- redis是一款高性能nosql系列的非关系型数据库,最常被开发人员来作为缓存使用
- mysql是将数据存储到硬盘上的,而redis是将数据存储到内存中的
- redis是(k,v)结构的,k一般为字符串类型,v一般有五种基本类型和三种特殊类型
下载安装
-
官网:https://redis.io
-
中文网:http://www.redis.net.cn/
-
解压直接可以使用:
* redis.windows.conf:配置文件
* redis-cli.exe:redis的客户端
* redis-server.exe:redis服务器端
value的五种基本类型:
-
字符串类型 string
存储:set key value
eg:set name aaa(输出:ok)
获取:get key
eg:get name(输出:aaa)
删除:del key
eg:del name(输出:ok)
-
哈希类型 hash:map形式
存储:hset key field value(field为map的k)
eg:hset name a aaa(输出:ok)
获取:hget key field
eg:hget name a(输出:aaa)
删除:hdel key field
eg:hdel name a(输出:ok)
-
列表类型 list:linkedlist格式,支持重复元素
存储:lpush key value(list类型,lpush为将元素添加到前边/左边)
rpush key value(rpush为将元素添加到后边/右边)
eg:rpush name aaa(输出:ok)
获取:lrange key start end(范围获取)
eg:lrange name 0 -1(输出:aaa)
删除:ipop key(删除最左边的,并返回删除的值)
rpop key(删除最右边的,并返回删除的值)
eg:ipop name(输出:ok)
-
集合类型 set:不支持重复元素
存储:sadd key value
eg:sadd name aaa(输出:ok)
获取:smembers key(获取所有)
eg:smembers name
删除:srem key value
eg:srem name aaa(输出:ok)
-
有序集合类型 sortedset:不支持重复元素且元素有顺序
存储:zadd key score value(每个添加的值都需要关联一个score,它是一个数字,用来集合排序,顺序为从小到大)
eg:zadd name 60 aaa(输出:ok)
获取:zrange key start end [withscores]
eg:zrange key 0 -1(输出:aaa,withscores可选,加上了它输出为:aaa 60)
删除:zrem key value
eg:zrem name aaa(输出:ok)
-
通用命令:
keys * : 查询所有的键
type key : 获取键对应的value的类型
del key:删除指定的key value
持久化
AOF 持久化
- AOF - 将每条写命令追加至 aof 文件,当重启时会执行 aof 文件中每条命令来重建内存数据
- AOF 日志是写后日志,即先执行命令,再记录日志
- Redis 为了性能,向 aof 记录日志时没有对命令进行语法检查,如果要先记录日志,那么日志里就会记录语法错误的命令
- 记录 AOF 日志时,有三种同步策略
- Always 同步写,日志写入磁盘再返回,可以做到基本不丢数据,性能不高
- 为什么说基本不丢呢,因为 aof 是在 serverCron 事件循环中执行 aof 写入的,并且这次写入的是上一次循环暂存在 aof 缓冲中的数据,因此最多还是可能丢失一个循环的数据
- Everysec 每秒写,日志写入 AOF 文件的内存缓冲区,每隔一秒将内存缓冲区数据刷入磁盘,最多丢一秒的数据
- No 操作系统写,日志写入AOF 文件的内存缓冲区,由操作系统决定何时将数据刷入磁盘
AOF 重写
- AOF 文件太大引起的问题
- 文件大小受操作系统限制
- 文件太大,写入效率变低
- 文件太大,恢复时非常慢
- 重写就是对同一个 key 的多次操作进行瘦身
- 例如一个 key 我改了 100 遍,aof 里记录了100 条修改日志,但实际上只有最后一次有效
- 重写无需操作现有 aof 日志,只需要根据当前内存数据的状态,生成相应的命令,记入一个新的日志文件即可
- 重写过程是由另一个后台子进程完成的,不会阻塞主进程
- AOF 重写过程
- 创建子进程时会根据主进程生成内存快照,只需要对子进程的内存进行遍历,把每个 key 对应的命令写入新的日志文件(即重写日志)
- 此时如果有新的命令执行,修改的是主进程内存,不会影响子进程内存,并且新命令会记录到
重写缓冲区
- 等子进程所有的 key 处理完毕,再将
重写缓冲区 记录的增量指令写入重写日志
- 在此期间旧的 AOF 日志仍然在工作,待到重写完毕,用重写日志替换掉旧的 AOF 日志
RDB 持久化
- RDB - 是把整个内存数据以二进制方式写入磁盘
- 对应数据文件为
dump.rdb
- 好处是恢复速度快
- 相关命令有两个
- save - 在主进程执行,会阻塞其它命令
- bgsave - 创建子进程执行,避免阻塞,是默认方式
- 子进程不会阻塞主进程,但创建子进程的期间,仍会阻塞,内存越大,阻塞时间越长
- bgsave 也是利用了快照机制,执行 RDB 持久化期间如果有新数据写入,新的数据修改发生在主进程,子进程向 RDB 文件中写入还是旧的数据,这样新的修改不会影响到 RDB 操作
- 但这些新数据不会补充至 RDB 文件
- 缺点: 可以通过调整 redis.conf 中的 save 参数来控制 rdb 的执行周期,但这个周期不好把握
- 频繁执行的话,会影响性能
- 偶尔执行的话,如果宕机又容易丢失较多数据
混合持久化
- 从 4.0 开始,Redis 支持混合持久化,即使用 RDB 作为全量备份,两次 RDB 之间使用 AOF 作为增量备份
- 配置项 aof-use-rdb-preamble 用来控制是否启用混合持久化,默认值 no
- 持久化时将数据都存入 AOF 日志,日志前半部分为二进制的 RDB 格式,后半部分是 AOF 命令日志
- 下一次 RDB 时,会覆盖之前的日志文件
- 优缺点
- 结合了 RDB 与 AOF 的优点,恢复速度快,增量用 AOF 表示,数据更完整(取决于同步策略)、也无需 AOF 重写
- 与旧版本的 redis 文件格式不兼容
java集成redis
* Jedis: 一款java操作redis数据库的工具.
* 使用步骤:
1. 下载jedis的jar包
2. 使用
//1. 获取连接
Jedis jedis = new Jedis("localhost",6379);
//2. 操作
jedis.set("username","zhangsan");
//3. 关闭连接
jedis.close();
* Jedis操作各种redis中的数据结构
1) 字符串类型 string
set
get
//1. 获取连接
Jedis jedis = new Jedis();//如果使用空参构造,默认值 "localhost",6379端口
//2. 操作
//存储
jedis.set("username","zhangsan");
//获取
String username = jedis.get("username");
System.out.println(username);
//可以使用setex()方法存储可以指定过期时间的 key value
jedis.setex("activecode",20,"hehe");//将activecode:hehe键值对存入redis,并且20秒后自动删除该键值对
//3. 关闭连接
jedis.close();
2) 哈希类型 hash : map格式
hset
hget
hgetAll
//1. 获取连接
Jedis jedis = new Jedis();//如果使用空参构造,默认值 "localhost",6379端口
//2. 操作
// 存储hash
jedis.hset("user","name","lisi");
jedis.hset("user","age","23");
jedis.hset("user","gender","female");
// 获取hash
String name = jedis.hget("user", "name");
System.out.println(name);
// 获取hash的所有map中的数据
Map user = jedis.hgetAll("user");
// keyset
Set keySet = user.keySet();
for (String key : keySet) {
//获取value
String value = user.get(key);
System.out.println(key + ":" + value);
}
//3. 关闭连接
jedis.close();
3) 列表类型 list : linkedlist格式。支持重复元素
lpush / rpush
lpop / rpop
lrange start end : 范围获取
//1. 获取连接
Jedis jedis = new Jedis();//如果使用空参构造,默认值 "localhost",6379端口
//2. 操作
// list 存储
jedis.lpush("mylist","a","b","c");//从左边存
jedis.rpush("mylist","a","b","c");//从右边存
// list 范围获取
List mylist = jedis.lrange("mylist", 0, -1);
System.out.println(mylist);
// list 弹出
String element1 = jedis.lpop("mylist");//c
System.out.println(element1);
String element2 = jedis.rpop("mylist");//c
System.out.println(element2);
// list 范围获取
List mylist2 = jedis.lrange("mylist", 0, -1);
System.out.println(mylist2);
//3. 关闭连接
jedis.close();
4) 集合类型 set : 不允许重复元素
sadd
smembers:获取所有元素
//1. 获取连接
Jedis jedis = new Jedis();//如果使用空参构造,默认值 "localhost",6379端口
//2. 操作
// set 存储
jedis.sadd("myset","java","php","c++");
// set 获取
Set myset = jedis.smembers("myset");
System.out.println(myset);
//3. 关闭连接
jedis.close();
5) 有序集合类型 sortedset:不允许重复元素,且元素有顺序
zadd
zrange
//1. 获取连接
Jedis jedis = new Jedis();//如果使用空参构造,默认值 "localhost",6379端口
//2. 操作
// sortedset 存储
jedis.zadd("mysortedset",3,"亚瑟");
jedis.zadd("mysortedset",30,"后裔");
jedis.zadd("mysortedset",55,"孙悟空");
// sortedset 获取
Set mysortedset = jedis.zrange("mysortedset", 0, -1);
System.out.println(mysortedset);
//3. 关闭连接
jedis.close();
* jedis连接池: JedisPool
* 使用:
1. 创建JedisPool连接池对象
2. 调用方法 getResource()方法获取Jedis连接
//0.创建一个配置对象
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(50);
config.setMaxIdle(10);
//1.创建Jedis连接池对象
JedisPool jedisPool = new JedisPool(config,"localhost",6379);
//2.获取连接
Jedis jedis = jedisPool.getResource();
//3. 使用
jedis.set("hehe","heihei");
//4. 关闭 归还到连接池中
jedis.close();
* 连接池工具类
public class JedisPoolUtils {
private static JedisPool jedisPool;
static{
//读取配置文件
InputStream is = JedisPoolUtils.class.getClassLoader().getResourceAsStream("jedis.properties");
//创建Properties对象
Properties pro = new Properties();
//关联文件
try {
pro.load(is);
} catch (IOException e) {
e.printStackTrace();
}
//获取数据,设置到JedisPoolConfig中
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(Integer.parseInt(pro.getProperty("maxTotal")));
config.setMaxIdle(Integer.parseInt(pro.getProperty("maxIdle")));
//初始化JedisPool
jedisPool = new JedisPool(config,pro.getProperty("host"),Integer.parseInt(pro.getProperty("port")));
}
/**
* 获取连接方法
*/
public static Jedis getJedis(){
return jedisPool.getResource();
}
}
springboot整合jedis
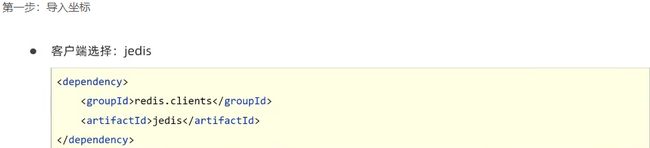
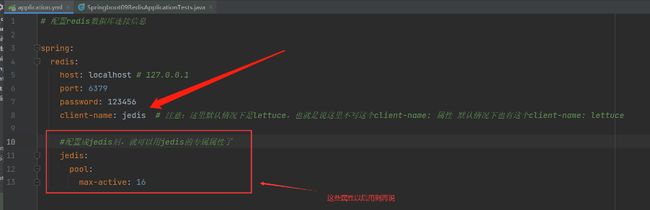

sprinboot整合redis–redistemplate方式(是spring框架对jedis和lettuce的封装)
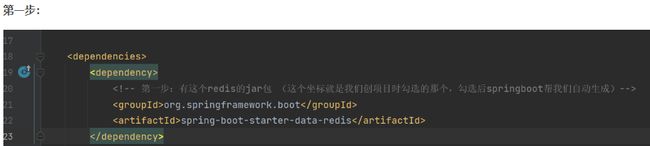
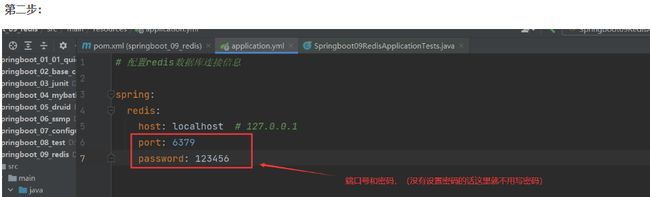
springboot整合后使用@Autowired注解自动注入使用,eg:
@Autowired
Redistemplate redistemplate;
redistemplate
1.String:
//void set(K key, V value);
redisTemplate.opsForValue().set("num","123");
redisTemplate.opsForValue().get("num") 输出结果为123
//void set(K key, V value, long timeout, TimeUnit unit);
redisTemplate.opsForValue().set("num","123",10, TimeUnit.SECONDS);
redisTemplate.opsForValue().get("num")设置的是10秒失效,十秒之内查询有结果,十秒之后返回为null
//void set(K key, V value, long offset);
//覆写(overwrite)给定 key 所储存的字符串值,从偏移量 offset 开始
template.opsForValue().set("key","hello world");
template.opsForValue().set("key","redis", 6);
System.out.println("***************"+template.opsForValue().get("key"));
//结果:***************hello redis
//V get(Object key);
template.opsForValue().set("key","hello world");
System.out.println("***************"+template.opsForValue().get("key"));
结果:***************hello world
//V getAndSet(K key, V value);
//设置键的字符串值并返回其旧值
template.opsForValue().set("getSetTest","test");
System.out.println(template.opsForValue().getAndSet("getSetTest","test2"));
结果:test
//Integer append(K key, String value);
//如果key已经存在并且是一个字符串,则该命令将该值追加到字符串的末尾。如果键不存在,则它被创建并设置为空字符串,因此APPEND在这种特殊情况下将类似于SET。
template.opsForValue().append("test","Hello");
System.out.println(template.opsForValue().get("test"));
template.opsForValue().append("test","world");
System.out.println(template.opsForValue().get("test"));
Hello
Helloworld
//Long size(K key);
//返回key所对应的value值得长度
template.opsForValue().set("key","hello world");
System.out.println("***************"+template.opsForValue().size("key"));
***************11
2.List:
//Long size(K key);
//返回存储在键中的列表的长度。如果键不存在,则将其解释为空列表,并返回0。当key存储的值不是列表时返回错误。
System.out.println(template.opsForList().size("list"));
6
//Long leftPush(K key, V value);
//将所有指定的值插入存储在键的列表的头部。如果键不存在,则在执行推送操作之前将其创建为空列表。(从左边插入)
template.opsForList().leftPush("list","java");
template.opsForList().leftPush("list","python");
template.opsForList().leftPush("list","c++");
返回的结果为推送操作后的列表的长度
1
2
3
//V range(K key, int a,int b);
//查询,a为从左到右,从0开始,b为从右到左,从-1开始
String[] strs = new String[]{"1","2","3"};
template.opsForList().leftPushAll("list",strs);
System.out.println(template.opsForList().range("list",0,-1));
[3, 2, 1]
//Long leftPushAll(K key, V... values);
//批量把一个数组插入到列表中
String[] strs = new String[]{"1","2","3"};
template.opsForList().leftPushAll("list",strs);
System.out.println(template.opsForList().range("list",0,-1));
[3, 2, 1]
//Long rightPush(K key, V value);
//将所有指定的值插入存储在键的列表的头部。如果键不存在,则在执行推送操作之前将其创建为空列表。(从右边插入)
template.opsForList().rightPush("listRight","java");
template.opsForList().rightPush("listRight","python");
template.opsForList().rightPush("listRight","c++");
1
2
3
//Long rightPushAll(K key, V... values);
String[] strs = new String[]{"1","2","3"};
template.opsForList().rightPushAll("list",strs);
System.out.println(template.opsForList().range("list",0,-1));
[1, 2, 3]
//void set(K key, long index, V value);
//在列表中index的位置设置value值
System.out.println(template.opsForList().range("listRight",0,-1));
template.opsForList().set("listRight",1,"setValue");
System.out.println(template.opsForList().range("listRight",0,-1));
[java, python, oc, c++]
[java, setValue, oc, c++]
//Long remove(K key, long count, Object value);
//从存储在键中的列表中删除等于值的元素的第一个计数事件。
//计数参数以下列方式影响操作:
//count> 0:删除等于从头到尾移动的值的元素。
//count <0:删除等于从尾到头移动的值的元素。
//count = 0:删除等于value的所有元素。
System.out.println(template.opsForList().range("listRight",0,-1));
template.opsForList().remove("listRight",1,"setValue");//将删除列表中存储的列表中第一次次出现的“setValue”。
System.out.println(template.opsForList().range("listRight",0,-1));
[java, setValue, oc, c++]
[java, oc, c++]
//V index(K key, long index);
//根据下表获取列表中的值,下标是从0开始的
System.out.println(template.opsForList().range("listRight",0,-1));
System.out.println(template.opsForList().index("listRight",2));
[java, oc, c++]
c++
//V leftPop(K key);
//弹出最左边的元素,弹出之后该值在列表中将不复存在
System.out.println(template.opsForList().range("list",0,-1));
System.out.println(template.opsForList().leftPop("list"));
System.out.println(template.opsForList().range("list",0,-1));
[c++, python, oc, java, c#, c#]
c++
[python, oc, java, c#, c#]
//V rightPop(K key);
//弹出最右边的元素,弹出之后该值在列表中将不复存在
System.out.println(template.opsForList().range("list",0,-1));
System.out.println(template.opsForList().rightPop("list"));
System.out.println(template.opsForList().range("list",0,-1));
[python, oc, java, c#, c#]
c#
[python, oc, java, c#]
3.hash:
//Long delete(H key, Object... hashKeys);
//删除给定的哈希hashKeys
System.out.println(template.opsForHash().delete("redisHash","name"));
System.out.println(template.opsForHash().entries("redisHash"));
1
{class=6, age=28.1}
//Boolean hasKey(H key, Object hashKey);
//确定哈希hashKey是否存在
System.out.println(template.opsForHash().hasKey("redisHash","666"));
System.out.println(template.opsForHash().hasKey("redisHash","777"));
true
false
//HV get(H key, Object hashKey);
//从键中的哈希获取给定hashKey的值
System.out.println(template.opsForHash().get("redisHash","age"));
26
//Set keys(H key);
//获取key所对应的散列表的key
System.out.println(template.opsForHash().keys("redisHash"));
//redisHash所对应的散列表为{class=1, name=666, age=27}
[name, class, age]
//Long size(H key);
//获取key所对应的散列表的大小个数
System.out.println(template.opsForHash().size("redisHash"));
//redisHash所对应的散列表为{class=1, name=666, age=27}
3
//void putAll(H key, Map m);
//使用m中提供的多个散列字段设置到key对应的散列表中
Map testMap = new HashMap();
testMap.put("name","666");
testMap.put("age",27);
testMap.put("class","1");
template.opsForHash().putAll("redisHash1",testMap);
System.out.println(template.opsForHash().entries("redisHash1"));
{class=1, name=jack, age=27}
//void put(H key, HK hashKey, HV value);
//设置散列hashKey的值
template.opsForHash().put("redisHash","name","666");
template.opsForHash().put("redisHash","age",26);
template.opsForHash().put("redisHash","class","6");
System.out.println(template.opsForHash().entries("redisHash"));
{age=26, class=6, name=666}
//List values(H key);
//获取整个哈希存储的值根据密钥
System.out.println(template.opsForHash().values("redisHash"));
[tom, 26, 6]
//Map entries(H key);
//获取整个哈希存储根据密钥
System.out.println(template.opsForHash().entries("redisHash"));
{age=26, class=6, name=tom}
//Cursor> scan(H key, ScanOptions options);
//使用Cursor在key的hash中迭代,相当于迭代器。
Cursor> curosr = template.opsForHash().scan("redisHash",
ScanOptions.ScanOptions.NONE);
while(curosr.hasNext()){
Map.Entry entry = curosr.next();
System.out.println(entry.getKey()+":"+entry.getValue());
}
age:27
class:6
name:666
4.set:
//Long add(K key, V... values);
//无序集合中添加元素,返回添加个数
//也可以直接在add里面添加多个值 如:template.opsForSet().add("setTest","aaa","bbb")
String[] strs= new String[]{"str1","str2"};
System.out.println(template.opsForSet().add("setTest", strs));
2
//Long remove(K key, Object... values);
//移除集合中一个或多个成员
String[] strs = new String[]{"str1","str2"};
System.out.println(template.opsForSet().remove("setTest",strs));
2
//V pop(K key);
//移除并返回集合中的一个随机元素
System.out.println(template.opsForSet().pop("setTest"));
System.out.println(template.opsForSet().members("setTest"));
bbb
[aaa, ccc]
//Boolean move(K key, V value, K destKey);
//将 member 元素从 source 集合移动到 destination 集合
template.opsForSet().move("setTest","aaa","setTest2");
System.out.println(template.opsForSet().members("setTest"));
System.out.println(template.opsForSet().members("setTest2"));
[ccc]
[aaa]
//Long size(K key);
//无序集合的大小长度
System.out.println(template.opsForSet().size("setTest"));
1
//Set members(K key);
//返回集合中的所有成员
System.out.println(template.opsForSet().members("setTest"));
[ddd, bbb, aaa, ccc]
//Cursor scan(K key, ScanOptions options);
//遍历set
Cursor