataset c WHERE (c.question , c.answer) IN
(SELECT b.question, b.answer FROM
(SELECT a.question, a.answer, COUNT(1) AS counter FROM baike_dataset a GROUP BY a.question , a.answer) b
WHERE b.counter > 1)
) d
GROUP BY d.question , d.answer
) e
);
数据插入汇总表之后可以通过自查进行数据排重。
1.7 数据转换
-- 将汇总表中问题和回答中的所有回车和换行的行为转换为逗号处理重新整合成一条完整的字符串(为后续提取内容做准备)
UPDATE baike_dataset
SET answer = REGEXP_REPLACE(answer, '[\r\n]', ','),
question = REGEXP_REPLACE(question, '[\r\n]', ',');
最后将汇总表中字段进行回车、换行符替换,将其做成完整一条字符串。至此完成了数据的初步清洗。
在完成了初步的数据清洗之后就可以对数据进行提纯,所谓的提纯就是将一些与目标数据无关的“杂质”剔出掉。由于我需要的是与“中药材”相关的问答数据,因此无关的数据必须删掉以保证数据质量。
2. 数据提纯
2.1 第一次提纯
第一次要对明确确定范围的内容先进行提取。如下图:
-- 将明确与中药有关的内容先确定下来设置 flag 状态为 1
UPDATE baike_dataset a SET a.flag = 1 WHERE a.category LIKE '%中药%';
通过 CATEGORY 字段可以检测到具体哪些问答属于中药材领域的,将状态设置为 1。后续将会以 flag 字段作为“已处理”和“未处理”依据来区分数据记录。
2.2 第二次提纯
第二次则需要额外数据源辅助比对,这里选用了公司原有的品种库数据得到了一个 1276 条品种名称的数据集。如下图:
mysql> SELECT count(1) FROM variety_dataset;
+----------+
| count(1) |
+----------+
| 1276 |
+----------+
1 row in set (0.01 sec)
以 variety_dataset 表数据集为关键字,对汇总表中“问题(QUESTION)”和“回答(ANSWER)”字段内容进行比对,python 关键代码如下图所示:
def analyze_content_by_tags():
start_time = time.time()
conn = mysql_util.get_connection()
# 查询品种名称数据集
vd_cursor = conn.cursor()
vd_cursor.execute("SELECT ID,NAME FROM variety_dataset")
vd_list = vd_cursor.fetchall()
vd_cursor.close()
# 查询汇总表中“未处理”数据集
bd_cursor = conn.cursor()
bd_cursor.execute(
"SELECT ID,QUESTION,ANSWER FROM baike_dataset WHERE flag = 0")
bd_list = bd_cursor.fetchall()
bd_cursor.close()
counter = 0
try:
with conn.cursor() as ud_cursor:
# 遍历未处理数据集获取 id、question 和 answer 字段数据
for bd_row in bd_list:
ids = bd_row[0]
question = bd_row[1]
answer = bd_row[2]
# 遍历品种名称数据集
for vd_row in vd_list:
# 将品种名称作为关键字与 question 和 answer 字段内容进行对比
if vd_row[1] in (question or answer):
# 若两个字段内容中都包含关键字,则根据该条记录的 id 对记录进行 flag = 1 的数据更新
ud_sql = "UPDATE baike_dataset SET flag = 1 WHERE ID = " + \
str(ids)
ud_cursor.execute(ud_sql)
counter = counter + 1
print("need to update count: " + str(counter))
break
conn.commit()
print("totally uses: " + str(time.time() - start_time)+" s")
except Exception as e:
conn.rollback()
print(f"Error: {e}")
finally:
mysql_util.close_connection(conn)
2.3 第三次提纯
基于前两次提纯后的问答数据集进行整理,将问答数据在不改变原意的情况下重新组织语言。譬如:
问题:为什么吃了这副药老是放屁?柴胡12g,沙参15g,枯芩10g
答案:屁多会不会是行气类的药太多,量太重的关系啊,苍术、厚朴、陈皮、藿香、木香、苏梗、郁金都有行气的功效,你看着加减一下呗。
像这种问答人工智能并不清楚问题的重点是什么,并且答案口语化太严重。什么“你看着加减一下呗”人工智能又怎么来判断呢?所以第三次提纯是需要将不通顺或者存在语意不清的问答内容进行重写,这个工作量是相当的大。
经过这么清洗和提纯后,真正留下来的数据其实所剩无几。不过为了数据质量也是没有办法的,尤其是我们 将要使用 AutoKeras 进行的 RNN 训练,如果数据质量不高一切都是白搭。因此经过这次我真正切切地感受到其实做人工智能最麻烦的并不是设计训练模型,这部分已经有高人在后面给我们搞好了,像我们这些平凡人最最困难的就是要做高质量的训练数据。
怎样才算高质量?这里就有很多学问了,不是单单是今天说的这套流程下来就能做高质量数据了,还需要经过模型的验证,多次数据模拟测量、结果曲线对比…真的是麻烦的一批。