FlinkSql通用调优策略
历史文章迁移,稍后整理
使用DataGenerator 提前进行压测,了解数据的处理瓶颈、性能测试和消费能力
开启minibatch:"table.exec.mini-batch.enabled", "true"
开启Local+Global 两阶段聚合:"table.exec.mini-batch.enabled", "true"
解决数据倾斜问题:
流式倾斜,开启minibatch
窗口类有界操作,传统的两阶段聚合的方式
数据源分布就不均匀,做reblance
针对大状态开启rocksdb
针对分区无数据导致watermark的窗口等不触发,设置idle
利用paimon做中间存储,既可以做批流复用olap,lookup join 时把全量数据拉到rocksdb并且是分片存的,效率很高,缺点是有延迟,会有join key miss的问题
暴力调优,加内存,调大并行度
设置空闲 State 保留时间 ,看情况,设置不当会影响结果正确性
FlinkSql 可以指定空闲状态(即未更新的状态)被保留的最小时间,当状态中的某个 Key 对应的状态未更新的时间达到阈值时,这条状态会被自动清理
4.2 开启 MiniBatch
Flink 是流式数据处理,没过来一条数据就会被直接处理
MiniBatch 是把流处理变为微批处理的方式,先缓存一定的数据后在触发处理,这样可以减少对 State 的访问、提升吞吐、有效减少输出数据量
但是会牺牲低延迟,对超低延迟要求的场景不建议用,常用在需要聚合的场景,有显著的性能提升
// 开启 miniBatch
configuration.setString("table.exec.mini-batch.enabled", "true");
// 批量输出的间隔时间
configuration.setString("table.exec.mini-batch.allow-latency", "5 s");
// 防止 OOM 设置每个批次最多缓存数据的条数,可以设为 2 万条
configuration.setString("table.exec.mini-batch.size", "20000");主要是依靠每个 Task 上注册的 Timer 线程(Flink 的定时器)来触发微批,当然了,是需要消耗一定的线程性能
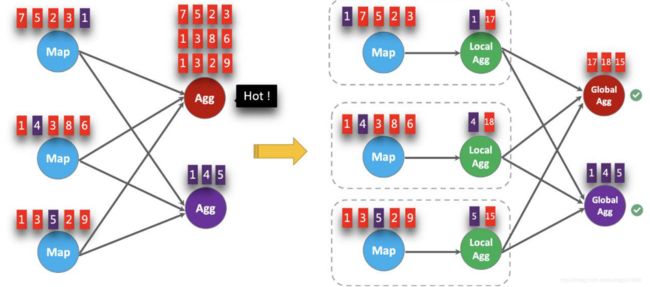
4.3 开启 LocalGlobal
其实就是本地聚合(Spark 的 reduceByKey 和 MR 的 Combine),所以开启 LocalGlobal 必须开启 MiniBatch,可以有效解决SUM的那个聚合函数数据倾斜的问题,同时还能优化上游对下游的数据传输、以及下游聚合的压力
// 开启 LocalGlobal
configuration.setString("table.optimizer.agg-phase-strategy", "TWO_PHASE");如下图,红色和紫色分别代表两个 Key 的数据进行聚合时的效果
4.4 开启 Split Distinct
LocalGlobal 的方式可以有效解决 SUM 等聚合函数数据倾斜的问题,但是对于 Group 后的 Count ( Distinct )的热点问题没法解决
1. 以前我们手动打散的方案
SELECT a, SUM(cnt)
FROM (
SELECT a, COUNT(DISTINCT b) as cnt
FROM T
GROUP BY a, MOD(HASH_CODE(b), 1024)
)
GROUP BY a2. FlinkSql 自动实现了这部分功能,只需要我们开启 Split Distinct 参数即可
// 设置参数:(要结合 minibatch 一起使用)
// 开启 Split Distinct
configuration.setString("table.optimizer.distinct-agg.split.enabled", "true");
// 第一层打散的 bucket 数目
configuration.setString("table.optimizer.distinct-agg.split.bucket-num", "1024");原理如下图,红色和紫色仍然分别代表两个 Key 的数据,但是红色的数据显然很多,但是去重必须同一个 Key 的数据肯定在一个节点,所以压力较大

4.5 Count ( Distinct ) 时可以用 Filter 代替 Case When
我们经常会写这样的 Sql,如下会有 3 个状态实例
SELECT
a,
COUNT(DISTINCT b) AS total_b,
COUNT(DISTINCT CASE WHEN c IN ('A', 'B') THEN b ELSE NULL END) AS AB_b,
COUNT(DISTINCT CASE WHEN c IN ('C', 'D') THEN b ELSE NULL END) AS CD_b
FROM T
GROUP BY a
而 FlinkSql 的优化器可以识别同一唯一键的不同 Filter 参数,三个 COUNT DISTINCT 都作用在 b 列上,我们可以利用 Filter 的这一特性,Flink 可以只使用一个共享状态实例,可减少状态的大小和对状态的访问
SELECT
a,
COUNT(DISTINCT b) AS total_b,
COUNT(DISTINCT b) FILTER (WHERE c IN ('A', 'B')) AS AB_b,
COUNT(DISTINCT b) FILTER (WHERE c IN ('C', 'D')) AS CD_b
FROM T
GROUP BY a
解决数据倾斜、反压问题
lookup join 的优化,避免性能较差的热查询
paimon属于链路的优化,既可以数据重用,重写了lookup join 减少checkpoint压力,缺点是...
FlinkSql window tvf 本身也是一种优化
这些都是通用的,很多时候其实这些方式解决不了,可以根据实际业务去探索某个业务的最佳方式
另外有时基于海量数据和业务要求的时效性和复杂度经常需要用到算子来处理