MySQL的索引
一:介绍
索引是通过某种算法,构建出一个数据模型,用于快速找出在某个列中有一特定值的行,不使用索引,MySQL必须从第一条记录开始读完整个表,直到找出相关的行,表越大,查询数据所花费的时间就越多,如果表中查询的列有一个索引,MySQL能快速到达一个位置去搜索数据文件,而不必查看所有数据,那么将节省很大一部分时间。
索引类似一本书的目录,比如要查找student这个单词,可以先找到s开头的页然后向后查找,这个就类似索引。
二:分类
索引是存储引擎用来快速查找记录的一种数据结构,按照现实的方式类分,主要有Hash索引和B+Tree索引



三:单列索引
:一个索引只包含单个列,但一个表中可以有多个单列索引
(1)普通索引
MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,存粹为了查询数据更快一点
<1>创建索引
-- 方式一:创建表的时候直接指定
create table student(
sid int primary key,
card_id varchar(20),
name varchar(20),
gender varchar(20),
age int,
birth date,
phone_num varchar(20),
score double,
index index_name(name)-- 给name列创建索引
);
select * from student where name = '张三';-- 会用索引的方式查找
-- 方式二:直接创建
create index index_gender on student(gender);-- index_gender 是索引的名字
-- 方式三:修改表结构(添加索引)
alter table student add index index_age(age);<2>查看索引



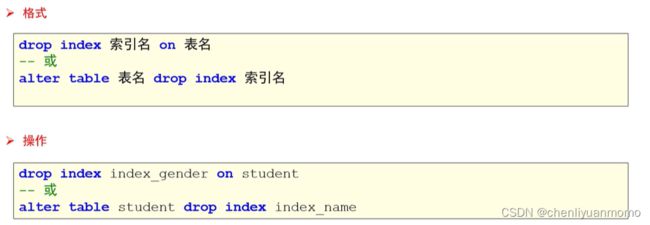
<3>删除索引
(2)唯一索引
唯一索引与前面的普通索引类似,不同的就是:索引创建的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
<1>创建索引
-- 方式一:创建表的时候直接指定
create table student2(
sid int primary key,
card_id varchar(20),
name varchar(20),
gender varchar(20),
age int,
birth date,
phone_num varchar(20),
score double,
unique index_card_id(card_id)-- 给card_id列创建索引
);
-- 方式二:直接创建
create unique index index_card_id on student2(card_id);-- index_gender 是索引的名字
-- 方式三:修改表结构(添加索引)
alter table student2 add unique index_phone_num(phone_num);
<2>删除索引

(3)主键索引
每张表一般都会有自己的主键,当我们在创建表时,MySQL会自动在主键列上建立一个索引,这就是主键索引。主键是具有唯一性并且不允许为NULL,所以它是一种特殊的唯一索引。
(查询时才可以看到)
四:组合索引

-- 组合索引
-- 普通索引
create index index_phone_name on student(phone_num,name);
-- 删除索引
drop index index_phone_num on student;
-- 唯一索引
create unique index index_phone_name on student(phone_num,name);
五:全文索引
(1)概述



(2)操作




六:空间索引



七:内部原理
(1)概述
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上;
这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的就是在查找过程中磁盘I/O操作次数的渐进复杂度;
换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数;
(2)相关算法
<1>hash算法

<2>二叉树
 也无法进行范围查找
也无法进行范围查找
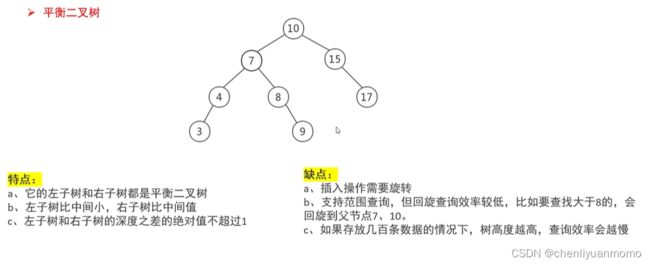
<3>平衡二叉树
<4>btree树(相关引擎使用)



八:索引的特点
(1)优点
大大加快数据的查询速度;
使用分组和排序进行数据查询时,可以显著减少查询时分组和排序的时间;
创建唯一索引,能够保证数据库中每一行数据的唯一性;
在实现数据的参考完整性方面,可以加快表和表之间的连接;
(2)缺点
创建索引和维护索引需要消耗时间,并且随着数据量的增加,时间也会增加;
索引需要占据磁盘空间;
对数据表中的数据进行增加,修改,删除时,索引也要动态地维护,降低了维护的速度;
九:索引的使用原则
