六、状态编程与容错机制
1、状态介绍
(1)分类
流式计算分为无状态和有状态
无状态流针对每个独立事件输出结果,有状态流需要维护一个状态,并基于多个事件输出结果(当前事件+当前状态值)

(2)有状态计算举例
窗口
复杂事件处理:一分钟出现两次
流与other的关联操作
2、有状态的算子
数据源source,数据存储sink都是有状态的
状态与算子相关联,有两种类型的状态:算子状态和键控状态
(1)算子状态(operator state)
为算子状态提供三种基本数据结构:列表状态(List state)、联合列表状态(Union list state)、广播状态(Broadcast state)
(2)键控状态(keyed state)
根据输入数据流中的键(key)来维护和访问,相同的key访问相同的状态
State支持的数据类型:单个值、列表值、map值、AggregatingState、ReducingState
2、状态一致性
(1)含义
成功处理故障并恢复之后得到的结果,与不产生故障的结果是否一致
(2)流处理器内部的一致性级别
主要包括at-most-once(计数结果可能丢失,无正确性保障)、at-least-once(计数结果可能大于但不会小于,可能会重复)、exactly-once(计数结果准确-依赖于检查点)
第一代流处理器Storm只保证at-least-once
Flink既保证了exactly-once,也具有低延迟和高吞吐的处理能力。
(3)流处理器之间的端到端状态一致性
结果的正确性贯穿了整个流处理应用的始终,各组件具有自身一致性;系统级别取决于所有组件中一致性最弱的组件
整个应用的一致性级别可以划分为:
内部保证(检查点)
source(可以重设数据读取位置)
sink(故障恢复时,数据不会重复写入,实现方式包含幂等写入、事务写入)
幂等写入:可执行多次,重复执行不起作用(例如转账500元)
事务写入:构建事务进行写入,checkpoint完成,才会将结果写入,事务性写入,具体又有两种实现方式:预写日志(WAL,GenericWriteAheadSink模板类)和两阶段提交(2PC,TwoPhaseCommitSinkFunction接口)
3、检查点(checkpoint)
(1)含义
重新计数的参考点
使用检查点保证exactly-once(计数结果准确),出现故障时将系统重置回正确状态
(2)实现
记录(字符串,数值),分别表示分组字符串(状态)和位置/偏移量
遇到检查点分界线(barrier)时,将输入流的位置异步持久化存储,从而可以从此位置重启
检查点失败,则会丢弃检查点并继续执行
4、数据管道实现精确语义
(1)组成
Flink + Kafka的数据管道系统(Kafka进、Kafka出)

(2)实现
内部:利用checkpoint机制,把状态存盘
source:kafka consumer作为source,可以将偏移量保存下来,故障恢复可以重置偏移量
sink:采用两阶段提交 sink,需要实现TwoPhaseCommitSinkFunction(预提交,jobmanager ack后正式提交)
5、状态后端选择
(1)分类
MemoryStateBackend:将键控状态作为内存中的对象进行管理,状态存在JVM堆上,检查点存在jobmanager内存中
FsStateBackend:检查点存在存到远程的持久化文件系统(FileSystem)上
RocksDBStateBackend:所有状态序列化后,存入本地的RocksDB中存储
RocksDB需要引入对应的依赖
(2)使用不同的状态后端
| val env = StreamExecutionEnvironment.getExecutionEnvironment val checkpointPath: String = ??? val backend = new RocksDBStateBackend(<strong>checkpointPathstrong>) env.setStateBackend(backend) env.setStateBackend(new FsStateBackend("file:///tmp/checkpoints")) env.enableCheckpointing(1000) // 配置重启策略 env.setRestartStrategy(RestartStrategies.fixedDelayRestart(60, Time.of(10, TimeUnit.SECONDS))) |
七、TableAPI与SQL
1、介绍
(1)介绍
Table API是流处理和批处理通用的关系型API,实现了流处理和批处理的统一
Table API和SQL是Flink中封装程度最高的API,但并不支持所有算子
(2)实现功能
内部目录catalog中注册表
注册外部catalog
执行SQL查询
注册用户定义(标量,表或聚合)函数
将DataStream或DataSet转换为表
持有对ExecutionEnvironment或StreamExecutionEnvironment的引用
2、Table API过程
(1)引入pom依赖
flink-table_2.11
(2)构造表环境
| def main(args: Array[String]): Unit = { val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val myKafkaConsumer: FlinkKafkaConsumer011[String] = MyKafkaUtil.getConsumer("GMALL_STARTUP") val dstream: DataStream[String] = env.addSource(myKafkaConsumer) val tableEnv: StreamTableEnvironment = TableEnvironment.getTableEnvironment(env) val startupLogDstream: DataStream[StartupLog] = dstream.map{ jsonString =>JSON.parseObject(jsonString,classOf[StartupLog]) } val startupLogTable: Table = tableEnv.fromDataStream(startupLogDstream) val table: Table = startupLogTable.select("mid,ch").filter("ch ='appstore'") val midchDataStream: DataStream[(String, String)] = table.toAppendStream[(String,String)] midchDataStream.print() env.execute() } |
(3)动态表
根据样例类生成table:tableEnv.fromDataStream(startupLogDstream)
对流根据字段命名:tableEnv.fromDataStream(startupLogDstream,’mid,’uid .......) -单引号标识
动态表按流输出:table.toAppendStream[(String,String)]
3、窗口聚合操作
(1)例子:统计每10秒中每个传感器温度值的个数
| StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); env.setParallelism(1); DataStreamSource<String> inputData = env.readTextFile("F:\\workspace\\flinkjavademo\\src\\main\\resources\\Sensor.txt"); DataStream<Sensor> dataStream = inputData.flatMap(new MySpliter()) .assignTimestampsAndWatermarks(new WatermarkStrategy<Sensor>() { @Override public WatermarkGenerator<Sensor> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) { return new WatermarkGenerator<Sensor>() { private long maxTimestamp; private long delay = 3000; //以“timeStamp”字段为event-time时间戳开启了一个时间跨度为10秒,水位线为3秒的滚动窗口 @Override public void onEvent(Sensor sensor, long l, WatermarkOutput watermarkOutput) { maxTimestamp = Math.max(sensor.getTimeStamp(),l); } @Override public void onPeriodicEmit(WatermarkOutput output) { output.emitWatermark(new Watermark(maxTimestamp-delay)); } }; } }); EnvironmentSettings envSetting = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build(); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, envSetting); Table table = tableEnv.fromDataStream(dataStream,$("id"),$("timeStamp").rowtime(),$("temperature")); Table filterTable = table.window(Tumble.over(lit(10).seconds()).on($("timeStamp")).as("tw")) .groupBy($("id"),$("tw")) .select($("id"),$("id").count().as("count")); DataStream<Tuple2<Boolean, Row>> sensorDataStream = tableEnv.toRetractStream(filterTable, Row.class); sensorDataStream.print(); env.execute("table test"); |
(2)group by
Group table转换为流:table.toRetractStream[(String,Long)]
api包括时间窗口,窗口的字段必须出现在groupBy中。
| val resultTable: Table = dataTable .window( Tumble over 10.seconds on 'ts as 'tw ) .groupBy('id, 'tw) .select('id, 'id.count) |
(3)时间窗口
提前声明时间字段,如果是processTime直接在创建动态表时进行追加
| val dataTable: Table = tableEnv.fromDataStream(dataStream, 'id, 'temperature, 'ps.proctime) |
使用Tumble over 10000.millis on 来表示滚动窗口
使用Tumble over 10.seconds on 'ts as 'tw表示滑动窗口
4、SQL编写
| EnvironmentSettings envSetting = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build(); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, envSetting); //使用流创建表 Table table = tableEnv.fromDataStream(dataStream,$("id"),$("ts").rowtime(),$("temperature")); //编写SQL完成开窗统计 Table filterTable = tableEnv.sqlQuery("select id,count(id) num from " + table + " group by id,tumble(ts, interval '10' second)"); DataStream<Tuple2<Boolean, Row>> sensorDataStream = tableEnv.toRetractStream(filterTable, Row.class); sensorDataStream.print(); env.execute("table test"); |
八、Flink CEP
1、介绍
Complex Event Processing,复杂事件处理
一个或多个简单事件构成的复杂事件流,得到满足规则的复杂事件。
2、Flink CEP library
Flink有专门的library支持
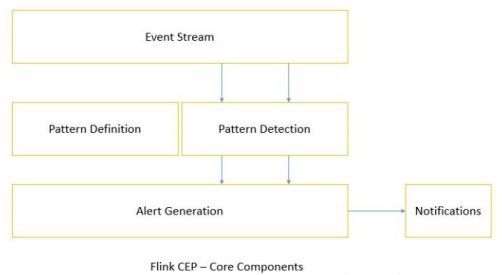
3、使用
在DataStream流上定义出模式条件,之后Flink CEP引擎进行模式检测,必要时生成告警
例子:登录检测