【集群】Slurm作业调度系统的使用
最近使用集群进行实验,记录并学习集群系统进行深度学习的实验过程。集群所使用的作业调度系统为Slurm,这里记录下使用的常用命令和一些注意事项。
Slurm简介
Slurm是一个开源,容错,高度可扩展的集群管理和作业调度系统,适用于大型和小型Linux集群。Slurm不需要对其操作进行内核修改,并且相对独立。作为集群工作负载管理器,Slurm有三个关键功能。
1 它在一段时间内为用户分配对资源(计算节点)的独占和/或非独占访问,以便他们可以执行工作。
2 它提供了一个框架,用于在分配的节点集上启动,执行和监视工作(通常是并行作业)。
3 它通过管理待处理工作的队列来仲裁资源争用。
相关的名词
1 资源(Resource)
作业运行过程中使用的可量化实体都是资源;
包括硬件资源(节点、内存、CPU 、GPU等)和软件资源( License )
2 集群(Cluster)
包含计算、存储、网络等各种资源实体且彼此联系的资源集合;
在物理上,一般由计算处理、互联通信、I/O 存储、操作系统、编译器、运行环境、开发工具等多个软硬件子系统组成;
节点是集群的基本组成单位,从角色上一般可以划分为管理节点、登陆节点、计算节点、存储节点等。一般用户接触到的有管理节点和计算节点,登录和存储节点一般用户不可直接接触。
3 作业(Job)
物理构成,一组关联的资源分配请求,以及一组关联的处理过程;
交互方式,可以分为交互式作业和非交互式作业;
资源使用,可以分为串行作业和并行作业;
4 分区(Partition)
带名称的作业容器;
用户访问控制;
资源使用限制;
5 作业调度系统(Job Schedule System)
负责监控和管理集群中资源和作业的软件系统;
通常由资源管理器、调度器、任务执行器,以及用户命令和API组成;
调度系统主要作用
单一系统映像
解决集群结构松散问题; 统一用户接口,使用简化;
系统资源整合
管理异构资源和异构系统;
多任务管理
统一管理任务,避免冲突;
资源访问控制
基于策略的资源访问控制;
简单来讲,调度系统是面向集群的操作系统。
Slurm三种模式
1 批处理作业(采用sbatch命令提交,最常用方式)
对于批处理作业(提交后立即返回该命令行终端,用户可进行其它操作)使用sbatch命令提交作业脚本,作业被调度运行后,在所分配的首个节点上执行作业脚本。在作业脚本中也可使用srun命令加载作业任务。提交时采用的命令行终端终止,也不影响作业运行。
2 交互式作业提交(采用srun命令提交)
资源分配与任务加载两步均通过srun命令进行:当在登录shell中执行srun命令时,srun首先向系统提交作业请求并等待资源分配,然后在所分配的节点上加载作业任务。采用该模式,用户在该终端需等待任务结束才能继续其它操作,在作业结束前,如果提交时的命令行终端断开,则任务终止。一般用于短时间小作业测试。这种方式类似于正常的通过命令行运行程序。需要一直保持连接状态
3 实时分配模式作业(采用salloc命令提交)
分配作业模式类似于交互式作业模式和批处理作业模式的融合。用户需指定所需要的资源条件,向资源管理器提出作业的资源分配请求。提交后,作业处于排队,当用户请求资源被满足时,将在用户提交作业的节点上执行用户所指定的命令,指定的命令执行结束后,运行结束,用户申请的资源被释放。在作业结束前,如果提交时的命令行终端断开,则任务终止。典型用途是分配资源并启动一个shell,然后在这个shell中利用srun运行并行作业。
注
(1)salloc后面如果没有跟定相应的脚本或可执行文件,则默认选择/bin/sh,用户获得了一个合适环境变量的shell环境。
(2)salloc和sbatch最主要的区别是salloc命令资源请求被满足时,直接在提交作业的节点执行相应任务,而sbatch则当资源请求被满足时,在分配的第一个节点上执行相应任务。
(3)salloc在分配资源后,再执行相应的任务,很适合需要指定运行节点和其它资源限制,并有特定命令的作业。
常用命令
sbatch:提交作业脚本。此脚本一般会包含一个或多个srun命令启动并行任务
sinfo:显示分区或节点状态,可以通过参数选项进行过滤、和排序
squeue:显示队列的作业及作业状态
scancel:取消排队或运行中的作业
scontrol:显示或设定slurm作业、分区、节点等状态
sacctmgr:显示和设置账户关联的QOS等信息
sacct:显示历史作业信息
srun:运行并行作业,具有多个选项,如:最大和最小节点数、处理器数、是否
指定和排除节点。
命令详情
(1)查看分区——sinfo


(2)查询排队和运行状态的作业——squeue
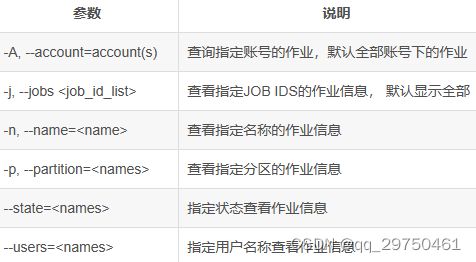
(3)删除作业命令——scancel
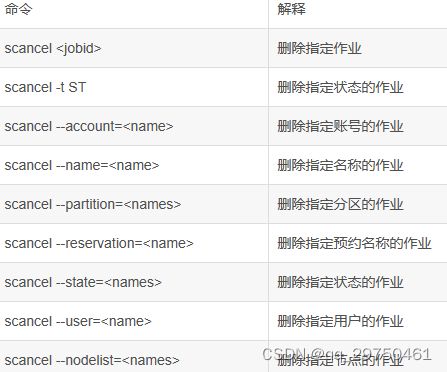
(4)控制作业命令——scontrol
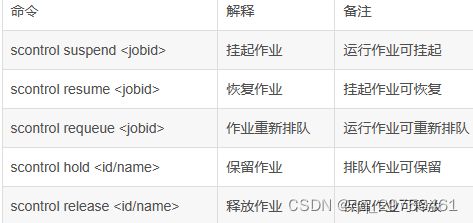
常用术语
user:用户名
node:泛指计算节点
core:CPU核
job:作业
job step:作业步,单个作业(job)可以有多个作业步
partition:分区(可理解为LSF、PBS等作业调度系统中的队列),作业需在特定分区中运行,一般不同分区之间资源不一样
QOS:服务质量,可理解为用户可使用的CPU、内存等资源限制
tasks:任务数,默认一个任务使用一个CPU核,可理解为作业所需的CPU核数
socket:CPU插槽,可理解为物理CPU颗数
stdout:标准输出文件,程序运行正常时输出信息的文件,一般指输出到屏幕的信息
stderr:标准错误文件,程序运行出错时输出信息的文件,一般指输出到屏幕的信息
常用环境变量
SLURM_NODELIST
当前作业被分配的节点列表
SLURM_JOB_NODELIST
当前作业被分配的节点列表
SLURM_JOB_NAME
当前作业的作业名称
SLURMD_NODENAME
当前作业执行任务的主机名
SLURM_NODE_ALIASES
当前作业执行节点的主机别名
SLURM_ARRAY_JOB_ID
当前组数作业的ID号码
SLURM_ARRAY_TASK_ID
当前数组作业的任务ID号
SLURM_ARRAY_TASK_COUNT
当前数组作业的任务总数
SLURM_ARRAY_TASK_MAX
当前数组作业的最大任务ID号
SLURM_ARRAY_TASK_MIN
当前数组作业的最小任务ID号
SLURM_ARRAY_TASK_STEP
当前数组作业任务ID号增长步长
SLURM_NNODES
当前作业使用的节点数目
SLURM_JOBID
当前作业ID号
SLURM_JOB_ID
当前作业ID号
SLURM_TASKS_PER_NODE
当前作业每个节点任务数
SLURM_JOB_USER
当前作业执行用户
SLURM_JOB_UID
当前作业实行用户的UID
SLURM_NODEID
当前作业执行时主机编号(每个任务从0开始)
SLURM_SUBMIT_DIR
当前作业提交时所在目录
SLURM_TASK_PID
当前任务执行时的进程号
SLURM_CPUS_ON_NODE
当前作业执行时做个节点使用的cpu数目
SLURM_PROCID
当前作业执行时CPU的号码
SLURM_LOCALID
当前作业节点上的本地任务的ID号
SLURM_JOB_GID
当前作业执行用户的GID
SLURM_JOB_CPUS_PER_NODE
当前作业执行时每节点使用的CPU数目
SLURM_CLUSTER_NAME
当前作业执行时所在的slurm集群名称
SLURM_GTIDS
当前作业在节点上运行时的全局任务ID号,以0为原点,逗号隔开
SLURM_SUBMIT_HOST
当前作业的提交主机名称
SLURM_JOB_PARTITION
当前作业提交时所用的partition
SLURM_JOB_NUM_NODES
当前作业所用的节点总数(单位:个)
SLURM_MEM_PER_NODE
当前作业每个节点使用的内存(单位:M)
SLURM_MEM_PER_CPU
当前作业每个节点上的每个CPU占用的内存大小
作业提交
这里记录使用 sbatch 进行作业调度
使用sbatch命令提交作业方式,sbatch命令在脚本正确传递给作业调度系统后立即退出,同时获取一个作业号。作业等所需资源满足后开始运行,一般脚本的格式为 .sh 或者 .script 文件。
sbatch提交一个批处理作业脚本到调度系统。批处理脚本名可以在命令行上通过传递给sbatch,也可以定义在批处理脚本中,如果没有指定文件名,则sbatch从标准输入中获取脚本内容。
脚本文件基本格式:
第一行以#!/bin/bash等指定改脚本的解释程序,/bin/bash可以变为/bin/sh、/bin/csh等。
在可执行命令之前的每行“#SBATCH”前缀后跟的参数作为作业调度系统的参数。
默认情况下,标准输出和标准错误都定向到同一个文件slurm-%j.out,“%j”将被作业号代替。
作业脚本基本结构如下:
1 第一行是脚本语言解释器的路径,一般选择 bash 作为解释器
#!/bin/bash
2 若干行由 #SBATCH 引导的 Slurm 设置选项,例如
#SBATCH --partition=hpxg #申请分区 `hpxg` 的计算资源
#SBATCH --nodes=1 #申请 1 个节点
#SBATCH --ntasks-per-node=1 #申请每个节点上分配一个任务(进程)
#SBATCH --time=06:00:00 #计划最多运行 6 小时
3 计算程序运行需要设置的环境变量,例如
#可以查看GPU的运行和使用情况
#nvidia-smi
#which nvidia-smi
#nvidia-smi
conda activate environment
cd /home/codeDir/
4 运行程序的命令,例如
python mycode.py
完整实例:
编辑脚本文件
vi test.sh
文本内容实例
#!/bin/bash -l
#SBATCH --job-name="myTest"
#SBATCH --partition=Pnamw
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=1
#SBATCH --cpus-per-task=1
#SBATCH --output=/home/testWorks.%j.out
#SBATCH --error=/home/testWorks.%j.err
#SBATCH --gpus=2
#nvidia-smi
nvidia-smi
which nvidia-smi
nvidia-smi
conda activate environment
python mai.py
提交运行脚本文件
sbatch test.sh
脚本常用命令
-J,--job-name 指定作业名称
-N,--nodes 节点数量
-n,--ntasks 使用的CPU核数
--mem 指定每个节点上使用的物理内存
-t,--time 运行时间,超出时间限制的作业将被终止
-p,--partition 指定分区
--reservation 执行资源预留名称
-w,--nodelist 指定特定的节点
-x,--exclude 分配给作业的节点中不要包含指定节点
--ntasks-per-node 指定每个节点使用几个CPU核心
--begin 指定作业开始时间
-D,--chdir 指定脚本/命令的工作目录
--export-file= 通过文件filename设定环境变量。文件中的环境变量格式为
NAME=value,变量之间通过空格分隔。
-o,--output= 采用--output可以将其重定向到同一文件中
--gpus 运行程序所需GPU的数量
squeue命令结果详情
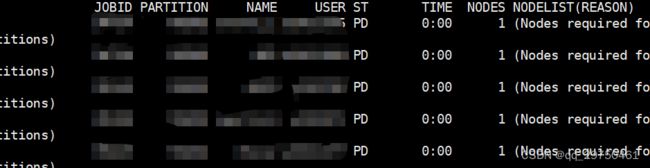
结果列头信息
JOBID:作业号
PARITION:分区名
NAME:作业名
USER:用户名
ST:状态,常见的状态包括
NODELIST(REASON):分配给的节点名列表(原因)
其中ST常见状态包括:
- PD、Q:排队中 ,PENDING
- R:运行中 ,RUNNING
- CA:已取消,CANCELLED
- CG:完成中,COMPLETIONG
- F:已失败,FAILED
- TO:超时,TIMEOUT
- NF:节点失效,NODE FAILURE
- CD:已完成,COMPLETED
NODELIST(REASON):分配给的节点名列表(原因)常见信息:
- AssociationJobLimit:作业达到其最大允许的作业数限制
- AssociationResourceLimit:作业达到其最大允许的资源限制
- AssociationTimeLimit作业:作业达到时间限制
- Resource:作业等待期所需资源可用
- QOSJobLimit:作业的QOS达到其最大的作业数限制
- QOSResourceLimit:作业的QOS达到其最大资源限制
- QOSTimeLimit:作业的QOS达到其最大时间限制
- PartitionNodeLimit:作业所需的节点超过所用分区当前限制
- PartitionTimeLimit:作业所需的分区达到时间限制
- Priority :作业所需的分区存在高等级作业或预留
- NodeDown:作业所需的节点宕机
- JobHeldUser:作业被用户自己挂起
- InvalidQOS:作业的QOS无效
Nodes required for job are DOWN, DRAINED or reserved for jobs in higher priority partitions:作业所需的节点已关闭、耗尽或保留给优先级较高的分区中的作业
scancel 取消任务
用户使用scancel命令取消自己的作业。命令格式如下:
scancel jobid
jobid可通过squeue获得。对于排队作业,取消作业将简单地把作业标记为CANCELLED状态而结束作业。对于运行中或挂起的作业,取消作业将终止作业的所有作业步,包括批处理作业脚本,将作业标记为CANCELLED状态,并回收分配给作业的结点。

挂起作业
scontrol hold job_list
scontrol hold job_list命令可使得排队中尚未运行的作业(设置优先级为0)暂停被分配运行,被挂起的作业将不被执行,这样可以让其他作业优先得到资源运行。被挂起的作业在使用squeue命令查询显示时NODELIST(REASON)状态标志为JobHelduser(被用户自己挂起)或JobheldAdmin(被系统管理员挂起),利用scontrol release job_list 可取消挂起。
其他常用命令
1 查看节点状态
sinfo
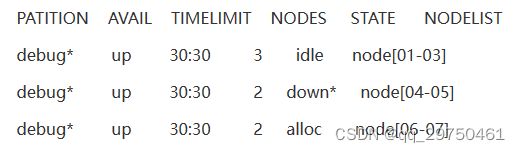
PARRITION:节点所在分区。
AVAIL:分区状态,up标识可用,down标识不可用。
TIMELIMIT: 程序运行最大时长,infinite表示不限制,
限制格式为days-houres:minutes:seconds。
NODES:节点数。
NODELIST:节点名列表。
STATE:节点状态,可能的状态包括
1 allocated、alloc :已分配
2 completing、comp:完成中
3 down:宕机
4 drained、drain:已失去活力
5 fail:失效
6 idle:空闲
7 mixed:混合,节点在运行作业,但有些空闲CPU核,可接受新作业
8 reserved、resv:资源预留
9 unknown、unk:未知原因
注意:如果状态带有后缀*,表示节点没有响应
2 主要参数
-a、–all
显示全部分区信息
-d、–dead
仅显示无响应或已宕机节点
-i
以 秒间隔持续自动更新显示信息
-I
显示详细信息
-n
显示指定 节点信息
-N
以每行一个节点方式显示信息,即显示各节点信息
-p
显示 分区信息
-r
仅显示响应节点信息
-R
显示不响应(down、drained、fail或者failing状态)节点的原因
-o
按照 格式输出信息,type[:[.]size],
默认为“%#P %5a %.101 %.6D %.6t %N”
1 %all:所有字段信息。
2 %a:分区的状态及是否可用。
3 %A:以“allocated/idle”格式显示状态对应的节点信息
4 %B:分区中每个节点可分配给作业的core数。
5 %c:各节点core数。
6 %C:以“allocated/idle/other.total”格式显示core数。
7 %D:节点数。
8 %e:节点空闲内存。
9 %E:节点无效的原因。
10 %g:可使用此节点的用户组。
11 %n:节点主机名。
12 .:指明为右对齐,默认为左对齐。
13 size:最小字段大小,如没有指明,则最大为20个字符
查看节点信息
scontorl show node [node]
$: scontrol show node node4
CPUAlloc=0 CPUErr=0 CPUTot=32 CPULoad=44.09
AvailableFeatures=(null)
ActiveFeatures=(null)
Gres=(null)
NodeAddr=node4 NodeHostName=node4
RealMemory=64000 AllocMem=0 FreeMem=72333 Sockets=32 Boards=1
State=DOWN* ThreadsPerCore=1 TmpDisk=0 Weight=1 Owner=N/A MCS_label=N/A
Partitions=batch
BootTime=None SlurmdStartTime=None
CfgTRES=cpu=32,mem=62.50G,billing=32
AllocTRES=
CapWatts=n/a
CurrentWatts=0 LowestJoules=0 ConsumedJoules=0
ExtSensorsJoules=n/s ExtSensorsWatts=0 ExtSensorsTemp=n/s
CPUAlloc:该节点已分配的core数量
CPUTot:该节点core总数
CPULoad:该节点负载情况
NodeHostName:该节点主机名
Partitions:该节点属于哪个分区
RealMemory:该节点内存大小
State:该节点状态值
查看分区信息
scontrol show partition
$:scontrol show partition
PartitionName=batch
AllowGroups=ALL AllowAccounts=ALL AllowQos=ALL
AllocNodes=ALL Default=YES QoS=N/A
DefaultTime=NONE DisableRootJobs=NO ExclusiveUser=NO GraceTime=0 Hidden=NO
MaxNodes=UNLIMITED MaxTime=UNLIMITED MinNodes=1 LLN=NO MaxCPUsPerNode=UNLIMITED
Nodes=node4
PriorityJobFactor=1 PriorityTier=1 RootOnly=NO ReqResv=NO OverSubscribe=NO
OverTimeLimit=NONE PreemptMode=OFF
State=UP TotalCPUs=32 TotalNodes=1 SelectTypeParameters=NONE
DefMemPerNode=UNLIMITED MaxMemPerNode=UNLIMITED
DisableRootJobs:不允许root提交作业
Maxtime:最大运行时间
LLN:是否按最小负载节点调度
Maxnodes:最大节点数
Hidden:是否为隐藏分区
Default:是否为默认分区
OverSubscribe:是否允许超时
ExclusiveUser:排除的用户