CDN相关和HTTP代理
CDN相关和HTTP代理
参考:
《透视 HTTP 协议》——chrono
把这两个放在一起是因为容易搞混,我一开始总以为CDN就是HTTP代理,但是看了极客时间里透视HTTP协议的讲解,感觉又不仅于此,于是专门写下来。
先说结论:CDN使用了HTTP缓存代理的技术+DNS负载均衡技术,它是一组分散在不同地理位置的web服务器。
什么是HTTP缓存代理
意思是这里有个代理服务器,然后它拥有缓存的能力。在 HTTP 的缓存体系中,缓存代理的身份十分特殊,它“既是客户端,又是服务器”,同时也“既不是客户端,又不是服务器”。
你可能听说过Nginx反向代理,是的,Nginx可以用于搭建HTTP缓存代理服务器。
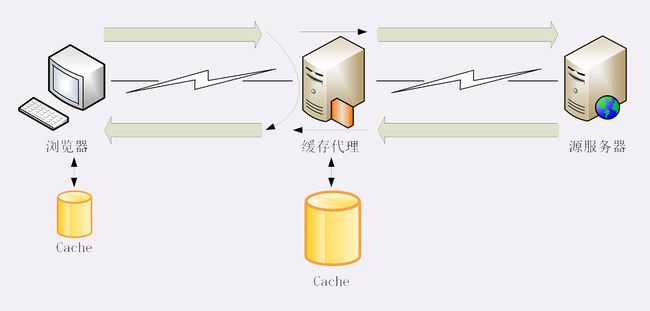
代理最基本的一个功能是负载均衡。因为在面向客户端时屏蔽了源服务器,客户端看到的只是代理服务器,源服务器究竟有多少台、是哪些 IP 地址都不知道。于是代理服务器就可以掌握请求分发的“大权”,决定由后面的哪台服务器来响应请求。
常用的负载均衡算法,比如轮询、一致性哈希等等,这些算法的目标都是尽量把外部的流量合理地分散到多台源服务器,提高系统的整体资源利用率和性能。
代理服务的功能
- 健康检查:使用“心跳”等机制监控后端服务器,发现有故障就及时“踢出”集群,保证服务高可用;
- 安全防护:保护被代理的后端服务器,限制 IP 地址或流量,抵御网络攻击和过载;
- 加密卸载:对外网使用 SSL/TLS 加密通信认证,而在安全的内网不加密,消除加解密成本;
- 数据过滤:拦截上下行的数据,任意指定策略修改请求或者响应;
- 内容缓存:暂存、复用服务器响应。
代理相关头字段
- Via
代理服务器需要用字段“Via”标明代理的身份。
Via 是一个通用字段,请求头或响应头里都可以出现。每当报文经过一个代理节点,代理服务器就会把自身的信息追加到字段的末尾。如果通信链路中有很多中间代理,就会在 Via 里形成一个链表,这样就可以知道报文究竟走过了多少个环节才到达了目的地。
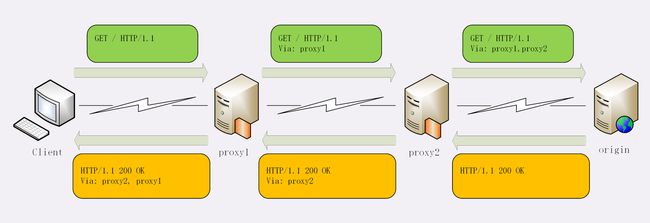
- X-Forwarded-For & X-Real-IP (有部分代理服务器不支持,需要代理服务器和后端自行约定)
X-Forwarded-For
“Via”追加的是代理主机名(或者域名),而“X-Forwarded-For”追加的是请求方的 IP 地址。所以,在字段里最左边的 IP 地址就是客户端的地址。
X-Real-IP
“X-Real-IP”是另一种获取客户端真实 IP 的手段,它的作用很简单,就是记录客户端 IP 地址,没有中间的代理信息,相当于是“X-Forwarded-For”的简化版。如果客户端和源服务器之间只有一个代理,那么这两个字段的值就是相同的。
协议实现
有了相关协议头,服务器和代理服务器就能拿到客户端的IP信息了,但是对于代理服务器来说大大增加了转发成本,原本只是直接转发的事,现在却变成要解析文本、再添加头部字段、再转发。而且尤其是一些加密信息更是无法解析的,这样的话要怎么解决呢?>
所以就出现了一个专门的“代理协议”(The PROXY protocol),它由知名的代理软件 HAProxy 所定义,也是一个“事实标准”,被广泛采用(注意并不是 RFC)。“代理协议”有 v1 和 v2 两个版本,v1 和 HTTP 差不多,也是明文,而 v2 是二进制格式。今天只介绍比较好理解的 v1,它在 HTTP 报文前增加了一行 ASCII 码文本,相当于又多了一个头。
这一行文本其实非常简单,开头必须是“PROXY”五个大写字母,然后是“TCP4”或者“TCP6”,表示客户端的 IP 地址类型,再后面是请求方地址、应答方地址、请求方端口号、应答方端口号,最后用一个回车换行(\r\n)结束。
服务器看到这样的报文,只要解析第一行就可以拿到客户端地址,不需要再去理会后面的 HTTP 数据,省了很多事情。
// 客户端的真实 IP 地址是“1.1.1.1”,端口号是 55555。
PROXY TCP4 1.1.1.1 2.2.2.2 55555 80\r\n
GET / HTTP/1.1\r\n
Host: www.xxx.com\r\n
\r\n
缓存代理的缓存控制
代理服务收到源服务器发来的响应数据后需要做两件事。第一个当然是把报文转发给客户端,而第二个就是把报文存入自己的 Cache 里。
下一次再有相同的请求,代理服务器就可以直接发送 304 或者缓存数据,不必再从源服务器那里获取。这样就降低了客户端的等待时间,同时节约了源服务器的网络带宽。
控制字段
缓存代理同样适用于cache-control的缓存控制策略。
常用的有“private”“s-maxage”“no-transform”等,同样必须配合“Last-modified”“ETag”等字段才能使用;
Cache-control新增字段:private、public、proxy-revalidate(代理专用)、s-maxage(代理专用)、no-transform(代理专用)
区分客户端上的缓存和代理上的缓存,可以使用两个新属性“private”和“public”。“private”表示缓存只能在客户端保存,是用户“私有”的,不能放在代理上与别人共享。而“public”的意思就是缓存完全开放,谁都可以存,谁都可以用。
缓存失效后的重新验证也要区分开,“must-revalidate”是只要过期就必须回源服务器验证,而新的“proxy-revalidate”只要求代理的缓存过期后必须验证,客户端不必回源,只验证到代理这个环节就行了。
缓存的生存时间可以使用新的“s-maxage”(s 是 share 的意思,注意 maxage 中间没有“-”),只限定在代理上能够存多久,而客户端仍然使用“max-age”。
还有一个代理专用的属性“no-transform”。代理有时候会对缓存下来的数据做一些优化,比如把图片生成 png、webp 等几种格式,方便今后的请求处理,而“no-transform”就会禁止这样做,不许“偷偷摸摸搞小动作”。

什么是CDN
CDN(Content Delivery Network 或 Content Distribution Network),中文名叫“内容分发网络”。
HTTP缓存服务器可以做到缓存、转发,连接客户端和服务器,但是CDN可以做到的更多,它是一个 外部加速 HTTP 协议的服务 。
在地理距离远、存在传输延迟损耗、运营商网络各不相同的真实互联网网络环境里,http的路由转发成本也会成倍增加(数据每经过一个节点,都要停顿一下,在二层、三层解析转发,这也会消耗一定的时间,带来延迟),极大地拖慢了访问速度,这是用户比较难以接受的。
CDN就是用于改善目前的HTTP传输方式,它是专门为解决“长距离”上网络访问速度慢而诞生的一种网络应用服务。
CDN 的最核心原则是“就近访问”,如果用户能够在本地几十公里的距离之内获取到数据,那么时延就基本上变成 0 了。
所以 CDN 投入了大笔资金,在全国、乃至全球的各个大枢纽城市都建立了机房,部署了大量拥有高存储高带宽的节点,构建了一个专用网络。这个网络是跨运营商、跨地域的,虽然内部也划分成多个小网络,但它们之间用高速专有线路连接,是真正的“信息高速公路”,基本上可以认为不存在网络拥堵。
有了这个高速的专用网之后,CDN 就要“分发”源站的“内容”了,用到的就是“缓存代理”技术。使用“推”或者“拉”的手段,把源站的内容逐级缓存到网络的每一个节点上。
于是,用户在上网的时候就不直接访问源站,而是访问离他“最近的”一个 CDN 节点,术语叫“边缘节点”(edge node),其实就是缓存了源站内容的代理服务器,这样一来就省去了“长途跋涉”的时间成本,实现了“网络加速”。
套用一句广告词来形容 CDN 吧,我觉得非常恰当:“我们不生产内容,我们只是内容的搬运工。”
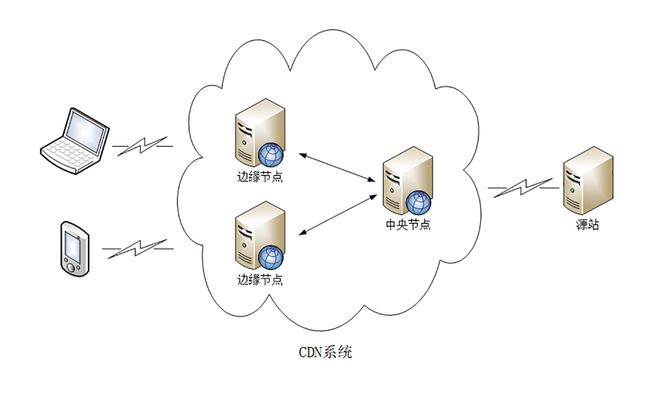
CDN的负载均衡
它有两个关键组成部分:全局负载均衡和缓存系统,对应的是 DNS和缓存代理技术。
- 由于客观地理距离的存在,直连网站访问速度会很慢,所以就出现了 CDN;
- CDN 构建了全国、全球级别的专网,让用户就近访问专网里的边缘节点,降低了传输延迟,实现了网站加速;
- GSLB 是 CDN 的“大脑”,使用 DNS 负载均衡技术,智能调度边缘节点提供服务;
- 缓存系统是 CDN 的“心脏”,使用 HTTP 缓存代理技术,缓存命中就返回给用户,否则就要回源。
全局负载均衡(Global Sever Load Balance)简称 GSLB.
它是 CDN 的“大脑”,主要的职责是当用户接入网络的时候在 CDN 专网中挑选出一个“最佳”节点提供服务,解决的是用户如何找到“最近的”边缘节点,对整个 CDN 网络进行“负载均衡”。
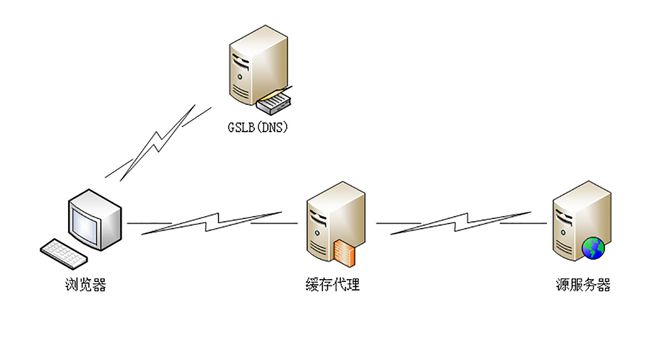
原来没有 CDN 的时候,权威 DNS 返回的是网站自己服务器的实际 IP 地址,浏览器收到 DNS 解析结果后直连网站。
但加入 CDN 后就不一样了,权威 DNS 返回的不是 IP 地址,而是一个 CNAME( Canonical Name ) 别名记录,指向的就是 CDN 的GSLB。
于是本地 DNS 就会向 GSLB 再发起请求,这样就进入了 CDN 的全局负载均衡系统,开始“智能调度”,主要的依据有这么几个:\
- 看用户的 IP 地址,查表得知地理位置,找相对最近的边缘节点;
- 看用户所在的运营商网络,找相同网络的边缘节点;
- 检查边缘节点的负载情况,找负载较轻的节点;
- 其他,比如节点的“健康状况”、服务能力、带宽、响应时间等。
GSLB 把这些因素综合起来,用一个复杂的算法,最后找出一台“最合适”的边缘节点,把这个节点的 IP 地址返回给用户,用户就可以“就近”访问 CDN 的缓存代理了。
CDN的缓存代理
基本上大部分就是HTTP缓存代理的技术
CDN缓存的内容往往是静态资源(设置了cache-control的文件都算一种静态资源)
CDN有两个相关的关键概念:“命中”和“回源”。
“命中”就是指用户访问的资源恰好在缓存系统里,可以直接返回给用户;“回源”则正相反,缓存里没有,必须用代理的方式回源站取。
相应地,也就有了两个衡量 CDN 服务质量的指标:“命中率”和“回源率”。
命中率就是命中次数与所有访问次数之比,回源率是回源次数与所有访问次数之比。显然,好的 CDN 应该是命中率越高越好,回源率越低越好。现在的商业 CDN 命中率都在 90% 以上,相当于把源站的服务能力放大了 10 倍以上。
优化命中率和回源率也有一些常用办法:
- 增大存储系统。
- 缓存系统可以划分层次,分成一级缓存节点和二级缓存节点。一级缓存配置高一些,直连源站,二级缓存配置低一些,直连用户。回源的时候二级缓存只找一级缓存,一级缓存没有才回源站,这样最终“扇入度”就缩小了,可以有效地减少真正的回源。
- 采用高性能的缓存服务,目前最常用的是专门的缓存代理软件 Squid、Varnish,还有新兴的 ATS(Apache Traffic Server),而 Nginx 和 OpenResty 作为 Web 服务器领域的“多面手”,凭借着强大的反向代理能力和模块化、易于扩展的优点,也在 CDN 里占据了不少的份额。
CDN的安全管理
WAF 安全防护
对于一些无法缓存的动态资源,CDN存在加速效果吗?
cdn一般都有专用的高速网络直连源站,或者是动态路径优化,因此动态资源回源也要比通过公网速度快很多。
线上相关问题记录
- 配置了CDN但是每次仍然没有命中
参考:
CDN缓存命中率较低排查方法
请求CDN加速资源时无法命中CDN缓存
URL的传递参数为变量导致CDN缓存命中率低
CDN回源罪魁祸首
排查了原因是因为引入js文件的时候,有一个第三方资源每次都会自动在URL后面加时间戳,导致明明下载的同一个js文件,却命中不了,因为是第三方资源导致的问题,我们没法取消时间戳,后续改成项目内部直接引入,其实也可以改成CDN忽略传递参数。