C语言 服务器编程-日志系统
日志系统的实现
- 引言
- 最简单的日志类 demo
- 按天日志分类和超行日志分类
- 日志信息分级
- 同步和异步两种写入方式
引言
日志系统是通过文件来记录项目的 调试信息,运行状态,访问记录,产生的警告和错误的一个系统,是项目中非常重要的一部分. 程序员可以通过日志文件观测项目的运行信息,方便及时对项目进行调整.
最简单的日志类 demo
日志类一般使用单例模式实现:
Log.h:
class Log
{
private:
Log() {};
~Log();
public:
bool init(const char* file_name);
void write_log(const char* str);
static Log* getinstance();
private:
FILE* file;
};
Log.cpp:
Log::~Log()
{
if (file != NULL)
{
fflush(file);
fclose(file);
}
}
Log* Log::getinstance()
{
static Log instance;
return &instance;
}
bool Log::init(const char * file_name)
{
file = fopen(file_name,"a");
if (file == NULL)
{
return false;
}
return true;
}
void Log::write_log(const char* str)
{
if (file == NULL)
return;
fputs(str, file);
}
main.cpp:
#include"Log.h"
int main()
{
Log::getinstance()->init("log.txt");
Log::getinstance()->write_log("Hello World");
}
这个日志类实现了最简单的写日志的功能,但是实际应用时,需要在日志系统上开发出许多额外的功能来满足工作需要,有些时候还要进行日志的分类操作,因为你不能将所有的日志信息都塞到一个日志文件中,这样会大大降低可读性,接下来讲一下在这个最简单的日志类的基础上,怎么添加一些新功能.
按天日志分类和超行日志分类
先说两个比较简单的
按天分类和超行分类
按天分类:每一个日志按照天来分类(日志前加上当前的日期作为日志的前缀) 并且写日志前检查日志的创建时间,如果日志创建时间不是今天,那么就额外新创建一个日志,更新创建时间和行数,然后向新日志中写日志信息
超行分类:写日志前检查本次程序写入日志的行数,如果当前本次程序写入日志的行数已经到达上限,那么额外创建新的日志,更新创建时间,然后向新日志中写日志信息
为了实现这两个小功能,我们需要先向日志类中添加以下成员:
- 程序本次启动,写入日志文件的最大行数
- 程序本次启动,已经写入日志的行数
- 日志的创建时间
- 日志的路径名+文件名(创建新日志的时候,命名要跟之前的命名标准一样,最好是标准日志名+后缀的形式,这样便于标识)
更新后的日志类:
Log.h:
#pragma once
#include
#include
#include
#include
using namespace std;
class Log
{
private:
Log() ;
~Log();
public:
//初始化文件路径,文件最大行数
bool init(const char* file_name,int split_lines= 5000000);
void write_log(const char* str);
static Log* getinstance();
private:
FILE* file;
char dir_name[128];//路径名
char log_name[128];//日志名
int m_split_lines; //日志文件最大行数(之前的日志行数不计,只记录本次程序启动写入的行数)
long long m_count; //已经写入日志的行数
int m_today; //日志的创建时间
};
Log.cpp
#define _CRT_SECURE_NO_WARNINGS
#include"Log.h"
Log::Log()
{
m_count = 0;
}
Log::~Log()
{
if (file != NULL)
{
fflush(file);
fclose(file);
}
}
Log* Log::getinstance()
{
static Log instance;
return &instance;
}
bool Log::init(const char * file_name,int split_lines)
{
m_split_lines = split_lines; //设置最大行数
time_t t = time(NULL);
struct tm* sys_tm = localtime(&t);
struct tm my_tm = *sys_tm; //获取当前的时间
const char* p = strrchr(file_name, '/');//这里需要注意下,windows和linux的路径上的 斜杠符浩方向是不同的,windows是\,linux是 / ,而且因为转义符号的原因,必须是 \\
char log_full_name[256] = { 0 };
if (p == NULL) //判断是否输入了完整的路径+文件名,如果只输入了文件名
{
strcpy(log_name, file_name);
snprintf(log_full_name, 255, "%d_%02d_%02d_%s", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, file_name);
}
else //如果输入了完整的路径名+文件名
{
strcpy(log_name, p + 1);
strncpy(dir_name, file_name, p - file_name + 1);
//规范化命名
snprintf(log_full_name,255, "%s%d_%02d_%02d_%s", dir_name, my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, log_name);
}
m_today = my_tm.tm_mday; //更新时间
file = fopen(log_full_name,"a"); //打开文件,打开方式:追加
if (file == NULL)
{
return false;
}
return true;
}
void Log::write_log(const char* str)
{
if (file == NULL)
return;
time_t t = time(NULL);
struct tm* sys_tm = localtime(&t);
struct tm my_tm = *sys_tm; //获取当前的时间,用来后续跟日志的创建时间作对比
m_count++; //日志行数+1
if (m_today != my_tm.tm_mday || m_count % m_split_lines == 0) //如果创建时间!=当前时间或者本次写入行数达到上限
{
char new_log[256] = { 0 }; //新日志的文件名
fflush(file);
fclose(file);
char time_now[16] = { 0 }; //格式化当前的时间
snprintf(time_now, 16, "%d_%02d_%02d_", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday);
if (m_today != my_tm.tm_mday) //如果是创建时间!=今天
{ //这里解释一下,m_today在init函数被调用的时候一定会被设置成当天的时间,只有init和write函数的调用不在同一天中,才会出现这种情况
snprintf(new_log, 255, "%s%s%s", dir_name, time_now, log_name);
m_today = my_tm.tm_mday; //更新创建时间
m_count = 0; //更新日志的行数
}
else //如果是行数达到本次我们规定的写入上限
{
snprintf(new_log,255,"%s%s%lld_%s", dir_name, time_now, m_count / m_split_lines,log_name);//加上版本后缀
}
file = fopen(new_log, "a");
}
fputs(str, file);
fputs("\n", file);
}
运行的结果:
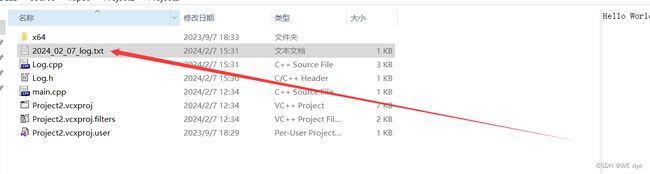
出现了一个以时间开头命名的日志,实现了按天分类
接下来我将一次性写入行数的上限调成5,看一下如果一次性写入超过了行数上限的运行结果是什么样:

出现了一个后缀_1的新文件
PS:这里有一个小BUG:因为m_count是每次运行程序都会重置的一个变量,所以上一次运行时可能因为输出的行数过多,创建了好多新日志,但是下一次运行程序时,还是从第一个日志开始打印的. 而且规定行数上限并不是日志中文件行数的上限,而是每次运行程序写入日志文件的行数上限,所以这个功能并不完美甚至说非常鸡肋暂时还没优化好,在这里仅做一个小小的演示吧.
日志信息分级
我们应该将每一条日志信息进行分类,可以分为四大类:
Debug: 调试中产生的信息
WARN: 调试中产生的警告信息
INFO: 项目运行时的状态信息
ERROR: 系统的错误信息
然后我们可以在日志文件中,每一条日志信息的前面,加上这条信息被写入的时间和其所属的分级,这样会大大增加日志的可读性.
代码还是在上面代码的基础上继续改动
Log.h:
#pragma once
#include
#include
#include
#include
using namespace std;
class Log
{
private:
Log() ;
~Log();
public:
//初始化文件路径,日志缓冲区大小,文件最大行数
bool init(const char* file_name, int log_buf_size = 8192, int split_lines= 5000000);
//新增了一个日志分级
void write_log(int level,const char* str);
static Log* getinstance();
private:
FILE* file;
char dir_name[128];//路径名
char log_name[128];//日志名
int m_split_lines; //日志文件最大行数
long long m_count; //日志当前的行数
int m_today; //日志创建的日期,记录是那一天
int m_log_buf_size; //日志缓冲区的大小,用来存放日志信息字符串
char* m_buf; //日志信息字符串;因为后续要把时间和日志分级也加进来,所以开一个新的char *
};
Log.cpp:
#define _CRT_SECURE_NO_WARNINGS
#include"Log.h"
Log::Log()
{
m_count = 0;
}
Log::~Log()
{
if (file != NULL)
{
fflush(file);
fclose(file);
}
if (m_buf != NULL)
{
delete[] m_buf;
m_buf = nullptr;
}
}
Log* Log::getinstance()
{
static Log instance;
return &instance;
}
bool Log::init(const char * file_name, int log_buf_size , int split_lines)
{
m_log_buf_size = log_buf_size;
m_buf = new char[m_log_buf_size];
memset(m_buf,'\0', m_log_buf_size);// 开辟缓冲区,准备存放格式化的日志字符串
m_split_lines = split_lines; //设置最大行数
time_t t = time(NULL);
struct tm* sys_tm = localtime(&t);
struct tm my_tm = *sys_tm; //获取当前的时间
const char* p = strrchr(file_name, '\\');
char log_full_name[256] = { 0 };
if (p == NULL)
{
snprintf(log_full_name, 255, "%d_%02d_%02d_%s", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, file_name);
strcpy(log_name, file_name);
}
else
{
strcpy(log_name, p + 1);
strncpy(dir_name, file_name, p - file_name + 1);
//规范化命名
snprintf(log_full_name,255, "%s%d_%02d_%02d_%s", dir_name, my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, log_name);
}
m_today = my_tm.tm_mday; //更新日志的创建时间
file = fopen(log_full_name,"a"); //打开文件,打开方式:追加
if (file == NULL)
{
return false;
}
return true;
}
void Log::write_log(int level,const char* str)
{
if (file == NULL)
return;
time_t t = time(NULL);
struct tm* sys_tm = localtime(&t);
struct tm my_tm = *sys_tm; //获取当前的时间,用来后续跟日志的创建时间作对比
char level_s[16] = { 0 }; //日志分级
switch (level)
{
case 0:
strcpy(level_s, "[debug]:");
break;
case 1:
strcpy(level_s, "[info]:");
break;
case 2:
strcpy(level_s, "[warn]:");
break;
case 3:
strcpy(level_s, "[erro]:");
break;
default:
strcpy(level_s, "[info]:");
break;
}
m_count++; //日志行数+1
if (m_today != my_tm.tm_mday || m_count % m_split_lines == 0) //如果创建时间!=当前时间或者行数达到上限
{
char new_log[256] = { 0 }; //新日志的文件名
fflush(file);
fclose(file);
char time_now[16] = { 0 }; //格式化当前的时间
snprintf(time_now, 16, "%d_%02d_%02d_", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday);
if (m_today != my_tm.tm_mday) //如果是创建时间!=今天
{
snprintf(new_log, 255, "%s%s%s", dir_name, time_now, log_name);
m_today = my_tm.tm_mday; //更新创建时间
m_count = 0; //更新日志的行数
}
else //如果是行数达到文件上限
{
snprintf(new_log,255,"%s%s%lld_%s", dir_name, time_now, m_count / m_split_lines,log_name);//加上版本后缀
}
file = fopen(new_log, "a");
}
int n = snprintf(m_buf, 48, "%d-%02d-%02d %02d:%02d:%02d %s",
my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday,
my_tm.tm_hour, my_tm.tm_min, my_tm.tm_sec,level_s);
int m = snprintf(m_buf + n, m_log_buf_size-n-1,"%s",str);
m_buf[n+m] = '\n';
m_buf[n+m+1] = '\0';
fputs(m_buf, file);
}
main.cpp:
#include
#include"Log.h"
int main()
{
Log::getinstance()->init("Log\\log.txt");
Log::getinstance()->write_log(0,"Hello World");
Log::getinstance()->write_log(1,"Hello World");
Log::getinstance()->write_log(2,"Hello World");
Log::getinstance()->write_log(3,"Hello World");
}
运行结果:

如图:日志信息前面已经加上了时间和类别分级,增加了可读性
同步和异步两种写入方式
同步写入和异步写入的逻辑:
图片来自公众号:两猿社

我先说明一下同步和异步的特点:
同步可以理解为顺序执行,而异步可以理解为并行执行
比如说吃饭和烧水两件事,如果先吃饭后烧水,这种是同步执行
如果说一边吃饭一边烧水,这种就是异步执行
那么同步执行和异步执行有什么优点,又使用在什么场景之下呢?
同步:
- 当对写入顺序和实时性要求很高时,例如需要确保按照特定顺序写入或写入即时生效的情况下,同步写入通常更合适。
- 在数据完整性和一致性很重要的情况下,同步写入能够提供更好的保证,避免数据丢失或不完整。
- 对于一些不频繁的、关键的写入操作,同步写入方式可能更容易确保操作的可靠性。
异步:
- 当写入频率很高或写入操作消耗较多时间时,使用异步写入可以显著提升系统性能和响应速度。
- 对于写入操作对主线程影响较大,容易阻塞主线程的情况下,通过异步写入可以将写入操作移到独立的线程中处理,减少主线程负担。
- 在需要降低I/O操作的影响、提高系统吞吐量和并发能力的场景下,异步写入方式更为适宜。
然后说一下如何实现同步和异步
同步只需要正常写入就行了
而异步我们可以借助生产者-消费者模型,由子线程执行写入操作.
如果你想了解生产者-消费者模型,请点击链接
生产者-消费者模型
接下来给出带有同步和异步两种写入方式的日志实现,还是在之前代码的基础上改动
封装了生产者-消费者模型的阻塞队列类:
#ifndef BLOCK_QUEUE_H
#define BLOCK_QUEUE_H
#include
#include
#include
#include //包含时间和定时器的头文件!
#include "../lock/locker.h"
using namespace std;
template
class block_queue
{
public:
block_queue(int max_size = 1000)
{
if (max_size <= 0)
{
exit(-1);
}
m_max_size = max_size;
m_array = new T[max_size];
m_size = 0;
m_front = -1;
m_back = -1;
}
void clear()
{
m_mutex.lock();
m_size = 0;
m_front = -1;
m_back = -1;
m_mutex.unlock();
}
~block_queue()
{
m_mutex.lock();
if (m_array != NULL)
delete [] m_array;
m_mutex.unlock();
}
//判断队列是否满了
bool full()
{
m_mutex.lock();
if (m_size >= m_max_size)
{
m_mutex.unlock();
return true;
}
m_mutex.unlock();
return false;
}
//判断队列是否为空
bool empty()
{
m_mutex.lock();
if (0 == m_size)
{
m_mutex.unlock();
return true;
}
m_mutex.unlock();
return false;
}
//返回队首元素
bool front(T &value)
{
m_mutex.lock();
if (0 == m_size)
{
m_mutex.unlock();
return false;
}
value = m_array[m_front];
m_mutex.unlock();
return true;
}
//返回队尾元素
bool back(T &value)
{
m_mutex.lock();
if (0 == m_size)
{
m_mutex.unlock();
return false;
}
value = m_array[m_back];
m_mutex.unlock();
return true;
}
int size()
{
int tmp = 0;
m_mutex.lock();
tmp = m_size;
m_mutex.unlock();
return tmp;
}
int max_size()
{
int tmp = 0;
m_mutex.lock();
tmp = m_max_size;
m_mutex.unlock();
return tmp;
}
//往队列添加元素,需要将所有使用队列的线程先唤醒
//当有元素push进队列,相当于生产者生产了一个元素
//若当前没有线程等待条件变量,则唤醒无意义
bool push(const T &item)
{
m_mutex.lock();
if (m_size >= m_max_size) //这里没考虑生产者必须在不空的情况下需要等待的问题
{
m_cond.broadcast();
m_mutex.unlock();
return false;
}
m_back = (m_back + 1) % m_max_size;
m_array[m_back] = item;
m_size++;
m_cond.broadcast();
m_mutex.unlock();
return true;
}
//pop时,如果当前队列没有元素,将会等待条件变量
bool pop(T &item)
{
m_mutex.lock();
while (m_size <= 0)
{
if (!m_cond.wait(m_mutex.get()))
{
m_mutex.unlock();
return false;
}
}
m_front = (m_front + 1) % m_max_size;
item = m_array[m_front];
m_size--;
m_mutex.unlock();
return true;
}
private:
locker m_mutex;
cond m_cond;
T *m_array;
int m_size;
int m_max_size;
int m_front;
int m_back;
};
#endif
注意: 这个生产者消费者模型并没有考虑生产者必须要在不满的情况下才能生产这一情况,不过这样也能凑活用,先凑活看吧
Log.h:
#pragma once
#include
#include
#include
#include
using namespace std;
class Log
{
private:
Log() ;
~Log();
//异步写入方法:
void* async_write_log()
{
string single_log;//要写入的日志
while (m_log_queue->pop(single_log))
{
m_mutex.lock();//互斥锁上锁
fputs(single_log.c_str(), file);
m_mutex.unlock();//互斥锁解锁
}
}
public:
//初始化文件路径,日志缓冲区大小,文件最大行数,阻塞队列长度(如果阻塞队列长度为正整数,表示使用异步写入,否则为同步写入)
bool init(const char* file_name, int log_buf_size = 8192, int split_lines= 5000000,int max_queue_size=0);
//新增了一个日志分级
void write_log(int level,const char* str);
//公有的异步写入函数,作为消费者线程的入口函数
static void* flush_log_thread(void *args)
{
Log::getinstance()->async_write_log();
}
static Log* getinstance();
private:
FILE* file;
char dir_name[128];//路径名
char log_name[128];//日志名
int m_split_lines; //日志文件最大行数
long long m_count; //日志当前的行数
int m_today; //日志创建的日期,记录是那一天
int m_log_buf_size; //日志缓冲区的大小,用来存放日志信息字符串
char* m_buf; //日志信息字符串;因为后续要把时间和日志分级也加进来,所以开一个新的char *
block_queue* m_log_queue; //阻塞队列,封装生产者消费者模型
bool m_is_async; //异步标记,如果为true,表示使用异步写入方式,否则是同步写入方式
locker m_mutex; //互斥锁类,内部封装了互斥锁,用来解决多线程竞争资源问题
};
Log.cpp
#define _CRT_SECURE_NO_WARNINGS
#include"Log.h"
// pthread,mutex等需要在Linux下使用相关的头文件才能使用,因为我是windows环境就暂时不加了.
Log::Log()
{
m_count = 0;
m_is_async = false;
}
Log::~Log()
{
if (file != NULL)
{
fflush(file);
fclose(file);
}
if (m_buf != NULL)
{
delete[] m_buf;
m_buf = nullptr;
}
}
Log* Log::getinstance()
{
static Log instance;
return &instance;
}
bool Log::init(const char * file_name, int log_buf_size , int split_lines,int max_queue_size)
{
if (max_queue_size >= 1)
{
//设置写入方式flag
m_is_async = true; //设置为异步写入方式
//创建并设置阻塞队列长度
m_log_queue = new block_queue(max_queue_size);
pthread_t tid;
//flush_log_thread为回调函数,这里表示创建线程异步写日志
pthread_create(&tid, NULL, flush_log_thread, NULL);
}
m_log_buf_size = log_buf_size;
m_buf = new char[m_log_buf_size];
memset(m_buf,'\0', m_log_buf_size);// 开辟缓冲区,准备存放格式化的日志字符串
m_split_lines = split_lines; //设置最大行数
time_t t = time(NULL);
struct tm* sys_tm = localtime(&t);
struct tm my_tm = *sys_tm; //获取当前的时间
const char* p = strrchr(file_name, '\\');
char log_full_name[256] = { 0 };
if (p == NULL)
{
snprintf(log_full_name, 255, "%d_%02d_%02d_%s", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, file_name);
strcpy(log_name, file_name);
}
else
{
strcpy(log_name, p + 1);
strncpy(dir_name, file_name, p - file_name + 1);
//规范化命名
snprintf(log_full_name,255, "%s%d_%02d_%02d_%s", dir_name, my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, log_name);
}
m_today = my_tm.tm_mday; //更新日志的创建时间
file = fopen(log_full_name,"a"); //打开文件,打开方式:追加
if (file == NULL)
{
return false;
}
return true;
}
void Log::write_log(int level,const char* str)
{
if (file == NULL)
return;
time_t t = time(NULL);
struct tm* sys_tm = localtime(&t);
struct tm my_tm = *sys_tm; //获取当前的时间,用来后续跟日志的创建时间作对比
char level_s[16] = { 0 }; //日志分级
switch (level)
{
case 0:
strcpy(level_s, "[debug]:");
break;
case 1:
strcpy(level_s, "[info]:");
break;
case 2:
strcpy(level_s, "[warn]:");
break;
case 3:
strcpy(level_s, "[erro]:");
break;
default:
strcpy(level_s, "[info]:");
break;
}
m_mutex.lock(); //互斥锁上锁
m_count++; //日志行数+1
if (m_today != my_tm.tm_mday || m_count % m_split_lines == 0) //如果创建时间!=当前时间或者行数达到上限
{
char new_log[256] = { 0 }; //新日志的文件名
fflush(file);
fclose(file);
char time_now[16] = { 0 }; //格式化当前的时间
snprintf(time_now, 16, "%d_%02d_%02d_", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday);
if (m_today != my_tm.tm_mday) //如果是创建时间!=今天
{
snprintf(new_log, 255, "%s%s%s", dir_name, time_now, log_name);
m_today = my_tm.tm_mday; //更新创建时间
m_count = 0; //更新日志的行数
}
else //如果是行数达到文件上限
{
snprintf(new_log,255,"%s%s%lld_%s", dir_name, time_now, m_count / m_split_lines,log_name);//加上版本后缀
}
file = fopen(new_log, "a");
}
m_mutex.unlock(); //互斥锁解锁
string log_str;
m_mutex.lock();
//格式化
int n = snprintf(m_buf, 48, "%d-%02d-%02d %02d:%02d:%02d %s",
my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday,
my_tm.tm_hour, my_tm.tm_min, my_tm.tm_sec,level_s);
int m = snprintf(m_buf + n, m_log_buf_size-n-1,"%s",str);
m_buf[n+m] = '\n';
m_buf[n+m+1] = '\0';
log_str = m_buf;
m_mutex.unlock();
//如果是异步的写入方式
if (m_is_async && !m_log_queue->full())
{
m_log_queue->push(log_str);
}
else//如果是同步的写入方式
{
m_mutex.lock();
fputs(log_str.c_str(), file);
m_mutex.unlock();
}
}
日志系统先介绍到这里,我介绍的日志系统还是属于功能比较稀缺,实际使用上可能远远比这复杂,如果想使用日志系统,可以以文章介绍的为雏形继续添加新功能.
本文中代码非常可能有错误,如果发现有错误,烦请评论区指正,我会及时修改.