【Yolo】YoloV5训练自定义模型
【Yolo】Jetson Orin Nano下部署 YoloV5
上一篇博文主要记录了在Jetson Orin Nano下部署YoloV5环境,并运行了yoloV5n.pt模型,本篇在上一篇的基础上,进一步记录如何训练自己的目标模型,我们以一根口香糖盒子为训练对象进行说明。
一、目标资源标记
1. 安装labelimg
通过以下命令安装labelimg软件,labelimg用于在待训练的图片上进行目标标记。可以在windows和ubuntu下安装和使用,本文为了方便在Window10下安装,标记完再把生成的文件拷贝到Jetson Orin Nano下进行训练,因为我的Win10电脑没有显卡而Jetson Orin Nano的显卡非常牛逼。
pip install labelimg安装完毕后,即可通过labelimg命令直接启动它,长这个样子。
2. 准备素材
2.1 建立目录
新建一个文件夹用来存放训练资源,我们暂且将它命名为“CustomDataset”,在里面再按以下目录结构建立空文件夹:
Parent
├── CustomDataset
└── images
└──train
└──val
└── labels
└──train
└──val
2.2 准备图片
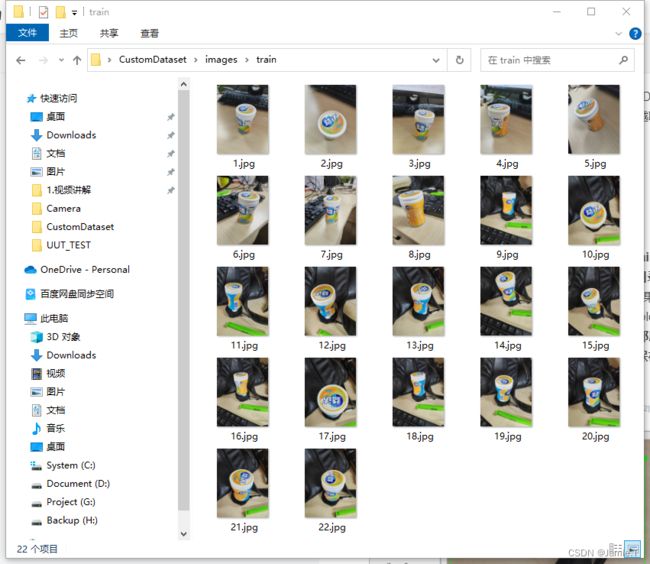
多拍点待测物照片,放到一个文件夹CustomDataset/images/train里,这里拍了22张口香糖盒子的照片,从各个角度拍的照片越多,训练结果也就越聪明,后期识别就越精准。
2.3 labimg标记资源
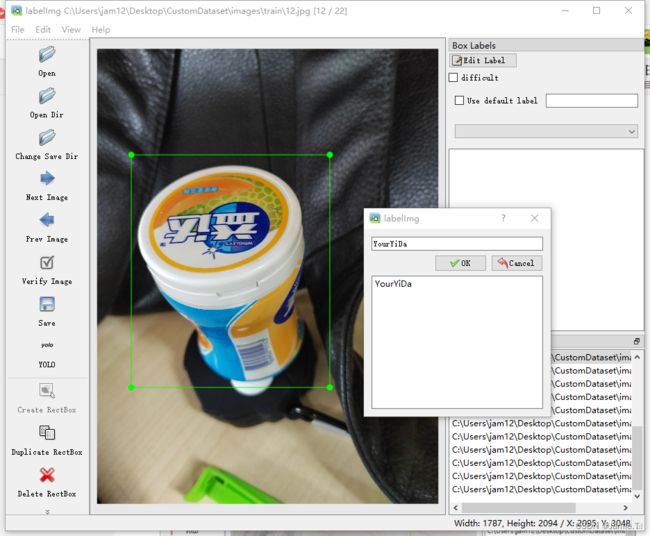
通过Open Dir指定CustomDataset/images/train,载入所有图片,通过Change Save Dir指定CustomDataset/labels/train为标记文件的生成目录,在下图红色1的位置单击按钮切换到YOLO格式,它将来会生成*.txt格式的标记文件,如果是默认的VOC,它将生成*.xml格式的标记文件,虽然可以转换成*.txt,但我们为了方便直接选yolo格式。单击Create RectBox按钮然后框选目标,并输入一个类型名,后面每个图片的标记,就都用这同一个类型名,我这里是“YourYiDa”。后面依次把每个图片都要进行同样的标记,记得Ctrl+S保存。
2.4 拷贝资源
现在将CustomDataset/images/train里面的所有图片拷贝一份到val文件夹下,同样的把CustomDataset/labels/train里面的所有*.txt文件拷贝一份到val文件夹。然后把整个CustomDataset文件夹复制到Jetson Orin Nano下,为了跟yolov5源码隔离开,我将它跟yolov5的代码放到同一级目录(yolov5的克隆,见上一篇第五节内容)。

3.修改配置
进入yolov5/data目录下,新建一个YourYiDa_data.yaml文件,名字可以自定义,取一个跟项目相关的名字就好,然后把以下内容贴进去,其中train目录为刚才拷贝进来的CustomDataset/images/train和val的实际路径。nc表示只识别目标物体种类,如果是多个也可以按实际个数去写,但下面names的类型名集合,就要跟nc个数保持一致,采用"names : ["YourYiDa", "Person", "Apple"]"这样的形式。这里为了方便记录,只识别一种。
#train and val data
train : ../../CustomDataset/images/train
val : ../../CustomDataset/images/val
#number of classes
nc : 1
#class names
names : ["YourYiDa"]进入yolov5/models目录下,将yolov5/models目录下的yolov5n.yaml复制一个,重命名为YourYiDa_model.yaml,并将其中的 nc节改为跟上面配置文件一致,本文是nc=1
4. 训练
进入yolov5目录下,执行以下命令:
python train.py --data ./data/YourYiDa_data.yaml --cfg ./models/YourYiDa_model.yaml --weight ./yolov5n.pt --epoch 100 --batch 16 --device 0 如果失败,请检查路径是否正确,另外资源被占用,内存不够也可能导致失败,可以关闭其他程序多试几次。正常训练如下图所示。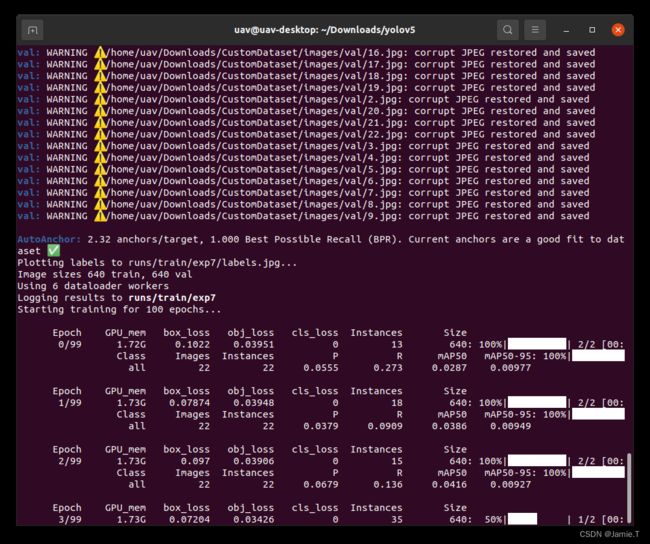
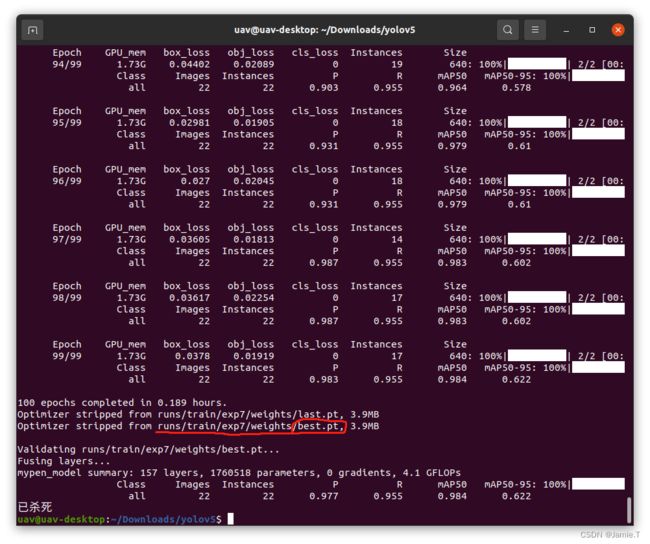
训练成功后会输出best.pt权重文件,路径如下图,即在yolov5文件夹下的runs/train/exp7/weights目录下。
如果此时Jetson Orin Nano上插着一个usb摄像头,通过 ls /dev/video* 命令可知,CSI摄像头设备号为0,而USB摄像头的设备号为1。那么就可以直接测试训练效果,命令如下:其中source 1表示USB摄像头。
python detect.py --source 1 --weights ./runs/train/exp7/weights/best.pt --img 640
5. 用DeepStream运行
以上是采用USB摄像头执行yolov5自带的detect.py程序,根据上一篇文章,要想调用Jetson Orin Nano的CSI_Camera摄像头执行目标检测,就需要用DeepStream来调用yolov5。既然上一步生成了best.pt文件,那么下面就说说如何使用DeepStream来调用yolov5,过程跟上一篇文章的第七节过程类似,我们假定在上一篇环境已经搭建好的基础上来讲述下面操作。
5.2 准备工作
将上一步生成的best.pt文件复制到yolov5文件夹下,为便于区分,将其重命名为YiDaBest.pt。
5.2 模型转换
进入到yolov5文件夹下,执行如下代码,会生成YiDaBest.cfg,YiDaBest.wts文件,将这两个文件拷贝到Deepstream-Yolo文件夹。
python gen_wts_yoloV5.py -w ./YiDaBest.pt
sudo cp YiDaBest.cfg /opt/nvidia/deepstream/deepstream-6.2/sources/DeepStream-Yolo
sudo cp YiDaBest.wts /opt/nvidia/deepstream/deepstream-6.2/sources/DeepStream-Yolo将生成的YiDaBest.cf
5.3 修改deepstream配置
修改config_infer_primary_yoloV5.txt 文件的一下变量
custom-network-config=YiDaBest.cfg
model-file=YiDaBest.wts5.4 运行DeepStream实例
deepstream-app -c deepstream_app_config.txt