PyTorch深度学习实战(23)——从零开始实现SSD目标检测
PyTorch深度学习实战(23)——从零开始实现SSD目标检测
-
- 0. 前言
- 1. SSD 目标检测模型
-
- 1.1 SSD 网络架构
- 1.2 利用不同网络层执行边界框和类别预测
- 1.3 不同网络层中默认框的尺寸和宽高比
- 1.4 数据准备
- 1.5 模型训练
- 2. 实现 SSD 目标检测
-
- 2.1 SSD300 架构
- 2.2 MultiBoxLoss
- 2. 训练 SSD
- 小结
- 系列链接
0. 前言
SSD (Single Shot MultiBox Detector) 是一种基于单次前向传递的实时目标检测算法,它在速度和准确性之间取得了很好的平衡。与传统的两阶段目标检测算法(如 Faster R-CNN )不同,SSD 直接在图像的多个尺度上进行预测,无需候选框生成和筛选。SSD 的核心思想是在卷积神经网络的不同层级上设置多个特征图用于预测目标。这些特征图在空间上具有不同的尺度,可以检测不同大小的目标。每个特征图上的每个位置都预测一组边界框和对应的类别概率。在本节中,将介绍 SSD 的工作原理,然后在自定义数据集上训练 SSD 目标检测模型。
1. SSD 目标检测模型
在 R-CNN 和 YOLO 目标检测模型中,通过数次应用卷积和池化预测目标对象类别和边界框。同时,我们也知道不同的网络层对原始图像具有不同的感受野,初始层相对于最终层具有较小的感受野。在本节中,我们将学习 SSD 如何利用这一现象来预测图像中目标对象的边界框。
SSD (Single Shot Multibox Detector) 使用了多层感受野的特性来解决多尺度目标检测问题,检测图像中不同尺度的目标对象,具体来说:
- 使用额外的网络层扩展预训练的
VGG网络,直到获得1 x 1的输出 - 与仅使用最终层进行边界框和类别预测不同,
SSD利用这些添加的卷积层和池化层检测大小不同的物体 SSD使用特定比例和纵横比的默认框来代替锚框,并将这些框与不同特征图中的不同尺寸的目标相对应- 与
YOLO使用锚框预测类别和偏移量一样,SSD通过对每个默认框进行类别和偏移量预测来输出目标检测结果
总体而言,SSD 与 YOLO 的主要区别包括:SSD 中使用默认框 (default box) 替换了 YOLO 中的锚框 (anchor box),并且 SSD 中使用多层特征图执行预测,而 YOLO 中使用最终特征层。
1.1 SSD 网络架构
SSD 的网络架构如下:
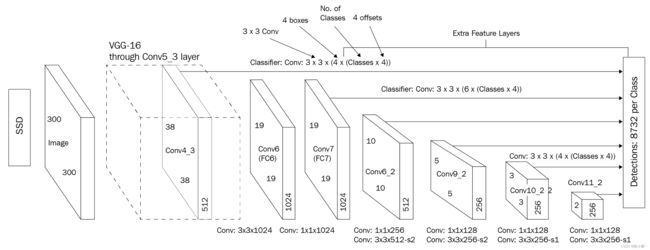
如上图中所示,将一张尺寸为 300 x 300 x 3 的图像输入到预训练的 VGG-16 网络获得 conv5_3 层的输出,然后,通过在 conv5_3 后追加更多卷积层来扩展网络。
1.2 利用不同网络层执行边界框和类别预测
接下来,针对每个单元格和每个默认框获取边界框偏移量和类别预测。conv5_3 输出的预测总数为 38 x 38 x 4,其中 38 x 38 是 conv5_3 层的输出形状,4 是在 conv5_3 层上的默认框数量。以此类推,整个网络的参数总数如下:
| 层 | 权重数 |
|---|---|
| conv5_3 | 38 x 38 x 4 = 5776 |
| FC6 | 19 x 19 x 6 = 2166 |
| conv8_2 | 10 x 10 x 6 = 600 |
| conv9_2 | 5 x 5 x 6 = 150 |
| conv10_2 | 3 x 3 x 4 = 36 |
| conv11_2 | 1 x 1 x 4 = 4 |
| 总计 | 8732 |
可以看到,每个网络层中特征图网格单元上使用的默认框数量并不相同。
1.3 不同网络层中默认框的尺寸和宽高比
本节中,我们学习如何确定默认框的尺寸和宽高比,首先计算默认框尺寸。假设目标对象最小尺寸为图像高度的 20%、宽度的 20%,最大尺寸为高度的 90%、宽度的 90%。在这种情况下,随着网络层的逐渐增加,图像大小会显著缩小:
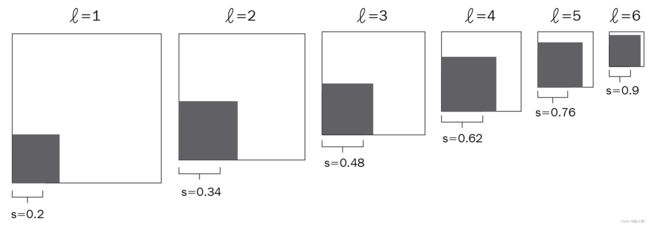
图像缩放的公式如下:
l e v e l i n d e x : l = 1 , . . . , L s c a l e o f b o x e s : s l = s m i n + s m a x − s m i n L − 1 ( l − 1 ) level\ index:l=1,...,L \\ scale\ of\ boxes:s_l=s_{min}+\frac{s_{max}-s_{min}}{L-1}(l-1) level index:l=1,...,Lscale of boxes:sl=smin+L−1smax−smin(l−1)
了解了如何计算默认框在不同网络层的尺寸后,我们继续学习如何确定默认框的宽高比,常用的宽高比如下:
a s p e c t r a t i o : r ∈ 1 , 2 , 3 , 1 / 2 , 1 / 3 aspect\ ratio:r∈{1,2,3,1/2,1/3} aspect ratio:r∈1,2,3,1/2,1/3
不同网络层的默认框框的中心坐标如下:
c e n t e r l o c a t i o n : ( x l i , y l i ) = ( i + 0.5 m , j + 0.5 n ) center\ location:(x_l^i,y_l^i)=(\frac {i+0.5}{m},\frac{j+0.5}{n}) center location:(xli,yli)=(mi+0.5,nj+0.5)
其中,使用 i i i 和 j j j 表示第 l l l 层中的一个单元。
不同宽高比对应的宽高计算如下:
w i d t h : w l r = s l r h e i g h t : h l r = s l r width:w_l^r=s_l\sqrt r\\ height:h_l^r=s_l\sqrt r width:wlr=slrheight:hlr=slr
需要注意的是,我们在不同网络层使用了不同数量的默认框( 4 个或 6 个),如果想要使用 4 个默认框,删除纵横比 {3,1/3},否则使用 6 个默认框,结合不同层及其特征图的比例和长宽比来检测各种尺寸的对象,第 6 个默认框的纵横比计算方式如下:
a d d i t i o n a l s c a l e : s l ′ = s l s l + 1 w h e n r = 1 additional\ scale:s_l'=\sqrt{s_ls_l+1}\ \ \ \ when\ r=1 additional scale:sl′=slsl+1 when r=1
获得了所有可能的默认框后,我们继续学习如何准备训练数据集。
1.4 数据准备
交并比 (Intersection over Union, IoU) 大于指定阈值(例如 0.5 ) 的默认框被视为正匹配,其余为负匹配。在 SSD 的输出中,我们预测默认框属于某个类别(其中第 0 个类别表示背景)的概率,以及默认框相对于真实边界框的偏移量。
最后,我们通过优化分类和定位损失值来训练模型。
1.5 模型训练
分类损失:
L c l s = − ∑ i ∈ p o s l i j k l o g ( c ^ i k ) − ∑ i ∈ n e g l o g ( c ^ i 0 ) , w h e r e c ^ i k = s o f t m a x ( c i k ) L_{cls}=-\sum_{i∈pos}l_{ij}^klog(\hat c_i^k)-\sum_{i∈neg}log(\hat c_i^0),\ where\ \hat c_i^k\ =\ softmax(c_i^k) Lcls=−i∈pos∑lijklog(c^ik)−i∈neg∑log(c^i0), where c^ik = softmax(cik)
其中,pos 表示与真实边界框高度重叠的默认框,而 neg 表示被错误分类的默认框(模型预测这些默认框中包含某个类别但实际上没有包含目标对象)。最后,需要确保 pos : neg 比率最多为 1:3,否则会因为背景类别默认框过多导致预测偏差。
定位损失:对于定位,仅在目标对象得分大于某个阈值时才计算损失值,定位损失计算如下:
L l o c = ∑ i , j ∑ m ∈ { x , y , w , h } 1 i j m a t c h L 1 s m o o t h ( d m i − t m j ) 2 L 1 s m o o t h ( x ) = { 0.5 x 2 i f ∣ x ∣ < 1 ∣ x ∣ − 0.5 o t h e r w i s e t x j = g x i − p x i p w i t y j = g y i − p y i p h i t w j = l o g g w i p w i t h j = l o g g h i p h i L_{loc}=\sum_{i,j}\sum_{m∈\{x,y,w,h\}}1_{ij}^{match}L_1^{smooth}(d_m^i-t_m^j)^2\\ L_1^{smooth}(x)=\left\{ \begin{array}{rcl} 0.5x^2 & & {if\ |x|<1}\\ |x|-0.5 & & {otherwise} \end{array} \right.\\ t_x^j=\frac {g_x^i-p_x^i}{p_w^i}\\ t_y^j=\frac {g_y^i-p_y^i}{p_h^i}\\ t_w^j=log\frac {g_w^i}{p_w^i}\\ t_h^j=log\frac {g_h^i}{p_h^i} Lloc=i,j∑m∈{x,y,w,h}∑1ijmatchL1smooth(dmi−tmj)2L1smooth(x)={0.5x2∣x∣−0.5if ∣x∣<1otherwisetxj=pwigxi−pxityj=phigyi−pyitwj=logpwigwithj=logphighi
其中, t t t 是预测的偏移量, d d d 是实际的偏移量。了解了如何训练 SSD 后,在下一节中,我们将使用 PyTorch 从零开始实现 SSD 模型用于公共汽车与卡车目标检测任务。
2. 实现 SSD 目标检测
2.1 SSD300 架构
SSD300 模型架构包含三个子模块:
class SSD300(nn.Module):
...
def __init__(self, n_classes, device):
...
self.base = VGGBase()
self.aux_convs = AuxiliaryConvolutions()
self.pred_convs = PredictionConvolutions(n_classes)
...
首先将图片输入到 VGGBase 主干网络,返回两个维度为 (N, 512, 38, 38) 和 (N, 1024, 19, 19) 的特征向量。第二个输出将作为 AuxiliaryConvolutions 的输入,并返回维度为 (N, 512, 10, 10)、(N, 256, 5, 5)、(N, 256, 3, 3) 和 (N, 256, 1, 1) 的输出特征图。最后,将 VGGBase 的第一个输出和 AuxiliaryConvolutions 的四个输出特征图输入到 PredictionConvolutions,返回 8,732 个默认框。
SSD300 类的另一个关键是 create_prior_boxes 方法。对于每个特征图,都有三个与之相关的参数:网格大小、网格单元的比例(特征图的基本默认框)以及单元格中所有默认框的宽高比。使用这三个配置,代码使用三重 for 循环创建一个包含 8732 个默认框 (cx, cy, w, h) 的列表。
最后,detect_objects 方法将预测的默认框分类和回归结果的张量转换为实际的边界框坐标。
2.2 MultiBoxLoss
对于人类而言,我们只需关注少数几个边界框。但是对于 SSD 而言,需要比较来自多个特征图的 8,732 个边界框,并预测默认框是否包含有价值的信息,使用 MultiBoxLoss 计算模型损失。前向传播方法 forward 的输入是模型的默认框预测和真实边界框。
首先,通过将模型中的每个默认框与边界框进行比较,将真实边界框转换为一个包含 8732 个默认框的列表。如果 IoU 足够高,那么特定的默认框将具有非零的回归坐标,并将对象类别作为分类的真实值。然后,计算分类置信度和定位损失,并返回这些损失的总和作为前向传播的输出。大多数默认框会被归类为背景类别,因为它们与真实边界框的 IoU 非常小(甚至在大多数情况下为零)。
一旦将真实值转换为包含 8,732 个默认框的回归和分类张量,就可以将它们与模型的预测进行比较。对回归张量执行 MSE-Loss,对定位张量执行 CrossEntropy-Loss,并将它们加起来作为最终损失返回。
2. 训练 SSD
在本节中,我们将使用 PyTorch 实现 SSD 模型来检测图像中目标对象的边界框,继续使用与 R-CNN 一节中相同的数据集。
(1) 加载图像数据集及所需库:
from torchvision.ops import nms
import torch
import numpy as np
from torch.utils.data import DataLoader, Dataset
from glob import glob
from matplotlib import pyplot as plt
import pandas as pd
import matplotlib.patches as mpatches
from PIL import Image
from torchvision import transforms
device = 'cuda' if torch.cuda.is_available() else 'cpu'
DATA_ROOT = 'open-images-bus-trucks/'
IMAGE_ROOT = f'{DATA_ROOT}/images'
DF_RAW = df = pd.read_csv('open-images-bus-trucks/df.csv')
print(DF_RAW.head())
df = df[df['ImageID'].isin(df['ImageID'].unique().tolist())]
label2target = {l:t+1 for t,l in enumerate(DF_RAW['LabelName'].unique())}
label2target['background'] = 0
target2label = {t:l for l,t in label2target.items()}
background_class = label2target['background']
num_classes = len(label2target)
(2) 预处理数据:
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
denormalize = transforms.Normalize(
mean=[-0.485/0.229, -0.456/0.224, -0.406/0.255],
std=[1/0.229, 1/0.224, 1/0.255]
)
def preprocess_image(img):
img = torch.tensor(img).permute(2,0,1)
img = normalize(img)
return img.to(device).float()
def find(item, original_list):
results = []
for o_i in original_list:
if item in o_i:
results.append(o_i)
if len(results) == 1:
return results[0]
else:
return results
(3) 定义数据集类:
class OpenDataset(torch.utils.data.Dataset):
w, h = 300, 300
def __init__(self, df, image_dir=IMAGE_ROOT):
self.image_dir = image_dir
self.files = glob(self.image_dir+'/*')
self.df = df
self.image_infos = df.ImageID.unique()
def __getitem__(self, ix):
# load images and masks
image_id = self.image_infos[ix]
img_path = find(image_id, self.files)
img = Image.open(img_path).convert("RGB")
img = np.array(img.resize((self.w, self.h), resample=Image.BILINEAR))/255.
data = df[df['ImageID'] == image_id]
labels = data['LabelName'].values.tolist()
data = data[['XMin','YMin','XMax','YMax']].values
data[:,[0,2]] *= self.w
data[:,[1,3]] *= self.h
boxes = data.astype(np.uint32).tolist() # convert to absolute coordinates
return img, boxes, labels
def collate_fn(self, batch):
images, boxes, labels = [], [], []
for item in batch:
img, image_boxes, image_labels = item
img = preprocess_image(img)[None]
images.append(img)
boxes.append(torch.tensor(image_boxes).float().to(device)/300.)
labels.append(torch.tensor([label2target[c] for c in image_labels]).long().to(device))
images = torch.cat(images).to(device)
return images, boxes, labels
def __len__(self):
return len(self.image_infos)
(4) 准备训练和测试数据集以及数据加载器:
from sklearn.model_selection import train_test_split
trn_ids, val_ids = train_test_split(df.ImageID.unique(), test_size=0.1, random_state=99)
trn_df, val_df = df[df['ImageID'].isin(trn_ids)], df[df['ImageID'].isin(val_ids)]
len(trn_df), len(val_df)
train_ds = OpenDataset(trn_df)
test_ds = OpenDataset(val_df)
train_loader = DataLoader(train_ds, batch_size=4, collate_fn=train_ds.collate_fn, drop_last=True)
test_loader = DataLoader(test_ds, batch_size=4, collate_fn=test_ds.collate_fn, drop_last=True)
(5) 定义函数在批数据训练模型并计算验证数据的准确率和损失值:
def train_batch(inputs, model, criterion, optimizer):
model.train()
N = len(train_loader)
images, boxes, labels = inputs
_regr, _clss = model(images)
loss = criterion(_regr, _clss, boxes, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss
@torch.no_grad()
def validate_batch(inputs, model, criterion):
model.eval()
images, boxes, labels = inputs
_regr, _clss = model(images)
loss = criterion(_regr, _clss, boxes, labels)
return loss
(6) 初始化模型(模型文件参考 ssd-utils)、优化器和损失函数:
from model import SSD300, MultiBoxLoss
from detect import *
model = SSD300(num_classes, device)
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4, weight_decay=1e-5)
criterion = MultiBoxLoss(priors_cxcy=model.priors_cxcy, device=device)
(7) 训练 SSD 模型:
train_loss_epochs = []
val_loss_epochs = []
for epoch in range(n_epochs):
_n = len(train_loader)
trn_loss = []
val_loss = []
for ix, inputs in enumerate(train_loader):
loss = train_batch(inputs, model, criterion, optimizer)
pos = (epoch + (ix+1)/_n)
trn_loss.append(loss.item())
train_loss_epochs.append(np.average(trn_loss))
_n = len(test_loader)
for ix,inputs in enumerate(test_loader):
loss = validate_batch(inputs, model, criterion)
pos = (epoch + (ix+1)/_n)
val_loss.append(loss.item())
val_loss_epochs.append(np.average(val_loss))
epochs = np.arange(n_epochs)+1
plt.plot(epochs, train_loss_epochs, 'bo', label='Training loss')
plt.plot(epochs, val_loss_epochs, 'r', label='Test loss')
plt.title('Training and Test loss over increasing epochs')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.grid('off')
plt.show()
训练和测试损失值随时间的变化情况如下:
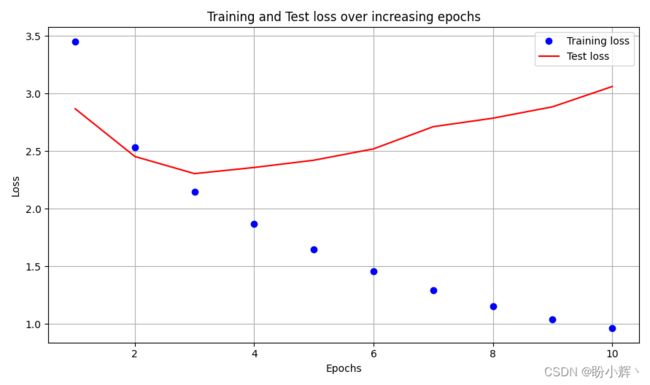
(8) 对测试图像执行预测。
加载测试图像:
def show_bbs(im, bbs, clss):
fig, ax = plt.subplots(ncols=2, nrows=1, figsize=(6, 6))
ax[0].imshow(im)
ax[0].grid(False)
ax[0].set_title('Original image')
if len(bbs) == 0:
ax[1].imshow(im)
ax[1].set_title('No objects')
plt.show()
return
ax[1].imshow(im)
for ix, (xmin, ymin, xmax, ymax) in enumerate(bbs):
rect = mpatches.Rectangle(
(xmin, ymin), xmax-xmin, ymax-ymin,
fill=False,
edgecolor='red',
linewidth=1)
ax[1].add_patch(rect)
centerx = xmin # + new_w/2
centery = ymin + 20# + new_h - 10
plt.text(centerx, centery, clss[ix].replace('@', ''),fontsize = 10,color='red')
ax[1].grid(False)
ax[1].set_title('Predicted bounding box and class')
plt.show()
from random import choice
image_paths = glob.glob(f'{DATA_ROOT}/images/*')
image_id = choice(test_ds.image_infos)
print(image_id)
img_path = find(image_id, test_ds.files)
original_image = Image.open(img_path, mode='r')
original_image = original_image.convert('RGB')
获取与图像中的目标对象对应的边界框、标签和置信度分数:
image_paths = glob.glob(f'{DATA_ROOT}/images/*')
for _ in range(20):
image_id = choice(test_ds.image_infos)
img_path = find(image_id, test_ds.files)
original_image = Image.open(img_path, mode='r')
bbs, labels, scores = detect(original_image, model, min_score=0.9, max_overlap=0.5,top_k=200, device=device)
labels = [target2label[c.item()] for c in labels]
label_with_conf = [f'{l} @ {s:.2f}' for l,s in zip(labels,scores)]
print(bbs, label_with_conf)
在图像上绘制输出结果:
show_bbs(original_image, bbs=bbs, clss=label_with_conf)#, text_sz=10)

小结
SSD 使用基础网络(如 VGG16 或 ResNet )提取图像特征,然后,通过添加额外的卷积层和特征图金字塔来获取不同尺度的特征图。每个特征图单元预测固定数量的边界框,并预测每个边界框属于不同类别的概率。为了提高检测的准确性,SSD 还引入了不同大小的默认框,用于与预测的边界框进行匹配。本文首先介绍了 SSD 模型的核心思想与目标检测流程,然后使用 PyTorch 从零开始实现了一个基于 SSD 的目标检测模型。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习
PyTorch深度学习实战(16)——面部关键点检测
PyTorch深度学习实战(17)——多任务学习
PyTorch深度学习实战(18)——目标检测基础
PyTorch深度学习实战(19)——从零开始实现R-CNN目标检测
PyTorch深度学习实战(20)——从零开始实现Fast R-CNN目标检测
PyTorch深度学习实战(21)——从零开始实现Faster R-CNN目标检测
PyTorch深度学习实战(22)——从零开始实现YOLO目标检测
PyTorch深度学习实战(23)——使用U-Net架构进行图像分割
PyTorch深度学习实战(24)——从零开始实现Mask R-CNN实例分割
PyTorch深度学习实战(25)——自编码器(Autoencoder)
PyTorch深度学习实战(26)——卷积自编码器(Convolutional Autoencoder)
PyTorch深度学习实战(27)——变分自编码器(Variational Autoencoder, VAE)
PyTorch深度学习实战(28)——对抗攻击(Adversarial Attack)
PyTorch深度学习实战(29)——神经风格迁移
PyTorch深度学习实战(30)——Deepfakes
PyTorch深度学习实战(31)——生成对抗网络(Generative Adversarial Network, GAN)
PyTorch深度学习实战(32)——DCGAN详解与实现
PyTorch深度学习实战(33)——条件生成对抗网络(Conditional Generative Adversarial Network, CGAN)
PyTorch深度学习实战(34)——Pix2Pix详解与实现