JAVASE进阶:源码精读——HashMap源码详细解析
作者简介:一位大四、研0学生,正在努力准备大四暑假的实习
上期文章:JAVASE进阶:Collection高级(3)——HashSet、LinkedHashSet底层原理
订阅专栏:JAVASE进阶
希望文章对你们有所帮助
在看HashSet底层源码的时候是可以发现其底层是用的HashMap,因此有必要把HashMap的源码仔细读一读,源码之所以难读,就是因为里面的很多写法都还是太高级了,比如数组中索引中同时进行了赋值、位运算等,还是需要有一定的耐心读下去。
HashMap源码详细解析
- 基本原理
- 源码基本属性、方法解析
-
- HashMap基本结构
- HashMap成员变量
- 添加的位置为null
- 添加的位置不为null,且键不重复
-
- 键不重复
- 键重复
基本原理
之前学习HashSet的时候有分析过运行的原理,如下所示:
1、创建一个默认长度为16、默认加载因子为0.75的数组,数组名为table
2、根据元素的哈希值与数组的长度计算出应存入的位置(index = (数组长度 - 1) & 哈希值)
3、判断当前位置是否为null,是则直接存入
4、若当前位置不为null,表示有元素,则调用equals方法比较属性值
5、equals方法判断是一样的,就不存储,如果不一样,就存入这个位置,形成链表
注意:
加载因子决定了哈希表的扩容时机,当存储了
16*0.75=12个位置后将会进行2倍扩容
JDK8以后,形成链表的方式是直接将新元素挂在老元素下面
当数组长度 ≥ 64,且当前位置的链表长度 > 8时,当前的链表就会自动转换成红黑树,从而提高效率
而HashMap的Key做的过程和上面也是一样的,元素之间的比较就是key进行的,因此可以对照上面的原理去分析源码。
源码基本属性、方法解析
HashMap基本结构
1、Ctrl+N进入HashMap的底层源码,Ctrl+F12找到Node,可以看到结点实现了Map的键值对接口,并封装了一些操作HashMap的方法,重点可以看出它具有的属性:
1、哈希值:计算存入位置
2、key
3、value
4、next:下一个结点的地址值,用于当哈希表中位置有多个元素时要形成的链表连接

2、Ctrl+F12找到TreeNode,这是一个红黑树,其重点组成:
1、parent:父结点
2、left:左孩子
3、right:右孩子
4、red:布尔类型,表示结点是否为红色

HashMap成员变量
1、哈希表的名称为table:

2、默认初始容量为16,加载因子为0.75:

3、Ctrl+F12查看HashMap的构造函数,发现只赋值了加载因子,并没有新建数组,所以有些面经中new HashMap<>()会创建一个长度为16的哈希表并不正确:

4、创建长度为16的哈希表是在执行第一次put操作时进行的,可以进行源码验证:
(1)Ctrl+F12查看put方法,其调用了putVal函数,不难看出,默认底层onlyIfAbsent=false表示当有元素重复的时候,默认不会保持唯一性,即默认会进行覆盖:

(2)其调用的putVal函数如下,这个函数处理的情况还是很多的,一次性读完很有难度,这里先简单看,可以看出当table为空或者数组的长度为0,就会调用resize()方法:
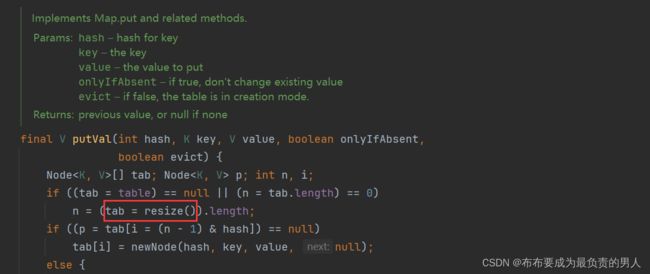
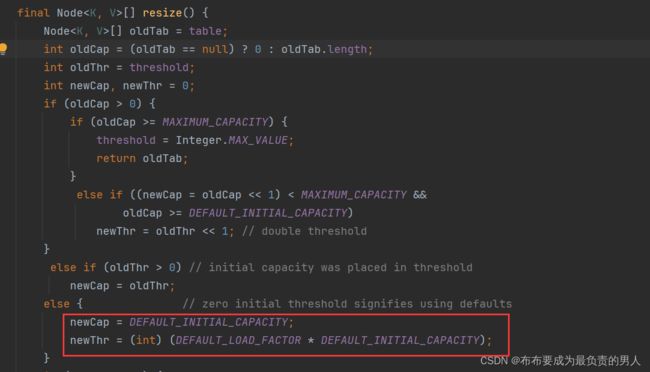
(3)跟踪resize()方法,它会设置newCap = 16,newThr = 12(16 * 0.75),因为这边的处理都是局部变量,所以后面newThr会赋值给成员变量threshold,以后每次执行resize的时候都会将这个成员变量取过来做处理,可以理解成哈希表要做扩容时候的阈值:

添加的位置为null
Ctrl+Alt+←返回putVal函数,查看这部分语句,并做个拆分解析:

这部分语句可以拆解成:
i = (n - 1) & hash;//根据哈希值求出元素要放的位置index
p = tab[i];//获取数组中这个位置的数据,并赋值给p
if(p == null){
//数组中这个位置为空,则直接开辟新结点
tab[i] = newNode(hash, key, value, null);
}
newNode底层其实就是根据传入的参数创建出一个键值对,并且这是一个非树结点,也就是做链表操作用的:

后面的else是不会走的,然后就会执行下方语句,存入元素后如果长度已经超过了阈值12,也就是说达到了扩容时机,那么就需要执行resize去扩容,最终返回null表示没有任何元素发生覆盖:

添加的位置不为null,且键不重复
如果添加元素的时候,当前的位置不为null,就会执行else语句,else里面的这一段的源代码我直接贴过来,其主要分为2种情况:键不重复与键重复,在后续分情况进行讨论:
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
键不重复
执行的代码片段如下,这一部分也拆分讲解一下比较好:
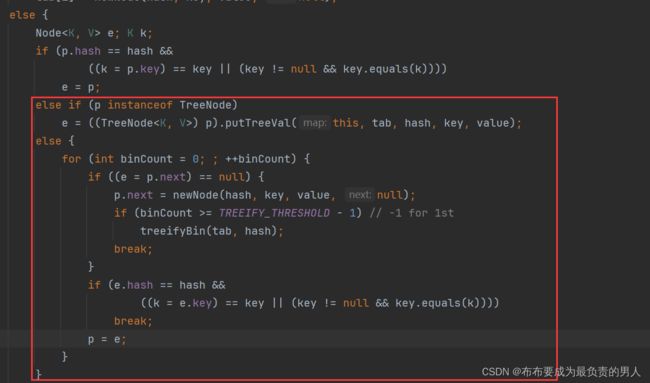
1、存入位置相同,且键不重复,显然第一个if不会执行,后面的else if和else里面就都是键不重复的情况了,继续往下分析。
2、else if先判断哈希表中这个位置的数据结构是不是红黑树,是的话就添加一个红黑树结点e
3、else里面说明哈希表中这个位置的数据结构不是红黑树,是一个链表,所以添加一个链表结点e,新增的规则是将新键直接挂在旧键下面,并且如果这个链表的长度超过了指定值(8),就会执行treeifyBin方法,treeifyBin会继续判断整个哈希表数组的长度是否大于等于64,是的话就把这个位置中的链表转化为红黑树。
键不会重复,所以后面的执行就是同前面了。
键重复
键重复,就会默认执行覆盖操作,并且返回被覆盖掉的老元素的value值,而通过源码我们可以看到的覆盖,其实不是把整个键值对进行覆盖,仅仅是将新元素对应的value值覆盖了老元素对应的value值:
