k8s-kubernetes错误集锦总结-环境搭建篇
k8s-kubernetes错误集锦
随笔,学习总结,写给以后的自己看的,所以文章会比较随意
①
[root@centos7 k8s-auto]# kubectl get nodes
The connection to the server localhost:8080 was refused - did you specify the right host or port?
上述错误,检查一下环境变量是否设置好了,检查步骤如下
env | grep -i kube

如果没有、为空或者路径不对,文件有误等等对正修正错误就可以了,添加方式如下
临时方式
export KUBECONFIG=/etc/kubernetes/admin.conf
永久修改方式
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" > /etc/profile.d/kubeconfig.sh
source /etc/profile.d/kubeconfig.sh
改为之后再试就可以了

②节点NotReady的原因
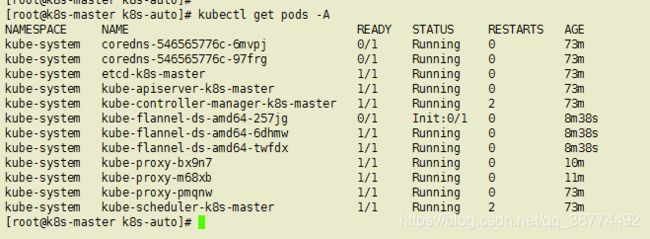
排查步骤,检查pods的状态如下,coredns处于pending(挂起状态),describe看看详细信息
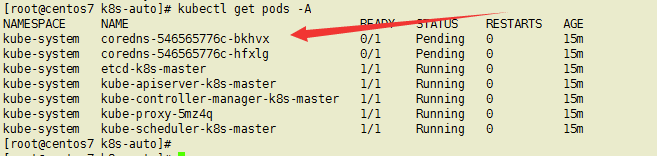
kubectl describe pods coredns-546565776c-bkhvx -n kube-system
 最下面是这样说的,这里先加个节点上去再看日志排错,因为我这里只有一个master节点
最下面是这样说的,这里先加个节点上去再看日志排错,因为我这里只有一个master节点
问题②先跳过,下文再解析,现在去另一台主机加入新的节点
③
kubeadm join 192.168.40.130:6443 --token hdp0kg.ac73i5ms09kuvqbx --discovery-token-ca-cert-hash sha256:5026d0d1673e55ae99bdbf74d6633988d3e9d76a70903adae9e5b9a8582bdf1a
这个tocken值每个人设的都不一样,自己替换下,报如下错,不方,拉到最后看看

 ERROR: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
ERROR: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
errors pretty printing info
, error: exit status 1
[ERROR Service-Docker]: docker service is not active, please run ‘systemctl start docker.service’
[ERROR IsDockerSystemdCheck]: cannot execute ‘docker info -f {{.CgroupDriver}}’: exit status 2
[ERROR FileContent–proc-sys-net-ipv4-ip_forward]: /proc/sys/net/ipv4/ip_forward contents are not set to 1
[ERROR SystemVerification]: error verifying Docker info: “Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?”
[preflight] If you know what you are doing, you can make a check non-fatal with --ignore-preflight-errors=...
To see the stack trace of this error execute with --v=5 or higher
图上说docker服务没起,确实没起,启起来再试就成功了,而且启动命令也给了,就是那么的方便_
systemctl start docker.service
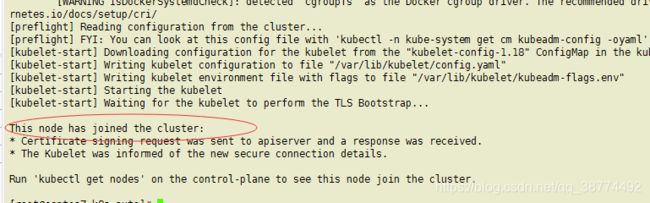 成功
成功
④回到master主机

ok,现在解决②中的错误,查看下系统日志
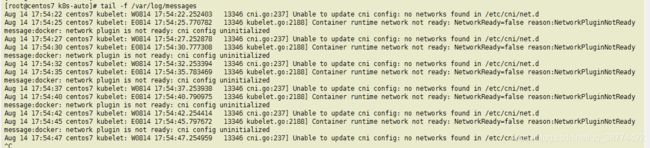 可以看到一直在刷这个错误:
可以看到一直在刷这个错误:
Unable to update cni config: no networks found in /etc/cni/net.d
Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
由此可见是网络问题,这个是需要部署一个网络规划服务,我这里因为用的是coredns这个pod,所以我这里部署的是flannel,步骤如下
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
下载,这里我的另一篇文档也有写,文件也提供到csdn的资源处
这个yaml里面可以修改一个配置,绑定网卡,防止双网卡的机器部署时报错;
检索关键词masq,在图中位置加入–iface,其中我这里的ens33是对应我的网卡名,你们对应修改即可;

在master上部署
kubectl apply -f kube-flannel.yml
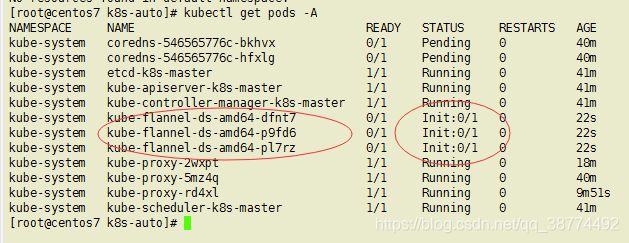 正在初始化,describe看看细节
正在初始化,describe看看细节
 正在拉取镜像,有时会报ImagePullBackOff,大多数是镜像拉取超时的原因
正在拉取镜像,有时会报ImagePullBackOff,大多数是镜像拉取超时的原因
导致的有网速(更换镜像源),还有可能是systemd服务不正常,或者磁盘内存等等,具体要看报错信息对应解决;
如果是systemd1服务超时问题,需要手动kill掉kubelet的进程,根据系统日志(message和dmesg)的报错修正错误,然后重启电脑;
如下图

 修正错误后,如下图显示
修正错误后,如下图显示

 还有一个节点的这个pod正在初始化中
还有一个节点的这个pod正在初始化中
ABRT has detected 1 problem(s). For more info run: abrt-cli list --since 1597805286
[root@k8s-node2 ~]# abrt-cli list --since 1597805286
id 0770fc07826bfb4326df323a5bc3e3bdc9c54cc8
reason: NMI watchdog: BUG: soft lockup - CPU#2 stuck for 22s! [flannel:6611]
time: 2020年08月19日 星期三 15时49分39秒
cmdline: BOOT_IMAGE=/vmlinuz-3.10.0-1062.el7.x86_64 root=/dev/mapper/centos-root ro crashkernel=auto rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet LANG=zh_CN.UTF-8
package: kernel
uid: 0 (root)
count: 1
Directory: /var/spool/abrt/oops-2020-08-19-15:49:39-6633-0
已报告: 无法报告
已禁用自动报告功能。请考虑启用该功能,方法是
作为有 root 特权的用户使用命令 'abrt-auto-reporting enabled'
这个cpu占用率过高,导致单核发生软锁("死锁”),这个会经常发生,具体原因要具体分析,下文会慢慢举例分析
 完成了,但是coredns仍未ready状态,查看系统日志发现
完成了,但是coredns仍未ready状态,查看系统日志发现
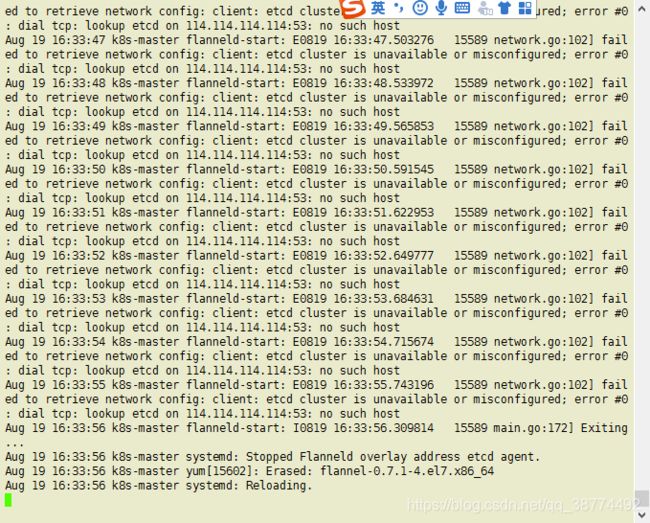
Aug 19 15:55:39 k8s-master flanneld-start: E0819 15:55:39.713690 8277 network.go:102] failed to retrieve network config: client: etcd cluster is unavailable or misconfigured; error #0: dial tcp 192.168.161.131:2379: i/o timeout
Aug 19 15:55:41 k8s-master flanneld-start: E0819 15:55:41.714940 8277 network.go:102] failed to retrieve network config: client: etcd cluster is unavailable or misconfigured; error #0: dial tcp 192.168.161.131:2379: i/o timeout
Aug 19 15:55:43 k8s-master flanneld-start: E0819 15:55:43.717839 8277 network.go:102] failed to retrieve network config: client: etcd cluster is unavailable or misconfigured; error #0: dial tcp 192.168.161.131:2379: i/o timeout
上述错误,在这里是因为原来我在这三台机器上装了etcd和flannel(搭建docker-swarm时所需),etcd加入集群时就报错,我就把存储的东西已经删除了,但是没想起flannel还启着;并且这个ip我还更改过,所以他连接的是根本不在线的ip当然会报错;检查/etc/hosts发现。
192.168.161.131 etcd #这个要移除,三台机器都要
作为这些还是会报错的,总结下message里面的日志
Aug 19 16:33:55 k8s-master flanneld-start: E0819 16:33:55.743196 15589 network.go:102] failed to retrieve network config: client: etcd cluster is unavailable or misconfigured; error #0: dial tcp: lookup etcd on 114.114.114.114:53: no such host
Aug 19 16:32:03 k8s-master flanneld-start: E0819 16:32:03.592101 15556 network.go:102] failed to retrieve network config: client: etcd cluster is unavailable or misconfigured; error #0: dial tcp 192.168.161.127:2379: getsockopt: connection refused
下图是我查看集群的日志
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling default-scheduler 0/1 nodes are available: 1 node(s) had taint {node.kubernetes.io/not-ready: }, that the pod didn't tolerate.
Warning FailedScheduling default-scheduler 0/2 nodes are available: 2 node(s) had taint {node.kubernetes.io/not-ready: }, that the pod didn' t tolerate.
Warning FailedScheduling default-scheduler 0/3 nodes are available: 3 node(s) had taint {node.kubernetes.io/not-ready: }, that the pod didn't tolerate.
Normal Scheduled default-scheduler Successfully assigned kube-system/coredns-546565776c-6mvpj to k8s-node2
Normal Pulling 10m kubelet, k8s-node2 Pulling image "registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.6.7"
Normal Pulled 10m kubelet, k8s-node2 Successfully pulled image "registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.6.7"
Normal Created 10m kubelet, k8s-node2 Created container coredns
Normal Started 10m kubelet, k8s-node2 Started container coredns
Warning Unhealthy 8m34s kubelet, k8s-node2 Readiness probe failed: Get http://10.18.1.2:8181/ready: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
Warning Unhealthy 10s (x55 over 10m) kubelet, k8s-node2 Readiness probe failed: HTTP probe failed with statuscode: 503
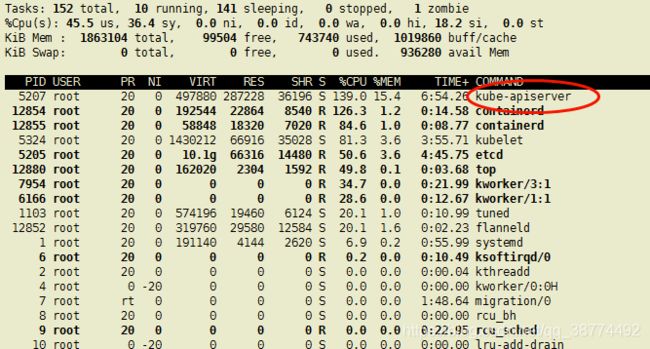 可以看到,因为这个原因,又造成线程堵塞,cpu占用过高,此时可以先停止k8s集群环境(仅测试学习时如此操作),不过即时你把kubelet和docker停止,也不会停止报错,因为根本原因不是出在集群里;
可以看到,因为这个原因,又造成线程堵塞,cpu占用过高,此时可以先停止k8s集群环境(仅测试学习时如此操作),不过即时你把kubelet和docker停止,也不会停止报错,因为根本原因不是出在集群里;
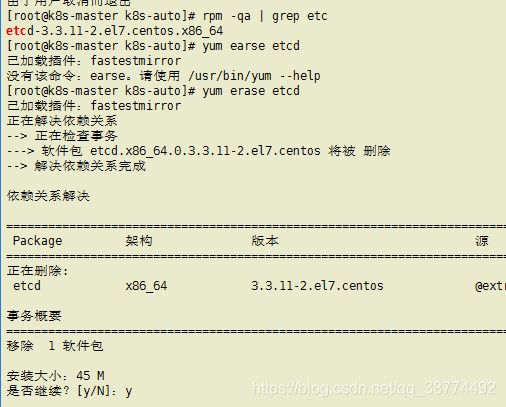
直接把三台机子里的etcd和flannel卸载后,错误日志就停止不刷了;
 卸载步骤
卸载步骤

 今天先到这
今天先到这