Linux系统信息与系统资源
目录
- 系统信息
-
- 系统标识uname
- sysinfo 函数
- gethostname 函数
- sysconf()函数
- 时间、日期
-
- GMT 时间
- UTC 时间
- UTC 时间格式
- 时区
- 实时时钟RTC
- 获取时间time/gettimeofday
- 时间转换函数
- 设置时间settimeofday
- 总结
- 进程时间
-
- times 函数
- clock 函数
- 产生随机数
- 休眠(延时)
-
- 秒级休眠: sleep
- 微秒级休眠: usleep
- 高精度休眠: nanosleep
- 申请堆内存
-
- 在堆上分配内存:malloc 和free
- 调用free()还是不调用free()
- 在堆上分配内存的其它方法
- 分配对齐内存
- proc 虚拟文件系统
-
- proc 文件系统的使用
在应用程序当中,有时往往需要去获取到一些系统相关的信息。
- 时间、日期、以及其它一些系统相关信息,如何通过Linux 系统调用或C 库函数获取系统信息;
- Linux 系统下的/proc 虚拟文件系统,包括/proc 文件系统是什么以及如何从/proc 文件系统中读取系统、进程有关信息;
- 系统资源的使用,譬如系统内存资源的申请与使用等。
系统信息
系统标识uname
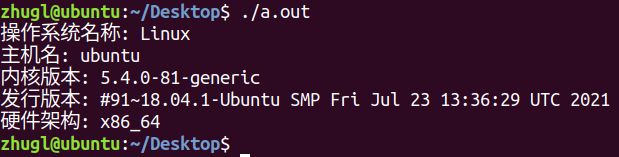
系统调用uname()用于获取有关当前操作系统内核的名称和信息,函数原型如下所示(可通过"man 2 uname"命令查看):
#include buf:struct utsname 结构体类型指针,指向一个struct utsname 结构体类型对象。
返回值:成功返回0;失败将返回-1,并设置errno。
struct utsname 结构体如下所示:
struct utsname {
char sysname[]; /* 当前操作系统的名称*/
char nodename[]; /* 网络上的名称(主机名)*/
char release[]; /* 操作系统内核版本*/
char version[]; /* 操作系统发行版本*/
char machine[]; /* 硬件架构类型*/
#ifdef _GNU_SOURCE
char domainname[];/* 当前域名*/
#endif
};
可以看到,struct utsname 结构体中的所有成员变量都是字符数组,所以获取到的信息都是字符串。
测试
#include 运行结果:
sysinfo 函数
sysinfo 系统调用可用于获取一些系统统计信息,其函数原型如下所示:
#include info:struct sysinfo 结构体类型指针,指向一个struct sysinfo 结构体类型对象。
返回值:成功返回0;失败将返回-1,并设置errno。
struct sysinfo 结构体如下所示:
struct sysinfo {
long uptime; /* 自系统启动之后所经过的时间(以秒为单位)*/
unsigned long loads[3]; /* 1, 5, and 15 minute load averages */
unsigned long totalram; /* 总的可用内存大小*/
unsigned long freeram; /* 还未被使用的内存大小*/
unsigned long sharedram; /* Amount of shared memory */
unsigned long bufferram; /* Memory used by buffers */
unsigned long totalswap; /* Total swap space size */
unsigned long freeswap; /* swap space still available */
unsigned short procs; /* 系统当前进程数量*/
unsigned long totalhigh; /* Total high memory size */
unsigned long freehigh; /* Available high memory size */
unsigned int mem_unit; /* 内存单元大小(以字节为单位)*/
char _f[20-2*sizeof(long)-sizeof(int)]; /* Padding to 64 bytes */
};
测试
#include 运行结果:

gethostname 函数
用于单独获取Linux 系统主机名,与struct utsname 数据结构体中的nodename 变量一样:
#include name:指向用于存放主机名字符串的缓冲区。
len:缓冲区长度。
返回值:成功返回0,;失败将返回-1,并会设置errno。
测试
#include 运行结果:

sysconf()函数
sysconf()函数是一个库函数,可在运行时获取系统的一些配置信息,譬如页大小(page size)、主机名的最大长度、进程可以打开的最大文件数、每个用户ID 的最大并发进程数等。其函数原型如下所示:
#include 参数name 指定了要获取哪个配置信息,参数name 可取以下任何一个值(都是宏定义,可通过man 手册查询):
⚫ _SC_ARG_MAX:exec 族函数的参数的最大长度,exec 族函数后面会介绍,这里先不管!
⚫ _SC_CHILD_MAX:每个用户的最大并发进程数,也就是同一个用户可以同时运行的最大进程数。
⚫ _SC_HOST_NAME_MAX:主机名的最大长度。
⚫ _SC_LOGIN_NAME_MAX:登录名的最大长度。
⚫ _SC_CLK_TCK:每秒时钟滴答数,也就是系统节拍率。
⚫ _SC_OPEN_MAX:一个进程可以打开的最大文件数。
⚫ _SC_PAGESIZE:系统页大小(page size)。
⚫ _SC_TTY_NAME_MAX:终端设备名称的最大长度。
⚫ ……
若指定的参数name 为无效值,则sysconf()函数返回-1,并会将errno 设置为EINVAL。否则返回的值便是对应的配置值。
使用示例
#include 运行结果:

时间、日期
GMT 时间
GMT(Greenwich Mean Time)中文全称是格林威治标准时间,1884 年被确立,GMT 时间就是英国格林威治当地时间,也就是零时区(中时区)所在时间,与我国的标准时间北京时间(东八区)相差8 个小时,即早八个小时,所以GMT 12:00 对应的北京时间是20:00。
UTC 时间
UTC(Coordinated Universal Time)指的是世界协调时间(又称世界标准时间、世界统一时间),是经过平均太阳时(以格林威治时间GMT 为准)、地轴运动修正后的新时标以及以「秒」为单位的国际原子时所综合精算而成的时间,计算过程相当严谨精密,因此若以「世界标准时间」的角度来说,UTC 比GMT 来得更加精准。
在Ubuntu 系统下,可以使用"date -u"命令查看到当前的UTC 时间,如下所示:

UTC 时间格式
根据 ISO 8601《数据存储和交换形式·信息交换·日期和时间的表示方法》,UTC时间,也就是国际统一时间/国际协调时,表示方法如下:
YYYYMMDD T HHMMSS Z(或者时区标识)。
例如,20100607T152000Z,表示2010年6月7号15点20分0秒,Z表示是标准时间
如果表示北京时间,那么就是:
20100607T152000+08,其中 “+08” 表示东八区。
时区
全球被划分为24 个时区,每一个时区横跨经度15 度,以英国格林威治的本初子午线作为零度经线,将全球划分为东西两半球,分为东一区、东二区、东三区……东十二区以及西一区、西二区、西三区……西十二区,而本初子午线所在时区被称为中时区(或者叫零时区),划分图如下所示:

东十二区和西十二区其实是一个时区,就是十二区,东十二区与西十二区各横跨经度7.5 度,以180 度经线作为分界线。每个时区的中央经线上的时间就是这个时区内统一采用的时间,称为区时。相邻两个时区的时间相差1 小时。例如,我国东8 区的时间总比泰国东7 区的时间早1 小时,而比日本东9 区的时间晚1小时。因此,出国旅行的人,必须随时调整自己的手表,才能和当地时间相一致。凡向西走,每过一个时区,就要把表向前拨1 小时(比如2 点拨到1 点);凡向东走,每过一个时区,就要把表向后拨1 小时(比如1 点拨到2 点)。
实际上,世界上不少国家和地区都不严格按时区来计算时间。为了在全国范围内采用统一的时间,一般都把某一个时区的时间作为全国统一采用的时间。例如,我国把首都北京所在的东8 区的时间作为全国统一的时间,称为北京时间,北京时间就作为我国使用的本地时间,譬如我们电脑上显示的时间就是北京时间,我国国土面积广大,由东到西横跨了5 个时区,也就意味着我国最东边的地区与最西边的地区实际上相差了4、5 个小时。又例如,英国、法国、荷兰和比利时等国,虽地处中时区,但为了和欧洲大多数国家时间相一致,则采用东1 区的时间。
譬如在Ubuntu 系统下,可以使用date 命令查看系统当前的本地时间,如下所示:

可以看到显示出来的字符串后面有一个"CST"字样,CST 在这里其实指的是China Standard Time(中国标准时间)的缩写,表示当前查看到的时间是中国标准时间,也就是我国所使用的标准时间–北京时间,一般在安装Ubuntu 系统的时候会提示用户设置所在城市,那么系统便会根据你所设置的城市来确定系统的本地时间对应的时区,譬如设置的城市为上海,那么系统的本地时间就是北京时间,因为我国统一使用北京时间作为本国的标准时间。
在Ubuntu 系统下,时区信息通常以标准格式保存在一些文件当中,这些文件通常位于/usr/share/zoneinfo目录下,该目录下的每一个文件(包括子目录下的文件)都包含了一个特定国家或地区内时区制度的相关信息,且往往根据其所描述的城市或地区缩写来加以命名,譬如EST(美国东部标准时间)、CET(欧洲中部时间)、UTC(世界标准时间)、Hongkong、Iran、Japan(日本标准时间)等,也把这些文件称为时区配置文件,如下图所示:

系统的本地时间由时区配置文件/etc/localtime 定义,通常链接到/usr/share/zoneinfo 目录下的某一个文件(或其子目录下的某一个文件):
![]()
如果我们要修改Ubuntu 系统本地时间的时区信息,可以直接将/etc/localtime 链接到/usr/share/zoneinfo目录下的任意一个时区配置文件,譬如EST(美国东部标准时间),首先进入到/etc 目录下,执行下面的命令:
sudo rm -rf localtime #删除原有链接文件
sudo ln -s /usr/share/zoneinfo/EST localtime #重新建立链接文件

接下来再使用date 命令查看下系统当前的时间,如下所示:

可以发现后面的标识变成了EST,也就意味着当前系统的本地时间变成了EST 时间(美国东部标准时间)。
实时时钟RTC
操作系统中一般会有两个时钟,一个系统时钟(system clock),一个实时时钟(Real time clock),也叫RTC;系统时钟由系统启动之后由内核来维护,譬如使用date 命令查看到的就是系统时钟,所以在系统关机情况下是不存在的;而实时时钟一般由RTC 时钟芯片提供,RTC 芯片有相应的电池为其供电,以保证系统在关机情况下RTC 能够继续工作、继续计时。
Linux 系统如何记录时间
Linux 系统在开机启动之后首先会读取RTC 硬件获取实时时钟作为系统时钟的初始值,之后内核便开始维护自己的系统时钟。所以由此可知,RTC 硬件只有在系统开机启动时会读取一次,目的是用于对系统时钟进行初始化操作,之后的运行过程中便不会再对其进行读取操作了。
而在系统关机时,内核会将系统时钟写入到RTC 硬件、以进行同步操作。
jiffies 的引入
jiffies 是内核中定义的一个全局变量,内核使用jiffies 来记录系统从启动以来的系统节拍数,所以这个变量用来记录以系统节拍时间为单位的时间长度,Linux 内核在编译配置时定义了一个节拍时间,使用节拍率(一秒钟多少个节拍数)来表示,譬如常用的节拍率为100Hz(一秒钟100 个节拍数,节拍时间为1s /100)、200Hz(一秒钟200 个节拍,节拍时间为1s / 200)、250Hz(一秒钟250 个节拍,节拍时间为1s /250)、300Hz(一秒钟300 个节拍,节拍时间为1s / 300)、500Hz(一秒钟500 个节拍,节拍时间为1s /500)等。由此可以发现配置的节拍率越低,每一个系统节拍的时间就越短,也就意味着jiffies 记录的时间精度越高,当然,高节拍率会导致系统中断的产生更加频繁,频繁的中断会加剧系统的负担,一般默认情况下都是采用100Hz 作为系统节拍率。
内核其实通过jiffies 来维护系统时钟,全局变量jiffies 在系统开机启动时会设置一个初始值,RTC 实时时钟会在系统开机启动时读取一次,目的是用于对系统时钟进行初始化,这里说的初始化其实指的就是对内核的jiffies 变量进行初始化操作,具体如何将读取到的实时时钟换算成jiffies 数值。
所以由此可知,操作系统使用jiffies 这个全局变量来记录当前时间,当我们需要获取到系统当前时间点时,就可以使用jiffies 变量去计算,当然并不需要我们手动去计算,Linux 系统提供了相应的系统调用或C库函数用于获取当前时间,譬如系统调用time()、gettimeofday(),其实质上就是通过jiffies 变量换算得到。
获取时间time/gettimeofday
(1)time 函数
系统调用time()用于获取当前时间,以秒为单位,返回得到的值是自1970-01-01 00:00:00 +0000 (UTC)以来的秒数,函数原型如下所示:
#include tloc:如果tloc 参数不是NULL,则返回值也存储在tloc 指向的内存中。
返回值:成功则返回自1970-01-01 00:00:00 +0000 (UTC)以来的时间值(以秒为单位);失败则返回-1,并会设置errno。
time 函数获取得到的是一个时间段,也就是从1970-01-01 00:00:00 +0000 (UTC)到现在这段时间所经过的秒数,所以你要计算现在这个时间点,只需要使用time()得到的秒数加1970-01-01 00:00:00即可!当然,这并不需要我们手动去计算,可以直接使用相关系统调用或C 库函数来得到当前时间,后面介绍。
自1970-01-01 00:00:00 +0000 (UTC)以来经过的总秒数,我们把这个称之为日历时间或time_t 时间。
测试
使用系统调用time()获取自1970-01-01 00:00:00 +0000 (UTC)以来的时间值:
#include 运行结果:

(2)gettimeofday 函数
time()获取到的时间只能精确到秒,gettimeofday()函数提供微秒级时间精度,函数原型如下:
#include tv:参数tv 是一个struct timeval 结构体指针变量,struct timeval 结构体在前面章节内容中已经给大家介绍过,具体参考示例代码5.6.3。
tz:参数tz 是个历史产物,早期实现用其来获取系统的时区信息,目前已遭废弃,在调用gettimeofday()函数时应将参数tz 设置为NULL。
返回值:成功返回0;失败将返回-1,并设置errno。
获取得到的时间值存储在参数tv 所指向的struct timeval 结构体变量中,该结构体包含了两个成员变量tv_sec 和tv_usec,分别用于表示秒和微秒,所以获取得到的时间值就是tv_sec(秒)+tv_usec(微秒),同样获取得到的秒数与time()函数一样,也是自1970-01-01 00:00:00 +0000 (UTC)到现在这段时间所经过的秒数,也就是日历时间,所以由此可知time()返回得到的值和函数gettimeofday()所返回的tv 参数中tv_sec 字段的数值相同。
测试
使用gettimeofday 获取自1970-01-01 00:00:00 +0000 (UTC)以来的时间值:
#include 运行结果:

时间转换函数
通过time()或gettimeofday()函数可以获取到当前时间点相对于1970-01-01 00:00:00 +0000 (UTC)这个时间点所经过时间(日历时间),所以获取得到的是一个时间段的长度,但是这并不利于我们查看当前时间,这个结果对于我们来说非常不友好,那么本小节将向大家介绍一些系统调用或C 库函数,通过这些API 可以将time()或gettimeofday()函数获取到的秒数转换为利于查看和理解的形式。
(1)ctime 函数
ctime()是一个C 库函数,可以将日历时间转换为可打印输出的字符串形式,ctime()函数原型如下所示:
#include timep:time_t 时间变量指针。
返回值:成功将返回一个char *类型指针,指向转换后得到的字符串;失败将返回NULL。
所以由此可知,使用ctime 函数非常简单,只需将time_t 时间变量的指针传入即可,调用成功便可返回字符串指针,拿到字符串指针之后,可以使用printf 将其打印输出。但是ctime()是一个不可重入函数,存在一些安全上面的隐患,ctime_r()是ctime()的可重入版本,一般推荐大家使用可重入函数ctime_r(),可重入函数ctime_r()多了一个参数buf,也就是缓冲区首地址,所以ctime_r()函数需要调用者提供用于存放字符串的缓冲区。
Tips:关于可重入函数与不可重入函数将会在后面章节内容中进行介绍,这里暂时先不去管这个问题,在Linux 系统中,有一些系统调用或C库函数提供了可重入版本与不可重入版本的函数接口,可重入版本函数所对应的函数名一般都会有一个" _r "后缀来表明它是一个可重入函数。
ctime (或ctime_r)转换得到的时间是计算机所在地对应的本地时间(譬如在中国对应的便是北京时间),并不是UTC时间,接下来编写一段简单地代码进行测试。
测试
#include 运行结果:

从图中可知,打印出来的时间为"Mon Feb 22 17:10:46 2021",Mon 表示星期一,这是一个英文单词的缩写,Feb 表示二月份,这也是一个英文单词的缩写,22 表示22 日,所以整个打印信息显示的时间就是2021年2 月22 日星期一17 点10 分46 秒。
(2)localtime 函数
localtime()函数可以把time()或gettimeofday()得到的秒数(time_t 时间或日历时间)变成一个struct tm结构体所表示的时间,该时间对应的是本地时间。localtime 函数原型如下:
#include 函数参数和返回值含义如下:
timep:需要进行转换的time_t 时间变量对应的指针,可通过time()或gettimeofday()获取得到。
result:是一个struct tm 结构体类型指针,稍后给大家介绍struct tm 结构体,参数result 是可重入函数
localtime_r()需要额外提供的参数。
返回值:对于不可重入版本localtime()来说,成功则返回一个有效的struct tm 结构体指针,而对于可重入版本localtime_r()来说,成功执行情况下,返回值将会等于参数result;失败则返回NULL。
使用不可重入函数localtime()并不需要调用者提供struct tm 变量,而是它会直接返回出来一个struct tm结构体指针,然后直接通过该指针访问里边的成员变量即可!虽然很方便,但是存在一些安全隐患,所以一般不推荐使用不可重入版本。
使用可重入版本localtime_r()调用者需要自己定义struct tm 结构体变量、并将该变量指针赋值给参数result,在函数内部会对该结构体变量进行赋值操作。
struct tm 结构体如下所示:
struct tm {
int tm_sec; /* 秒(0-60) */
int tm_min; /* 分(0-59) */
int tm_hour; /* 时(0-23) */
int tm_mday; /* 日(1-31) */
int tm_mon; /* 月(0-11) */
int tm_year; /* 年(这个值表示的是自1900 年到现在经过的年数) */
int tm_wday; /* 星期(0-6, 星期日Sunday = 0、星期一=1…) */
int tm_yday; /* 一年里的第几天(0-365, 1 Jan = 0) */
int tm_isdst; /* 夏令时*/
};
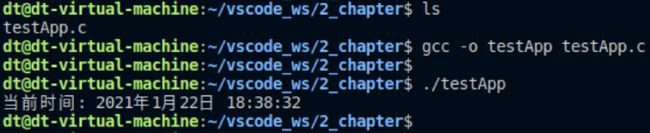
从struct tm 结构体内容可知,该结构体中包含了年月日时分秒星期等信息,使用localtime/localtime_r()便可以将time_t 时间总秒数分解成了各个独立的时间信息,易于我们查看和理解。
测试
#include 运行结果:
(3)gmtime 函数
gmtime()函数也可以把time_t 时间变成一个struct tm 结构体所表示的时间,与localtime()所不同的是,gmtime()函数所得到的是UTC 国际标准时间,并不是计算机的本地时间,这是它们之间的唯一区别。gmtime()函数原型如下所示:
#include gmtime_r()是gmtime()的可重入版本,同样也是推荐大家使用可重入版本函数gmtime_r。关于该函数的参数和返回值,这里便不再介绍,与localtime()是一样的。
测试
使用localtime 获取本地时间、使用gmtime 获取UTC 国际标准时间,并进行对比:
#include 运行结果:
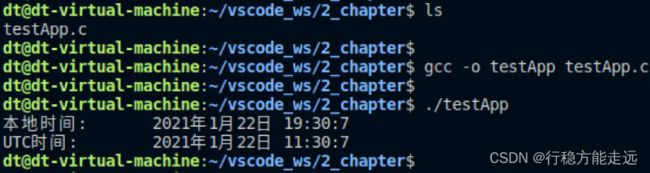
从打印结果可知,本地时间与UTC 时间(国际标准时间)相差8 个小时,因为笔者使用的计算机其对应的本地时间指的便是北京时间,而北京时间要早于国际标准时间8 个小时(东八区)。
(4)mktime 函数
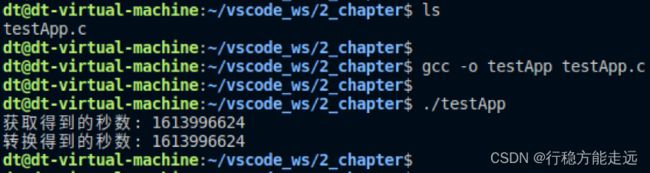
mktime()函数与localtime()函数相反,mktime()可以将使用struct tm 结构体表示的分解时间转换为time_t时间(日历时间),同样这也是一个C 库函数,其函数原型如下所示:
#include tm:需要进行转换的struct tm 结构体变量对应的指针。
返回值:成功返回转换得到time_t 时间值;失败返回-1。
测试
#include 运行结果:
(5)asctime 函数
asctime()函数与ctime()函数的作用一样,也可将时间转换为可打印输出的字符串形式,与ctime()函数的区别在于,ctime()是将time_t 时间转换为固定格式字符串、而asctime()则是将struct tm 表示的分解时间转换为固定格式的字符串。asctime()函数原型如下所示:
#include tm:需要进行转换的struct tm 表示的时间。
buf:可重入版本函数asctime_r 需要额外提供的参数buf,指向一个缓冲区,用于存放转换得到的字符串。
返回值:转换失败将返回NULL;成功将返回一个char *类型指针,指向转换后得到的时间字符串,对于asctime_r 函数来说,返回值就等于参数buf。
测试
#include 运行结果:

(6)strftime 函数
除了asctime()函数之外,这里再给大家介绍一个C 库函数strftime(),此函数也可以将一个struct tm 变量表示的分解时间转换为为格式化字符串,并且在功能上比asctime()和ctime()更加强大,它可以根据自己的喜好自定义时间的显示格式,而asctime()和ctime()转换得到的字符串时间格式的固定的。
strftime()函数原型如下所示:
#include s:指向一个缓存区的指针,该缓冲区用于存放生成的字符串。
max:字符串的最大字节数。
format:这是一个用字符串表示的字段,包含了普通字符和特殊格式说明符,可以是这两种字符的任意组合。特殊格式说明符将会被替换为struct tm 结构体对象所指时间的相应值,这些特殊格式说明符如下:

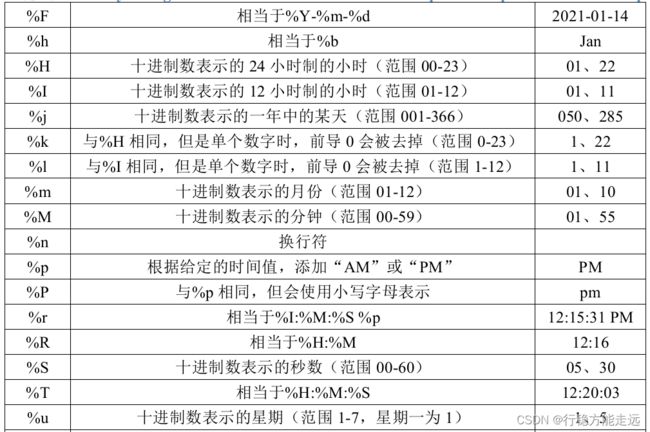

strftime 函数的特殊格式说明符还是比较多的,不用去记它,需要用的时候再去查即可!
通过上表可知,譬如我要想输出"2021-01-14 16:30:25 January Thursday"这样一种形式表示的时间日期,那么就可以这样来设置format 参数:
"%Y-%m-%d %H:%M:%S<%p> %B %A"
tm:指向struct tm 结构体对象的指针。
返回值:如果转换得到的目标字符串不超过最大字节数(也就是max),则返回放置到s 数组中的字节数;如果超过了最大字节数,则返回0。
测试
#include 运行结果:

设置时间settimeofday
使用settimeofday()函数可以设置时间,也就是设置系统的本地时间,函数原型如下所示:
#include tv:参数tv 是一个struct timeval 结构体指针变量,struct timeval 结构体在前面章节内容中已经给大家介绍了,需要设置的时间便通过参数tv 指向的struct timeval 结构体变量传递进去。
tz:参数tz 是个历史产物,早期实现用其来设置系统的时区信息,目前已遭废弃,在调用settimeofday()函数时应将参数tz 设置为NULL。
返回值:成功返回0;失败将返回-1,并设置errno。
使用settimeofday 设置系统时间时内核会进行权限检查,只有超级用户(root)才可以设置系统时间,普通用户将无操作权限。
总结
本小节给大家介绍了时间相关的基本概念,譬如GMT 时间、UTC 时间以及全球24 个时区的划分等,并且给大家介绍了Linux 系统下常用的时间相关的系统调用和库函数,主要有9 个:time/ctime/localtime/gmtime/mktime/asctime/strftime/gettimeofday/settimeofday,对这些函数的功能、作用总结如下:

进程时间
进程时间指的是进程从创建后(也就是程序运行后)到目前为止这段时间内使用CPU 资源的时间总数,出于记录的目的,内核把CPU 时间(进程时间)分为以下两个部分:
⚫ 用户CPU 时间:进程在用户空间(用户态)下运行所花费的CPU 时间。有时也成为虚拟时间(virtualtime)。
⚫ 系统CPU 时间:进程在内核空间(内核态)下运行所花费的CPU 时间。这是内核执行系统调用或代表进程执行的其它任务(譬如,服务页错误)所花费的时间。
一般来说,进程时间指的是用户CPU 时间和系统CPU 时间的总和,也就是总的CPU 时间。
Tips:进程时间不等于程序的整个生命周期所消耗的时间,如果进程一直处于休眠状态(进程被挂起、不会得到系统调度),那么它并不会使用CPU 资源,所以休眠的这段时间并不计算在进程时间中。
times 函数
times()函数用于获取当前进程时间,其函数原型如下所示:
#include buf:times()会将当前进程时间信息存在一个struct tms 结构体数据中,所以我们需要提供struct tms 变量,使用参数buf 指向该变量,关于struct tms 结构体稍后给大家介绍。
返回值:返回值类型为clock_t(实质是long 类型),调用成功情况下,将返回从过去任意的一个时间点(譬如系统启动时间)所经过的时钟滴答数(其实就是系统节拍数),将(节拍数/ 节拍率)便可得到秒数,返回值可能会超过clock_t 所能表示的范围(溢出);调用失败返回-1,并设置errno。
如果我们想查看程序运行到某一个位置时的进程时间,或者计算出程序中的某一段代码执行过程所花费的进程时间,都可以使用times()函数来实现。
struct tms 结构体内容如下所示:
struct tms {
clock_t tms_utime; /* user time, 进程的用户CPU 时间, tms_utime 个系统节拍数*/
clock_t tms_stime; /* system time, 进程的系统CPU 时间, tms_stime 个系统节拍数*/
clock_t tms_cutime; /* user time of children, 已死掉子进程的tms_utime + tms_cutime 时间总和*/
clock_t tms_cstime; /* system time of children, 已死掉子进程的tms_stime + tms_cstime 时间总和*/
};
测试
以下我们演示了通过times()来计算程序中某一段代码执行所耗费的进程时间和总的时间,测试程序如下所示:
#include 首先,笔者先对测试程序做一个简单地介绍,程序中使用sysconf(_SC_CLK_TCK)获取到系统节拍率,程序还使用了一个库函数sleep(),该函数也是本章将要向大家介绍的函数,具体参考7.5.1 小节中的介绍。
示例代码7.3.2 中对如下代码段进行了测试:
for (i = 0; i < 20000; i++)
for (j = 0; j < 20000; j++)
;
sleep(1); //休眠挂起
接下来编译运行,测试结果如下:

可以看到用户CPU 时间为1.9 秒,系统CPU 时间为0 秒,也就是说测试的这段代码并没有进入内核态运行,所以总的进程时间= 用户CPU 时间+ 系统CPU 时间= 1.9 秒。
图7.3.1 中显示的时间总和并不是总的进程时间,前面也给大家解释过,这个时间总和指的是从起点到终点锁经过的时间,并不是进程时间,这里大家要理解。时间总和包括了进程处于休眠状态时消耗的时间(sleep 等会让进程挂起、进入休眠状态),可以发现时间总和比进程时间多1 秒,其实这一秒就是进程处于休眠状态的时间。
clock 函数
库函数clock()提供了一个更为简单的方式用于进程时间,它的返回值描述了进程使用的总的CPU 时间(也就是进程时间,包括用户CPU 时间和系统CPU 时间),其函数原型如下所示:
#include 无参数。
返回值:返回值是到目前为止程序的进程时间,为clock_t 类型,注意clock()的返回值并不是系统节拍数,如果想要获得秒数,请除以CLOCKS_PER_SEC(这是一个宏)。如果返回的进程时间不可用或其值无法表示,则该返回值是-1。
clock()函数虽然可以很方便的获取总的进程时间,但并不能获取到单独的用户CPU 时间和系统CPU 时间,在实际编程当中,根据自己的需要选择。
测试
对示例代码7.3.2 进行简单地修改,使用clock()获取到待测试代码段所消耗的进程时间,如下:
#include 运行结果:

产生随机数
随机数与伪随机数
随机数是随机出现,没有任何规律的一组数列。在我们编程当中,是没有办法获得真正意义上的随机数列的,这是一种理想的情况,在我们的程序当中想要使用随机数列,只能通过算法得到一个伪随机数序列,那在编程当中说到的随机数,基本都是指伪随机数。
C 语言函数库中提供了很多函数用于产生伪随机数,其中最常用的是通过rand()和srand()产生随机数,本小节就以这两个函数为例向大家介绍如何在我们的程序中获得随机数列。
rand 函数
rand()函数用于获取随机数,多次调用rand()可得到一组随机数序列,其函数原型如下:
#include 返回值:返回一个介于0 到RAND_MAX(包含)之间的值,也就是数学上的[0, RAND_MAX]。
程度当中调用rand()可以得到[0, RAND_MAX]之间的伪随机数,多次调用rand()便可以生成一组伪随机树序列,但是这里有个问题,就是每一次运行程序所得到的随机数序列都是相同的,那如何使得每一次启动应用程序所得到的随机数序列是不一样的呢?那就通过设置不同的随机数种子,可通过srand()设置随机数种子。
如果没有调用srand()设置随机数种子的情况下,rand()会将1 作为随机数种子,如果随机数种子相同,那么每一次启动应用程序所得到的随机数序列就是一样的,所以每次启动应用程序需要设置不同的随机数种子,这样就可以使得程序每次运行所得到随机数序列不同。
srand 函数
使用srand()函数为rand()设置随机数种子,其函数原型如下所示:
#include seed:指定一个随机数中,int 类型的数据,一般尝尝将当前时间作为随机数种子赋值给参数seed,譬如time(NULL),因为每次启动应用程序时间上是一样的,所以就能够使得程序中设置的随机数种子在每次启动程序时是不一样的。
返回值:void
常用的用法srand(time(NULL));
测试
使用rand()和srand()产生一组伪随机数,数值范围为[0~100],将其打印出来:
#include 运行结果:

从图中可以发现,每一次得到的[0~100]之间的随机数数组都是不同的(数组不同,不是产生的随机数不同),因为程序中将rand()的随机数种子设置为srand(time(NULL)),直接等于time_t 时间值,意味着每次启动种子都不一样,所以能够产生不同的随机数数组。
本小节关于在Linux 下使用随机数就给大家介绍这么多,产生随机数的API 函数并不仅仅只有这些,除此之外,譬如还有random()、srandom()、initstate()、setstate()等,这里便不再给大家一一介绍了,在我们使用man 手册查看系统调用或C 库函数帮助信息时,在帮助信息页面SEE ALSO 栏会列举出与本函数有关联的一些命令、系统调用或C 库函数等,如下所示(譬如执行man 3 srand 查看):

休眠(延时)
有时需要将进程暂停或休眠一段时间,进入休眠状态之后,程序将暂停运行,直到休眠结束。常用的系统调用和C 库函数有sleep()、usleep()以及nanosleep(),这些函数在应用程序当中通常作为延时使用,譬如延时1 秒钟,本小节将一一介绍。
秒级休眠: sleep
sleep()是一个C 库函数,从函数名字面意思便可以知道该函数的作用了,简单地说,sleep()就是让程序“休息”一会,然后再继续工作。其函数原型如下所示:
#include seconds:休眠时长,以秒为单位。
返回值:如果休眠时长为参数seconds 所指定的秒数,则返回0;若被信号中断则返回剩余的秒数。
sleep()是一个秒级别休眠函数,程序在休眠过程中,是可以被其它信号所打断的,关于信号这些内容,将会在后面章节向大家介绍。
测试
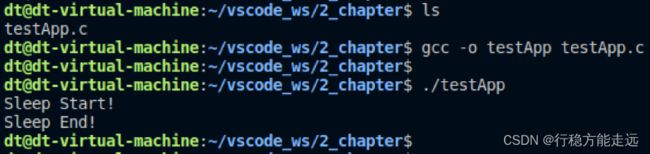
编写一个简单地程序,调用sleep()函数让程序暂停运行(休眠)3 秒钟。
#include 运行结果:
微秒级休眠: usleep
usleep()同样也是一个C 库函数,与sleep()的区别在于休眠时长精度不同,usleep()支持微秒级程序休眠,其函数原型如下所示:
#include 函数参数和返回值含义如下:
usec:休眠时长,以微秒为单位。
返回值:成功返回0;失败返回-1,并设置errno。
测试
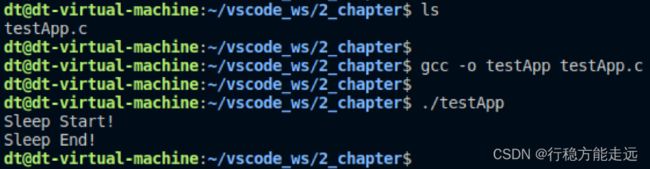
使用usleep()函数让程序休眠3 秒钟。
#include 运行结果:
高精度休眠: nanosleep
nanosleep()与sleep()以及usleep()类似,都用于程序休眠,但nanosleep()具有更高精度来设置休眠时间长度,支持纳秒级时长设置。与sleep()、usleep()不同的是,nanosleep()是一个Linux 系统调用,其函数原型如下所示:
#include req:一个struct timespec 结构体指针,指向一个struct timespec 变量,用于设置休眠时间长度,可精确到纳秒级别。
rem:也是一个struct timespec 结构体指针,指向一个struct timespec 变量,也可设置NULL。
返回值:在成功休眠达到请求的时间间隔后,nanosleep()返回0;如果中途被信号中断或遇到错误,则返回-1,并将剩余时间记录在参数rem 指向的struct timespec 结构体变量中(参数rem 不为NULL 的情况下,如果为NULL 表示不接收剩余时间),还会设置errno 标识错误类型。
在5.2.3 小节中介绍了struct timespec 结构体,该结构体包含了两个成员变量,秒(tv_sec)和纳秒(tv_nsec),具体定义可参考示例代码5.2.2。
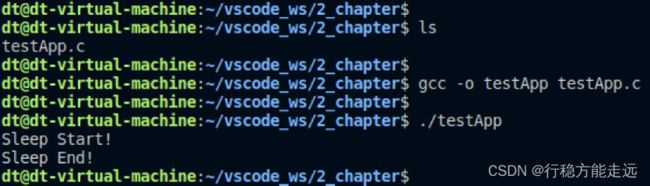
测试
#include 运行结果:
前面说到,在应用程序当中,通常使用这些函数作为延时功能,譬如在程序当中需要延时一秒钟、延时5 毫秒等应用场景时,那么就可以使用这些函数来实现;但是大家需要注意,休眠状态下,该进程会失去CPU使用权,退出系统调度队列,直到休眠结束。在一个裸机程序当中,通常使用for 循环(或双重for 循环)语句来实现延时等待,譬如在for 循环当中执行nop 空指令,也就意味着即使在延时等待情况下,CPU 也是一直都在工作;由此可知,应用程序当中使用休眠用作延时功能,并不是裸机程序中的nop 空指令延时,一旦执行sleep(),进程便主动交出CPU 使用权,暂时退出系统调度队列,在休眠结束前,该进程的指令将得不到执行。
申请堆内存
在操作系统下,内存资源是由操作系统进行管理、分配的,当应用程序想要内存时(这里指的是堆内存),可以向操作系统申请内存,然后使用内存;当不再需要时,将申请的内存释放、归还给操作系统;在许多的应用程序当中,往往都会有这种需求,譬如为一些数据结构动态分配/释放内存空间,本小节向大家介绍应用程序如何向操作系统申请堆内存。
在堆上分配内存:malloc 和free
Linux C 程序当中一般使用malloc()函数为程序分配一段堆内存,而使用free()函数来释放这段内存,先来看下malloc()函数原型,如下所示:
#include size:需要分配的内存大小,以字节为单位。
返回值:返回值为void *类型,如果申请分配内存成功,将返回一个指向该段内存的指针,void *并不是说没有返回值或者返回空指针,而是返回的指针类型未知,所以在调用malloc()时通常需要进行强制类型转换,将void *指针类型转换成我们希望的类型;如果分配内存失败(譬如系统堆内存不足)将返回NULL,如果参数size 为0,返回值也是NULL。
malloc()在堆区分配一块指定大小的内存空间,用来存放数据。这块内存空间在函数执行完成后不会被初始化,它们的值是未知的,所以通常需要程序员对malloc()分配的堆内存进行初始化操作。
在堆上分配的内存,需要开发者自己手动释放掉,通常使用free()函数释放堆内存,free()函数原型如下所示:
#include ptr:指向需要被释放的堆内存对应的指针。
返回值:无返回值。
测试
#include 调用free()还是不调用free()
在学习文件IO 基础章节内容时曾向大家介绍过,Linux 系统中,当一个进程终止时,内核会自动关闭它没有关闭的所有文件(该进程打开的文件,但是在进程终止时未调用close()关闭它)。同样,对于内存来说,也是如此!当进程终止时,内核会将其占用的所有内存都返还给操作系统,这包括在堆内存中由malloc()函数所分配的内存空间。基于内存的这一自动释放机制,很多应用程序通常会省略对free()函数的调用。
这在程序中分配了多块内存的情况下可能会特别有用,因为加入多次对free()的调用不但会消耗品大量的CPU 时间,而且可能会使代码趋于复杂。
虽然依靠终止进程来自动释放内存对大多数程序来说是可以接受的,但最好能够在程序中显式调用free()释放内存:
- 首先其一,显式调用free()能使程序具有更好的可读性和可维护性;
- 其二,对于很多程序来说,申请的内存并不是在程序的生命周期中一直需要,大多数情况下,都是根据代码需求动态申请、释放的,如果申请的内存对程序来说已经不再需要了,那么就已经把它释放、归还给操作系统,如果持续占用,将会导致内存泄漏,也就是人们常说的“你的程序在吃内存”
在堆上分配内存的其它方法
除了malloc()外,C 函数库中还提供了一系列在堆上分配内存的其它函数,本小节将逐一介绍。
用calloc()分配内存
calloc()函数用来动态地分配内存空间并初始化为0,其函数原型如下所示:
#include calloc()在堆中动态地分配nmemb 个长度为size 的连续空间,并将每一个字节都初始化为0。所以它的结果是分配了nmemb * size 个字节长度的内存空间,并且每个字节的值都是0。
返回值:分配成功返回指向该内存的地址,失败则返回NULL。
calloc()与malloc()的一个重要区别是:calloc()在动态分配完内存后,自动初始化该内存空间为零,而malloc()不初始化,里边数据是未知的垃圾数据。下面的两种写法是等价的:
// calloc()分配内存空间并初始化
char *buf1 = (char *)calloc(10, 2);
// malloc()分配内存空间并用memset()初始化
char *buf2 = (char *)malloc(10 * 2);
memset(buf2, 0, 20);
测试
编写测试代码,将用户输入的一组数字存放到堆内存中,并打印出来。
#include 运行结果:

分配对齐内存
C 函数库中还提供了一系列在堆上分配对齐内存的函数,对齐内存在某些应用场合非常有必要,常用于分配对其内存的库函数有:posix_memalign()、aligned_alloc()、memalign()、valloc()、pvalloc(),它们的函数原型如下所示:
#include 使用posix_memalign()、aligned_alloc()、valloc()这三个函数时需要包含头文件
posix_memalign()函数
posix_memalign()函数用于在堆上分配size 个字节大小的对齐内存空间,将 * memptr 指向分配的空间,分配的内存地址将是参数alignment 的整数倍。参数 alignment 表示对齐字节数,alignment 必须是2 的幂次方(譬如2 ^ 4、2 ^ 5、2 ^ 8 等),同时也要是sizeof( void * )的整数倍,对于32 位系统来说,sizeof(void *)等于
4,如果是64 位系统sizeof(void *)等于8。
函数参数和返回值含义如下:
memptr:void ** 类型的指针,内存申请成功后会将分配的内存地址存放在* memptr 中。
alignment:设置内存对其的字节数,alignment 必须是2 的幂次方(譬如2^ 4、2 ^ 5、2 ^ 8 等),同时也要是 sizeof( void *)的整数倍。
size:设置分配的内存大小,以字节为单位,如果参数size 等于0,那么 * memptr 中的值是NULL。
返回值:成功将返回0;失败返回非0 值。
示例代码
#include aligned_alloc()函数
aligned_alloc()函数用于分配size 个字节大小的内存空间,返回指向该空间的指针。
函数参数和返回值含义如下:
alignment:用于设置对齐字节大小,alignment 必须是2 的幂次方(譬如2 ^ 4、2 ^ 5、2 ^ 8 等)。
size:设置分配的内存大小,以字节为单位。参数size 必须是参数alignment 的整数倍。
返回值:成功将返回内存空间的指针,内存空间的起始地址是参数alignment 的整数倍;失败返回NULL。
使用示例
#include memalign()函数
memalign()与aligned_alloc()参数是一样的,它们之间的区别在于:对于参数size 必须是参数alignment的整数倍这个限制条件,memalign()并没有这个限制条件。
Tips:memalign()函数已经过时了,并不提倡使用!
使用示例
#include valloc()函数
valloc()分配size 个字节大小的内存空间,返回指向该内存空间的指针,内存空间的地址是页大小(pagesize)的倍数。
valloc()与memalign()类似,只不过valloc()函数内部实现中,使用了页大小作为对齐的长度,在程序当中,可以通过系统调用getpagesize()来获取内存的页大小。
Tips:valloc()函数已经过时了,并不提倡使用!
使用示例
#include proc 虚拟文件系统
proc文件系统是一个虚拟文件系统,它以文件系统的方式为应用层访问系统内核数据提供了接口,用户和应用程序可以通过proc文件系统得到系统信息和进程相关信息,对proc文件系统的读写作为与内核进行通信的一种手段。但是与普通文件不同的是,proc文件系统是动态创建的,文件本身并不存在于磁盘当中、只存在于内存当中,与devfs一样,都被称为虚拟文件系统。
最初构建proc文件系统是为了提供有关系统中进程相关的信息,但是由于这个文件系统非常有用,因此内核中的很多信息也开始使用它来报告,或启用动态运行时配置。内核构建proc虚拟文件系统,它会将内核运行时的一些关键数据信息以文件的方式呈现在proc文件系统下的一些特定文件中,这样相当于将一些不可见的内核中的数据结构以可视化的方式呈现给应用层。
proc文件系统挂载在系统的/proc目录下,对于内核开发者(譬如驱动开发工程师)来说,proc文件系统给了开发者一种调试内核的方法:通过查看/proc/xxx文件来获取到内核特定数据结构的值,在添加了新功能前后进行对比,就可以判断此功能所产生的影响是否合理。
/proc目录下中包含了一些目录和虚拟文件,如下所示:
可以看到/proc 目录下有很多以数字命名的文件夹,譬如100038、2299、98560,这些数字对应的其实就是一个一个的进程PID 号,每一个进程在内核中都会存在一个编号。
所以这些以数字命名的文件夹中记录了这些进程相关的信息,不同的信息通过不同的虚拟文件呈现出来,关于这些信息将会在后面章节内容中向大家介绍。
/proc 目录下除了文件夹之外,还有很多的虚拟文件,譬如buddyinfo、cgroups、cmdline、version 等等,不同的文件记录了不同信息,关于这些文件记录的信息和意思如下:
⚫ cmdline:内核启动参数;
⚫ cpuinfo:CPU 相关信息;
⚫ iomem:IO 设备的内存使用情况;
⚫ interrupts:显示被占用的中断号和占用者相关的信息;
⚫ ioports:IO 端口的使用情况;
⚫ kcore:系统物理内存映像,不可读取;
⚫ loadavg:系统平均负载;
⚫ meminfo:物理内存和交换分区使用情况;
⚫ modules:加载的模块列表;
⚫ mounts:挂载的文件系统列表;
⚫ partitions:系统识别的分区表;
⚫ swaps:交换分区的利用情况;
⚫ version:内核版本信息;
⚫ uptime:系统运行时间;
proc 文件系统的使用
proc 文件系统的使用就是去读取/proc 目录下的这些文件,获取文件中记录的信息,可以直接使用cat 命令读取,也可以在应用程序中调用open()打开、然后再使用read()函数读取。
使用cat 命令读取
在Linux 系统下直接使用cat 命令查看/proc 目录下的虚拟文件,譬如"cat /proc/version"查看内核版本相关信息:

使用read()函数读取
编写一个简单地程序,使用read()函数读取/proc/version 文件。
#include 运行结果:
