【数据+代码】CNN-LSTM模型实现时间序列预测
01、引言
本文涵盖主题:引言、数据准备、探索性数据分析、数据预处理、模型训练、模型评估。
本文使用深度学习组合模型CNN-LSTM来进行销售额的预测。将介绍这一模型的原理并应用于一个销售数据集,帮助我们理解销售模式并进行准确的销售额预测。
本期内容『数据+代码』已上传百度网盘。
有需要的朋友可以关注公众号【小Z的科研日常】,后台回复关键词[CNN-LSTM]获取。
02、数据准备
首先导入所需的库,加载和探索销售数据集。观察数据集的前几行,以了解数据的结构和字段。
import warnings
import numpy as np
import pandas as pd
warnings.filterwarnings("ignore")
# 加载数据集
train = pd.read_csv('C:/Users/asus/Desktop/CNN-LSTM/train.csv', parse_dates=['date'])
test = pd.read_csv('C:/Users/asus/Desktop/CNN-LSTM/test.csv', parse_dates=['date'])
# 查看数据集的前几行
train.head()同时,观察训练数据集的时间周期:
print('Min date from train set: %s' % train['date'].min().date())
print('Max date from train set: %s' % train['date'].max().date())找出从训练集的最后一天到测试机的最后一天之间的时间差,即滞后期(需要预测的天数):
lag_size = (test['date'].max().date() - train['date'].max().date()).days
print('Max date from train set: %s' % train['date'].max().date())
print('Max date from test set: %s' % test['date'].max().date())
print('Forecast lag size', lag_size)03、数据探索性分析
为了探索时间序列数据,我们首先需要按日汇总销售额。我们将将绘制折线图来可视化每日销售额以及不同店铺和商品的销售趋势。
日销售总额
import seaborn as sns
import matplotlib.pyplot as plt
# 设置Seaborn样式
sns.set_style("whitegrid")
sns.set_palette("bright") # 设置亮色调色板
# 创建图像
fig, ax = plt.subplots(figsize=(10, 6)) # 设置图像大小
# 绘制折线图
sns.lineplot(data=daily_sales, x='date', y='sales', ax=ax)
# 设置标题和轴标签
ax.set_title('Daily Sales', fontsize=16)
ax.set_xlabel('Date', fontsize=12)
ax.set_ylabel('Sales', fontsize=12)
# 调整刻度标签字体大小
ax.tick_params(axis='x', labelsize=10)
ax.tick_params(axis='y', labelsize=10)
# 调整图例样式和位置
ax.legend(['Sales'], loc='upper left', fontsize=10)
# 保存图像(可选)
plt.savefig('daily_sales_plot.png', dpi=300, bbox_inches='tight')
# 显示图像
plt.show()
门店日销售额
# 设置Seaborn样式
sns.set_style("whitegrid")
sns.set_palette("bright") # 设置亮色调色板
# 创建图像
fig, ax = plt.subplots(figsize=(10, 6)) # 设置图像大小
# 遍历每个店铺的销售数据
for store in store_daily_sales['store'].unique():
current_store_daily_sales = store_daily_sales[store_daily_sales['store'] == store]
# 绘制折线图
sns.lineplot(data=current_store_daily_sales, x='date', y='sales', label=f"Store {store}", ax=ax)
# 设置标题和轴标签
ax.set_title('Store Daily Sales', fontsize=16)
ax.set_xlabel('Date', fontsize=12)
ax.set_ylabel('Sales', fontsize=12)
# 调整刻度标签字体大小
ax.tick_params(axis='x', labelsize=10)
ax.tick_params(axis='y', labelsize=10)
# 调整图例样式和位置
ax.legend(loc='upper left', fontsize=10)
# 保存图像(可选)
plt.savefig('store_daily_sales_plot.png', dpi=300, bbox_inches='tight')
# 显示图像
plt.show()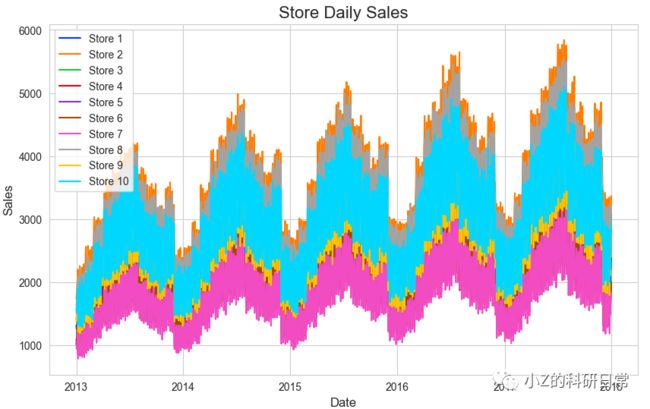
门店日销售额
sns.set_style("whitegrid")
sns.set_palette("bright") # 设置亮色调色板
# 创建图像
fig, ax = plt.subplots(figsize=(10, 6)) # 设置图像大小
# 遍历每个商品的销售数据
max_legend_items = 5 # 最多显示的图例项数
num_legend_items = 0 # 当前已显示的图例项数
for item in item_daily_sales['item'].unique():
current_item_daily_sales = item_daily_sales[item_daily_sales['item'] == item]
# 只绘制前 max_legend_items 个图例项
if num_legend_items < max_legend_items:
# 绘制折线图
sns.lineplot(data=current_item_daily_sales, x='date', y='sales', label=f"Item {item}", ax=ax)
num_legend_items += 1
else:
break
# 添加省略号标识
if num_legend_items < len(item_daily_sales['item'].unique()):
ax.plot([], [], ' ', label='...')
# 设置标题和轴标签
ax.set_title('Item Daily Sales', fontsize=16)
ax.set_xlabel('Date', fontsize=12)
ax.set_ylabel('Sales', fontsize=12)
# 调整刻度标签字体大小
ax.tick_params(axis='x', labelsize=10)
ax.tick_params(axis='y', labelsize=10)
# 调整图例样式和位置
ax.legend(loc='upper left', fontsize=10)
# 保存图像(可选)
plt.savefig('item_daily_sales_plot.png', dpi=300, bbox_inches='tight')
# 显示图像
plt.show()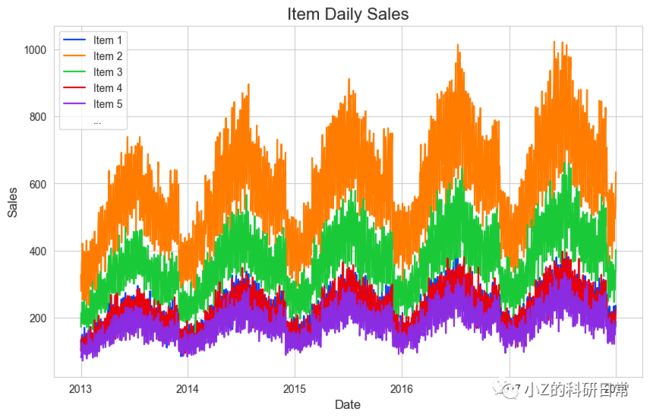
04、数据预处理
在进行预测建模之前,我们需要对数据进行预处理。我们将根据日期范围筛选数据,并按照商品、店铺和日期进行分组。然后,我们将数据转换为监督学习问题的形式,其中子样本训练集仅获取最后一年的数据,减少训练时间,并重新排列数据集,以便可以应用移位方法:
train = train[(train['date'] >= '2017-01-01')]
train_gp = train.sort_values('date').groupby(['item', 'store', 'date'], as_index=False)
train_gp = train_gp.agg({'sales':['mean']})
train_gp.columns = ['item', 'store', 'date', 'sales']
train_gp.head()将数据转换为时间序列问题:
def series_to_supervised(data, window=1, lag=1, dropnan=True):
cols, names = list(), list()
# Input sequence (t-n, ... t-1)
for i in range(window, 0, -1):
cols.append(data.shift(i))
names += [('%s(t-%d)' % (col, i)) for col in data.columns]
# Current timestep (t=0)
cols.append(data)
names += [('%s(t)' % (col)) for col in data.columns]
# Target timestep (t=lag)
cols.append(data.shift(-lag))
names += [('%s(t+%d)' % (col, lag)) for col in data.columns]
# Put it all together
agg = pd.concat(cols, axis=1)
agg.columns = names
# Drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg我们将使用当前时间步和上一个29天的时间步来预测未来90天的时间。同时删除项目或存储值于移位列不同的行和不需要的列:
window = 29
lag = lag_size
series = series_to_supervised(train_gp.drop('date', axis=1), window=window, lag=lag)
series.head()
last_item = 'item(t-%d)' % window
last_store = 'store(t-%d)' % window
series = series[(series['store(t)'] == series[last_store])]
series = series[(series['item(t)'] == series[last_item])]
columns_to_drop = [('%s(t+%d)' % (col, lag)) for col in ['item', 'store']]
for i in range(window, 0, -1):
columns_to_drop += [('%s(t-%d)' % (col, i)) for col in ['item', 'store']]
series.drop(columns_to_drop, axis=1, inplace=True)
series.drop(['item(t)', 'store(t)'], axis=1, inplace=True)05、模型训练
将数据分割为训练集和验证集,并为CNN-LSTM模型准备数据。然后,我们构建和编译CNN-LSTM模型,并进行训练:
from keras import optimizers
from keras.models import Sequential, Model
from keras.layers.convolutional import Conv1D, MaxPooling1D
from keras.layers import Dense, LSTM, RepeatVector, TimeDistributed, Flatten
import tensorflow as tf
# 将数据分割为训练集和验证集
X_train, X_valid, Y_train, Y_valid = train_test_split(series, labels.values, test_size=0.4, random_state=0)
# 将数据准备成CNN-LSTM模型所需的格式
X_train_series = X_train.values.reshape((X_train.shape[0], X_train.shape[1], 1))
X_valid_series = X_valid.values.reshape((X_valid.shape[0], X_valid.shape[1], 1))
# 构建CNN-LSTM模型
model_cnn_lstm = Sequential()
model_cnn_lstm.add(TimeDistributed(Conv1D(filters=64, kernel_size=1, activation='relu'), input_shape=(None, X_train_series_sub.shape[2], X_train_series_sub.shape[3])))
model_cnn_lstm.add(TimeDistributed(MaxPooling1D(pool_size=2)))
model_cnn_lstm.add(TimeDistributed(Flatten()))
model_cnn_lstm.add(LSTM(50, activation='relu'))
model_cnn_lstm.add(Dense(1))
optimizer = tf.keras.optimizers.Adam()
# 编译模型
model_cnn_lstm.compile(loss='mse', optimizer=optimizer)
# 训练模型
cnn_lstm_history = model_cnn_lstm.fit(X_train_series_sub, Y_train, validation_data=(X_valid_series_sub, Y_valid), epochs=50, verbose=2)06、模型评估
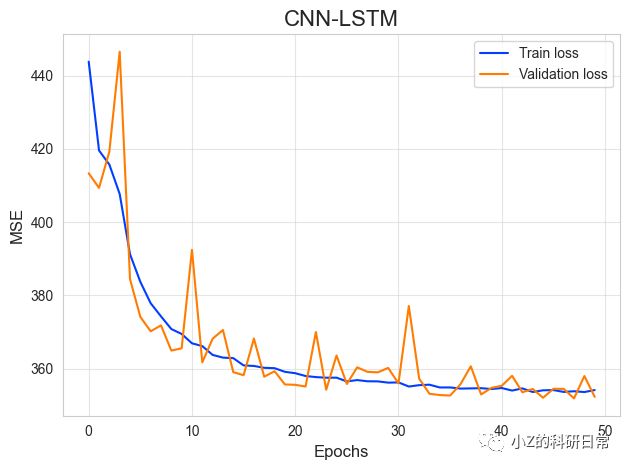
通过可视化训练和验证损失随着训练轮数的变化,以及计算训练集和验证集上的均方根误差(RMSE)来评估模型的性能:
from sklearn.metrics import mean_squared_error
# 可视化训练和验证损失
sns.set_style("whitegrid")
sns.set_palette("bright")
fig, ax4 = plt.subplots()
ax4.plot(cnn_lstm_history.history['loss'], label='Train loss')
ax4.plot(cnn_lstm_history.history['val_loss'], label='Validation loss')
ax4.legend(loc='best')
ax4.set_title('CNN-LSTM')
ax4.set_xlabel('Epochs')
ax4.set_ylabel('MSE')
# 计算训练集和验证集上的RMSE
cnn_lstm_train_pred = model_cnn_lstm.predict(X_train_series_sub)
cnn_lstm_valid_pred = model_cnn_lstm.predict(X_valid_series_sub)
train_rmse = np.sqrt(mean_squared_error(Y_train, cnn_lstm_train_pred))
valid_rmse = np.sqrt(mean_squared_error(Y_valid, cnn_lstm_valid_pred))
print('Train rmse:', train_rmse)
print('Validation rmse:', valid_rmse)