关于二手房python数据分析及其可视化
python对杭州二手房数据分析
该数据集来自网络公开数据,python语言,在数据分析方面,作为一柄利器,涵盖了“数据获取→数据处理→数据分析→数据可视化”这个流程中每个环节。
环境搭建:
环境:win10+Anaconda +jupyter Notebook
库:Numpy,pandas,matplotlib,seaborn ,missingno,各种包的管理和安装主要利用conda和pip。
数据集:杭州二手房信息样本
探索问题:
要探索的问题有: 1、二手房区域位置特点 2、总价等差间距中房数占比、总价在各区域中的平均值 3、单价等差间距房数占比、单价在各区域的平均值 4、看房时间可视化 6、关注度特点分析 7、楼层高低分析 8、户型结构分析 9、建筑类型 10、朝向分析 11、建筑结构 12、是否有电梯分析 13、用途分析 14、核心卖点词云分析
# 导入需要的数据库
import pandas as pd
import numpy as np
import seaborn as sns
sns.set()
import matplotlib.pyplot as plt
# 设置配置输出高清矢量图:
%config InlineBackend.figure_format = 'svg'
%matplotlib inline
# 使用pandas进行数据读入和分析:
house = pd.read_csv("C:/Users/EVILLIFES/Desktop/接单/Secondhand_house.csv",encoding='gbk')
# 输出主要信息:
house.info()
RangeIndex: 8121 entries, 0 to 8120 Data columns (total 45 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 序号 8121 non-null int64 1 小区名称 8121 non-null object 2 区域位置 8121 non-null object 3 经度 8121 non-null object 4 纬度 8121 non-null object 5 总价 8121 non-null object 6 单价 8121 non-null object 7 看房时间 8121 non-null object 8 链家编号 8121 non-null object 9 关注度 8121 non-null object 10 房屋户型 8119 non-null object 11 所在楼层 8121 non-null object 12 建筑面积 8121 non-null object 13 户型结构 7762 non-null object 14 套内面积 8119 non-null object 15 建筑类型 7762 non-null object 16 房屋朝向 8121 non-null object 17 建筑结构 8119 non-null object 18 装修情况 8119 non-null object 19 梯户比例 7762 non-null object 20 配备电梯 7762 non-null object 21 挂牌时间 8121 non-null object 22 交易权属 8121 non-null object 23 上次交易 8121 non-null object 24 房屋用途 8121 non-null object 25 房屋年限 8121 non-null object 26 产权所属 8121 non-null object 27 抵押信息 8121 non-null object 28 房本备件 8121 non-null object 29 房源核验统一编码 8121 non-null object 30 查询房管备案记录 7744 non-null object 31 核心卖点 7747 non-null object 32 小区介绍 5199 non-null object 33 周边配套 4958 non-null object 34 税费解析 821 non-null object 35 用水类型 1248 non-null object 36 用电类型 1248 non-null object 37 燃气价格 384 non-null object 38 户型介绍 2390 non-null object 39 适宜人群 1436 non-null object 40 装修描述 620 non-null object 41 售房详情 354 non-null object 42 交通出行 200 non-null object 43 别墅类型 358 non-null object 44 权属抵押 21 non-null object dtypes: int64(1), object(44) memory usage: 2.8+ MB
# 获得行数和列数 rows = len(house) columns = len(house.columns) print(rows,columns) # 输出列的数据类型 columns_type = house.dtypes columns_type
8121 45
序号 int64 小区名称 object 区域位置 object 经度 object 纬度 object 总价 object 单价 object 看房时间 object 链家编号 object 关注度 object 房屋户型 object 所在楼层 object 建筑面积 object 户型结构 object 套内面积 object 建筑类型 object 房屋朝向 object 建筑结构 object 装修情况 object 梯户比例 object 配备电梯 object 挂牌时间 object 交易权属 object 上次交易 object 房屋用途 object 房屋年限 object 产权所属 object 抵押信息 object 房本备件 object 房源核验统一编码 object 查询房管备案记录 object 核心卖点 object 小区介绍 object 周边配套 object 税费解析 object 用水类型 object 用电类型 object 燃气价格 object 户型介绍 object 适宜人群 object 装修描述 object 售房详情 object 交通出行 object 别墅类型 object 权属抵押 object dtype: object
# 为了显示中文 from pylab import mpl mpl.rcParams['font.sans-serif'] = [u'SimHei'] mpl.rcParams['axes.unicode_minus'] = False
# 通过上述info信息我们发现有数据的缺失值,在此我们统计一下缺失情况: missing_values = house.isnull().sum() print(missing_values) # 通过可视化展现为: import missingno as msno msno.matrix(house,figsize = (15,5), labels=True)
序号 0 小区名称 0 区域位置 0 经度 0 纬度 0 总价 0 单价 0 看房时间 0 链家编号 0 关注度 0 房屋户型 2 所在楼层 0 建筑面积 0 户型结构 359 套内面积 2 建筑类型 359 房屋朝向 0 建筑结构 2 装修情况 2 梯户比例 359 配备电梯 359 挂牌时间 0 交易权属 0 上次交易 0 房屋用途 0 房屋年限 0 产权所属 0 抵押信息 0 房本备件 0 房源核验统一编码 0 查询房管备案记录 377 核心卖点 374 小区介绍 2922 周边配套 3163 税费解析 7300 用水类型 6873 用电类型 6873 燃气价格 7737 户型介绍 5731 适宜人群 6685 装修描述 7501 售房详情 7767 交通出行 7921 别墅类型 7763 权属抵押 8100 dtype: int64

msno.bar(house,figsize = (15,5)) # 条形图显示

数据清洗:
这一步的数据处理,主要是我们在上一步骤中发现的数据集问题:缺失值问题。实际业务中,数据清洗,往往比这麻烦的多,是一项复杂且繁琐的工作(用过excel清洗数据的都知道~),在网上看到,有人说一个分析项目80%的时间都是在清洗数据数据,不无道理。清洗的目的有两个,第一是通过清洗让数据可用。第二是让数据变的更适合进行后续的分析工作。总的说来,一份“脏”数据要清晰,一份“干净”的数据也要清洗。
““脏”数据需要清洗,这是众所周知的。但“干净”的数据也要清洗?这听起来很让人疑惑,其实我个人觉得更准确的表达是,这属于特征工程中的特征构造,构造出我们需要的特征。利于下一步分析。
就拿数据分析钟我们常见的处理日期变量问题来说,有时需要我们在日期变量中,提取对应的星期数,构造为以星期的方式来表述日期,有时又需要我们在日期变量中,提取月份,构造为以月份的方式展现日期,又或者把连续型数值数据离散化,构造分类区间等等。这些处理方式,在ML中被叫做特征工程,但本质上就是数据清洗。
缺失值处理中,我们一般会删除缺失值。pandas模块中,提供了将包含NaN值的行删除的方法dropna(),但其实处理缺失值最好的思路是“用最接近的数据替换它”
对于数值型数据,可用该列的数据的均值或者中位数进行替换,对于分类型数据,可利用该列数据的出现频数最多的数据(众数)来填充。
实在处理不了的空值,可以暂时先放着,不必着急删除。因为在后续的情况可能会出现:后续运算可以跳过该空值进行。
通过对空值数据的分析我们发现:【房屋户型、户型结构、套内面积、建筑类型、建筑结构、装修情况、梯户比例、配备电梯、查询房管备案记录、核心卖点、小区介绍、周边配套、税费解析、用水类型、用电类型、燃气价格、户型介绍、适宜人群、装修描述、售房详情、交通出行、别墅类型、权属抵押】有却失值。
对于我们需要的数据有影响的有【户型结构(缺359)、建筑类型(缺359)、建筑结构(缺2)、配备电梯(缺359)、核心卖点(缺374)、别墅类型(缺7763)】。
我们发现在这些数据中,并没有像数值一样的列存在,所有,我们可以对缺失值跳过。
# 对总价和单价列进行数值类型转换: price = pd.to_numeric(house['总价'], errors='coerce',).fillna(0) unit_price = pd.to_numeric(house['单价'], errors='coerce',).fillna(0) print(price) print(unit_price)
0 930.0
1 765.0
2 225.0
3 148.0
4 130.0
...
8116 205.0
8117 570.0
8118 440.0
8119 242.0
8120 325.0
Name: 总价, Length: 8121, dtype: float64
0 69053.0
1 55423.0
2 34611.0
3 31835.0
4 26461.0
...
8116 30308.0
8117 36562.0
8118 48993.0
8119 32903.0
8120 44260.0
Name: 单价, Length: 8121, dtype: float64
# 总价分析: price.describe()
count 8121.000000 mean 429.089820 std 368.176619 min 0.000000 25% 210.000000 50% 320.000000 75% 545.000000 max 6500.000000 Name: 总价, dtype: float64
# 单价分析: unit_price.describe()
count 8121.000000 mean 40310.525305 std 18436.762039 min 0.000000 25% 26552.000000 50% 37487.000000 75% 48544.000000 max 128968.000000 Name: 单价, dtype: float64
# 对建筑结构一列的数据填补 # 首先查看当前占比 house['建筑结构'].value_counts()
钢混结构 5612 砖混结构 1015 混合结构 851 框架结构 478 钢结构 91 未知结构 44 砖木结构 27 建筑结构 1 Name: 建筑结构, dtype: int64
# 发现钢混结构占比最大,所以我们用钢混结构来补充缺失值
house.fillna({'建筑结构':'钢混结构'},inplace=True)
structure = house['建筑结构']
# 查看是否还存在缺失值
structure.isnull().sum()
0
对其他缺值的处理: pandas模块中,提供了将包含NaN值的行删除的方法dropna()
数据可视化
pandas.pivot_table函数中包含四个主要的变量,以及一些可选择使用的参数。四个主要的变量分别是数据源data,行索引index,列columns,和数值values。可选择使用的参数包括数值的汇总方式,NaN值的处理方式,以及是否显示汇总行数据等。
在可视化分析方面,会涉及到python常用的绘图库:matplotlib和seaborn,网上已经有非常多的使用指南,这里就不多说了,以后有时间,也会做一些总结。
# 手动区间划分
# 总价占比:
f1 = [0,0,0,0,0,0,0]
y1 = ['>6000','<=6000','<=5000','<=4000','<=3000','<=2000','<=1000']
for i in price:
if i<=1000.0:
f1[0]+=1
elif i<=2000.0:
f1[1]+=1
elif i<=3000.0:
f1[2]+=1
elif i<=4000.0:
f1[3]+=1
elif i<=5000.0:
f1[4]+=1
elif i<=6000.0:
f1[5]+=1
else:
f1[6]+=1
print(f1)
plt.figure(figsize = (10,5))
plt.subplot(121) # 第一个子图
plt.title("总价占比图")
plt.plot(y1,f1)
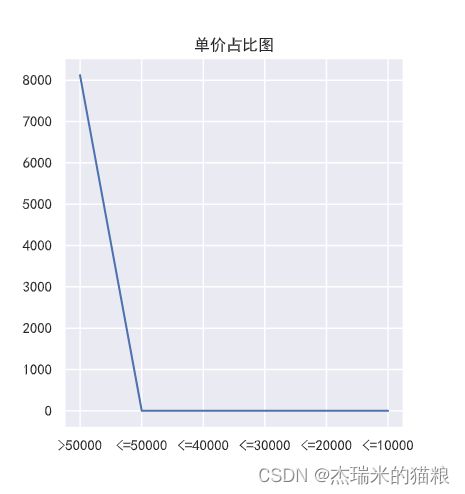
# 单价占比:
f2 = [0,0,0,0,0,0]
y2 = ['>50000','<=50000','<=40000','<=30000','<=20000','<=10000']
for i in price:
if i<=10000.0:
f2[0]+=1
elif i<=20000.0:
f2[1]+=1
elif i<=30000.0:
f2[2]+=1
elif i<=40000.0:
f2[3]+=1
elif i<=50000.0:
f2[4]+=1
else:
f2[5]+=1
print(f2)
plt.figure(figsize = (10,5))
plt.subplot(122) # 第一个子图
plt.title("单价占比图")
plt.plot(y2,f2)
[7691, 373, 44, 8, 3, 1, 1] [8121, 0, 0, 0, 0, 0]
[]

# 使用工具进行区间划分 house["总价分布"]=pd.cut(price,5)#将年龄列的数值划分为5等分 price_info = house["总价分布"].value_counts(sort=False)#查看每个分组有多少人数 price_info.plot(label='数量',title='对应区间划分内房屋数量',figsize=(11,5)) plt.show()

# 区域单价分析
f3 = house['区域位置'].value_counts(ascending=True)
print(f3)
plt.figure(figsize= (25 ,5))#创建画布
plt.xticks(rotation = 90) # 横坐标
plt.plot(f3, linewidth=3, marker='o',
markerfacecolor='blue', markersize=5)
plt.title('区域房数统计')
plt.show()
区域位置 1 富阳 1 拱墅-笕桥 22 拱墅-天水 24 拱墅-德胜东 24 拱墅-体育场路 28 拱墅-三里亭 33 拱墅-丝绸城 34 拱墅-和平 39 富阳-江南新城 42 拱墅-武林 43 拱墅-万达广场 50 拱墅-众安桥 57 拱墅-德胜 74 拱墅-潮鸣 85 拱墅-长庆 86 拱墅-三墩 87 富阳-富阳 91 富阳-鹿山新城 95 拱墅-和睦 111 拱墅-信义坊 118 拱墅-湖墅 128 滨江-白马湖 138 拱墅-大关 153 拱墅-桥西 160 拱墅-朝晖 169 拱墅-半山 181 拱墅-建国北路 186 拱墅-流水苑 187 拱墅-石桥 187 滨江-奥体 199 滨江-西兴 209 拱墅-申花 238 拱墅-拱宸桥 239 拱墅-三塘 257 滨江-长河 335 富阳-东洲 392 富阳-富春 513 滨江-浦沿 554 滨江-彩虹城 635 滨江-滨江区政府 930 富阳-银湖科技城 986 Name: 区域位置, dtype: int64

我们发现在滨江区单价普遍较高,而富阳-银湖科技城比较昂贵
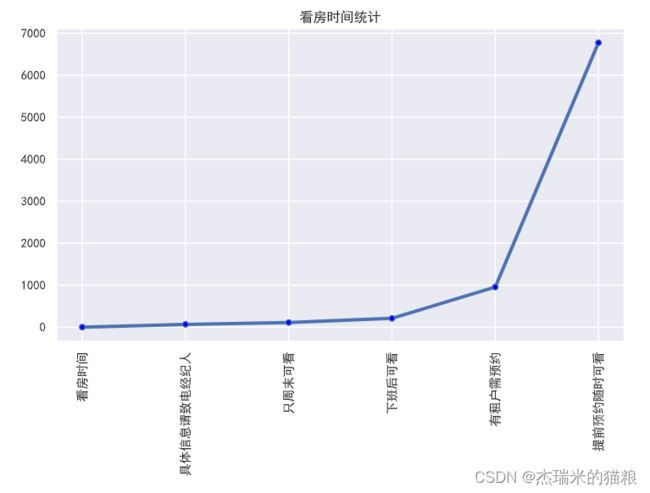
# 看房时间分析
f4 = house['看房时间'].value_counts(ascending=True)
print(f4)
plt.figure(figsize= (9 ,5))#创建画布
plt.xticks(rotation = 90) # 横坐标
plt.plot(f4, linewidth=3, marker='o',
markerfacecolor='blue', markersize=5)
plt.title('看房时间统计')
plt.show()
# 通过图表我们发现,看房的顾客大多都是通过提前预约然后随时观看这个选择来看的。
看房时间 1 具体信息请致电经纪人 68 只周末可看 111 下班后可看 210 有租户需预约 955 提前预约随时可看 6776 Name: 看房时间, dtype: int64
# 使用饼图查看 print(type(f4)) f4.plot.pie()

# 各区域关注度平均值:
house['关注度'] = pd.to_numeric(house['关注度'], errors='coerce',).fillna(0)
f5 = house.groupby('区域位置')['关注度'].mean().to_dict()
print(f5)
x = list(f5.keys())
y = list(f5.values())
plt.figure(figsize= (9 ,5))#创建画布
plt.xticks(rotation = 90) # 横坐标
plt.plot(x, y, linewidth=3, marker='o',markerfacecolor='blue', markersize=5)
plt.title('各区域关注度均值')
plt.show()
{'区域位置': 0.0, '富阳': 0.0, '富阳-东洲': 8.721938775510203, '富阳-富春': 3.9688109161793372, '富阳-富阳': 4.758241758241758, '富阳-江南新城': 7.071428571428571, '富阳-银湖科技城': 13.101419878296147, '富阳-鹿山新城': 2.1052631578947367, '拱墅-万达广场': 13.44, '拱墅-三塘': 19.972762645914397, '拱墅-三墩': 29.71264367816092, '拱墅-三里亭': 15.757575757575758, '拱墅-丝绸城': 17.61764705882353, '拱墅-众安桥': 16.42105263157895, '拱墅-体育场路': 21.821428571428573, '拱墅-信义坊': 18.347457627118644, '拱墅-半山': 19.41988950276243, '拱墅-和平': 21.128205128205128, '拱墅-和睦': 21.135135135135137, '拱墅-大关': 15.627450980392156, '拱墅-天水': 15.625, '拱墅-建国北路': 25.118279569892472, '拱墅-德胜': 30.5, '拱墅-德胜东': 38.541666666666664, '拱墅-拱宸桥': 27.476987447698743, '拱墅-朝晖': 17.644970414201183, '拱墅-桥西': 25.625, '拱墅-武林': 24.348837209302324, '拱墅-流水苑': 23.11764705882353, '拱墅-湖墅': 31.3203125, '拱墅-潮鸣': 24.658823529411766, '拱墅-申花': 25.449579831932773, '拱墅-石桥': 19.56149732620321, '拱墅-笕桥': 11.909090909090908, '拱墅-长庆': 15.883720930232558, '滨江-奥体': 17.417085427135678, '滨江-彩虹城': 21.973228346456693, '滨江-浦沿': 19.862815884476536, '滨江-滨江区政府': 14.706451612903226, '滨江-白马湖': 24.579710144927535, '滨江-西兴': 19.679425837320576, '滨江-长河': 20.755223880597015}

# 户型结构分析
f6 = house['户型结构'].value_counts(ascending=True)
f6.plot.pie()
plt.title('户型结构分析')
# 图标表现出大多为平方出卖。
Text(0.5, 1.0, '户型结构分析')

# 建筑类型:
f7 = house['建筑类型'].value_counts(ascending=True)
f7.plot.pie()
plt.title('建筑类型分析')
# 图标表示大多为板楼建筑
Text(0.5, 1.0, '建筑类型分析')

# 房屋朝向:
f8 = house['房屋朝向'].value_counts(ascending=True)
f8.plot.pie()
plt.title('房屋朝向分析')
# 表现为大多面朝南向
Text(0.5, 1.0, '房屋朝向分析')

# 配备电梯:
f9 = house['配备电梯'].value_counts(ascending=True)
print(f9)
plt.xticks(rotation = 90) # 横坐标
plt.plot(f9, linewidth=3, marker='o',
markerfacecolor='blue', markersize=5)
plt.title('配备电梯统计')
plt.show()
# 表现为大多为配备电梯
配备电梯 1 暂无数据 348 无 1937 有 5476 Name: 配备电梯, dtype: int64

# 房屋用途:
f10 = house['房屋用途'].value_counts(ascending=True)
print(f10)
plt.xticks(rotation = 90) # 横坐标
plt.plot(f10, linewidth=3, marker='o',
markerfacecolor='blue', markersize=5)
plt.title('房屋用途统计')
plt.show()
# 表现为大多为普通住宅
房屋用途 1 车库 2 别墅 357 商住两用 1247 普通住宅 6514 Name: 房屋用途, dtype: int64

# 卖点核心分析
# 导入词云库
import wordcloud
# 导入jieba库,做分词使用
import jieba
# 精确模式,分词后返回一个列表
ls = jieba.lcut(str(house['核心卖点']))
# 将空格与分词分隔开
txt1 = " ".join(ls)
w = wordcloud.WordCloud(font_path="simkai.ttf", background_color="white",
width=600, height=400, max_font_size=120, max_words=3000)
# 生成词云
w.generate(txt1)
# 词云图片命名
w.to_file("maidian.png")
# 展现出大多为靠近市场、夜市、购物方便、整洁等特点
