线性表基本概念及用法
目录
线性表的定义
线性表:
线性表的抽象数据类型
线性表的抽象数据类型定义:
组合例题
注意一个需要混淆的地方:
线性表的顺序存储结构
顺序存储定义:
顺序存储方式:
数据长度与线性表长度的区别:
地址计算方法:
顺序存储结构的插入和删除
获得元素操作:
插入操作:
删除操作:
线性表顺序存储结构的优缺点:
线性表的链式存储结构
链式存储结构基本定义:
线性表链式存储结构代码描述:
单链表的读取
单链表的插入与删除:
单链表的删除:
显然
单链表的整表创建
单链表整表创建的算法思路:
单链表的整表删除
单链表整表删除的算法思路:
单链表结构与顺序存储结构的优缺点
静态链表
静态链表的插入操作
静态链表的删除操作:
循环链表
合成链表
双向链表
双向链表插入:
双向链表的删除:
简单总结
总结回顾
线性表的定义
线性表:
零个或多个数据元素的有限序列
若将线性表记为(a1,a2,a3.......ai,an)a1称为a2的直接前驱元素,a3称为a2的直接后继元素,线性表的个数n定义为线性表的长度,当n=0是,称为空集。
ai,i称数据元素ai在线性表中的位序。
在较为复杂的线性表中,一个数据元素可以由若干个数据项组成
线性表的抽象数据类型
线性表的抽象数据类型定义:
ADT 线性表(List)
Data
线性表的数据对象集合为{a1,a2,a3,.......an},每个元素的类型均为DataType。其中,除了第一个元素a1外,每一个元素有且只有一个前驱元素,除了最后一个数据元素an外,每一个元素有且只有一个直接后继元素。数据元素之间的关系是一对一的关系。
Operation
InitList(*L)//初始化操作,建立一个空的线性表L。
ListEmpty(L)//若线性表为空,返回true,否则返回false。
ClearList(*L)//将线性表清空。
GetElem(L,i,*e)//将线性表L中的第i个位置元素值返回给e
LocateElem(L,e)//在线性表L中查找与给定值e相等的遇难苏,如果查找成功,返回该元素在表中序号表示
成功;否则,返回0表示失败。
Listinsert(*L,i,e)//在线性表L中第i个元素位置插入新元素e
ListDelete(*L,i,*e)//删除线性表L中第i个位置的元素,并用e返回其值
ListLength(L)//返回线性表L的元素个数
endADT组合例题
上面都是线性表的基本操作,对于涉及线性表的问题可以更加复杂,比如合并两个几个,需要用这些基本操作的组合来实现
A=AUB,循环B集合中每个元素,发现B集合中存在的A集合中不存在,即将元素插入A集合中
//将线性表Lb中但不存在La中的元素插入La
void unionL(SqList *La,SqList Lb)
{
int La_len,Lb_len,i;
ElemType e;//声明与La,Lb相同的数据元素e
La_len=ListLength(*La);//求线性表的长度
Lb_len=Listlength(Lb);
for(i=1;i<=Lb_len;i++)
{
GetElem(Lb,i,&e);//取Lb中第i元素赋给e
if(!LocateElem(*La,e))//La中不存在和e相同数据元素
ListInsert(La,++La_len,e);//插入
}
}注意一个需要混淆的地方:
1、当你传递一个参数给函数的时候,这个参数会不会在函数内被改动决定了使用什么参数形式
2、如果需要被改动,则需要传递指向这个参数的指针
3、如果不需要改动,可以直接传递这个参数
线性表的顺序存储结构
顺序存储定义:
线性表的顺序存储结构,指的是使用一段地址连续的存储单元依次存储线性表的数据元素
顺序存储方式:
线性表的每个数据元素的类型都相同,所以用c语言的一维数组来实现顺序存储结构,即可以把第一个数据元素存到数组下表为0的韦志中,接着把线性表相邻的元素存储在数组中相邻的位置。
线性表的顺序存储的结构代码:
#define MAXSIZE 20//存储空间初始分配量
Typedef int ElemType;//ElemType类型根据实际情况而定,这里是int
typedef struct
{
ElemType data[MAXSIZE];//数组,存储数据元素
int length;//线性表当前长度
}SqList数据长度与线性表长度的区别:
数组的长度是存放线性表的存储空间的长度,存储分配后这个量一般是不变的
线性表的长度是线性表中数据元素的个数,随着线性表的插入和删除等操作进行,这个量是变化的
在任意时刻,线性表的长队应该小于等于数组的长度
地址计算方法:

存储器中的每个存储单元都有自己的编号,这个编号称为地址。
假设占用的是c个存储单元,呢么线性表中第i+1个数据元素的存储位置和第个数据的存储位置关系满足下列关系(Loc表示获得存储位置的函数)
Loc(ai+1)=Loc(ai)+c
通过这个公式,你可以随时计算出线性表中任意未知的位置,不管他是第一个还是最后一个,都是相同的时间
我们对线性表未知的存入或者取出数据,对于计算机来说都是相等的时间,也就是一个常数,因此它的存取时间性能为O(1)。
我们通常把具有这一特点的存储结构称为 随机存储结构
顺序存储结构的插入和删除
获得元素操作:
对于线性表的顺序存储结构来说,如果我们哟啊哈斯先GetElem操作,即将线性表L中的第i个位置元素值返回
#define ok 1
#define ERROR 0
typedf int Status;
//初始条件:顺序线性表L已存在,1<=i<=ListLength(L);
//操作结果:用e返回L中第i个数据元素的值,注意i是指的位置,第1个位置的数组是从0开始
Status GetElem(SqList L,int i,ElemType*e)
{
if(L.length==0||i<1||i>L.length)
return ERROR;
*e=L.data[i-1];
return ok;
}插入操作:
即在线性表L中的第i个位置插入新元素e
插入算法的思路:
(1)如果插入位置不合理,抛出异常
(2)如果线性表长度对等于数组长度,则抛出异常或动态增加容量
(3)从最后一个元素开始向前遍历到第i个位置,分别将他们都向后移动一个位置
(4)将要插入元素填入i位置处
(5)表长加1
//初始化条件:顺序线性表L已存在,1<=i<=ListLength(L)
//操作结果:在L中第i个位置之前插入新的数据元素e,L的长度加1
Status ListInsert(SqList *L,int i,ElemType e)
{
int k;
if(L->length==MAXSIZE)//顺序线性表已满
return ERROR;
if(i<1||i>L->length+1)//当i比第一位置小或者比最后一位置后位置还要大时
return ERROR;
if(i<=L->length)//若插入数据不在表尾
{
for(k=L->length-1;k>=i-1;k--)//将要插入为之后的元素向后移一位
L->data[k+1]=L->data[k];
}
L->data[i-1]=e;//将新元素插入
L->length++;
return ok;
}
删除操作:
删除算法思路:
(1)如果删除位置不合理,抛出异常
(2)取出删除元素
(3)从删除元素位置开始遍历到最后一个元素位置,分别将他们都向前移动一个位置
(4)表长减1
//操作结果:删除L的第i个数据元素,并用e返回其值,L的长度减1
Status ListDelete(SqList *L,int i,ElemType *e)
{
int k;
if(L->length==0);//线性表为空
return ERROR;
if(i<1||i>L->length)//删除位置不正确
return ERROR;
*e=L->data[i-1];
if(iLength)//如果删除的不是最后一个位置
{
for(k=i;klength;k++)//将桑出位置后级元素前移
L->data[k-1]=L->data[k];
}
L->length--;
return ok;
} 最坏情况下所有元素向后移动
则该时间复杂度为O(n)
线性表顺序存储结构的优缺点:
优点:
无需为表示表中元素之间的逻辑关系而增加额外的存储空间
可以快速地存取表中任意位置的元素
缺点:
插入和删除操作需要移动大量元素
当线性表长度变化较大是,难以确定存储空间的容量
造成存储空间的“碎片”
线性表的链式存储结构
链式存储结构基本定义:
线性表的链式存储结构特点是用一组任意的存储单元存储线性表的数据元素,这组数据元素可以是连续的,也可以不是连续的
链式存储结构中,除了要存储数据元素信息外,还要存储它的后继元素的存储地址。
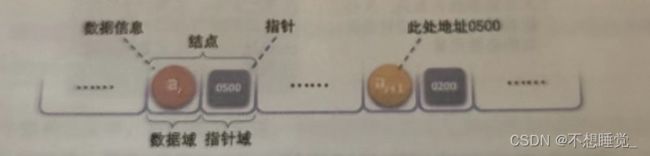
我们把存储数据元素信息的域称为数据域,把存储直接后继位置的域称为指针域,指针域中存储的信息称为指针或链
这两部分信息组称数据元素的存储映像,称为结点。
链表的第一个结点的存储位置叫做头指针
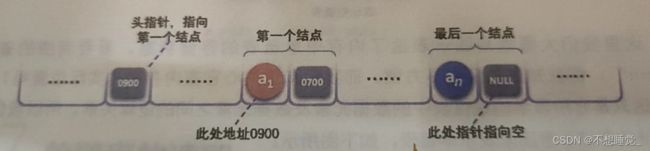
为了更方便对链表的操作,会在单链表的第一个结点前附设一个结点,称为头结点
头指针与头结点的异同:
头指针:
1.头指针是指链表指向第一个结点的指针,若链表有头结点,则是指向头结点的指针
2.头指针具有标志作用,所以常用头指针冠以链表的名字
3.无论链表是否为空,头指针均不为空。头指针是链表的必要元素
头结点:
1.头结点是为了操作的统一和方便而设立的,放在第一个元素的结点之前,其数据域一般无意义 (也可以存放链表的长度)
2.有了头结点,对在第一元素结点前插入结点和删除第一结点,其操作与其他结点的操作就统一了
3.头结点不一定是链表必须的要素
线性表链式存储结构代码描述:
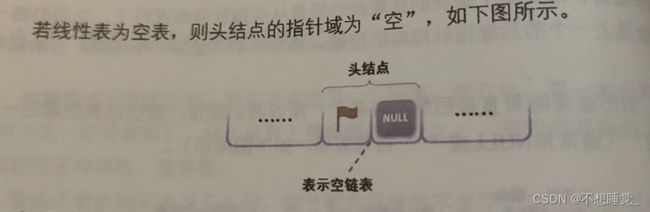
若线性表为空,则头指针的指针域为“空”
单链表中,我们在C语言中可以用结构体指针来描述:
//线性表的单链表存储结构
typedef struct Node
{
ElemType data;
struct Node *next;
}Node;
typedef struct Node *LinkList;//定义LinkList;单链表的读取
获得链表第i个数据的算法思路:
(1)声明一个指针p指向链表第一个结点,初始化j从1开始;
(2)当j (3)若到链表末尾p为空,则说明第i个结点不存在 (4)否则查找成功,返回节点p的数据 时间复杂度最坏情况为O(n) 单链表第i个数据插入节点的算法思路: (1)声明一个指针p指向链表头结点,初始化j从1开始; (2)当就j (3)若到链表末尾p为空,则说明第i个节点不存在 (4)否则查找成功,在系统中生成一个空结点s; (5)将数据元素e复制给s->data (6)单链表的插入标准语句s->next=p->next;p->next=s; (7)返回成功 单链表第i个数据删除结点的算法思路; (1)声明一指针p指向链表头结点,初始化j从1开始; (2)当就j (3)若链表末尾p为空,则说明第i个结点不存在 (4)否则查找成功,将于删除的结点p->next赋值给q; (5)单链表的删除标准语句p->next=q->next (6)将q结点中的数据赋值给e,作为返回 (7)释放q结点; (8)返回成功 对于插入或删除数据越频繁的操作,单链表的效率优势越明显 单链表和顺序存储结构不一样,它不像顺序存储结构这么集中,它可以很散,是一种动态结构。对于每个链表来说,它所招用空间的大小和位置是不需要提前分配划定的,可以根据系统的情况和实际需求即时生成 即单链表的生成就是一个动态生成链表的过程 即从“空表”的初始状态起,一次建立各元素结点,并逐个插入链表 (1)声明一指针p和计数器变量i; (2)初始化一空链表L; (3)让L的头结点的指针指向NULL,即建立一个带头结点的单链表 (4)循环: 1.生成一新结点赋值给p; 2.随机生成一数字赋值给p的数据域p->data; 3.将p插入到头结点域前一新结点之间 这段算法代码里,我们其实用的是插队的办法,就是始终让新结点在第一的位置。我们把这种算法简称为头插法 按排队的正常思维,所谓先来后到,我们每次把新结点都插在终端结点的后面,这种算法我们简称为尾插法 当我们不打算使用这个单链表时,我们需要把它销毁,其实也就是在内存中将它释放掉,以便流出空间给其他程序或软件使用 (1)声明一指针p和q; (2)将第一个结点赋值给p; (3)循环; 1.将下一结点赋值给q; 2.释放p; 3.将q赋值给p; 通过对比得出: 若线性表需要频繁查找,很少进行插入和删除操作时,宜采用顺序存储结构 当线性表中的元素个数变化较大时或者根本不知道有多大时,最好用单链表结构 在早期的Basic、Fortran等高级编程语言中,由于没有指针,就有人想出来用数组来代替指针描述单链表 我们把这种用数组描述的链表称为静态链表 为了方便插入数据,我们通常会把数组建立得大一些,以便有空闲空间而不会溢出 另外我们对数组第一个和最后一个元素作为特殊元素处理,不存数据 我们通常把未被使用的数组元素称为备用链表 数组第一个元素,即下标为0的元素的cur就存放备用链表的第一个结点的下标 数组的最后一个元素的cur则存放第一个右束支的元素的下标,相当于单链表中的头结点作用,当整个链表为空是,则为0. 此时图示相当于初始化的数组状态: 假如我们已经将数据存入静态链表,则它处于如下图所示这种状态 说明: 此时“甲”这里就存有下一元素“已”的游标2,“已”则存有下一个元素“丁”的下标3.“庚”作为最后一个有值元素,所以它的cur设置为0.而最后一个元素的cur则因“甲”是第一有值元素而存有它的下标为1。 而第一个元素则因空闲空间的第一个元素下标为7,所以它的cur为7. 静态链表中要解决的是:如何用静态模拟动态链表结构的存储空间的分配,需要时申请,无用时释放 为了辨明数组中那些分量未被使用,解决的方式是将所有未被使用过的及已被删除的分量用游标链成一个备用的链表,每当进行插入式,便可以从备用链表上取得第一个结点作为待插入的新结点 这段代码一方面它的作用是返回数组头元素cur存的第一个空闲的下标,既然要准备使用了,那么久的有接替者,就把分量7的cur值赋值给space【0】.cur, 现在进行插入操作: “已”与“丁”之间插入一个“丙”,那么我们先找到“已”,把它的cur改成7,再回到“丙”这把cur改成3 和前面一样,删除元素时,原来是需要释放结点的函数free()。现在我们也得自己实现它 将单链表中终端结点的指针端由空指针改为指向头结点,使得整个单链表形成一个环,这种头尾相接的单链表称为单循环链表,简称循环链表。 循环链表解决了一个很麻烦的问题,就是不管从何点出发,都可访问链表的全部结点 改良 单链表中,我们可以用O(1)的时间访问第一个结点,但对于访问最后一个节点,却需要O(n)的时间 经过改造循环链表,不用头指针,而是用指向终端结点的为指针来表示循环链表,此时查找开始结点和终端结点都很方便了 从图中可以看到,查找终端的时间复杂度为O(1),查找头结点的时间复杂度也是O(1)。 代码如下 最坏的条件下,循环链表的时间复杂度为O(n),为了克服这一缺点,设计出了双向链表 双向链表是在单链表的每个节点中,在设置一个指向其前驱结点的指针域 空链表 非空的循环带头结点的双向链表 双向链表相对于单链表,更为复杂,空间占用多一些,不过有良好的对称性,为操作带来了方便,换句话讲,就是那空间换时间 线性表是另个或多个具有想同类型的数据元素的有限序列,从顺序存储结构延生一系列存储结构 线性表的学习对后面其他的数据结构的基础有着至关重要的作用//初始条件:链式线性表L已存在,1<=i<=ListLength(L)
//操作结果:用e返回L中第i个数据元素的值
Status GetElem(LinkList L,int i,ElemType *e)
{
int j;
LinkList p;//声明一结点p
p=L->next;//让p指向链表L的第一个结点
j=1;//j为计数器
while(p&&j单链表的插入与删除:
//操作结果:在L中第i个位置之前插入新的数据元素e,L的长度加1
Status ListInsert(LinkList *L,int i,ElemType e)
{
int j;
LinkList p,s;
p=*L;
j=1;
while(p&&j单链表的删除:
//操作结果:删除L的第i个数据元素,并用e返回其值,L的长度减1;
Status ListDelete(LinkList *L,int i,ElemType *e)
{
int j;
LinkList p,q;
p=*L;
j=1;
while(p&&j显然
单链表的整表创建
单链表整表创建的算法思路:
//随机产生n个元素的值,建立带表头结点的单链线性表L
void CreateListHead(LinkList*L,int n)
{
LinkList p;
int i;
srand(time(0));//以时间为依据,初始化随机数种子
*L=(LinkList)malloc(sizeof(Node));
(*L)->next=NULL;//先建立一个带头结点的单链表
for(i=0;i
//随机产生n个元素,建立带表头结点的单链线性表L(尾插法)
void CreateListTail(LinkList *L,int n)
{
LinkList p,r;
int i;
srand(time(0));
*L=(LinkList)malloc(sizeof(Node));//L为整个线性表
r=*L;//r为指向尾部的结点
for(i=0;i单链表的整表删除
单链表整表删除的算法思路:
//初始条件:链式线性表L已存在。操作噢结果:将L重置为空表
Status ClearList(LinkList*L)
{
LinkList p,q;
p=(*L)->next;//p指向第一个结点
while(p)//没到表尾
{
q=p->next;
free(p);
p=q;
}
(*L)->next=NULL;//头结点指针域为空
return ok;
}
单链表结构与顺序存储结构的优缺点
静态链表
#define MAXSIZE 1000//存储空间初始分配量
//线性表的静态链表存储结构
typedef struct
{
ElemType data;
int cur;//游标(curosr),为0时表示无指向
}Component,StaticLinkList[MAXSIZE];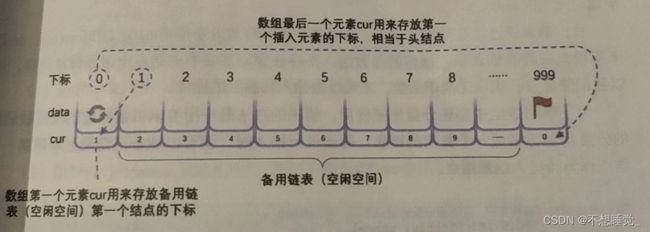
//将一维数组space中各分量链成一个备用链表,spcae[0].cur为头指针,“0”表示空指针
Status InitList(StaticLinkList space)
{
int i;
for(i=0;i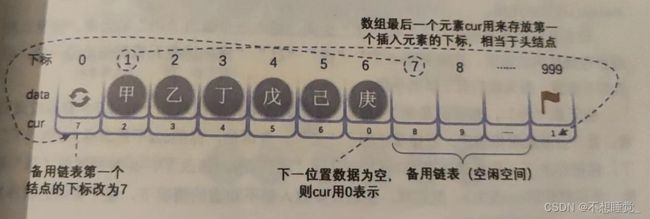
静态链表的插入操作
//若备用空间链表非空,则返回分配的结点下标,否则返回0
int Malloc_SSL(StaticLinkList space)
{
int i=space[0].cur;//当前数组第一个元素的cur存的值
//就是要返回的第一个备用空闲的下标
if(space[0].cur)
space[0].cur=space[i].cur;//由于要拿出一个分量来试用了,所以我们就把它的下一个分量用来备用
return i;
}
Static ListInsert(StaticLinkList L,int i,ElemType e)
{
int j,k,l;
k=MAXSIZE-1;//注意k首先是最后一个元素的下标
if(i<1||i>ListLength(L)+1)
return ERROR;
j=Malloc_SSL(L);//获得空闲分量的下标
if(j)
{
L[j].data=e;//将数据赋值给次分量的data
for(l=1;l<=i-1;l++)//找到第i个元素之前的位置
k=L[k].cur;
L[j].cur=L[k].cur;//把第i个元素之前的cur赋值给新元素的cur
L[k].cur=j;
}
return ERROR;
}静态链表的删除操作:
//删除在L中第i个数据元素
Status ListDelete(StaticLinkList L,int i)
{
int j,k;
if(i<1||i>ListLength(L))
return ERROR;
k=MAXSIZE-1;
for(j=1;j<=i-1;j++)
k=L[k].cur;
j=L[k].cur;
L[k].cur=L[j].cur;
Free_SSL(L,j);
return ok;
}
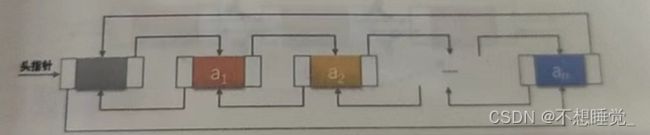
循环链表

合成链表

p=rearA->next;//保留A表的头结点,即1
rearA->next=rearB->next->next;//将本事指向B表的第一个结点,赋值给rearA->next
q=rearB->next;
rearB->next=p;//将原A表的头结点赋值给rearB->next;
free(q);双向链表
//线性表的双向链表存储结构
typedef struct DulNode
{
ElemType data;
Struct DuLNode *prior;//直接前驱指针
struct DuLNode *next;//直接后继指针
}DulNode,*DuLinkList;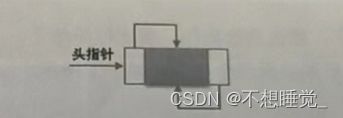
p->next->prior==p==p->prior->next//结点的前驱的直接后继还是自己双向链表插入:
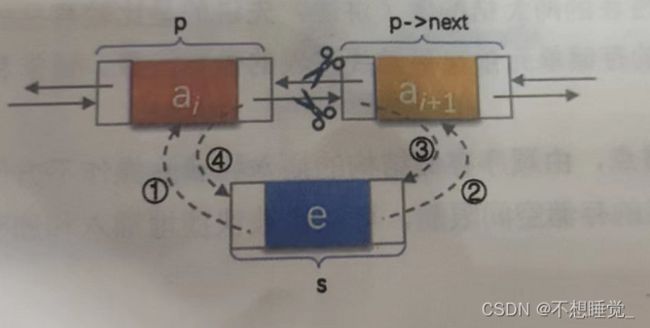
s->prior=p;//把p赋值给s的直接前驱
s->next=p->next;//把p的后继直接复制给s的后继
p->next->prior=s;//把s赋值给p->next的前驱
p->next=s;//把s赋值给p的后继双向链表的删除:

p->prior->next=p->next;//把p的后继赋值给p的前驱的后继
p->next->prior=p->prior;//把p的前驱赋值给p后继的前驱
free(p);简单总结
总结回顾
