基于YOLOv8的暗光低光环境下(ExDark数据集)检测,加入多种优化方式---DCNv4结合SPPF ,助力自动驾驶(一)
本文主要内容:详细介绍了暗光低光数据集检测整个过程,从数据集到训练模型到结果可视化分析,以及如何优化提升检测性能。
加入 DCNv4结合SPPF [email protected]由原始的0.682提升至0.694
1.暗光低光数据集ExDark介绍
低光数据集使用ExDark,该数据集是一个专门在低光照环境下拍摄出针对低光目标检测的数据集,包括从极低光环境到暮光环境等10种不同光照条件下的图片,包含图片训练集5891张,测试集1472张,12个类别。
1.Bicycle 2.Boat 3.Bottle 4.Bus 5.Car 6.Cat 7.Chair 8.Cup 9.Dog 10.Motorbike 11.People 12.Table
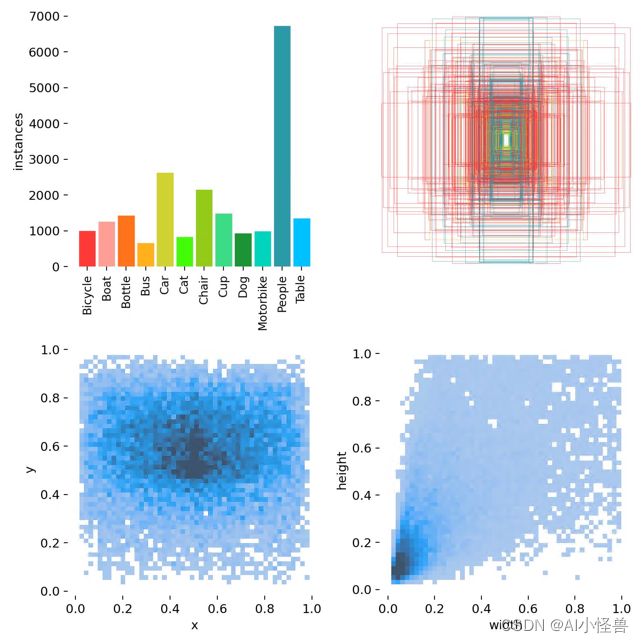
细节图:

2.基于YOLOv8的暗光低光检测
2.1 修改ExDark_yolo.yaml
path: ./data/ExDark_yolo/ # dataset root dir
train: images/train # train images (relative to 'path') 1411 images
val: images/val # val images (relative to 'path') 458 images
#test: images/test # test images (optional) 937 images
names:
0: Bicycle
1: Boat
2: Bottle
3: Bus
4: Car
5: Cat
6: Chair
7: Cup
8: Dog
9: Motorbike
10: People
11: Table2.2 开启训练
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/v8/yolov8.yaml')
model.train(data='data/ExDark_yolo/ExDark_yolo.yaml',
cache=False,
imgsz=640,
epochs=200,
batch=16,
close_mosaic=10,
workers=0,
device='0',
optimizer='SGD', # using SGD
project='runs/train',
name='exp',
)3.结果可视化分析
YOLOv8 summary: 225 layers, 3012500 parameters, 0 gradients, 8.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 24/24 [00:25<00:00, 1.05s/it]
all 737 2404 0.743 0.609 0.682 0.427
Bicycle 737 129 0.769 0.697 0.764 0.498
Boat 737 143 0.69 0.56 0.649 0.349
Bottle 737 174 0.761 0.587 0.652 0.383
Bus 737 62 0.854 0.742 0.808 0.64
Car 737 311 0.789 0.672 0.761 0.5
Cat 737 95 0.783 0.568 0.661 0.406
Chair 737 232 0.725 0.513 0.609 0.363
Cup 737 181 0.725 0.53 0.609 0.375
Dog 737 94 0.634 0.617 0.628 0.421
Motorbike 737 91 0.766 0.692 0.78 0.491
People 737 744 0.789 0.603 0.711 0.398
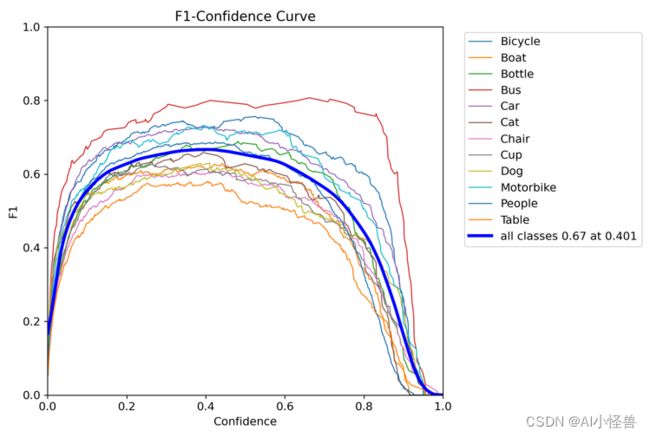
Table 737 148 0.637 0.52 0.553 0.296F1_curve.png:F1分数与置信度(x轴)之间的关系。F1分数是分类的一个衡量标准,是精确率和召回率的调和平均函数,介于0,1之间。越大越好。
TP:真实为真,预测为真;
FN:真实为真,预测为假;
FP:真实为假,预测为真;
TN:真实为假,预测为假;
精确率(precision)=TP/(TP+FP)
召回率(Recall)=TP/(TP+FN)
F1=2*(精确率*召回率)/(精确率+召回率)
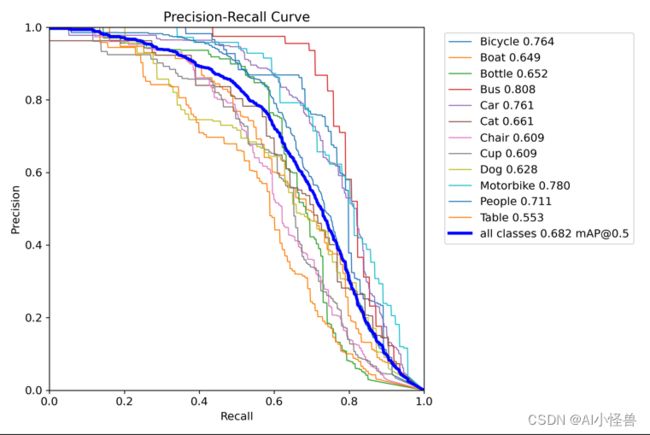
PR_curve.png :PR曲线中的P代表的是precision(精准率),R代表的是recall(召回率),其代表的是精准率与召回率的关系。
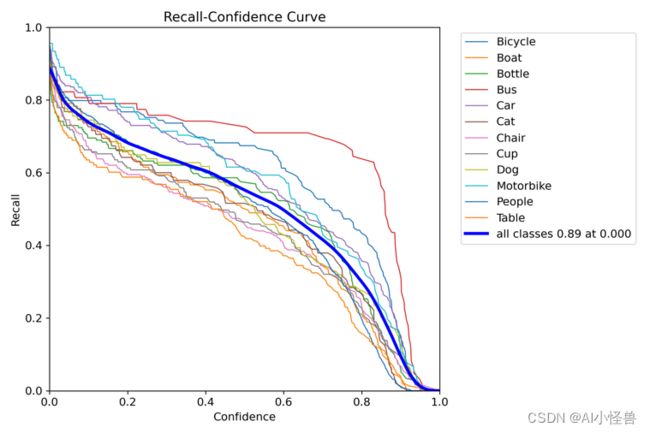
R_curve.png :召回率与置信度之间关系
results.png
mAP_0.5:0.95表示从0.5到0.95以0.05的步长上的平均mAP.

预测结果:

4.如何优化模型
4.1 DCNv4结合SPPF
YOLOv8全网首发:新一代高效可形变卷积DCNv4如何做二次创新?高效结合SPPF-CSDN博客

论文: https://arxiv.org/pdf/2401.06197.pdf
摘要:我们介绍了可变形卷积v4 (DCNv4),这是一种高效的算子,专为广泛的视觉应用而设计。DCNv4通过两个关键增强解决了其前身DCNv3的局限性:去除空间聚合中的softmax归一化,增强空间聚合的动态性和表现力;优化内存访问以最小化冗余操作以提高速度。与DCNv3相比,这些改进显著加快了收敛速度,并大幅提高了处理速度,其中DCNv4的转发速度是DCNv3的三倍以上。DCNv4在各种任务中表现出卓越的性能,包括图像分类、实例和语义分割,尤其是图像生成。当在潜在扩散模型中与U-Net等生成模型集成时,DCNv4的性能优于其基线,强调了其增强生成模型的可能性。在实际应用中,将InternImage模型中的DCNv3替换为DCNv4来创建FlashInternImage,无需进一步修改即可使速度提高80%,并进一步提高性能。DCNv4在速度和效率方面的进步,以及它在不同视觉任务中的强大性能,显示了它作为未来视觉模型基础构建块的潜力。
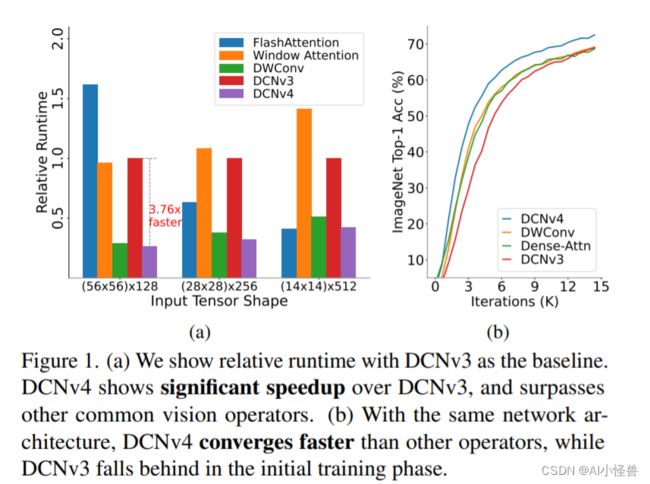
图1所示。(a)我们以DCNv3为基准显示相对运行时间。DCNv4比DCNv3有明显的加速,并且超过了其他常见的视觉算子。(b)在相同的网络架构下,DCNv4收敛速度快于其他视觉算子,而DCNv3在初始训练阶段落后于视觉算子。
4.2 对应yaml
# Ultralytics YOLO , AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, DCNv4_SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
4.3 实验结果分析
[email protected]由原始的0.682提升至0.694
YOLOv8_DCNv4_SPPF summary: 238 layers, 4867508 parameters, 0 gradients, 9.7 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 24/24 [00:23<00:00, 1.02it/s]
all 737 2404 0.786 0.587 0.694 0.436
Bicycle 737 129 0.802 0.659 0.752 0.487
Boat 737 143 0.779 0.617 0.676 0.361
Bottle 737 174 0.799 0.603 0.66 0.386
Bus 737 62 0.856 0.726 0.819 0.654
Car 737 311 0.849 0.64 0.764 0.514
Cat 737 95 0.757 0.589 0.696 0.436
Chair 737 232 0.792 0.526 0.638 0.366
Cup 737 181 0.776 0.499 0.625 0.391
Dog 737 94 0.689 0.585 0.673 0.444
Motorbike 737 91 0.806 0.659 0.806 0.5
People 737 744 0.828 0.549 0.689 0.39
Table 737 148 0.701 0.395 0.536 0.303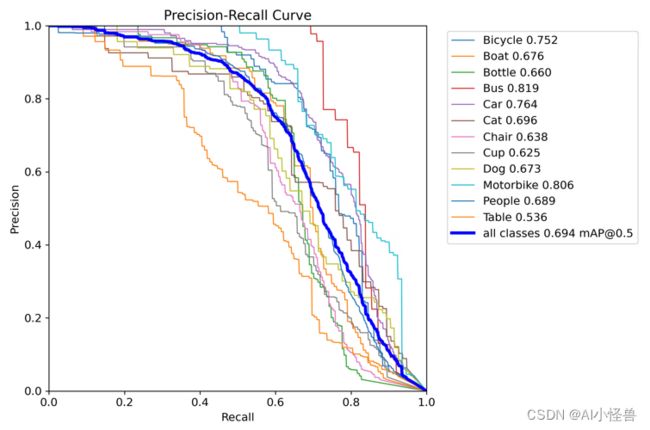
5.系列篇
系列篇1: DCNv4结合SPPF ,助力自动驾驶
系列篇2:自研CPMS注意力,效果优于CBAM