「数据处理」pandas.concat() 合并数据集
concat()
The concat() function concatenates an arbitrary amount of Series or DataFrame objects along an axis while performing optional set logic (union or intersection) of the indexes on the other axes. Like numpy.concatenate, concat() takes a list or dict of homogeneously-typed objects and concatenates them.
df1 = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3],
)
df2 = pd.DataFrame(
{
"A": ["A4", "A5", "A6", "A7"],
"B": ["B4", "B5", "B6", "B7"],
"C": ["C4", "C5", "C6", "C7"],
"D": ["D4", "D5", "D6", "D7"],
},
index=[4, 5, 6, 7],
)
df3 = pd.DataFrame(
{
"A": ["A8", "A9", "A10", "A11"],
"B": ["B8", "B9", "B10", "B11"],
"C": ["C8", "C9", "C10", "C11"],
"D": ["D8", "D9", "D10", "D11"],
},
index=[8, 9, 10, 11],
)
frames = [df1, df2, df3]
result = pd.concat(frames)
result
Out[6]:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11

Note
concat() makes a full copy of the data, and iteratively reusing concat() can create unnecessary copies. Collect all DataFrame or Series objects in a list before usingconcat().
frames = [process_your_file(f) for f in files] result = pd.concat(frames)
Note
When concatenating DataFrame with named axes, pandas will attempt to preserve these index/column names whenever possible. In the case where all inputs share a common name, this name will be assigned to the result. When the input names do not all agree, the result will be unnamed. The same is true for MultiIndex, but the logic is applied separately on a level-by-level basis.
Joining logic of the resulting axis
The join keyword specifies how to handle axis values that don’t exist in the first DataFrame.
join='outer' takes the union of all axis values
df4 = pd.DataFrame(
{
"B": ["B2", "B3", "B6", "B7"],
"D": ["D2", "D3", "D6", "D7"],
"F": ["F2", "F3", "F6", "F7"],
},
index=[2, 3, 6, 7],
)
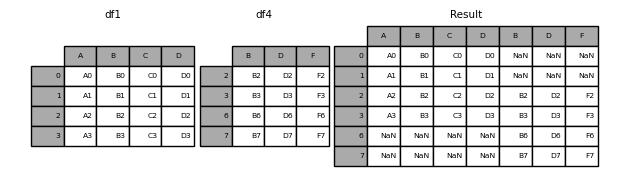
result = pd.concat([df1, df4], axis=1)
result
Out[9]:
A B C D B D F
0 A0 B0 C0 D0 NaN NaN NaN
1 A1 B1 C1 D1 NaN NaN NaN
2 A2 B2 C2 D2 B2 D2 F2
3 A3 B3 C3 D3 B3 D3 F3
6 NaN NaN NaN NaN B6 D6 F6
7 NaN NaN NaN NaN B7 D7 F7
join='inner' takes the intersection of the axis values
result = pd.concat([df1, df4], axis=1, join="inner")
result
Out[11]:
A B C D B D F
2 A2 B2 C2 D2 B2 D2 F2
3 A3 B3 C3 D3 B3 D3 F3

To perform an effective “left” join using the exact index from the original DataFrame, result can be reindexed.
result = pd.concat([df1, df4], axis=1).reindex(df1.index)
result
Out[13]:
A B C D B D F
0 A0 B0 C0 D0 NaN NaN NaN
1 A1 B1 C1 D1 NaN NaN NaN
2 A2 B2 C2 D2 B2 D2 F2
3 A3 B3 C3 D3 B3 D3 F3

Ignoring indexes on the concatenation axis
For DataFrame objects which don’t have a meaningful index, the ignore_index ignores overlapping indexes.
result = pd.concat([df1, df4], ignore_index=True, sort=False)
result
Out[15]:
A B C D F
0 A0 B0 C0 D0 NaN
1 A1 B1 C1 D1 NaN
2 A2 B2 C2 D2 NaN
3 A3 B3 C3 D3 NaN
4 NaN B2 NaN D2 F2
5 NaN B3 NaN D3 F3
6 NaN B6 NaN D6 F6
7 NaN B7 NaN D7 F7

Concatenating Series and DataFrame together
You can concatenate a mix of Series and DataFrame objects. The Series will be transformed to DataFrame with the column name as the name of the Series.
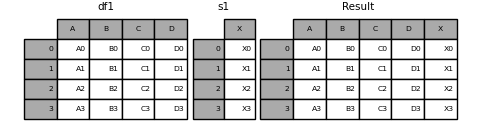
s1 = pd.Series(["X0", "X1", "X2", "X3"], name="X")
result = pd.concat([df1, s1], axis=1)
result
Out[18]:
A B C D X
0 A0 B0 C0 D0 X0
1 A1 B1 C1 D1 X1
2 A2 B2 C2 D2 X2
3 A3 B3 C3 D3 X3
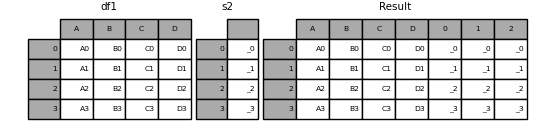
Unnamed Series will be numbered consecutively.
s2 = pd.Series(["_0", "_1", "_2", "_3"])
result = pd.concat([df1, s2, s2, s2], axis=1)
result
Out[21]:
A B C D 0 1 2
0 A0 B0 C0 D0 _0 _0 _0
1 A1 B1 C1 D1 _1 _1 _1
2 A2 B2 C2 D2 _2 _2 _2
3 A3 B3 C3 D3 _3 _3 _3
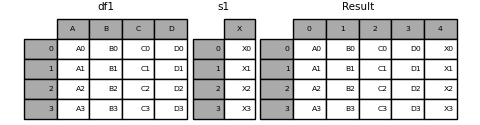
ignore_index=True will drop all name references.
result = pd.concat([df1, s1], axis=1, ignore_index=True)
result
Out[23]:
0 1 2 3 4
0 A0 B0 C0 D0 X0
1 A1 B1 C1 D1 X1
2 A2 B2 C2 D2 X2
3 A3 B3 C3 D3 X3
Resulting keys#
The keys argument adds another axis level to the resulting index or column (creating a MultiIndex) associate specific keys with each original DataFrame.
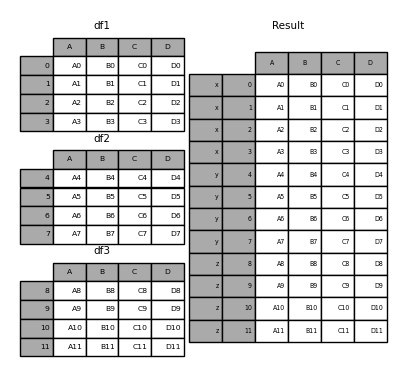
result = pd.concat(frames, keys=["x", "y", "z"])
result
Out[25]:
A B C D
x 0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
y 4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
z 8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11
result.loc["y"]
Out[26]:
A B C D
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
The keys argument cane override the column names when creating a new DataFrame based on existing Series.
s3 = pd.Series([0, 1, 2, 3], name="foo") s4 = pd.Series([0, 1, 2, 3]) s5 = pd.Series([0, 1, 4, 5]) pd.concat([s3, s4, s5], axis=1) Out[30]: foo 0 1 0 0 0 0 1 1 1 1 2 2 2 4 3 3 3 5 pd.concat([s3, s4, s5], axis=1, keys=["red", "blue", "yellow"]) Out[31]: red blue yellow 0 0 0 0 1 1 1 1 2 2 2 4 3 3 3 5
You can also pass a dict to concat() in which case the dict keys will be used for the keysargument unless other keys argument is specified:
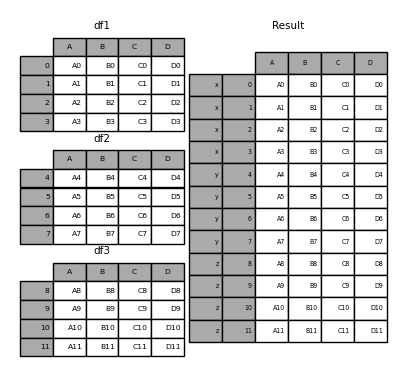
pieces = {"x": df1, "y": df2, "z": df3}
result = pd.concat(pieces)
result
Out[34]:
A B C D
x 0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
y 4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
z 8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11

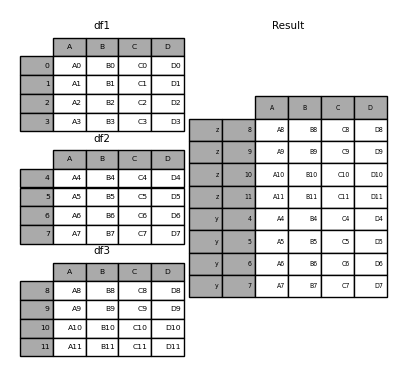
result = pd.concat(pieces, keys=["z", "y"])
result
Out[36]:
A B C D
z 8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11
y 4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
The MultiIndex created has levels that are constructed from the passed keys and the index of the DataFrame pieces:
result.index.levels Out[37]: FrozenList([['z', 'y'], [4, 5, 6, 7, 8, 9, 10, 11]])
levels argument allows specifying resulting levels associated with the keys
result = pd.concat(
pieces, keys=["x", "y", "z"], levels=[["z", "y", "x", "w"]], names=["group_key"]
)
result
Out[39]:
A B C D
group_key
x 0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
y 4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
z 8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11
result.index.levels Out[40]: FrozenList([['z', 'y', 'x', 'w'], [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]])
Appending rows to a DataFrame
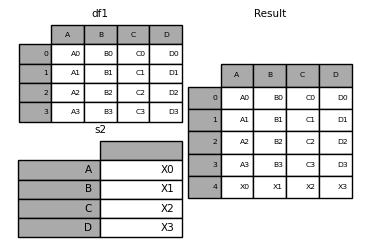
If you have a Series that you want to append as a single row to a DataFrame, you can convert the row into a DataFrame and use concat()
s2 = pd.Series(["X0", "X1", "X2", "X3"], index=["A", "B", "C", "D"])
result = pd.concat([df1, s2.to_frame().T], ignore_index=True)
result
Out[43]:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 X0 X1 X2 X3
更多函数见https://pandas.pydata.org/pandas-docs/stable/user_guide/merging.html