【知识图谱论文】知识图谱自主构建综述A Comprehensive Survey on Automatic Knowledge Graph Construction
0.论文摘要和作者信息
摘要
自动知识图谱构建旨在制造结构化的人类知识。为此,历史上花费了大量的努力从不同的数据源中提取信息丰富的事实模式。然而,最近,研究兴趣已经转移到获取信息数据之外的概念化结构化知识。此外,研究人员也一直在探索在各种情况下处理复杂建筑任务的新方法。因此,有必要对范式进行系统审查,以组织超越数据级提及的知识结构。为了满足这一需求,我们全面调查了300多种方法,总结了知识图谱构建的最新进展。知识图谱分三步构建:知识获取、知识提炼和知识进化。详细回顾了知识获取的过程,包括获取具有细粒度类型的实体及其与知识图谱的概念链接;解析共指;以及在复杂场景中提取实体关系。该调查涵盖了知识细化模型,包括知识图谱完成和知识融合。系统地提出了处理知识进化的方法,包括条件知识获取、条件知识图谱完成和知识动态。我们提出了一些范例,沿着数据环境、动机和架构的轴线来比较这些方法之间的区别。此外,我们还提供了可访问资源的简介,可以帮助读者开发实用的知识图谱表系统。调查最后讨论了今后勘探的挑战和可能的方向。
知识图谱,深度学习,信息抽取,知识图谱补全,知识融合,逻辑推理
作者信息
LINGFENG ZHONG, Macquarie University, Australia
JIA WU, Macquarie University, Australia
QIAN LI, Beihang University, China
HAO PENG, Beihang University, China
XINDONG WU, Hefei University of Technology, China
1.研究背景
知识图谱(kg)为搜索引擎[1]、推荐系统[2]和问答[3]等应用程序提供了组织良好的人类知识。
许多著名的大型KG系统都是通过众包构建的,比如Freebase[4]和Wikidata[5]。因此,可以从非结构化或半结构化数据中自动构建知识图谱的系统解决方案为非常艰巨的实际手动过程提供了巨大的推动力。知识图谱是由描述真实世界对象知识的边和节点组成的语义图。在这些结构中,知识元组是最小的知识携带组。元组包括表示由表示关系的边连接的概念的两个节点。因此,构建知识图谱的任务是发现特定领域或开放领域中构成知识图谱的元素。在这一学科研究的早期,研究人员主要专注于从半结构化或非结构化的文本数据中抓出事实元组,作为模式化知识的提及。像TextRunner[6]和Knowitall[7]这样的信息提取系统是早期知识图谱构建的里程碑,由指定的规则或聚类驱动。不幸的是,这些设计没有充分配备背景知识,因此遭受两个主要缺陷:1)非实体的、传统的信息提取系统不能从不同的表达式中创建或区分实体,这阻止了知识聚合;2)传统的信息提取系统仅从句法结构中提取信息,而没有捕获给定表达式中的语义外延。此外,传统的基于规则的信息提取系统也需要大量的特征工程和额外的专家知识。吴等人[8]指出,如果一个KG系统没有用关于概念的背景知识来组织节点和边,它仅仅是一个数据图。
关于这个问题,研究人员然后求助于良好划分的习得子任务来安排语义知识结构。最经典的范例是管道,它首先发现和链接概念实体,解析共指提及,然后提取实体之间的关系。图1显示了知识图谱构造的一般过程。
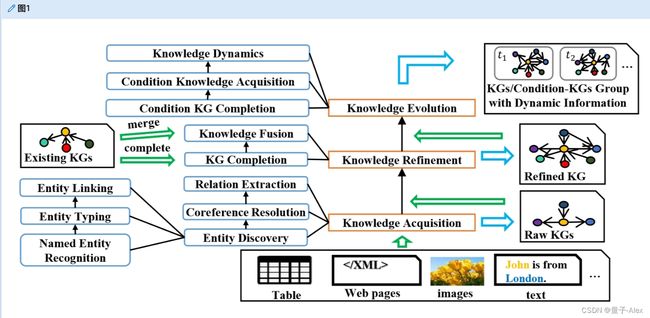
图1。构建知识图谱的一般过程。在该图中,半结构化或非结构化输入数据通过获取知识被制造成原始知识图谱。然后将知识细化以完成知识图谱或用其他已有的知识图谱来丰富它。如果输入只是一个现有的知识图谱,它将由知识细化过程直接处理。最后,知识进化过程将试图获得一组知识图谱/条件知识图谱,其中包含关于图进化的动态信息。
近年来,深度学习方法在自然语言处理(NLP)领域取得了巨大突破,这些突破推动了知识图谱的应用一系列方面的建设。许多深度学习模型在命名实体识别[9]、[10]、实体类型[11]、[12]、实体链接[13]、[14]、共指解析[15]、关系提取[16]、[17]等任务中表现良好。此外,还开发了深度知识表示模型,可以细化知识图谱。改进包括完成损坏的元组,通过其内部图结构在构建的知识图谱中发现新的元组,以及合并来自不同来源的图以构建新的知识图谱。目前,许多知识库1,如TransOMCS[18]、ASER[19]和huapu[20]已经将自动KG构造方法付诸实践。
此外,随着深度学习模型预训练的进步,如预训练的BERT模型[21]和一些大规模图形卷积网络(GCN)模型,KG构建任务正在应用于大数据环境中更复杂的场景。除了处理异构数据(如网页和表格)的系统之外,人们越来越关注处理复杂数据的有效方法,例如,联合统一多个采集子任务或解决方案,从长期环境[22]、噪声数据[23]或低资源数据[24]中获取知识图谱。在知识图谱细化任务方面,可解释推理已经成为一种流行趋势。研究人员正在寻求融合跨语言知识的解决方案,并通过逻辑和推理在节点之间导出新的关系。研究人员还关注条件知识的知识图谱,如时间知识图谱[25]和一般条件知识图谱[26]。主动学习[27],它向人类用户询问未知的有价值的收集数据是处理自治区知识的另一个重要方向。吴等[28]利用HACE定理总结大数据环境中知识发现所面临的挑战,如图2所示。

图二。HACE环境所构成的挑战的例证。就异构数据而言,第4节概述了半结构化和非结构化数据的知识图谱构建。第5节详细介绍了改进现有知识图谱的方法。获取时态数据的方法在6.1中描述。第8.2节讨论了多模态知识图谱。就复杂数据而言,第4.1.2、4.2、4.3.6节讨论了长期环境及其与多KG施工任务的关系。处理噪声数据的方法主要在4.3.3节中介绍。第5.1.3节介绍了模型的可解释性。就进化数据而言,第6节介绍了知识进化方面的最新工作,第8.5节讨论了自主数据的研究。
1.1 主要差异和贡献
许多调查提供了知识图谱表及其应用的概述。比如霍根等人。[29]为知识图谱提供了一个百科全书式的调查,而Paulheim[30]研究了提炼和填充知识图谱的方法。其他调查总结了从非结构化或半结构化数据中获取知识的方法。吴[31]回顾了KG构建子任务相对于文本的竞争工具和模型,包括关系提取、命名实体识别和共指消解,而Yan[32]浏览不同数据类型的方法,如网页、表格等。在[33]、[34]中回顾了用于联合提取实体及其关系的深度学习方法。一些调查还侧重于从现有的知识图谱表中获取知识。先前的工作如[35]和[36]也涵盖了知识表示学习和知识图谱完成的方法,而蔡等[37]深入研究时间知识图谱。表1比较了以前的工作和这次调查。与其他调查不同,我们更深入地研究了知识图谱构建的最新模型的范式,根据HACE环境的不同阶段和方面安排了我们的工作。我们还提供实用资源,并讨论数据、模型和架构的未来挑战和方向。因此,我们的贡献概述如下:

•我们通过给出正式的定义和分类,介绍了知识图谱的构建过程和各种知识图谱。我们还总结了KG相关资源的必要信息,包括实用的知识图谱项目和构建工具,涵盖出版年份、引用和访问链接,供读者比较。
•根据任务背景和挑战,全面分析从知识获取到知识图谱细化的不同场景下的知识图谱构建模型。我们总结了经典和新颖模型的动机和设计,然后主要描述了它们的架构和改进的语用学。
•我们讨论了HACE大数据环境中的知识图谱构建,包括嘈杂的文档级数据和低资源数据。然后,我们回顾了在获取模型可解释性和进化条件知识方面的成就。最后,我们总结了影响KG建设任务的主要挑战和方向。
1.2 综述的组织
我们的调查组织如下。第2节给出了知识图谱构建的背景,包括KG项目的定义和资源。第3节提供了预处理半结构化数据的方法,包括内容提取和结构解释。第4节介绍了处理从各种数据类型和环境中获取实体和关系的任务的方法。第5节回顾了用外部结构化数据细化知识图谱的方法。我们描述了进化知识图谱的最新成就和趋势,包括第6节中的条件知识图谱和时间知识图谱。第7节提供了有效存储知识图谱的解决方案。最后,我们在第8节展望未来的方向和发展,同时在第9节结束这篇文章。
2.背景
2.1 定义
已经为正式定义知识图谱做出了许多贡献。王等[38]将知识图谱建模为多关系图,其中节点是实体,边代表不同类型的关系。然而,以前的定义没有考虑知识图谱中的语义结构。Ehrlinger和Wo β[39]进一步强调,知识图谱将信息排列成一个本体,然后用“推理器”启发新的知识发现。为了具体突出支持知识级信息的本质成分,吴等[31]将知识图谱定义为语义图,其中节点表示概念(实体/属性/事实),边表示连接节点的关系,同时利用关于概念和关系的背景知识。
2.1.1 定义1(知识图谱)
知识图谱 G \mathcal{G} G定义为 G = { E , R , T , F k } \mathcal{G}=\{\mathcal{E},\mathcal{R},\mathcal{T},\mathcal{F_k}\} G={E,R,T,Fk},其中 E \mathcal{E} E和 R \mathcal{R} R分别表示概念和关系的集合。在本文中,概念可以被视为实体/属性。\mathcal{T}是事实三元组的集合,其中标准的二元事实是三元组 ( h , t , r ) ∈ T (h, t, r ) ∈ \mathcal{T} (h,t,r)∈T, h , t ∈ E , r ∈ R h, t ∈ \mathcal{E}, r ∈ \mathcal{R} h,t∈E,r∈R,n元关系三元组将形成为 ( e 1 , . . . , e n , r ) (e_1, ..., e_n, r ) (e1,...,en,r),其中 e 1 , . . . , e n ∈ E e_1,...,e_n∈\mathcal{E} e1,...,en∈E. F k \mathcal{F_k} Fk是一个集合函数,表示将潜在事实约束为知识级信息的背景知识,我们有 T ∈ F k ( { E , R } ) \mathcal{T}∈\mathcal{F_k}(\{\mathcal{E},\mathcal{R}\}) T∈Fk({E,R})。在实践中,背景知识可以被视为一个规则集、图式或一组隐含的数学原则。
2.1.2 定义2(知识图谱构造)
知识图谱构造 f f f是将数据源映射到知识图谱的过程: f : D × f k ( D ) → G f : D × f_k (D) → \mathcal{G} f:D×fk(D)→G,其中 D D D是数据源的集合, f k ( D ) f_k (D) fk(D)是数据目标的背景知识,可以是领域知识。值得注意的是,如果没有由预先设计的规则或表示的语言模型提供的背景知识,知识图谱的构建通常无法继续。
2.2 实用知识图谱项目
在本节中,我们回顾了知识图谱的代表性实践项目(数据集),包括百科全书知识图谱、语言知识图谱、常识知识图谱、企业支持知识图谱、特定领域知识图谱和联邦知识图谱。详情见表2。

2.2.1 百科全书知识图谱
百科全书知识图谱系统地涵盖了来自不同领域的事实或事件知识。许多研究人员已经从手工构建的在线百科全书中开发了知识图谱结构。例如,DBpedia[40](从维基百科开发而来)是一个基本的百科全书知识图谱,而Freebase[4]结合了自动提取工具,以获得更多的内容。Probase[41](由微软概念图支持)作为事件百科全书知识图谱,创造性地以概率模型的形式描绘了包含冲突信息的不确定事件的知识。XLore[42](THUKC的子项目)作为多语言百科全书知识图谱,通过深度学习方法建立跨多语言内容的实体链接。在DBpedia项目早期尝试整合自动提取工具后,更多的知识图谱项目决定做同样的事情,包括Wikidata[5]和CN-DBpedia[43]。马克斯·普朗克研究所开发了YAGO[44],它将维基百科中的时间和地理结构与WordNet本体集成在一起。明茨等人。[45]将距离监督应用于Freebase,用于自动注释实体关系。研究界也一直关注可能性的知识图谱表。例如,CN-Probase[46]用中文概念扩展了Probase,以理解涉及不确定事件的文本数据的一般模式。
2.2.2 语言知识图谱
语言知识图谱提供人类语言的知识,以提供作为本体或外部特征的基本语义。WordNet[47]是一个广泛用于语言学研究的经典知识图谱词典,提供单词之间的同义词或下义关系。使用这些工具,开发人员可以根据构建良好的语言知识图谱为下游应用程序创建高性能的单词嵌入。除了WordNet,BabelNet[48]用百科全书中单词的跨语言属性和关系扩展了WordNet。ConceptNet[49]作为Link Open Data的一部分,基于crown sourcing收集概念知识,而HowNet[50]手动收集关于单词概念和属性的语义信息(最小不可分割语义单元)。THUOCL[51]记录了来自过滤良好的网络语料库的单词的文档频率。开发人员还为下游应用程序创建了基于良好构建的语言知识图谱的高性能单词嵌入。
2.2.3 企业支持知识图谱
知识图谱及其相关系统已经有效地支持了企业的业务活动。谷歌知识图谱(GKG)[53]自2012年以来一直作为核心功能,为用户查询提供知识支持,并用更多语义相关的内容丰富结果。Facebook Graph Search 2是Facebook强大的语义搜索引擎,提供通过脸书社交系统中的动态知识库获得用户特定的答案。与GKG类似,脸书图形搜索提供了脸书强大的语义搜索引擎,通过动态的脸书社交知识库提供用户特定的答案。
2.2.4 常识知识图谱
常识知识图谱描绘了普遍接受的常识知识。OpenCyc[52]是这些尝试中最早的一个,它以CycL的形式对知识概念、规则和常识思想进行编码。除了OpenCyc,ASER[19]还提供了一个加权知识图谱,通过对这些对象之间的动作、状态、事件和关系的实体进行建模来描述常识,这些实体通过依赖模式选择获得其节点,并由Probase概念化。TransOMCS[18]开发了一个自动生成的数据集,涵盖了从语言图中获得的20个常识性关系。
2.2.5 特定领域知识图谱
研究人员还汇集特定的知识,为多个专业研究领域服务。至于生物医学领域,Pubmed[54]提供了Pubmed中心发布的开放生物医学文献数据库,而Durgbank[55]提供了对蛋白质和药物信息的药理学洞察。许多KG收集工作也有助于抗击新冠肺炎疫情,如新冠肺炎概念数据集3和阿米纳新冠肺炎开放数据4。至于学术活动,AMiner[56]的学术社交网络(ASN)通过包含论文和引用关系的网络公开了学者及其学术活动。类似地,开放学术图(OAG)[57]提供了具有纸质数据的集成学术社交网络。创造性地,华普[20]从数字化的数千本祖先家谱书籍中构建了一个高质量的中国家谱语义网络,同时通过融合多个网络源建立了不同家谱中相同人之间的关系链接。
2.2.6 联邦知识图谱
对于拥有来自不同提供商的大量用户数据的知识库来说,隐私保护起着至关重要的作用,而收集多源KG数据的知识社区拥有丰富的特征,这些特征可以统一起来构建集成的知识模型。提出了联合学习来将来自不同数据提供者的子KG特征与防止数据交换的保护相结合。联邦策略已经应用于具有敏感数据的KG系统。GEDmatch5是一个系谱KGs,收集用户提供的信息用于查询DNA,同时分发一个联合知识模型来探测数据跟踪。联邦策略已经应用于许多具有敏感数据的知识图谱系统。这有助于建立综合知识模型,同时防止数据交换。研究人员还关注联合知识图谱平台。OpenKG.cn[58]是一个众包社区,它提供了一个知识共享平台,通过联合学习开发知识应用,同时支持知识区块链的去中心化。
2.3 知识图谱构建工具
在本节中,我们回顾了一些常用于构建知识图谱的工具。这些工具主要支持构建子任务,如预处理、知识获取和知识细化。这些工具的详细信息如表3所示。
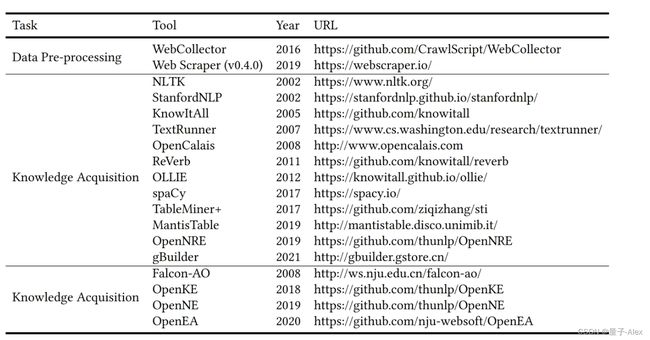
2.3.1 数据预处理
数据预处理任务去除广告等噪音。例如,WebCollector[59]是一个代表性的数据预处理工具包,它可以自动过滤非内容噪音,如广告和布局信息,同时通过集成算法保留页面内容。许多网络爬虫还支持提取信息结构或内容的数据预处理任务。除了WebCollector,Web Scraper 6是一个用户友好的手动提取工具,用于收集多个网页。它提供了一个用户界面来保存集中的web结构,并提供了一个云服务器来提取大量内容。
2.3.2 知识获取
早期的知识获取工具包通过规则、模式和统计特征直接提取事实三元组。这些工具包也被称为信息提取工具包。除了KnowItAll[7],其他工具包,如TextRunner[6],ReVerb[60],利用半监督设计来收集关系信息。这些工具通过句法和词汇信息产生精炼的动词三元组。此外,还有OLLIE[61]支持非语言三元组的发现。许多NLP应用程序可以直接执行知识获取子任务,包括命名实体识别、关系提取和共指消解任务,或者它们可以为相关应用程序提供语言特征。NLTK[62]和StanfordNLP[63]是基于条件随机场和MEM等统计算法的强大知识获取工具包。这些工具还可以提供后台功能,如POS标记和NP块。同时,TableMiner+[64]和MantisTable[65]从半结构化的表格形式中提取知识。
最近,开发人员被吸引到基于深度学习的工具包中。例如,spaCy[66]是一个全面实用的NLP工具包,它集成了NeuralCoref用于共指解析任务,还提供了一个可训练的深度学习模块用于专门的关系提取(在spaCy v3中)。OpenNRE[67]提供了各种可扩展的神经网络模型,如CNN和LSTM,以执行监督关系提取。深度学习工具包为用户提供了高性能的技术。对于工业应用,用户可以通过OpenCalais 7定制他们的知识获取解决方案。此外,gBuilder 8是基于用户选择的神经网络的具有里程碑意义的端到端解决方案还支持主动学习界面以优化性能的架构。gBuilder可以直接从输入的非结构化数据中输出原始知识图谱。
2.3.3 知识提炼
知识提炼工具通过完成现有的原始知识图谱或将其与其他知识图谱合并来细化现有的原始知识图谱。基于深度学习的工具是流行的解决方案。例如,OpenKE[68]为知识图谱的完成提供了多种知识表示模型,而OpenEA[69]利用类似的方法来合并知识图谱中的结构。除了集成的深度学习工具包OpenKE和OpenEA,OpenNE9还集成了Node2VEC[70]和LINE[71]等嵌入模型,从完整的知识图谱中生成全局表示。在知识融合(合并)任务方面,Falcon-AO[72]使用多种算法来测量语义相似性,以便以不同的符号对齐概念。
3.半结构化数据预处理
真实世界的原始数据源包含多结构内容,不相关的部分削弱了知识提取的效果。数据预处理对于处理混乱的数据环境是必要的。预处理子任务主要包括内容提取和结构解释。
3.1 内容提取
许多网页包含非内容噪音,如广告。内容提取任务旨在删除这些不相关的元素,同时保留知识内容。用户可以手动选择网页的主要部分,例如由“< table >”包围的内容,通过诸如JSoup、BeautifulSoup和Web Scraper之类的网络爬虫来实现这一目标,这些爬虫检索和解释文档对象模型(DOM)结构中的元素,然后用户可以选择网页的主要部分。然而,当数据量很大时,手动工作将无法处理它们。主流的自动内容抽取方法主要有基于包装的方法和基于统计的方法。基于包装的方法是检测主要内容的最早尝试,它利用匹配规则来捕获信息内容。从半结构化页面自动生成规则的现成包装工具包括IEPAD[73]、SoftMealy[74]。自举方法通过种子示例迭代地增强提取模板,例如[75]和[76]。一些工具包提供用户界面来优化提取模板,如NoDoSE[77]和DEByE[78]。基于模板的包装器易于理解,并在页面结构格式良好的情况下实现可行的结果,但无法掌握复杂的新颖元素或结构所覆盖的内部内容。
用户还可以利用基于网页统计特征的方法来获得信息内容。Finn等人[79]提出了一个经验假设,即网页中的信息子序列包含足够多的单词和最少的标签。许多模型考虑web内容的统计特征来提取信息内容,例如CETR[80](文本长度与标签数量的比率)、CETD[81](DOM树的每个子树结构中的文本密度)和CEPR[82](web链接的路径比率)。用户可以利用WebCollector[59]集成基于统计的模型进行内容提取。另一个启发式的研究方向是基于视觉特征的方法。例如,VIPS[83]利用页面的视觉外观(如字体和颜色类型)来构建用于内容提取的内容结构树。当在半结构化页面上执行内容提取时,用户将获得更新的无噪声半结构化或非结构化文档。
3.2 结构解释
网页中的许多表格形式充当内容的导航器或样式格式的容器(由内容提取器处理),不包含任何关系结构。模型应该在获得关系信息之前过滤这些装饰性的非关系web表结构。关系表解释是一项二进制分类任务,用于确定表是否具有信息性。方法分析表结构的语义特征进行分类。王和胡[84]设计了一个基于布局和内容类型特征的集成了支持向量机(SVM)和决策树的表分类器。类似地,WebTables[85]开发了一个基于表格大小(行数和列数)和标签的基于规则的分类器。埃比留斯等人。[86]利用表格矩阵的特点开发一个分类系统DWTC。许多web表也包含数据噪声。OCTOPUS[87]进一步将数据清理与表分类任务结合起来,以过滤信息丰富的表。开发表格解释模型包括两个步骤:首先选择表格形式中的特征,然后集成学习模型来分析数据中的关系语义。我们建议读者参考[88]以获得更多的表语法特性和高性能模型集成。
4.知识获取
知识获取是从多结构数据中收集元素以构建知识图谱的一般过程。它包括实体识别、共指分解和关系提取。实体识别任务发现数据中的实体提及。然后,共同引用解析任务定位被引用的提及对,接着是关系提取任务,将实体与其语义关系联系起来。
4.1 实体发现
实体发现从半结构化或结构化数据中获取概念的子集,这些数据可以构成知识图谱的节点。实体发现的一般过程包括命名实体识别、实体类型和实体链接任务。命名实体识别任务发现引用语义实体的字符串,然后将它们分类到一般类型(例如,人、位置、国家、公司)。实体键入任务将找到的实体分类为特定类型(例如,演员、艺术家、品牌)。实体链接将发现的实体与知识图谱中的可能节点相关联。如果没有可用于链接的节点,将创建相应的实体节点来表示新找到的实体。图3描绘了一般过程的概述。

4.1.1 半结构化数据与非结构化数据中的命名实体识别
命名实体识别任务用位置和分类标记半结构化或非结构化数据中的命名实体。半结构化数据被与属性——属性结构相关的语义提示所包围,而非结构化数据只包含文本。基于规则的方法[89]是NER的一般解决方案。对于半结构化web数据,包装器归纳生成规则包装器来解释半结构,如DOM树节点以及用于从页面中获取实体的标记。一些基于规则的解决方案是无监督的,不需要人工注释,如Omini[90]。至于表格形式的实体,基于维基百科的属性——属性布局提出了许多方法,如DBpedia的基于规则的工具[40]、[44]和YAGO。对于非结构化数据,经典的NER系统[91]也依赖手动构建的规则集进行模式匹配。开发半监督方法是为了通过模式种子和评分迭代生成精炼的新模式来改进基于规则的NER,例如基于自举的NER[92]。
基于统计的方法将命名实体识别视为顺序分类标记任务,根据BIES方案(开始、中间、结束、单个)及其类型标记实体。对于非结构化命名实体识别,关键假设是每个单词的标签只依赖于前面的单词。因此,建立在隐马尔可夫模型[93]和条件随机场(CRF)模型[94]上的应用程序,捕捉邻域依赖性,是流行的NER设计。对于半结构化的表格数据,研究人员经常使用CRF变体来处理与实体相关的属性的二维特征,如2D-CRF[95]。因此,它们提取2D结构中每个实体的多个属性。动态条件随机场(DCRF)[96]通过动态贝叶斯网络推断潜在的属性——实体相互作用,分层CRF[97]将半结构化数据建模为分层树以进行联合提取。此外,Finn和Kushmerick[98]开发了一个基于SVM的模型来定位文本中实体的边界。
深度学习也正在成为命名实体识别的流行趋势,尤其是文本命名实体识别。这些深度学习方法通常将命名实体识别视为seq2seq模型(单词序列到标签序列)。这些模型根据输入聚合上下文嵌入,然后上下文编码器通过标签解码器输出单词类型标签,例如CRF结构或softmax结构[99]。CNN结构主要关注用于捕获实体的局部特征。科洛贝特等[100]是第一个使用带有CRF输出层的CNN作为实体检测的统一解决方案的。IDCNN等[101]在CNN的基础上改进了扩张卷积,通过省略一些输入来增强泛化,从而扩大了感知场。RNN结构可以更好地消化长句中的全局上下文特征,例如[102]中提出的用于生物医学实体识别的单向RNN。然而,RNNs可能会受到后面即将出现的单词的上下文偏差[9]。因此,许多模型考虑双向RNNs,如[9]中基于双LSTM-CRF的模型和[103]中基于GRU的NER模型。字符和单词编码器的组合也是广泛应用的结构,例如包括用于字符嵌入的CNN和用于单词嵌入的LSTM的结构[10]。基于深度学习的NER模型的标准架构如图4所示。

图4。基于深度学习的命名实体识别的标准架构图示。当输入一个句子时,这种NER模型将输出带有位置信息和粗略实体分类的标记实体词。
另一个为全球环境投射显著互动的方向是注意机制。罗等[104]引入单词级软注意以增强命名实体识别。格雷戈里奇等[105]使用单词——单词自我注意进行命名实体识别。图卷积网络通常用于处理命名实体识别的语言图结构中的上下文。比如塞托利等[106]提出了一个GCN框架,该框架通过具有句法依赖树的GCN结构对LSTM-proceed特征进行编码。为命名实体识别任务的训练提供表示作为背景知识的预训练语言模型也在命名实体识别方面取得了突破。模型包括Elmo[107],Ltp[108],LUKE[109]。
4.1.2 实体类型
实体类型(ET)任务为科学家、俱乐部和酒店等实体提供细粒度和超粒度的类型信息。如果不执行ET任务,就会发生信息丢失,例如,唐纳德·特朗普是一名政治家和商人。半结构化表为标题中的细粒度类型提供了提示。例如,“英格兰的足球运动员”暗示足球运动员是实体。然而,在不同的上下文中为非结构化数据标记适当的细粒度实体类型可能是复杂的。深度学习方法解决了实体类型的两个主要挑战:1)不频繁的细粒度类型;和2)过于具体的类型。一些特定的类型可能是不平衡的或不频繁的。出于这个原因,Shimaoka等人[110]提出了一种基于LSTM的注意力神经网络,用于不频繁的实体分型,该网络依赖于与提及和上下文表示相结合的分层标签编码,以利用细粒度的上下文特征。过度特定的类型注释派生出正确的类型,但不适合当前的数据上下文。徐等人[11]将上下文外损失函数应用于具有多个标签的实体,用于过滤过度特定的数据噪声,该函数假设在训练期间得分最高的类型标签被正确标记。为了进一步探索上下文场景,张等人[111]引入了文档级表示,为发现提供了全局上下文。然后使用句子级别的上下文表示来对齐e相同的实体表征出现在不同的句子中。然后,自适应概率阈值生成不同上下文中实体类型的标签。图5示出了典型的基于深度学习的ET模型。

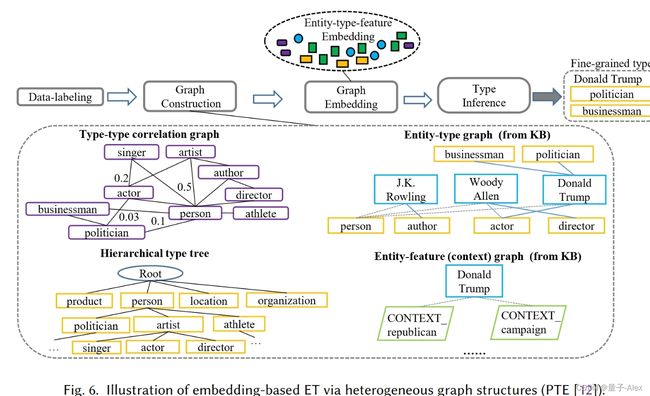
新的基于嵌入的模型利用结合全局图结构特征和背景知识来通过表示预测实体的潜在类型。研究人员报告说,经典的TransE模型在直接应用于ET任务时表现不佳。穆恩等人。[112]提出了TransE-ET模型,通过优化实体及其类型表示之间的欧几里德距离来调整TransE模型,该模型受到实体类型和三元组不足的限制特征。新的解决方案旨在构建各种图来共享实体相关对象的各种特征,以学习具有实体类型特征的嵌入。PTE[12]通过部分标签嵌入减少数据噪声,部分标签嵌入在实体及其所有类型之间构建两党图,同时将实体节点连接到其相关的提取文本特征。最后,PTE通过用导出的相关权重构建类型层次树来利用背景KG。JOIE[113]将实体节点嵌入本体视图图和实例图中,通过实体和类型候选之间的top-k排名来收集实体类型。同样,ConnectE[114]将实体映射到它们的类型上,学习知识使嵌入增加了三倍。改进ET任务在异构图上的嵌入的实用模型(在Xlore项目[42]中)还包括[115]、[116]、[117]。我们在图6中给出了用于嵌入基于模型的ET的图形结构。
4.1.3 半结构化数据与非结构化数据的实体链接
实体链接(EL)任务,也称为实体消歧,将实体提及链接到知识图谱中相应的对象。文本提及可以有不同的参考,例如,文本“Tesla”可以指汽车、公司或科学家。实体链接将不同数据背景中的提及与其各自节点的上下文信息连接起来。对于半结构化数据,实体链接使用来自列标题、类型标签、表格单元格文本和超链接的语义提示来标识实体。对于非结构化文本,实体链接模型关注实体提及的上下文表示。统计方法,尤其是基于概率图和SVM模型的方法,是半结构化和非结构化数据的通用解决方案。基于概率图的模型构造表中提及的概率图,然后通过计算节点的语义因子来链接实体。利马耶[118],例如,基于TF-IDF算法构建了用于集体实体链接的因子图,该算法计算具有单元格——文本对的实体标签和具有列——标题对的类型标签的术语频率。一些模型结合了外部知识库来改进实体链接任务。例如,TabEL[119]通过利用维基百科中的超链接来改进其因子图,以在集体分类消除歧义之前估计语义相关特征。吴等[120]提出加强实体链接的方法具有多个知识库中的“相同”边。埃夫蒂米乌等[121]系统地利用实体链接的语义特征。他们的方法集成了实体上下文的向量表示、最小实体上下文以及知识库和表格之间共享的示意图结构。SVM模型将实体链接视为分类任务。在这里,穆尔瓦德[122]开发一个基于SVMRanker的模型,该模型确定哪些潜在节点可以链接到目标实体。同样,郭等人。[123]提出了一个非结构化数据的概率模型,该模型在执行与非结构化数据的链接任务时利用实体、上下文和名称的先验概率。韩等[124]采用了实体的参考图,假设在相同文档中共同出现的实体应该在语义上相关。
基于嵌入的模型也是通过实体嵌入进行实体链接的关键解决方案。LIEGE[125]为网页的链接实体导出分布上下文表示。早期研究人员[126]利用词袋(BoW)进行实体提及的上下文嵌入,然后进行聚类以收集链接的实体对。后来,拉塞克等[127]将BoW模型扩展为EL任务的语言嵌入。研究人员还关注高性能链接的深度表示。DSRM[128]采用深度神经网络来利用语义相关性,将实体描述和关系与类型特征相结合,以获得用于链接的深度实体特征。EDKate[129]联合学习知识库和文本数据中实体和单词的低维嵌入,捕捉BoW模型之外的内在实体提及特征。此外,Ganea和Hofmann[13]引入了一种用于联合嵌入的注意机制,并通过语义交互来消除歧义。Le和Titov[14]对嵌入上下文中提及之间的潜在关系进行建模,利用提及和关系归一化对成对一致性评分函数进行评分。
4.1.4 其他进展
少数/零镜头实体类型是一个复杂的挑战性问题。马等[139]开发了原型HLE,该原型HLE为零射击细粒度ET任务的实体标签嵌入原型建模,将原型特征与分层类型标签相结合,用于推断新类型的基本特征。张等[140]进一步提出MZET,其利用上下文特征和具有记忆网络的单词嵌入来为少量实体类型提供语义侧信息。结合NER和EL任务的联合提取模型减少了基于流水线的实体识别任务的错误传播。NEREL[141]通过对提取的提及——实体对进行排序来耦合NER和EL任务,以利用实体提及及其链接之间的交互特征。图形模型也是组合NEN(命名实体规范化)标签的有效设计,该标签将实体提及转换为明确的形式,例如,Washington(Person)和Washington(State)。刘等[142]利用因子图模型将EL与NEN任务结合起来,形成单词实体类型及其目标节点的CRF链。同样,MINTREE[143]为集体任务引入了基于树的配对链接模型。
研究人员探索更多灵活NER任务的策略。迁移学习在不同领域或模型之间共享知识。潘等[130]提出转移联合嵌入(TJE)以联合嵌入来自不同域的输出标签和输入样本,用于混合内在实体特征。林应用[131]具有自适应层的神经网络来传递来自在不同域上预训练的模型的参数特征。强化学习(RL)使NER模型通过具有奖励策略的行为代理与环境域进行交互,例如马尔可夫决策过程(基于MDP)模型[132]和Q网络增强模型[133]。值得注意的是,研究人员[134]还利用RL模型在远距离监督的NER数据中降噪。对抗性学习生成反例或扰动以增强NER模型的鲁棒性,例如DATNet[135]对单词表示和反例生成器施加扰动([136],[137])。此外,主动学习,查询用户注释选定的样本,也已被应用于NER。沈等[138]在训练过程中逐步选择最多的样本进行NER标记,以减轻对标记样本的依赖。
4.2 共指消解Coreference Resolution
共指表达式经常出现在非结构化文本中。因此,共指解析Coreference Resolution(CO)任务检测涉及相同实体(包括别名和代词)的提及。如果没有其他提及,则提及将是单例的。给定一些非结构化的句子,这样的任务将输出共同引用的词跨度对。图7示出了该过程。

图7。共指消解过程。首先,检测提及。然后选择提及的先行词并匹配共指对。值得注意的是,共指消解任务可以在具有多个句子的文档上执行,同时处理复合句中的相同提及。
4.2.1 基于统计的方法
早期捕捉共指语言对象的尝试集中在实体、提及和先行词的统计特征上。基于聚类的解决方案将CO任务作为成对的二元分类任务来处理(无论是否共同引用)。早期的聚类模型以提及对特征为目标。宋等人。[148]提出了检测回指对的单链接聚类策略。里卡森斯等人。[149]进一步开发基于提及对的聚类以发出共指链或单例叶。后来,研究人员专注于基于实体的特征,以利用复杂的回指特征。Rahman和Ng[150]提出了一个提及排序聚类模型来深入研究实体特征。Stoyanov和Eisner[151]开发了凝聚聚类,以合并具有实体特征的最佳聚类。
基于树的模型和基于图的模型也是将共指解析转换为分区任务的流行设计。这些模型从给定的文档构建一个超图,其中每个边可以链接两个以上的节点,用于建模多个提及之间的共指。Cai和Strube[144]通过聚类算法学习统计特征来加权边缘并获得共指分区。萨佩纳等[145]进一步使用宽松的标记来解释共指。研究人员还简化了共指分辨率的图表,以适应基于树的方法。例如,Bean和Riloff[146]引入了一个决策树模型来区分结合上下文特征的回指提及。费尔南德斯等[147]利用投票感知器算法来检测提及对共指树。
4.2.2 基于深度学习的方法
深度学习模型自动将文档输入转换为单词表示,以收集用于检测共指提及对的特征。许多早期模型都是基于CNN的。Xi等[152]通过将远距离特征与分级提及对特征结合来解析共指,并且还通过softmax层对提及对进行评分。吴等[153]开发一个CO模型,以有效地处理具有丰富多尺度上下文的共指和单例表达式,通过卷积和串联将先行词、提及和提及对特征的上下文特征组合结合起来。RNN及其变体更好地提取了单词提及对之间的全局特征。怀斯曼等人。[154]提出了一个基于RNN的CO模型。李等[15]开发一个基于端到端LSTM的模型,检测提及跨度内的内部依赖关系,以理解围绕跨度的全局上下文。顾等[155]将聚类修改算法应用于LSTM以排除不相似的对。图8描绘了标准深度端到端CO模型。
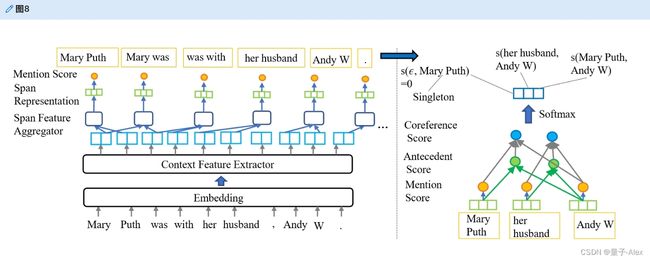
图8。标准深度端到端模型的架构(基于[15])。深度学习模型执行两阶段程序来处理共指解析任务:1)提及检测,它从文本中发现作为跨度的实体提及;2)共指检测,其对跨度中的先行词进行评分,以匹配作为输出的共指提及对。跨度包括所有单词序列的组合。该图显示了简化的结果。
注意机制模拟CO任务的语义交互。这方面的一个很好的例子是双LSTM结构,在[15]中提出的单词级注意增强了这种结构。然而,已经开发了许多不同的共指消解特定注意机制来利用共指特征。这些包括:用于CO任务的双仿射注意模型[156],该模型捕获单词跨度交互以检测关联表达;以及相互注意模型[157],该模型将句法特征与单词跨度的依存结构和先行词之间的交互特征相结合。此外,克拉克和曼宁等[158]采用基于RL的策略来增强他们的神经CO模型的鲁棒性,该神经CO模型使用启发式策略网络来过滤掉错误的共指匹配动作。研究人员还关注多个语义结构上基于嵌入的分布模型,以处理共指解析。Durrett和Klein[159]利用先行词表示,通过分布特征进行共指推理。Martschat和Strube[160]探索了提及对和树模型的分布语义,以增强共指表示,直接选择健壮的特征来优化共指任务。查克拉巴蒂等[161]进一步使用MapReduce框架,通过查询上下文相似性覆盖回指实体名称。
4.3 关系提取
关系提取任务从非结构化或半结构化数据中提取关系事实,以指示实体之间的交互和属性。关系提取作为下游任务,通常被称为关系分类。二元关系提取提取实体对之间的关系三元组,而n元关系提取提取多个实体(如合著者)上的关系三元组。关系提取赋予知识图谱语义链接。图9示出关系提取任务的概述。
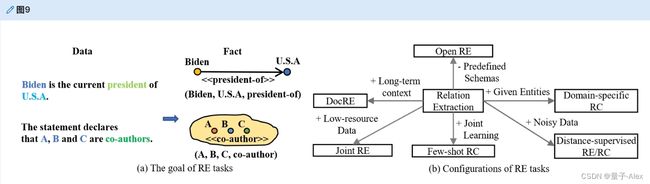
图9。关系提取。关系提取任务的目标是从数据中提取事实三元组,并找到将节点链接在一起的边。对于n元关系,链路是覆盖多个节点的超边。
4.3.1 半结构化数据与非结构化数据的开放关系提取
开放式关系提取任务从没有预定义关系类型的非结构化数据中发现事实。这些技术从自由文本中检测名词性词(作为主语或宾语)和动词短语(作为谓语),以形成知识三元组,如(主语、谓语、宾语)。统计方法也是开放关系提取的趋势解决方案。在关系检测方面,基于概率图的模型是允许上下文信息流经半结构化结构或非结构化自由文本的流行设计。穆尔瓦德等[176]提出了用于标记关系的半结构化表和语义消息传递的概率图。Chen和Cafarella[177]利用一个基于CRF结构的模块和一个帧查找器来标记单元格的位置标签(如左、中和右)。由此,构建了一个层次树,其中关系三元组可以通过父子结构恢复。研究人员还将概率模型应用于文本的关系分类。例如,StatSnowball[178]采用马尔可夫逻辑网络来识别关系。
方法聚焦规则是对不同数据结构类型的RE任务的最早尝试,收集适合手工模板的字符串,例如,“ P E O P L E i s b o r n i n PEOPLE is born in PEOPLEisborninLOCATION。”指( P E O P L E , b o r n − i n , PEOPLE,born-in, PEOPLE,born−in,LOCATION)。然而,这些无监督策略依赖于复杂的语言学家知识来标记数据。后来,研究人员专注于三元组挖掘的自动模式发现。半监督设计是一种减少手工特征和数据标记的启发性策略,它基于一小组带注释的样本发现更可靠的模式,例如DIPRE[179]用种子迭代提取模式,基于bootstrapping的KnowItAll[7]和Snowball[180]为DIPRE配备置信度评估。一些基于规则的模型考虑更多用于挖掘的词汇对象。OLLIE[61]将词汇结构模式与文本中的关系依赖路径相结合。MetaPAD[181]将词汇分割和同义聚类结合到元模式中,这些元模式对于关系三元组来说具有足够的信息量、频率和准确性。特别是对于半结构化表格,研究人员设计基于表格结构的规则来获取按行、列和表格标题排列的关系,如[182]。此外,一些利用远程监督的半结构化提取系统容忍潜在的错误,这些错误直接查询外部数据库,如DBpedia和Wikipedia,以获取表格数据中找到的实体的关系,如前面的方法[122]、[176]和[183]。同样,穆尼奥斯等[184]在维基百科表格中查找表格形式的标注关系。克劳斯等185]还扩展了通过远程监督提取关系的规则集。
深度学习模型也被开发来处理开放关系提取。一个常见的框架是编码器——解码器模型,旨在获取事实模式。CopyAttention[186]包括一种通过神经自举策略将单词从输入序列复制到输出序列的机制。IMOJIE[187]通过伯特-LSTM结构改进了复制注意力,同时结合了无监督聚合方案来执行迭代提取。开放关系提取的另一个方向是将有监督的知识转移到模型中,以便调整已知的关系来获得无监督的关系。本着这种精神,吴等[188]开发了一个基于度量学习的解决方案,该解决方案将关系连体网(RSN)与聚类策略相结合,以发现新的事实。图10示出了两种深度学习范例。
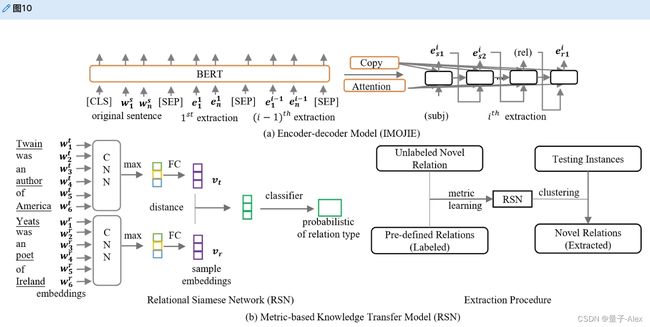
图10。基于深度学习的开放关系提取的两种范式。在该图中,(a)显示了IMOJIE模型[187],该模型通过编码器——解码器设计提取事实。(b)描绘使用RSN来比较关系模式,然后利用聚类来收集关系的模型[188]。
4.3.2 基于非结构化句子级数据的领域特定关系分类
给定具有概念(实体)提及的非结构化句子,特定领域的关系分类任务在给定句子上下文的预定义关系集中用关系标签标记给定的提及。核方法和深度学习框架通常将关系分类作为多标签单类分类任务来处理。基于SVM核的方法利用单词的特征向量来训练分类器,用于非结构化文本的监督关系分类任务。这些模型将特定的语义对象映射到通过用于分类的核函数的特征空间,例如具有基于词核的SVM(具有位置和实体标签)[162],基于依赖树核的SVM[163],或者基于浅解析树核的SVM[164]。然而,高性能的内核函数可能很难设计。
基于深度学习的框架自动收集实体相关的上下文信息,用于关系分类任务。给定一个需要将其关系分类为的句子,让xeh和xet分别代表头实体和尾实体。深度学习模型会为每个单词生成一个表示,那么特征提取器将导出向量r来指示每种关系类型的概率。基于卷积的模型,如结合词汇特征的基于特征的CNN[165]和最大池策略,关注邻域单词中的局部上下文。Nguyen和Grishman[166]使用多尺度卷积窗口来增强局部特征聚合。一些研究使用捕捉长距离关系的LSTM框架关注句子之间的全局语境意识。周等[17]使用BiLSTM,该BiLSTM采用词间注意来捕捉关系的长距离依赖性,而Miwa和Bansal[167]将树结构合并到LSTM框架中。许多设计还通过注意力机制将全局上下文特征整合到CNN结构中,以模拟显著的交互,例如注意力-CNN[168]用单词级注意力选择实体相关的上下文,多层次CNN[169]开发基于注意力池的输入注意力机制。一些最近的研究通过GCN探索了图形级上下文,并通过预训练的模型提取背景知识。这种方法的例子包括EPGNN[170],它包括GCN的实体对图(具有预训练的BERT模型),AGGCN[171],它集成了用于图卷积的多头注意机制,以及RIFRE[172],它进一步采用异构图网络来合并高阶特征。科恩等[173]将关系分类转换为问答任务,并将BERT嵌入用于分类。图11描绘了关系分类模型的一些经典框架,表4比较了流行模型的关键设计方面。一些任务需要一个模型来处理多个实体之间的n元关系。为此,已经设计了语义角色标记解决方案来将n元关系分解成二进制关系。例子包括NNF[174]和依赖路径嵌入[175]。
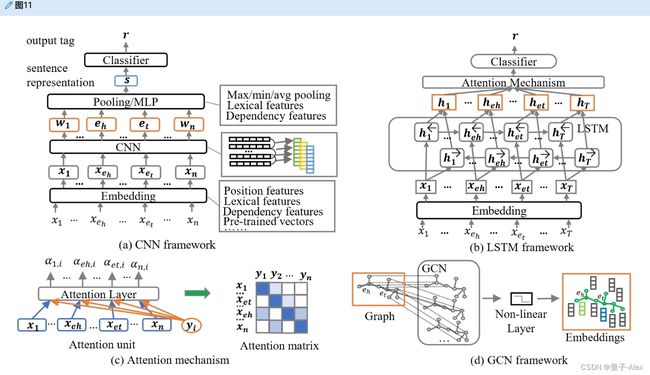
图11。经典关系分类模型的一些框架。在该图中,(a)、(b)、(d)显示了CNN、LSTMs、GCN的架构,而(c)显示了广泛使用的注意机制的结构。
4.3.3 远程监督关系提取/分类
大型数据集上完全监督的关系提取/分类通常需要大量费力的标签标记。为了解决这个问题,明茨等[45]开发了一种远程监督策略,用于用外部知识库(原始工作中的Freebase)自动注释关系标签。该策略假设出现在不同句子中的实体对反映了知识库中链接它们的相同关系。然而,远程监控没有充分考虑数据上下文,因此不可避免地会受到噪声的影响。数据噪声阻碍了传统模型中的关系分类任务。一些方法试图通过增强特征提取器来克服这个问题,例如分段卷积(PCNN)[16]。这种方法将一个句子分成三个独立的部分,根据实体来保留关键的上下文特征。还参见图12(a)。分级注意机制[189]模拟长尾标签以增强解码器特征。一些模型涉及改进的学习策略,旨在提高对噪声的鲁棒性。转移矩阵结构[190]学习不正确的模式以防止噪声。黄等[191]采用协作学习来处理交互环境,而秦等[192]利用强化学习去除错误标记的样本。此外,DSGAN[193]通过对抗性学习挑选可靠的样本进行训练。
最近,努力集中在设计实例选择器结构上,以比较样本袋中实例的可靠特征。例如,里德尔等[23]发展了多实例多标签学习(MIML)的“至少一个”假设。该假设认为,包含相同实体对的至少一个样本将表达给定的远程监督关系(即,样本是正确的)。基于此,选择性注意[196]提出了一个经典的设计,将标记有相同关系标签的句子分组。还参见图12(b)。MIML CNN[194]使用CNN来处理每个句子包,然后利用跨句子池操作来导出用于多标签关系建模的实体对表示。参见图12(c)。纪等[195]合并实体描述以增强MIML CNN。实现实例级特征提取的另一个方向是实例级注意机制。然后用相同的关系标签在不同的组中对每个句子表示的贡献进行评分。最后,为每种关系类型生成注意力加权上下文表示。许多模型用MIML设计扩展了这一思想。一个例子是袋内/袋间注意[197]。该方法通过复合注意机制和交叉关系注意[198]捕捉内部关系和外部包——关系相互作用的句子特征,其中Baye规则用于获取不同关系类型包的全局相似性。设计实例选择器的主要目的是强调正确样本中的指导性特征,同时屏蔽错误标记数据中的虚拟特征。
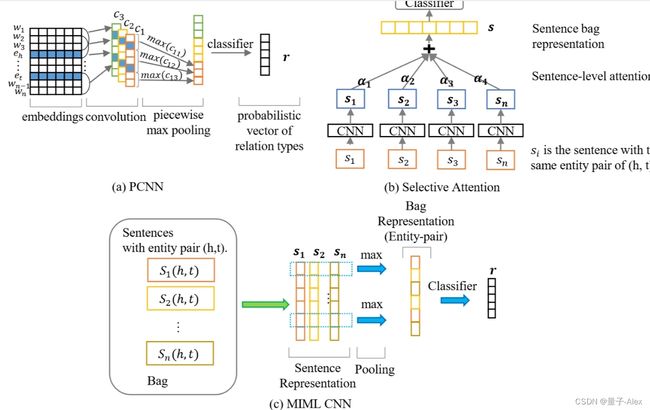
图12。远程监控的里程碑模型。
深度学习方法还考虑外部知识来改善距离监督关系提取,例如将实体的知识图谱嵌入到模型中[199]。RESIDE[200]进一步使用带有基于GCN的表示的辅助信息的句法图。我们在表5中比较了这些流行的成就。
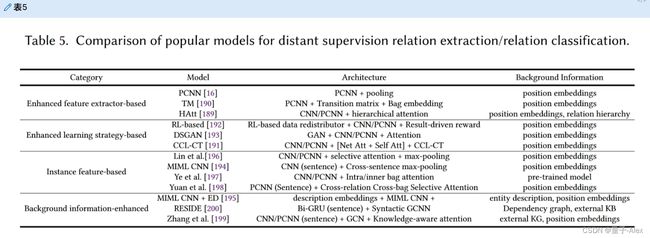
表5。远程监督关系提取/关系分类的流行模型比较。
4.3.4 Few-shot 关系分类
低资源场景,特别是少镜头和零镜头关系分类,需要深度学习模型从几个例子中学习。少数/零镜头学习,也称为元学习,只为少数样本提供燃料来驱动DL模型,具体来说,是少数镜头、零镜头学习。少数镜头学习以N路K-shot形式提供支持数据集,该支持数据集为一般N路的每种关系类型提供K个实例(总共NxK个样本),并基于给定的支持集预测查询集中的数据标签。此外,零镜头学习遵循上述形式,但查询集包含不可见的样本标签,这些标签不会出现在支持集中。值得注意的是,在大数据环境中,知识库中存在长尾现象,其中大多数知识类型用很少的样本来表达。[201]元学习配置通常出现在知识获取和知识提炼的各个子任务中。一般来说,研究人员试图通过三种方法来放大这些低资源配置的可用特征:度量学习、元学习和领域适应。元学习通过从有限的监督中保留可传递的元信息来增强优化器。模型不可知的机器学习(MAML)[208]通过两阶段多重梯度下降改进了批量学习。这里,在所有样本类型用估计值进行一般优化之前,模型被训练以估计每种关系类型的梯度。各个关系类型的任务敏感元信息存储在部分梯度值中。通过单独反向传播的梯度估计也被其他模型应用。MetaNet[209]利用快——慢机制来获得样本和特定任务的高阶隐式关系元特征。元学习器和基本学习器都包含一组用于优化的慢速权重和快速权重。另一个关键问题是灾难性遗忘。为了解决这个问题,吴等[210]开发了一种课程元学习策略,该策略按顺序审查样本,并在记忆机制中保存所学的特征。
度量学习旨在寻找度量空间来比较不同的关系类型。为了确定查询样本中的关系类型,例如,ProtoNet[202]平均支持集中每种关系类型的嵌入,作为原型支持向量。LM-ProtoNet[203]利用关系上下文的细粒度特征来构建支持向量,将短语嵌入与CNN诱导的句子嵌入连接起来。低资源样本中的噪声会吸引不恰当的元特征,降低深度学习模型的鲁棒性。高等。[204]将特征级关注与实例级关注结合起来,以强调可靠的原型特征。此外,匹配网络[205]提出了一种基于注意力的嵌入策略,用于分类,通过向量乘法计算每个支持样本的查询样本的注意力得分。RSN[206]比较了样本嵌入的相似性。另一种方法称为多级匹配和聚合网络(MLMAN)[207],通过将支持向量与查询向量聚合来聚合本地和实例特征,以匹配查询样本的正确长尾类标签。图13概述了经典的基于度量的范例。
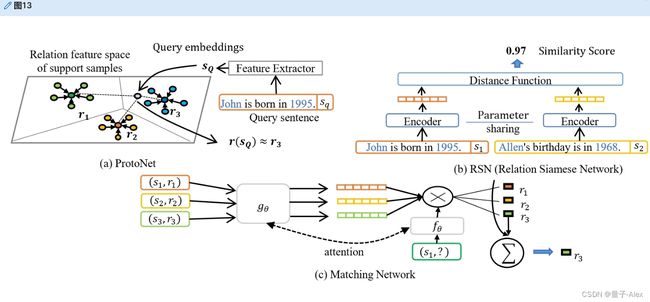
图13。基于度量的少数镜头关系分类模型。在该图中,(a)示出了ProtoNet[202],其比较了不同关系类型的支持向量之间的查询样本的距离。(b)示出RSN[206],其计算样本对的相似性。(c)示出匹配网络[205],其使用注意机制通过将查询与不同标记的支持样本进行匹配来标记查询。
少数镜头RC设计还考虑特征增强策略,以减轻有趣的模型设计和背景知识的数据不足。类似于[173],利维等人。[211]通过模板转换器将零镜头RC变成阅读理解问题来理解看不见的标签。苏亚雷斯等[212]通过实体对和相应句子的BERT语境化嵌入,为每个句子组成复合关系表示。GCN还为少量学习提供了额外的图形级功能。Satorras和Estrach[213]提出了一种新的GCN框架,通过计算节点之间的相似性来确定查询样本的关系标签。而且,曲等[214]对原型向量采用后验分布。一些设计还利用基于度量学习的半监督数据扩充。先前的神经雪球[206](基于RSN)通过连体网络标记查询集,同时从外部远程监督样本集抽取相似的样本候选以丰富支持集。少数镜头域适应映射看不见的标签进行分类。针对看不见的“以上都不是”类型的具有域适应策略的BERT-PAIR对。高等[215]讨论了作为搜索域不变特征的博弈过程的少数镜头关系分类的域自适应。他们通过对抗性训练实现领域适应。在[24]中可以找到更多用于少数镜头关系分类的域适应策略。
4.3.5 联合关系提取模型
传统的基于流水线的关系提取(关系分类)模型在每个阶段都遭受错误传播,同时还破坏了任务间的交互。早期研究人员专注于用于快速端到端联合关系提取的有趣的基于统计的特征,例如通过条件概率模型求解实体和关系的基于整数线性规划(ILP)算法[216],联合解码全局级关系特征的半马尔可夫链模型[217],以及建模实体标签和关系的联合逻辑规则的马尔可夫逻辑网络(MLN)[218]。早期的尝试提供了实体——关系交互的原型。然而,对于复杂的上下文,统计模式并不明确。研究人员可以求助于转向联合提取模型,主流高性能设计侧重于参数共享策略和新颖的标记模式。参数共享策略为各种类型的任务合并神经架构。它们共享权重,并使用不同的输出层来获取具有关系的实体。郑等[219]合并NER和RC任务的双BiLSTM层以共享参数,然后使用CNN和LSTM网络分别标记关系和实体。Miwa和Bansal[167]还将与NER和RC相关联的依赖特征与双LSTM和BiTreeLSTM层的组合集成在一起。一些模型关注分配跨任务特征的微妙策略。例如,GraphRel模型[220]直观地利用两阶段监督,通过两个各自的BiGCN层进行跨任务交互。GCN框架结合了一个依赖图和一个关系实体图来利用深层特征。
为了处理重叠标签,新的标签方案通过复合标签为输出层设置联合解码目标。郑等。[221]用单词的关系类型和角色(例如,句子的主语或宾语)扩展BIES标签,以开发包括命名实体识别和关系分类的序列标记任务。魏等。[222]通过级联映射函数为每个关系类型直观地标记主题实体的所有对象候选,以包含重叠提及。进一步,王等[223]开发了一个握手方案,以减轻重叠实体内的暴露偏差。贝库利斯等人。[224]设计了一个多头选择机制来探索所有实体/关系组合。李等[225]将实体关系标记转化为多回合问答问题,利用机器阅读综合(MRC)模型来处理实体之间的远程语义。与以前的方案不同,KGGen[226]通过基于结合对抗学习的预训练模型的编码器——解码器/生成器结构直接生成三元组,这克服了对实体共现信息的特征依赖。图14示出了一些种子关节提取模型。还提出了新的基于分布嵌入的模型来模拟跨任务分布,以弥合NER和RC之间的语义差距。任等。[227]提出了一种用于联合提取任务的知识增强分布同型模型。该模型首先将实体对映射到其在知识库中的提及,然后用实体类型和所有关系标记实体对知识库提供的候选人。该模型学习具有语境化词汇和句法特征的关系提及的嵌入,同时训练具有其类型的实体提及的嵌入,然后通过翻译嵌入(TranE)[228]模型由其头和尾实体嵌入导出上下文关系提及。同型模型假设实体和它们的关系标签之间的交互共现,用来自外部领域的知识和额外的类型特征填充分布差异。值得注意的是,该模型还有效地防止了远程监督数据集中的噪声。然而,也需要特征工程和额外的知识库。

4.3.6 文档级关系提取
文档中的实体可以通过复杂的跨句子上下文来表达关系,这击败了大多数传统的句子级上下文编码器。因此,人们设想了新的架构来捕获文档级上下文。句内语义段落对于文档级提取至关重要。因此,研究人员最初开发了LSTM拟合图结构的变体来处理长期依赖关系,如图LSTM[229]和图状态LSTM[230]。然而,最近,研究人员一直专注于基于GCN的模型,以探索具有新颖的跨句图结构的不同语言特征。许多方法使用静态文档图来处理句子间语义上下文。例如,对于n元关系提取,AGGCN[171]通过注意力引导的GCN层链接相邻句子的依赖树的根,这也克服了对语义角色标记的依赖。萨胡等[231]引入共指边和相邻词边以形成同质文档图。克里斯托普卢等[232]使用提及/句子/实体(M,S,E)节点来创建区分各种语言角色的异构语义图,同时使用上述中间节点结构经由EoG干扰层进行推理。然后,研究人员开发了用于高阶推理的动态文档图模型。许多模型利用动态边缘。GP-GNNs[233]在用于推理的全连通图中推导出具有动态边权重的隐藏语义逻辑。LSR[234]将图结构视为一个潜在变量,以迭代地提炼链接和权重,从而从上下文中构建逻辑特征。徐等[235]考虑重建依赖路径以重新加权关系实体对。GraphRel[220]通过两阶段过程联合提取实体和关系,该过程将静态依赖关系与动态关系加权图相结合,以增强多跳推理。一些模型还考虑了多个图的特征提取。比如曾等[236]设计了一个具有实体级图的异构提及级图,用于多跳推理。文档级关系提取的另一个方向是证据推理。张等[237]开发具有外部标记的共现证据特征的基本原理图,用于捕获长期关系依赖性。还考虑了具有可变节点的动态图。
在复杂推理的范围内。DyGIE[238]修剪静音低可信度实体通过门机制跨越节点,用于文档级特征利用。其他方法试图理解不同语境中隐含的常识规则。判别推理网络(DRN)[239]识别常识关系,同时通过异构图形表示特征执行句子内推理。该方法基于具有句法结构的多尺度语境包含可区分的常识特征的假设。背景常识特征也可以从像COMET[240]这样的预训练模型中获得。然而,理解常识是如何在上下文中表达的,以及它是如何在人类逻辑中展开的,仍然具有挑战性。
通过多层卷积采用U形分割进行文档级推理。此外,它将文档视为视觉语义信息。ATLOP[242]引入了本地化上下文池来提取BERT的实体相关特征,同时使用自适应阈值来解码可靠关系。这种技术不依赖于图形结构。我们在表6中比较了典型里程碑模型的设计。
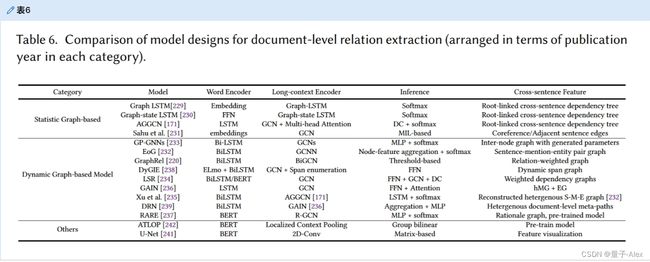
表6。文档级关系抽取模型设计比较(按每类出版年份排列)
5.基于结构化数据的知识图谱提炼
从非结构化或半结构化数据构建的原始知识图谱可能是稀疏的,并且知识三元组可能是不完整的或损坏的。知识图谱精化通过背景语义或用额外的知识图谱(结构化数据)填充知识三元组来修复这些问题。知识图谱精化的子任务包括知识图谱完成和知识融合。一般程序如图15所示。
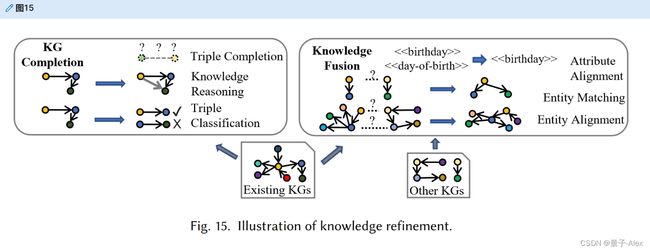
5.1 知识图谱补全
知识图谱完成填充未完成的三元组,同时从已完成的三元组中导出新的三元组。就完成的三元组而言,知识图谱完成通过三元组分类评估每个三元组的责任。所谓责任,我们指的是三元组的正确性。
5.1.1 基于嵌入的三重补全
基于嵌入的链接预测模型利用分布表示来搜索可以填充缺失部分的元素,这些元素被公式化为(h,?,t)或者(?,r,t)(实体预测),以及(h,?,t)(关系预测)。例如,基于TransE的模型[112]搜索头实体h、尾实体t和关系r,它们的表示接近h+r=t以完成三元组。后来,研究人员发现,以前的对称TransE模型没有考虑一对多关系。然后,焦点转向导入具有基于距离的翻译模型的超空间结构,用于链接预测,如TransR[243]、TransH[244]和TranSparse[245]。一些模型,如RESCAL[246],TuckerER[247],DistMult[248]和NTN[249],考虑将实体对表示与潜在的关系语义空间相匹配,以便用大图进行预测。
最近,研究人员将注意力集中在语义知识结构上。例如,HAKE[250]使用极坐标系统来模拟知识图谱中的语义层次,如上位词、下位词和实体本体关联的并置,它们通过模具和角度约束来区分不同层次的实体向量。CAKE[251]用常识规则提升负采样。许多模型,如SimKGC[252]和HaLE[253],通过对比学习优化低维嵌入的负采样。CAFE[254]引入了邻域子图特征集来增强相关链接信息。此外,人们对通过GCNs的语义扩散机制用知识图谱的子结构分解知识表示的语义成分很感兴趣。DisenKGAT[255]通过将表示组件分解成子图结构中隐含的不同语义来识别知识图谱的高阶邻居节点特征。这些模型背后的假设是,一个大的知识图谱应该包含足够的子集,这些子集可以被简化为k个组件,以推理链接的实体节点。
5.1.2 关系路径推理
关系路径推理通过完成的三重序列作为支持证据来演绎新的事实,比如“(B,lives-in,Seattle)←(A,works-in,Microsoft),(Microsoft,Location-in,Seattle)”。早期的尝试开发了用于关系路径推理的随机游走模型,该模型在潜在变量逻辑图形模型中推断关系逻辑路径。路径排序算法(PRA)[256]生成特征矩阵来采样潜在的关系路径。然而,图中的特征稀疏性阻碍了随机游走方法。提出了语义丰富策略来缓解这一瓶颈,例如诱导向量空间相似性[257]和聚类关联关系[258]。随后,研究人员将关系路径推理任务建模为马尔可夫决策过程,以便识别知识环境中的逻辑约束。深度强化学习通过学习评估每个选择步骤并扩展推理路径的策略代理来实现这一想法。DeepPath[259]将状态空间建模为实体及其诱导关系的(预训练的)基于翻译的表示。然后,所采取的动作通过实体对的特征空间找到最匹配的关系标签。行动奖励由二进制函数计算。然而,二元奖励函数的低质量评估将意味着基于RL的模型不能很好地推广到处理不完整的知识结构[260]。为此,林等[260]设计了一个基于关系和实体向量空间的软奖励塑造函数,而李等[261]使用多个代理来选择实体对和关系。M-Walk[262]利用RNN来捕捉路径决策之间的时间状态相关性。更多的设计利用捕捉全局特征的神经网络来寻找合理的路径。路径RNN[263]递归聚合关系路径特征,用于多跳推理。原因链模型[264]增强了具有注意机制的路径RNN,以强调实体中类型信息的多路径依赖性。陈等[265]通过变分编码统一路径推理和路径查找任务。
一些方法进一步关注注意力机制,以增强强化学习的特征。ADRL[266]利用自我注意机制来强调邻里实体关系互动特征。同样,王等人。[267]引入图形注意机制以增强知识特征。最近的研究兴趣被吸引到整合处理复杂语义特征的神经结构上,如郑等人的分层策略网络[268]和DAPath[269],后者整合了一种通过路径长度特征发布奖励的远程感知机制。MemoryPath[270]是一个基于注意力的记忆组件,它为强化学习保留知识特征,并减轻模型对预训练嵌入的依赖。
许多努力也集中在自动挖掘逻辑规则以铺设推理路径。有规则发现的方法,如李正吉[271],RLvLR[272]和鲁伦[273]。规则挖掘方法不是寻找接近知识符号本质的有希望的关系路径模式,而是从合理的KG结构中提取和修剪逻辑规则,然后通过收集的规则模板进行链接预测。然而,不完全图中的逻辑规则不容易导出看不见的知识路径。另一个研究方向是将逻辑规则注入神经模型,以促进路径推理。KALE[274]将一阶逻辑规则与知识嵌入联合嵌入,以增强关系推理。RUGE[275]通过学习的软规则迭代地纠正KG嵌入,然后执行关系路径推理。逻辑规则也被用作神经模型的辅助语义信息。NeuralLP[276]提出了一种神经框架,该框架将逻辑规则结构编码成具有注意机制的矢量化嵌入。pLogicNet[277]引入马尔可夫逻辑网络来模拟推理的不确定规则。ExpressGNN[278]进一步采用GCNN来解决具有逻辑规则的邻域图形语义。这些基于规则的神经模型也被认为是可微学习在逻辑规划中的应用,有利于基于梯度的优化算法。
5.1.3 可解释关系推理
可解释性有助于使人类用户能够理解机器学习模型[279],这在评估模型的可靠性和响应不同数据环境的能力方面起着关键作用。解释模型包括自我解释的临时模型和可检查的临时模型。包含透明决策过程的预先推理模型可以通过内省通过其内部结构进行自我解释。逻辑规则挖掘方法,如AMIE[271]和RLvLR[272]可以反馈逻辑规则,向用户解释链接决策。一些模型只包含一些人类可以解释的组件(例如,学习的规则)。当使用基于神经模型(如NeuralLP[276]、pLogicNet[277]和ExpressGNN[278])的规则查找方法进行推理时,用户可以观察这些学习到的规则作为辅助信息。然而,这些神经网络仍然是黑箱。主流的部分预选模型还包括基于随机游走(潜在路径的概率值)、强化学习(每个动作的奖励值)和注意力(显著相关性的注意力得分)的模型。事后解释方法开发代理来探索黑盒模型中的隐含特征,如矩阵和神经网络框架。一些代理提取规则或学习概率分布来复制模型。卡莫纳等人。[280]用一阶逻辑训练贝叶斯网络以从嵌入模型中提取规则。OXKBC[281]通过关系和实体之间的相似性生成似是而非的解释路径。模型简化不能分解缠绕在一起的非线性神经模型的特征。一种解决方案是进行敏感性分析以利用深层特征。分析将包括对模型施加小的扰动,以便观察输出如何变化。这些变化揭示了有影响的特征。GNNExplainer[282]探索了影响单实例和多实例预测的子图结构。CRIAGE[283]生成虚假事实来评估模型性能,并为每个关系定位突出的事实三元组。
5.1.4 三重分类
三元组分类旨在区分知识图谱中有保证的三元组和异常(不真实)三元组。许多语义模型都是为判断知识图谱中可疑三元组的任务而设计的,该知识图谱不断更新新的关系类型和事实。负三元组样本赋予知识表示模型判断无序三元组的表现力。例如,CKRL[284]包括用于确定可靠三元组的索引系统,包括局部三重置信度,比较三重样本和负样本之间的距离;全局路径置信度,测试形成三元组的推理路径的全局资源;和自适应路径置信度,其对导出三元组的局部推理路径进行评分。然而,由于负采样不足,许多潜在合理的三元组没有被涵盖,特别是一对多关系[35]。因此,研究人员利用更复杂的语义结构来缓解这个问题。本着这种精神,董等[285]将实体嵌入扩展到n球结构中,利用n球结构来合并细粒度类型链,作为对三元组进行分类的一种方式。Amador-Dom í nguez等[286]添加本体信息以增强模型不可知的表达性。一些模型专注于高级神经网络嵌入来检测可信的三元组。例如,R-MeN[287]通过采用多头注意力机制来生成基于记忆的嵌入,从而捕获三元组之间的潜在依赖性。
5.2 知识融合
现实世界的知识通常是开放更新的。在大多数情况下,用户应该能够添加外部知识来丰富现有的外部知识图谱。通过这种方式,知识融合旨在合并语义等价的元素,如“特朗普”和“唐纳德·特朗普”,以便将新知识整合到新的概念或事实中。知识融合的子任务包括属性对齐、小规模输入三元组的实体匹配和完整知识图谱的实体对齐。
5.2.1 属性对齐
属性三元组表示具有描述值(如颜色、日期、数字或字符串)的概念属性。用户可能使用不同的术语来指代同一属性,例如“生日”和“出生日期”,其中同义词可能导致语义稀疏。因此,属性对齐旨在统一属性符号。许多方法侧重于对齐属性的语义嵌入,前提是如果两个属性名的嵌入彼此接近,则它们应该相同。一些模型利用属性名称字符串之间的相似性来生成分布式嵌入,例如在[288]和[289]中。杨等[290]利用单词包模型来学习属性的上下文嵌入。类似地,JAPE[291]利用用于属性嵌入的Skip-gram模型来建模经常一起用于描述实体的共现属性,例如位置的“纬度”和“经度”。属性嵌入还为实体对齐任务提供辅助信息,如定义和描述。然而,属性也可以携带信息不是特别丰富的数据,如电话号码,这在试图生成知识级表示时可能具有挑战性。然后,一些模型考虑使用神经网络来基于上下文值生成嵌入。例如,AttrE[292]用LSTM框架嵌入属性值的每个字符,以便组成用于预测单语表达中潜在阶段的属性嵌入。该方法结合了属性——名称谓词对齐策略来处理看不见的属性。
5.2.2 基于小尺度知识图谱的实体匹配
在其初步阶段,一个知识库将只包含几个三重提及,没有足够的信息用于严格的概念。因此,实体匹配模型将多源知识与小规模数据中可用的语言信息相结合。最近的模型将实体匹配视为机器学习分类任务。例如,Magellan[293]将多个相似性函数与随机森林相结合,因此该方法也考虑了数值属性。MSejrKu[294]探索了利用分类器层(包括逻辑回归和MLP分类器)来判断相同实体对的可行性。DeepMatcher[295]是一个深度学习系统,将RNN结构与注意力机制相结合,以表示实体匹配的属性词。与传统模型相比,基于深度学习的模型更擅长处理文本中的噪声,尤其是使用WordNet的概念丰富任务[296]。
早期的尝试也针对实体匹配的实体的唯一属性。许多模型利用基于距离的方法来分布式表示实体描述或定义。VCU[297]提出了一阶和二阶向量模型来嵌入实体对的描述词,以全面测量概念距离。TALN[298]利用由BabelNet导出的基于意义的嵌入来组合单词的定义描述,该描述首先通过BabelNet生成每个过滤的定义单词的嵌入,并结合词性标记、语法特征,然后对它们进行平均以获得质心意义,从而获得最佳匹配候选词。可用于实体匹配的基于字符串相似性的模型还包括TF-IDF[299],I-Sub[300]。基于图的方法在由分层图结构组成的小规模KG上实现了可行的实体匹配性能。ETF[301]通过语义特征和基于图的特征学习概念表示,包括Katz相似性、随机游走介数中心性和信息传播得分。ParGenFS[302]利用基于图的模糊聚类算法来概念化新的实体。该方法激励主题分布获取不同的概念聚类,在目标知识图谱中搜索实体更新的对应位置。实体匹配任务也可以由基于文本相似性的模型来处理,当考虑性能和计算成本之间的权衡时,该模型检测实体之间的表面相似性。Rdf-ai[303]提出了一个匹配两个实体节点图的系统模型,该模型利用字符串匹配和词汇特征相似性比较算法来对齐可用属性,然后计算实体相似性以进行对齐。类似地,Lime[304]进一步利用度量空间来检测对齐的实体对,这些实体对首先生成实体样本,以在实体融合的相似性计算之前过滤可对齐的候选实体。与小规模KGs不同,成形的大型KGs包含有意义的关系路径和丰富的概念分类。HolisticEM[305]采用IDF分数来计算用于种子生成的实体名称的表面相似性,并利用个性化PageRank(PPR)通过分别遍历实体图的邻居节点来测量实体图之间的距离。
自治区可以向KG系统输入独特的信息,如昵称、电话号码和其他个性化数据。这样的知识只有用户知道。检测独特缺失部分并要求用户填写的策略是必要的。通过查询用户来判断信息或解决冲突的主动学习方法[306]是最可靠的解决方案,在这些场景中是不可或缺的。
5.2.3 基于大规模知识图谱的实体对齐
大规模的知识图谱通常包含足够的属性信息和图结构,可以通过概念实体和关系链接形成知识感知结构。实体对齐任务旨在将结构化数据与构建良好的大规模知识图谱集成,这些知识图谱包含知识级别的语义结构。基于嵌入的模型通过具有三元组知识嵌入的种子实体来学习实体对齐任务的图间实体映射。孙等[307]指出用于链路预测的普通负样本会损害区分同一类型的不同实体的能力。因此,他们使用相应目标实体的特征空间中的近实体来生成负样本。IPTransE[308]是一种用于知识表示和学习实体映射的迭代联合嵌入策略。它利用路径转换嵌入方法来嵌入链接同一实体对的不同关系路径。这些被视为具有相同效果的联系。然后使用软对准策略来减轻匹配误差。参见图16。MultiEA[309]考虑了实体图属性、链接和邻居节点的多视图特征。BootEA[307]包括一个自举的“可能比对”标记算法,该算法迭代地添加可靠的种子进行比对。在跨语言场景中,MtransE[310]生成轴校准和平移向量,以模拟不同语言中的特征空间不变性。此外,一些模型考虑自我监督策略来利用种子信息,如SS-AGA[311]和SelfKG[312]。
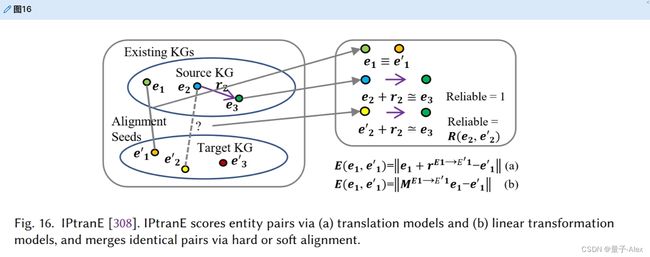
图16。IPtranE[308]。IPtranE通过(a)翻译模型和(b)线性变换模型对实体对进行评分,并通过硬比对或软比对合并相同的实体对。
实体对齐的一个关键挑战是许多实体不具备表面或结构分布特征。因此,许多实体对齐模型也使用属性表示来增加特征。例如,KDCoE[313]利用了具有描述属性的联合训练策略。JarKA[314]对稀疏多语言知识图谱中属性之间的交互进行建模,以推断等价实体。一些模型利用基于深度学习的神经网络进行属性上下文嵌入。例如,AttrE[292]利用LSTM来导出属性值的依赖特征。与以前的方法不同,JAPE[291]将属性嵌入与覆盖关系图结构相结合,以捕捉跨语言差异。另一个具有挑战性的问题是用于对齐的语义图结构。GCN-Align[315]首次提出了基于GCN的实体对齐任务框架。从那时起,最近的研究集中在使用基于GCN的模型的复杂图语义上。例如,RNM[316]匹配邻域节点特征来比较实体对。RDGCN[317]利用对偶关系图来解决三角形实体图结构中的矛盾表示。大规模知识图谱通常包含用于对齐的独特语义子图结构。这里,图匹配神经网络(GMNN)[318]构建主题实体图,该主题实体图用墨水标记相邻节点以合并相同的实体。AttrGNN[319]根据属性三重类型划分知识图谱,以理解异构实体信息。最近的研究方向也旨在建立交叉图交互的模型。例如,MuGNN[320]提出了一种具有多通道GNN编码器的交叉知识图谱注意机制,该编码器可以一致地对图间结构特征建模。类似地,GTEA[321]涉及一个联合图注意机制来融合跨图关系信息。
6.知识进化
最近,研究人员专注于在给定的环境条件下知识是如何进化的。条件知识图谱通过反映在特定条件下建立的事实来服务于这一目标。条件元组被表述为(h,r,t,γ),其中γ可以是事实的先决条件三元组。许多研究人员在简化的情况下研究了这一点,作为一个时间知识图谱,其中γ是某种时间信息(如时间戳)——例如(拜登,乔布,副总统,2009-2017),(拜登,乔布,总统,2020-)。图17示出了知识演化的示意图。
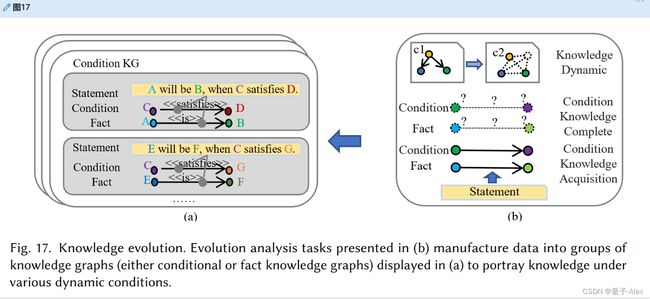
图17。知识进化。(b)中介绍的进化分析任务将数据制造成(a)中显示的知识图谱组(条件或事实知识图谱),以描绘各种动态条件下的知识。
6.1 条件知识获取
许多科学事实是建立在一定条件下的,尤其是在生物医学领域。早期的努力没有从系统的角度全面考虑这种情况。因此,江等[322]开发了一个新的标记模式来描述格式化为“B/I-XYZ”的条件元组,其中“BI”代表位置信息(开始/中间),“X”是逻辑角色(事实/条件),“Y”标记元组角色(主语/宾语),“Z”表示组成类型(概念/属性/谓词)。条件知识提取实现了三个目标:提取事实元组,收集条件元组,连接事实条件。江等[26]注意到传统的提取系统将条件信息合并到实体中以形成事实三元组,这将损害实体链接。此外,在非结构化语句中,相同的标记可以是不同元组的主题和对象。因此,他们设计了一种基于多输入多输出序列标记(MIMO)的联合提取方法来解决这个问题。
他们的MIMO模型利用关系名称标记层,该层分别通过事实和条件标记子层表示每个令牌的关系标记。然后使用元组完成标记层来区分具有不同关系名称的每个令牌的逻辑角色。然而,郑等人[323]指出MIMO标记模式不能有效地处理重叠的三元组。因此,他们利用分层解析将MIMO模型中的多输出模式简化为单输出模式。图18示出了MIMO模型。条件知识提取的另一个流行趋势是时间知识提取,其中条件三元组被简化为时间。许多以前的模型利用RNN结构来捕捉时间依赖性,从而识别句子内的时间关系,例如[324]和[325]。在提取细粒度时态知识方面,Vashishtha等[326]对事件、状态和持续时间进行建模,以通过多个堆叠的注意层来匹配它们的时间线。最近的研究改进了处理文档级时态知识提取的解决方案。例如,TIMERS[327]是GCN模型的修辞感知图,用于通过文档的表达来解释复杂连续的“基本话语单元”。在这里,基本话语单位是时间活动中涉及的最小语义单位。
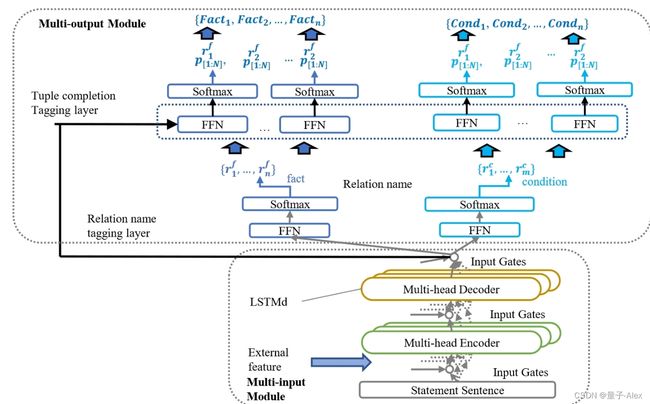
图18。MIMO模型[26]的架构,用于在文本上提取带有条件的事实。
6.2 条件知识图谱完成
条件知识图谱完成任务填充条件KG中的不完整三元组,例如(h,?,t,γ),(h,r,?,γ),和(h,r,t,?)。请注意,在这一节中,我们的主要焦点是完成时态知识图谱的方法。研究人员可以通过时态信息嵌入模型预测不完整的时态元组。TTransE[328]用时间嵌入向量扩展了TransE。HyTE[329]将时间戳视为匹配实体和关系嵌入的超平面。另一个有前途的方向是时态感知嵌入。在该流中,基于LSTM的模型[330]解释时间编码序列,而基于CNN的模型[331]捕获上下文的时间一致性。时间知识图谱的表示可以看作是沿时间维度的张量结构,这意味着张量分解可以用来完成时间知识图谱。张量分解的主要解有正则多边形分解和Tucker分解。正则多边形分解使用几个一秩张量的和来接近目标张量。许多时态知识图谱完成模型使用规范的多进制分解,例如[332]和[333]。塔克分解将目标张量分解为核张量和沿着目标张量的每个维度的多个张量之间的乘法。邵等[334]开发了一个基于Tucker分解的模型来解释时间语义关联,该模型增加了包括时间戳的表示的灵活性。SpliMe[335]通过静态模型获得时间查看的实体嵌入。时态知识图谱完成的另一个关键主题是时态知识推理。最近的研究兴趣集中在基于GCN的方法上。在这里,韩等[25]通过基于边缘注意分数扩展依赖于查询的干扰子图来利用历史上下文。荣格等[336]通过基于边缘的注意传播实现多跳时态推理,而Liu等[337]通过基于强化学习的模型增强时态知识图谱推理。此外,时间线中的事实不能忽略时间依赖性,例如在“工作”之前的“出生”。江[338]定义了包含非对称矩阵的评分函数,以保持用于推理的时间排序约束。填充不完整的一般条件元组有待进一步探索。元组可能包含不止一个条件,例如只在某个温度范围内发生的化学反应。对于这些复杂的场景,应该有一个系统的解决方案。我们建议读者也考虑因果发现方法[339]。
6.3 知识动态
许多研究人员对知识动力学的文献做出了贡献。很大一部分人使用RNN结构来理解历时依赖性,以便预测状态变化。例如,Know-evolve[340]涉及具有增强的RNN结构的多变量时间点过程,该结构学习时间进化表示函数。RE-NET[341]结合了一个邻域聚合器来捕获实体节点之间的并发交互。还设计了包含进化表示的模型,如MGraph[342]和DyERNIE[343]。格雷斯等[344]系统地构建一个神经潜在空间模型,该模型结合了异构知识图谱的进化信息。严等[345]改进了GCN模型捕获拓扑不变特征的能力。其思想是对齐不同时态知识图谱快照中的节点,并构建概念的动态配置文件。当不同类型的条件发生变化时,知识如何演变仍然具有挑战性——以结束新冠肺炎疫情所需的条件为例。我们建议读者参考因果特征选择方法[339]以及专家和多来源证据。
7.知识图谱存储
在本节中,我们将简要概述适用于不同数据环境的KG存储工具。早期的图形存储工作使用关系模型来延续构建的知识图谱。传统的RDBMS为表型数据库提供了可靠而快速的CRUD操作。开发人员还采用了深度优先遍历和最短路径搜索等图形算法来增强关系数据库[32]。这种类型的算法的代表性例子包括PostgreSQL[346]和filament 10。然而,对于关系数据库来说,处理稀疏KGs或为分布存储执行数据分区的成本可能非常高。键/值数据库是在大型知识图谱中保存集群的轻量级解决方案。此外,它们支持具有简化和灵活数据格式的分布式存储。Trinity[347]提供了一个高性能的内存键/值存储系统来管理具有数十亿节点的大型知识图谱,如Probase。CouchDB[348]使用复制机制来维护动态知识图谱。MapReduce技术自动将数据组转换为键/值映射。Hadoop 11支持知识的高吞吐量并行计算通过MapReduce存储图形。Pregel[349]开发了一种superstep机制,在顶点之间共享消息,用于并行计算。另一个有希望的方向是设计适合知识三重结构的图形数据库。Neo4j[350]是一个基于NoSQL的轻量级图形数据库,支持嵌入式动态知识图谱形存储。SOnes 12为KG数据库提供面向对象的查询。还开发了用于知识存储的新语言,例如资源描述框架(RDF)和网络本体语言(OWL)13。一些基于RDF的图形数据库优化了图形结构的存储。例如,gStore[349]通过子图匹配算法改进了RDF结构的知识图谱数据库。
8.关于知识图谱构建的探讨
研究人员为知识图谱构建的不同方面贡献了各种解决方案。然而,一些具有挑战性的问题和研究方向仍有待进一步讨论。
8.1 KG结构的长而复杂的语境
复杂的跨句或跨段语境阻碍了不同的KG结构子任务的实际应用,尤其是关系提取任务。值得提醒读者的是,复杂的环境不仅仅与长期依赖有关。姚等。[22]指出四种推理包括模式识别、共指推理、逻辑推理和常识推理,对于包含高阶上下文语义至关重要。在图19中给出了一个具体的例子。处理复杂长上下文的模型应该关注复杂的跨句模式,同时对多个语言对象进行推理。除了4.3.6节中的文档级提取模型之外,4.1.2节中的一些工作也通过实体类型的异构模型对文档级上下文进行建模。值得注意的是,在用户生成的文本中可能会出现模糊的表达,在没有外部信息的情况下,模型通常无法正确解释这些表达。推理的另一个挑战性问题是多跳推理。应该探索更多的语言结构来理解曲折的表达。需要背景知识来处理的断章取义表达式是KG构造的瓶颈。障碍主要有两个方面:1)自发的知识,2)证据支持。自发产生的常识知识经常被用来推导新的事实,
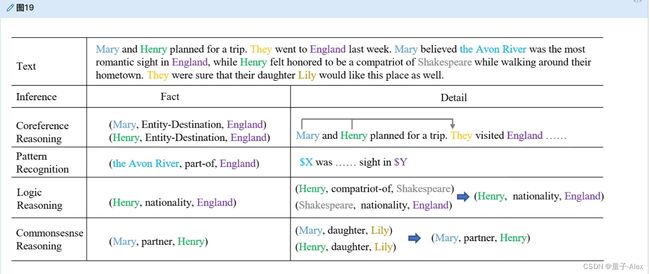 图19。文档中长上下文关系推理的一个例子
图19。文档中长上下文关系推理的一个例子
例如,有孩子的男人和女人应该是夫妻/伴侣,尽管这种信念有时是不准确的。如何获得常识性规则并使其适应合适的场景是一个重要的方向。同时,许多文档级数据集不包含正确逻辑路径的证据信息。像[357]这样的努力已经探索了关系提及的文档级证据结构。然而,不太可能预见到一个模型可以学会正确地组织线索,以解决所有场景中的事实(例如,验证哲学书籍中的结论)。我们认为长语境不仅仅是一个自然语言处理问题,模型[358]理解语言表达将是一个关键的方向。此外,还应考虑所提供数据源中的时间和地理信息等条件,以便严格理解上下文。
8.2 多模态知识图谱的构建与完成
多模态知识图谱可以完全表达和存储异构信息以供显示。多模态知识还可以应用于检测虚假或低质量的内容,例如具有不匹配图像的文本(例如,标有巴黎和伦敦图片的文档)。MMKG[353]是一个完成对图像信息进行推理的多模态元组的模型,而Dost等人。[354]探讨文本和图像的跨模态实体链接。多模态知识图谱的另一个问题是通过跨模态依赖解决单模态表达中的语义不完全性。我们用图20中的具体例子来说明这一挑战。

图20。通过跨模态依赖解决信息不完全性的一个例子。在这种情况下,文本表达“a用望远镜锯B。”不清楚。提取器只能通过解释图像数据中的边信息来确定人与“望远镜”之间的关系
8.3 联邦学习
对于隐私保护的基本要求,联合学习是一个有启发性的方向。从多个来源训练模型集合的KGs的联合设置是流行的策略之一。联合知识嵌入已经取得了重大进展,如FKGE[355]和FedE[356],它们禁止数据交换,同时在训练期间结合跨模态特征。然而,实体对齐是阻碍联合学习的矛盾瓶颈,需要在模型学习之前共享多源KGs,这将在知识融合过程中交换敏感信息。如何在联合特征的同时为加密实体对齐创建隐私保留的超级特征空间仍有待探索。为构建kg设计更隐私友好的模型对于敏感数据场景至关重要。我们在图21中说明开发联合模型的过程。
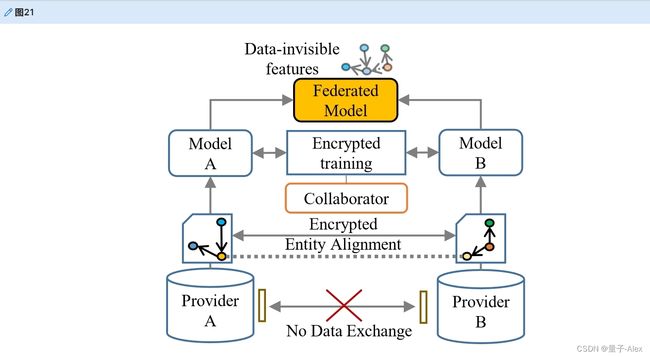
图21。在保护隐私的同时,从不同的知识提供者构建联合模型的说明。在此过程中,在多源数据部分上训练单独的模型之前,执行加密的实体对齐过程,然后合作者计算并聚合每个模型的加密梯度以防止泄漏。联合模型只保留数据——不可见的众包知识特征。
8.4 知识图谱构建任务中的高级语义与动态
最近的研究已经扩展到高级语义评估任务,如检测模棱两可[351]和用常识验证事实[352]来处理复杂的语言现象。解释文学表达,如明喻和隐喻,是智能知识图谱构建的未来方向,例如,“汤姆在2008年去了天堂。”意思是“汤姆,死于2008年”。开发或微调具有高级语义的预训练模型将是高生产率的起点。此外,已经对时态知识图谱的动力学进行了许多研究。然而,知识语义如何随着一般相关条件的演变仍然是一个未探索的领域。深入到启发性的问题,如“医务人员的专业社会网络如何随着疫情的阶段而变化?”可能有助于我们发现促进公共卫生政策制定的隐性因素。捕捉相关条件如何影响相关事实的动态是模拟一般人类知识的最终方向。
8.5 知识图谱构建中的人机协同
要求适当的用户完成和纠正知识图谱是在开放世界中获得未知事实的最终解决方案。为此,吴等[8]设计了HAO模型,通过让人类和机器协作来解决不同的建筑问题。基于HAO的主动学习模型,自动识别不同的角色(例如,领域专家(HI)、有组织的权威机构(OI)、计算系统(AI)等。)并将未确定的数据分配给适当的用户进行标记将是赋予知识图谱构建框架智慧的有前途的方向。我们在图22中给出了这一重要思想的图示。

图22。基于HAO的知识图谱构建主动学习案例。基于HAO的主动学习模型选择具有适当角色的用户来标记不确定样本。在这种情况下(如果隐私政策允许),约翰的国籍将由权威机构(OI)标记,而他的朋友将通过在他的社交网络中询问用户(HI)来找到。然后人工智能将从已知的事实中得出他的居住地。
8.6 跨语言知识图谱
构建跨语言知识图谱是一个长期目标,指的是整合分布在不同语言中的不平衡资源。Xlore[42]提供了一个通过深度学习方法对齐跨语言实体的启发性例子。然而,机器翻译仍然是跨语言任务的一个巨大瓶颈。首先,翻译过程中产生的错误和冲突会影响翻译的精细化。其次,用少数民族语言表达的数据资源可能不足以进行机器学习。在解决跨语言冲突的同时,准确地实现低资源知识的自动翻译是一个很有前途的方向。
8.7 端到端统一构建框架
端到端的提取方法,如基于GCN的框架,将知识获取的子任务统一为一个统一的提取任务,超越了管道设计。然而,将知识获取与知识提炼任务结合起来建立一个集成的联合模型仍然是一个巨大的瓶颈。寻找统一知识图谱的提取和细化的端到端框架可能是一个启发性的未来方向。提供高质量的现成解决方案避免了对组件进行手动调整的需要,并且考虑跨任务语义的解决方案将是一项值得的工作。此外,训练一个统一知识图谱构建的一般程序的框架将是一个值得解决的具有挑战性的多任务学习问题。
9.总结
通过本文,我们对知识图谱构建这一主题进行了全面的综述。具体来说,我们回顾了在不同场景中用于从各种数据类型构建、提炼和集成KGs的任务、方法、挑战和相关资源。为了探讨大数据环境的基本主题,我们系统地介绍了用于获取细粒度概念(实体类型)、处理低资源知识(fewshot场景中的提取任务)、理解大型语言对象(文档级关系提取)、复杂推理(逻辑和可解释推理)以及处理知识图谱中的条件结构(时间和一般条件)的paragon模型。此外,我们还提供了实用的KG工具包和项目简介。总之,知识图谱构建已经成为在人工智能应用中实现人类智能的关键主题。在未来,研究社区肯定会寻找更多的范例,在大规模异构、自主、复杂和不断发展的数据环境中赋予KGs智慧,同时加强知识社区之间的合作。
10.参考文献
[1] J. Liu, J. Ren, W. Zheng, L. Chi, I. Lee, and F. Xia, “Web of scholars: A scholar knowledge graph,” in SIGIR , 2020, pp. 2153–2156, 2020.
[2] X. Wang, X. He, Y. Cao, M. Liu, and T. Chua, “KGAT: knowledge graph attention network for recommendation,” in KDD, 2019, pp. 950–958, 2019.
[3] J. Bao, N. Duan, Z. Yan, M. Zhou, and T. Zhao, “Constraint-based question answering with knowledge graph,” in Proc. COLING, 2016, pp. 2503–2514, 2016. [4] K. D. Bollacker, R. P. Cook, and P. Tufts, “Freebase: A shared database of structured general human knowledge,” in Proc. AAAI-07, 2007, pp. 1962–1963, 2007.
[5] D. Vrandecic, “Wikidata: a new platform for collaborative data collection,” in Proc. WWW,2012, 2012 (Companion Volume), pp. 1063–1064, 2012.
[6] A. Yates, M. Banko, M. Broadhead, M. J. Cafarella, O. Etzioni, and S. Soderland, “Textrunner: Open information extraction on the web,” in HLT-NAACL, Proceedings, 2007, pp. 25–26, 2007.
[7] O. Etzioni, M. J. Cafarella, D. Downey, S. Kok, A. Popescu, T. Shaked, S. Soderland, D. S. Weld, and A. Yates, “Web-scale information extraction in knowitall: (preliminary results),” in Proc. WWW, 2004, pp. 100–110, 2004.
[8] M. Wu and X. Wu, “On big wisdom,” Knowl. Inf. Syst., vol. 58, no. 1, pp. 1–8, 2019.
[9] Z. Huang, W. Xu, and K. Yu, “Bidirectional LSTM-CRF models for sequence tagging,” CoRR, vol. abs/1508.01991, 2015.
[10] X. Ma and E. H. Hovy, “End-to-end sequence labeling via bi-directional lstm-cnns-crf,” in Proc. ACL, 2016, Volume 1: Long Papers, 2016.
[11] P. Xu and D. Barbosa, “Neural fine-grained entity type classification with hierarchy-aware loss,” in Proc. NAACL-HLT, 2018, Volume 1 (Long Papers), pp. 16–25, 2018.
[12] X. Ren, W. He, M. Qu, C. R. Voss, H. Ji, and J. Han, “Label noise reduction in entity typing by heterogeneous partial-label embedding,” in KDD, 2016, pp. 1825–1834, 2016.
[13] O. Ganea and T. Hofmann, “Deep joint entity disambiguation with local neural attention,” in Proc. EMNLP , 2017, pp. 2619–2629, 2017.
[14] P. Le and I. Titov, “Improving entity linking by modeling latent relations between mentions,” in Proc. ACL , 2018, Volume 1: Long Papers, pp. 1595–1604, 2018.
[15] K. Lee, L. He, M. Lewis, and L. Zettlemoyer, “End-to-end neural coreference resolution,” in Proc. EMNLP, 2017, pp. 188–197, 2017.
[16] D. Zeng, K. Liu, Y. Chen, and J. Zhao, “Distant supervision for relation extraction via piecewise convolutional neural networks,” in Proc. EMNLP, 2015, pp. 1753–1762, 2015.
[17] P. Zhou, W. Shi, J. Tian, Z. Qi, B. Li, H. Hao, and B. Xu, “Attention-based bidirectional long short-term memory networks for relation classification,” in Proc. ACL, 2016, Volume 2: Short Papers, 2016.
[18] H. Zhang, D. Khashabi, Y. Song, and D. Roth, “Transomcs: From linguistic graphs to commonsense knowledge,” in Proc. IJCAI, 2020, pp. 4004–4010, 2020.
[19] H. Zhang, X. Liu, H. Pan, H. Ke, J. Ou, T. Fang, and Y. Song, “ASER: towards large-scale commonsense knowledge acquisition via higher-order selectional preference over eventualities,” CoRR, vol. abs/2104.02137, 2021.
[20] W. Xin-Dong, S. Shao-Jing, J. Ting-Ting, B. Chen-Yang, and W. Ming-Hui, “Huapu-cp: from knowledge graphs to a data central-platform,” Acta Automatica Sinica, vol. 46, no. 10, pp. 2045–2059, 2020.
[21] J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: pre-training of deep bidirectional transformers for language understanding,” in NAACL-HLT , 2019, Volume 1 (Long and Short Papers), pp. 4171–4186, 2019.
[22] Y. Yao, D. Ye, P. Li, X. Han, Y. Lin, Z. Liu, Z. Liu, L. Huang, J. Zhou, and M. Sun, “Docred: A large-scale document-level relation extraction dataset,” in Proc. ACL, 2019, Volume 1: Long Papers, pp. 764–777, 2019.
[23] S. Riedel, L. Yao, and A. McCallum, “Modeling relations and their mentions without labeled text,” in ECML PKDD, 2010, Proceedings, Part III, vol. 6323, pp. 148–163, 2010.
[24] X. Wang, X. Han, Y. Lin, Z. Liu, and M. Sun, “Adversarial multi-lingual neural relation extraction,” in Proc. COLING, 2018, pp. 1156–1166, 2018.
[25] Z. Han, P. Chen, Y. Ma, and V. Tresp, “Explainable subgraph reasoning for forecasting on temporal knowledge graphs,” in ICLR, 2021.
[26] T. Jiang, T. Zhao, B. Qin, T. Liu, N. V. Chawla, and M. Jiang, “Multi-input multi-output sequence labeling for joint extraction of fact and condition tuples from scientific text,” in Proc. EMNLP-IJCNLP, 2019, pp. 302–312, 2019.
[27] A. Pradhan, K. K. Todi, A. Selvarasu, and A. Sanyal, “Knowledge graph generation with deep active learning,” in IJCNN , 2020, pp. 1–8, 2020.
[28] X. Wu, X. Zhu, G. Wu, and W. Ding, “Data mining with big data,” IEEE Trans. Knowl. Data Eng., vol. 26, no. 1, pp. 97–107, 2014.
[29] A. Hogan, E. Blomqvist, M. Cochez, C. d’Amato, G. de Melo, C. Gutiérrez, S. Kirrane, J. E. L. Gayo, R. Navigli, S. Neumaier, A. N. Ngomo, A. Polleres, S. M. Rashid, A. Rula, L. Schmelzeisen, J. Sequeda, S. Staab, and A. Zimmermann, Knowledge Graphs. Synthesis Lectures on Data, Semantics, and Knowledge, Morgan & Claypool Publishers, 2021.
[30] H. Paulheim, “Knowledge graph refinement: A survey of approaches and evaluation methods,” Semantic Web, vol. 8, no. 3, pp. 489–508, 2017.
[31] X. Wu, J. Wu, X. Fu, J. Li, P. Zhou, and X. Jiang, “Automatic knowledge graph construction: A report on the 2019 ICDM/ICBK contest,” in ICDM, 2019, pp. 1540–1545, 2019.
[32] J. Yan, C. Wang, W. Cheng, M. Gao, and A. Zhou, “A retrospective of knowledge graphs,” Frontiers Comput. Sci., vol. 12, no. 1, pp. 55–74, 2018.
[33] T. Nayak, N. Majumder, P. Goyal, and S. Poria, “Deep neural approaches to relation triplets extraction: a comprehensive survey,” Cogn. Comput., vol. 13, no. 5, pp. 1215–1232, 2021.
[34] S. Pawar, P. Bhattacharyya, and G. K. Palshikar, “Techniques for jointly extracting entities and relations: A survey,” CoRR, vol. abs/2103.06118, 2021.
[35] S. Ji, S. Pan, E. Cambria, P. Marttinen, and P. S. Yu, “A survey on knowledge graphs: Representation, acquisition, and applications,” IEEE Trans. Neural Networks Learn. Syst., vol. 33, no. 2, pp. 494–514, 2022.
[36] S. Arora, “A survey on graph neural networks for knowledge graph completion,” CoRR, vol. abs/2007.12374, 2020.
[37] B. Cai, Y. Xiang, L. Gao, H. Zhang, Y. Li, and J. Li, “Temporal knowledge graph completion: A survey,” CoRR, vol. abs/2201.08236, 2022.
[38] Q. Wang, Z. Mao, B. Wang, and L. Guo, “Knowledge graph embedding: A survey of approaches and applications,” IEEE Trans. Knowl. Data Eng., vol. 29, no. 12, pp. 2724–2743, 2017.
[39] L. Ehrlinger and W. Wöß, “Towards a definition of knowledge graphs,” in SEMANTiCS, SuCCESS’16, 2016, vol. 1695 of CEUR Workshop Proceedings, 2016.
[40] S. Auer, C. Bizer, G. Kobilarov, J. Lehmann, R. Cyganiak, and Z. G. Ives, “Dbpedia: A nucleus for a web of open data,” in ISWC + ASWC, 2007, vol. 4825, pp. 722–735, 2007.
[41] W. Wu, H. Li, H. Wang, and K. Q. Zhu, “Probase: a probabilistic taxonomy for text understanding,” in SIGMOD , 2012, pp. 481–492, 2012.
[42] Z. Wang, J. Li, Z. Wang, S. Li, M. Li, D. Zhang, Y. Shi, Y. Liu, P. Zhang, and J. Tang, “Xlore: A large-scale englishchinese bilingual knowledge graph,” in Proc. ISWC, 2013, Posters & Demonstrations Track, vol. 1035 of CEUR Workshop Proceedings, pp. 121–124, 2013.
[43] B. Xu, Y. Xu, J. Liang, C. Xie, B. Liang, W. Cui, and Y. Xiao, “Cn-dbpedia: A never-ending chinese knowledge extraction system,” in IEA/AIE, 2017, Proceedings, Part II, vol. 10351, pp. 428–438, 2017.
[44] F. M. Suchanek, G. Kasneci, and G. Weikum, “Yago: a core of semantic knowledge,” in Proc. WWW, 2007, pp. 697–706, 2007.
[45] M. Mintz, S. Bills, R. Snow, and D. Jurafsky, “Distant supervision for relation extraction without labeled data,” in Proc. ACL , 2009, pp. 1003–1011, 2009.
[46] J. Chen, A. Wang, J. Chen, Y. Xiao, Z. Chu, J. Liu, J. Liang, and W. Wang, “Cn-probase: A data-driven approach for large-scale chinese taxonomy construction,” in Proc. ICDE, 2019, pp. 1706–1709, 2019.
[47] G. A. Miller, “Wordnet: A lexical database for english,” Commun. ACM, vol. 38, no. 11, pp. 39–41, 1995.
[48] R. Navigli and S. P. Ponzetto, “Babelnet: Building a very large multilingual semantic network,” in Proc. ACL, 2010, pp. 216–225, 2010.
[49] H. Liu and P. Singh, “Conceptnet—a practical commonsense reasoning tool-kit,” BT technology journal, vol. 22, no. 4, pp. 211–226, 2004.
[50] Z. Dong and Q. Dong, “Hownet - a hybrid language and knowledge resource,” in ICNLP, 2003 , Proceedings, pp. 820–824, 2003.
[51] S. Han, Y. Zhang, Y. Ma, C. Tu, Z. Guo, Z. Liu, and M. Sun, “Thuocl: Tsinghua open chinese lexicon,” Tsinghua University, 2016.
[52] C. Matuszek, J. Cabral, M. J. Witbrock, and J. DeOliveira, “An introduction to the syntax and content of cyc,” in Papers from the 2006 AAAI Spring Symposium, Technical Report SS-06-05, 2006, pp. 44–49, 2006.
[53] T. Steiner, R. Verborgh, R. Troncy, J. Gabarró, and R. V. de Walle, “Adding realtime coverage to the google knowledge graph,” in Proc. ISWC, 2012, vol. 914 of CEUR Workshop Proceedings, 2012.
[54] R. J. Roberts, “Pubmed central: The genbank of the published literature,” Proceedings of the National Academy of Sciences of the United States of America, vol. 98, no. 2, p. 381, 2001.
[55] D. S. Wishart, C. Knox, A. Guo, S. Shrivastava, M. Hassanali, P. Stothard, Z. Chang, and J. Woolsey, “Drugbank: a comprehensive resource for in silico drug discovery and exploration,” Nucleic Acids Res., vol. 34, no. Database-Issue, pp. 668–672, 2006.
[56] J. Tang, D. Zhang, and L. Yao, “Social network extraction of academic researchers,” in Proc. ICDM, 2007, pp. 292–301, 2007.
[57] F. Zhang, X. Liu, J. Tang, Y. Dong, P. Yao, J. Zhang, X. Gu, Y. Wang, B. Shao, R. Li, and K. Wang, “OAG: toward linking large-scale heterogeneous entity graphs,” in KDD, 2019, pp. 2585–2595, 2019.
[58] H. Chen, N. Hu, G. Qi, H. Wang, Z. Bi, J. Li, and F. Yang, “Openkg chain: A blockchain infrastructure for open knowledge graphs,” Data Intell., vol. 3, no. 2, pp. 205–227, 2021.
[59] W. Gong-Qing, H. Jun, L. Li, X. Zhe-Hao, L. Peng-Cheng, H. Xue-Gang, and W. Xin-Dong, “Online web news extraction via tag path feature fusion. ruan jian xue bao,” Journal of Software, vol. 27, no. 3, pp. 714–735, 2016.
[60] A. Fader, S. Soderland, and O. Etzioni, “Identifying relations for open information extraction,” in Proc. EMNLP, 2011.
[61] Mausam, M. Schmitz, S. Soderland, R. Bart, and O. Etzioni, “Open language learning for information extraction,” in Proc. EMNLP-CoNLL, ACL 2012, pp. 523–534, 2012.
[62] S. Bird, “NLTK: the natural language toolkit,” in ACL, 2006 (N. Calzolari, C. Cardie, and P. Isabelle, eds.), 2006.
[63] C. D. Manning, M. Surdeanu, J. Bauer, J. R. Finkel, S. Bethard, and D. McClosky, “The stanford corenlp natural language processing toolkit,” in Proc. ACL, 2014, pp. 55–60, 2014.
[64] Z. Zhang, “Effective and efficient semantic table interpretation using tableminer+,” Semantic Web, vol. 8, no. 6, pp. 921–957, 2017.
[65] M. Cremaschi, A. Rula, A. Siano, and F. D. Paoli, “Mantistable: A tool for creating semantic annotations on tabular data,” in ESWC 2019 Satellite Events, 2019, Revised Selected Papers, vol. 11762, pp. 18–23, 2019.
[66] M. Honnibal and I. Montani, “spaCy 2: Natural language understanding with Bloom embeddings, convolutional neural networks and incremental parsing.” To appear, 2017.
[67] X. Han, T. Gao, Y. Yao, D. Ye, Z. Liu, and M. Sun, “OpenNRE: An open and extensible toolkit for neural relation extraction,” in Proceedings of EMNLP-IJCNLP: System Demonstrations, pp. 169–174, 2019.
[68] X. Han, S. Cao, X. Lv, Y. Lin, Z. Liu, M. Sun, and J. Li, “Openke: An open toolkit for knowledge embedding,” in Proc. EMNLP, 2018, pp. 139–144, 2018.
[69] Z. Sun, Q. Zhang, W. Hu, C. Wang, M. Chen, F. Akrami, and C. Li, “A benchmarking study of embedding-based entity alignment for knowledge graphs,” Proc. VLDB Endow., vol. 13, no. 11, pp. 2326–2340, 2020.
[70] A. Grover and J. Leskovec, “node2vec: Scalable feature learning for networks,” in Proceedings of KDD, pp. 855–864, 2016.
[71] J. Tang, M. Qu, M. Wang, M. Zhang, J. Yan, and Q. Mei, “Line: Large-scale information network embedding,” in Proceedings of WWW, pp. 1067–1077, 2015. [72] W. Hu and Y. Qu, “Falcon-ao: A practical ontology matching system,” J. Web Semant., vol. 6, no. 3, pp. 237–239, 2008.
[73] C. Chang, C. Hsu, and S. Lui, “Automatic information extraction from semi-structured web pages by pattern discovery,” Decis. Support Syst., vol. 35, no. 1, pp. 129–147, 2003.
[74] C. Hsu and M. Dung, “Generating finite-state transducers for semi-structured data extraction from the web,” Inf. Syst., vol. 23, no. 8, pp. 521–538, 1998.
[75] P. B. Golgher, A. S. da Silva, A. H. F. Laender, and B. A. Ribeiro-Neto, “Bootstrapping for example-based data extraction,” in Proc. CIKM, 2001, pp. 371–378, 2001.
[76] A. Carlson and C. Schafer, “Bootstrapping information extraction from semi-structured web pages,” in ECML/PKDD, 2008, Proceedings, Part I, vol. 5211, pp. 195–210, 2008.
[77] B. Adelberg, “Nodose - A tool for semi-automatically extracting semi-structured data from text documents,” in SIGMOD, 1998 (L. M. Haas and A. Tiwary, eds.), pp. 283–294, 1998.
[78] A. H. F. Laender, B. A. Ribeiro-Neto, and A. S. da Silva, “Debye - data extraction by example,” Data Knowl. Eng., vol. 40, no. 2, pp. 121–154, 2002.
[79] A. Finn, N. Kushmerick, and B. Smyth, “Fact or fiction: Content classification for digital libraries,” in DELOS , 2001, vol. 01/W03 of ERCIM Workshop Proceedings, 2001.
[80] T. Weninger, W. H. Hsu, and J. Han, “CETR: content extraction via tag ratios,” in Proc. WWW, 2010, pp. 971–980, 2010.
[81] F. Sun, D. Song, and L. Liao, “DOM based content extraction via text density,” in SIGIR, 2011, pp. 245–254, 2011.
[82] G. Wu, L. Li, X. Hu, and X. Wu, “Web news extraction via path ratios,” in CIKM, 2013, pp. 2059–2068, 2013.
[83] D. Cai, S. Yu, J. Wen, and W. Ma, “Extracting content structure for web pages based on visual representation,” in APWeb, 2003, Proceedings, vol. 2642, pp. 406–417, 2003.
[84] Y. Wang and J. Hu, “A machine learning based approach for table detection on the web,” in WWW, 2002, pp. 242–250, 2002.
[85] M. J. Cafarella, A. Y. Halevy, Y. Zhang, D. Z. Wang, and E. Wu, “Uncovering the relational web,” in 11th International Workshop on the Web and Databases, WebDB, 2008.
[86] J. Eberius, K. Braunschweig, M. Hentsch, M. Thiele, A. Ahmadov, and W. Lehner, “Building the dresden web table corpus: A classification approach,” in BDC , 2015, pp. 41–50, 2015.
[87] M. J. Cafarella, A. Y. Halevy, and N. Khoussainova, “Data integration for the relational web,” Proc. VLDB Endow., vol. 2, no. 1, pp. 1090–1101, 2009.
[88] S. Zhang and K. Balog, “Web table extraction, retrieval, and augmentation: A survey,” ACM Trans. Intell. Syst. Technol., vol. 11, no. 2, pp. 13:1–13:35, 2020.
[89] N. Kushmerick, “Wrapper induction: Efficiency and expressiveness,” Artificial intelligence, vol. 118, no. 1-2, pp. 15–68, 2000.
[90] D. Buttler, L. Liu, and C. Pu, “A fully automated object extraction system for the world wide web,” in Proc. ICDCS ,2001, pp. 361–370, 2001.
[91] B. M. Sundheim, “The message understanding conferences,” in TIPSTER TEXT PROGRAM PHASE II: Proceedings of a Workshop held at Vienna, 1996, pp. 35–37, 1996.
[92] S. Thenmalar, B. Jagan, and T. V. Geetha, “Semi-supervised bootstrapping approach for named entity recognition,” CoRR, vol. abs/1511.06833, 2015.
[93] G. Zhou and J. Su, “Named entity recognition using an hmm-based chunk tagger,” in Proc. ACL, 2002, pp. 473–480, 2002.
[94] J. R. Finkel, T. Grenager, and C. D. Manning, “Incorporating non-local information into information extraction systems by gibbs sampling,” in Proc. ACL, 2005, pp. 363–370, 2005.
[95] J. Zhu, Z. Nie, J. Wen, B. Zhang, and W. Ma, “2d conditional random fields for web information extraction,” in Proc. ICML, 2005, vol. 119, pp. 1044–1051, 2005.
[96] C. Sutton, K. Rohanimanesh, and A. McCallum, “Dynamic conditional random fields: factorized probabilistic models for labeling and segmenting sequence data,” in Proc. ICML, 2004, vol. 69, 2004.
[97] J. Zhu, Z. Nie, J. Wen, B. Zhang, and W. Ma, “Simultaneous record detection and attribute labeling in web data extraction,” in KDD, 2006, pp. 494–503, 2006.
[98] A. Finn and N. Kushmerick, “Multi-level boundary classification for information extraction,” in Proc. ECML, 2004, vol. 3201, pp. 111–122, 2004.
[99] J. Li, A. Sun, J. Han, and C. Li, “A survey on deep learning for named entity recognition,” IEEE Trans. Knowl. Data Eng., vol. 34, no. 1, pp. 50–70, 2022.
[100] R. Collobert, J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu, and P. P. Kuksa, “Natural language processing (almost) from scratch,” J. Mach. Learn. Res., vol. 12, pp. 2493–2537, 2011.
[101] E. Strubell, P. Verga, D. Belanger, and A. McCallum, “Fast and accurate entity recognition with iterated dilated convolutions,” in Proc. EMNLP, 2017, pp. 2670–2680, 2017.
[102] L. Li, L. Jin, Z. Jiang, D. Song, and D. Huang, “Biomedical named entity recognition based on extended recurrent neural networks,” in BIBM , 2015, pp. 649–652, 2015.
[103] T. H. Nguyen, A. Sil, G. Dinu, and R. Florian, “Toward mention detection robustness with recurrent neural networks,” CoRR, vol. abs/1602.07749, 2016.
[104] L. Luo, Z. Yang, P. Yang, Y. Zhang, L. Wang, H. Lin, and J. Wang, “An attention-based bilstm-crf approach to document-level chemical named entity recognition,” Bioinform., vol. 34, no. 8, pp. 1381–1388, 2018.
[105] A. Z. Gregoric, Y. Bachrach, P. Minkovsky, S. Coope, and B. Maksak, “Neural named entity recognition using a self-attention mechanism,” in ICTAI, 2017, pp. 652–656, 2017.
[106] A. Cetoli, S. Bragaglia, A. D. O’Harney, and M. Sloan, “Graph convolutional networks for named entity recognition,” in Proc. TLT, 2018, pp. 37–45, 2018.
[107] C. Dogan, A. Dutra, A. Gara, A. Gemma, L. Shi, M. Sigamani, and E. Walters, “Fine-grained named entity recognition using elmo and wikidata,” CoRR, vol. abs/1904.10503, 2019.
[108] M. Liu, Z. Tu, T. Zhang, T. Su, X. Xu, and Z. Wang, “Ltp: A new active learning strategy for crf-based named entity recognition,” Neural Processing Letters, pp. 1–22, 2022.
[109] I. Yamada, A. Asai, H. Shindo, H. Takeda, and Y. Matsumoto, “LUKE: deep contextualized entity representations with entity-aware self-attention,” in EMNLP, 2020, pp. 6442–6454, 2020.
[110] S. Shimaoka, P. Stenetorp, K. Inui, and S. Riedel, “Neural architectures for fine-grained entity type classification,” in Proc. EACL, 2017, Volume 1: Long Papers, pp. 1271–1280, 2017.
[111] S. Zhang, K. Duh, and B. V. Durme, “Fine-grained entity typing through increased discourse context and adaptive classification thresholds,” in Proc. SEM@NAACL-HLT, 2018, pp. 173–179, 2018.
[112] C. Moon, P. Jones, and N. F. Samatova, “Learning entity type embeddings for knowledge graph completion,” in Proc. CIKM, 2017, pp. 2215–2218, 2017. [113] J. Hao, M. Chen, W. Yu, Y. Sun, and W. Wang, “Universal representation learning of knowledge bases by jointly embedding instances and ontological concepts,” in KDD, 2019, pp. 1709–1719, 2019.
[114] Y. Zhao, A. Zhang, R. Xie, K. Liu, and X. Wang, “Connecting embeddings for knowledge graph entity typing,” in Proc. ACL, 2020, pp. 6419–6428, 2020. [115] H. Jin, L. Hou, and J. Li, “Type hierarchy enhanced heterogeneous network embedding for fine-grained entity typing in knowledge bases,” in NLP-NABD, 2018, Proceedings, vol. 11221, pp. 170–182, 2018.
[116] H. Jin, L. Hou, J. Li, and T. Dong, “Attributed and predictive entity embedding for fine-grained entity typing in knowledge bases,” in Proc. COLING , 2018, pp. 282–292, 2018.
[117] Y. Cao, L. Hou, J. Li, Z. Liu, C. Li, X. Chen, and T. Dong, “Joint representation learning of cross-lingual words and entities via attentive distant supervision,” in Proc. EMNLP, 2018, pp. 227–237, 2018.
[118] G. Limaye, S. Sarawagi, and S. Chakrabarti, “Annotating and searching web tables using entities, types and relationships,” Proc. VLDB Endow., vol. 3, no. 1, pp. 1338–1347, 2010.
[119] C. S. Bhagavatula, T. Noraset, and D. Downey, “Tabel: Entity linking in web tables,” in ISWC, 2015, Proceedings, Part I, vol. 9366, pp. 425–441, 2015.
[120] T. Wu, S. Yan, Z. Piao, L. Xu, R. Wang, and G. Qi, “Entity linking in web tables with multiple linked knowledge bases,” in JIST, 2016, Revised Selected Papers, vol. 10055, pp. 239–253, 2016.
[121] V. Efthymiou, O. Hassanzadeh, M. Rodriguez-Muro, and V. Christophides, “Matching web tables with knowledge base entities: From entity lookups to entity embeddings,” in Proc. ISWC, 2017, Part I, vol. 10587, pp. 260–277, 2017.
[122] V. Mulwad, T. Finin, Z. Syed, and A. Joshi, “Using linked data to interpret tables,” in Proceedings of the First International Workshop on Consuming Linked Data, 2010, vol. 665 of CEUR Workshop Proceedings, 2010.
[123] Y. Guo, W. Che, T. Liu, and S. Li, “A graph-based method for entity linking,” in IJCNLP, 2011, pp. 1010–1018, 2011.
[124] X. Han, L. Sun, and J. Zhao, “Collective entity linking in web text: a graph-based method,” in SIGIR, 2011, pp. 765–774, 2011.
[125] W. Shen, J. Wang, P. Luo, and M. Wang, “LIEGE: : link entities in web lists with knowledge base,” in KDD, 2012, pp. 1424–1432, 2012.
[126] A. Bagga and B. Baldwin, “Entity-based cross-document coreferencing using the vector space model,” in COLING-ACL , 1998, Proceedings of the Conference, pp. 79–85, 1998.
[127] I. Lasek and P. Vojtás, “Various approaches to text representation for named entity disambiguation,” in IIWAS , 2012, pp. 256–262, 2012.
[128] H. Huang, L. P. Heck, and H. Ji, “Leveraging deep neural networks and knowledge graphs for entity disambiguation,” CoRR, vol. abs/1504.07678, 2015. [129] W. Fang, J. Zhang, D. Wang, Z. Chen, and M. Li, “Entity disambiguation by knowledge and text jointly embedding,” in SIGNLL, CoNLL, ACL, 2016, pp. 260–269, 2016.
[130] S. J. Pan, Z. Toh, and J. Su, “Transfer joint embedding for cross-domain named entity recognition,” ACM Trans. Inf. Syst., vol. 31, no. 2, p. 7, 2013.
[131] B. Y. Lin and W. Lu, “Neural adaptation layers for cross-domain named entity recognition,” in Proc. EMNLP, 2018, pp. 2012–2022, 2018.
[132] K. Narasimhan, A. Yala, and R. Barzilay, “Improving information extraction by acquiring external evidence with reinforcement learning,” in Proc. EMNLP, 2016, pp. 2355–2365, 2016.
[133] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. A. Riedmiller, A. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, and D. Hassabis, “Human-level control through deep reinforcement learning,” Nat., vol. 518, no. 7540, pp. 529–533, 2015.
[134] Y. Yang, W. Chen, Z. Li, Z. He, and M. Zhang, “Distantly supervised NER with partial annotation learning and reinforcement learning,” in Proc. COLING, 2018, pp. 2159–2169, 2018.
[135] J. T. Zhou, H. Zhang, D. Jin, H. Zhu, M. Fang, R. S. M. Goh, and K. Kwok, “Dual adversarial neural transfer for low-resource named entity recognition,” in Proc. ACL , 2019, Volume 1: Long Papers, pp. 3461–3471, 2019.
[136] P. Cao, Y. Chen, K. Liu, J. Zhao, and S. Liu, “Adversarial transfer learning for chinese named entity recognition with self-attention mechanism,” in Proc. EMNLP, 2018, pp. 182–192, 2018.
[137] J. Li, D. Ye, and S. Shang, “Adversarial transfer for named entity boundary detection with pointer networks,” in Proc. IJCAI, 2019, pp. 5053–5059, 2019.
[138] Y. Shen, H. Yun, Z. C. Lipton, Y. Kronrod, and A. Anandkumar, “Deep active learning for named entity recognition,” in ICLR, 2018, Conference Track Proceedings, 2018.
[139] Y. Ma, E. Cambria, and S. Gao, “Label embedding for zero-shot fine-grained named entity typing,” in COLING, 2016, Proceedings of the Conference: Technical Papers, pp. 171–180, 2016.
[140] T. Zhang, C. Xia, C. Lu, and P. S. Yu, “MZET: memory augmented zero-shot fine-grained named entity typing,” in Proc. COLING, 2020, pp. 77–87, 2020.
[141] A. Sil and A. Yates, “Re-ranking for joint named-entity recognition and linking,” in CIKM, 2013, pp. 2369–2374, 2013.
[142] X. Liu, M. Zhou, X. Zhou, Z. Fu, and F. Wei, “Joint inference of named entity recognition and normalization for tweets,” in Proc. ACL,2012, Volume 1: Long Papers, pp. 526–535, 2012.
[143] M. C. Phan, A. Sun, Y. Tay, J. Han, and C. Li, “Pair-linking for collective entity disambiguation: Two could be better than all,” IEEE Trans. Knowl. Data Eng., vol. 31, no. 7, pp. 1383–1396, 2019.
[144] J. Cai and M. Strube, “End-to-end coreference resolution via hypergraph partitioning,” in Proc. COLING, 2010, pp. 143151, 2010.
[145] E. Sapena, L. Padró, and J. Turmo, “A constraint-based hypergraph partitioning approach to coreference resolution,” Comput. Linguistics, vol. 39, no. 4, pp. 847–884, 2013.
[146] D. L. Bean and E. Riloff, “Unsupervised learning of contextual role knowledge for coreference resolution,” in HLTNAACL, 2004, pp. 297–304, 2004.
[147] E. R. Fernandes, C. N. dos Santos, and R. L. Milidiú, “Latent structure perceptron with feature induction for unrestricted coreference resolution,” in EMNLP-CoNLL, ACL, 2012, pp. 41–48, 2012.
[148] W. M. Soon, H. T. Ng, and C. Y. Lim, “A machine learning approach to coreference resolution of noun phrases,” Comput. Linguistics, vol. 27, no. 4, pp. 521–544, 2001.
[149] M. Recasens, M. de Marneffe, and C. Potts, “The life and death of discourse entities: Identifying singleton mentions,” in NAACL-HLT, Proceedings, 2013, pp. 627–633, 2013.
[150] M. A. ur Rahman and V. Ng, “Supervised models for coreference resolution,” in Proc. EMNLP, 2009, A meeting of SIGDAT, a Special Interest Group of the ACL, pp. 968–977, 2009.
[151] V. Stoyanov and J. Eisner, “Easy-first coreference resolution,” in Proc. COLING ,2012, pp. 2519–2534, 2012.
[152] X. Xi, G. Zhou, F. Hu, and B. Fu, “A convolutional deep neural network for coreference resolution via modeling hierarchical features,” in IScIDE, 2015, Revised Selected Papers, Proceedings, Part II, vol. 9243, pp. 361–372, 2015.
[153] J. Wu and W. Ma, “A deep learning framework for coreference resolution based on convolutional neural network,” in ICSC , 2017, pp. 61–64, 2017.
[154] S. Wiseman, A. M. Rush, and S. M. Shieber, “Learning global features for coreference resolution,” in NAACL-HLT, 2016, pp. 994–1004, 2016.
[155] J. Gu, Z. Ling, and N. Indurkhya, “A study on improving end-to-end neural coreference resolution,” in NLP-NABD, 2018, Proceedings, vol. 11221, pp. 159–169, 2018.
[156] R. Zhang, C. N. dos Santos, M. Yasunaga, B. Xiang, and D. R. Radev, “Neural coreference resolution with deep biaffine attention by joint mention detection and mention clustering,” in Proc. ACL, 2018, Volume 2: Short Papers, pp. 102–107, 2018.
[157] J. Ma, J. Liu, Y. Li, X. Hu, Y. Pan, S. Sun, and Q. Lin, “Jointly optimized neural coreference resolution with mutual attention,” in WSDM , 2020, pp. 402–410, 2020.
[158] K. Clark and C. D. Manning, “Deep reinforcement learning for mention-ranking coreference models,” in Proc. EMNLP, 2016, pp. 2256–2262, 2016.
[159] G. Durrett and D. Klein, “Easy victories and uphill battles in coreference resolution,” in Proc. EMNLP, 2013, A meeting of SIGDAT, a Special Interest Group of the ACL, pp. 1971–1982, 2013.
[160] S. Martschat and M. Strube, “Latent structures for coreference resolution,” Trans. Assoc. Comput. Linguistics, vol. 3, pp. 405–418, 2015.
[161] K. Chakrabarti, S. Chaudhuri, T. Cheng, and D. Xin, “A framework for robust discovery of entity synonyms,” in KDD, 2012, pp. 1384–1392, 2012.
[162] R. C. Bunescu and R. J. Mooney, “Learning to extract relations from the web using minimal supervision,” in Proc. ACL, 2007.
[163] F. Reichartz, H. Korte, and G. Paass, “Semantic relation extraction with kernels over typed dependency trees,” in KDD, 2010, pp. 773–782, 2010.
[164] D. Zelenko, C. Aone, and A. Richardella, “Kernel methods for relation extraction,” in Proc. EMNLP, 2002, pp. 71–78, 2002.
[165] D. Zeng, K. Liu, S. Lai, G. Zhou, and J. Zhao, “Relation classification via convolutional deep neural network,” in Proc. COLING, 2014, pp. 2335–2344, 2014. [166] T. H. Nguyen and R. Grishman, “Relation extraction: Perspective from convolutional neural networks,” in Proc. VS@NAACL-HLT, 2015, pp. 39–48, 2015. [167] M. Miwa and M. Bansal, “End-to-end relation extraction using lstms on sequences and tree structures,” in Proc. ACL, 2016, Volume 1: Long Papers, 2016. [168] Y. Shen and X. Huang, “Attention-based convolutional neural network for semantic relation extraction,” in Proc. COLING, 2016, pp. 2526–2536, 2016. [169] L. Wang, Z. Cao, G. de Melo, and Z. Liu, “Relation classification via multi-level attention cnns,” in Proc. ACL 2016, Volume 1: Long Papers, 2016.
[170] Y. Zhao, H. Wan, J. Gao, and Y. Lin, “Improving relation classification by entity pair graph,” in Proc. ACML, 2019, vol. 101, pp. 1156–1171, 2019.
[171] Z. Guo, Y. Zhang, and W. Lu, “Attention guided graph convolutional networks for relation extraction,” in Proc. ACL,2019, Volume 1: Long Papers, pp. 241–251, 2019.
[172] K. Zhao, H. Xu, Y. Cheng, X. Li, and K. Gao, “Representation iterative fusion based on heterogeneous graph neural network for joint entity and relation extraction,” Knowl. Based Syst., vol. 219, p. 106888, 2021.
[173] A. D. N. Cohen, S. Rosenman, and Y. Goldberg, “Relation extraction as two-way span-prediction,” CoRR, vol. abs/2010.04829, 2020.
[174] N. FitzGerald, O. Täckström, K. Ganchev, and D. Das, “Semantic role labeling with neural network factors,” in Proc. EMNLP, 2015, pp. 960–970, 2015.
[175] M. Roth and M. Lapata, “Neural semantic role labeling with dependency path embeddings,” in Proc. ACL 2016, Volume 1: Long Papers, 2016.
[176] V. Mulwad, T. Finin, and A. Joshi, “Semantic message passing for generating linked data from tables,” in ISWC, 2013 , Proceedings, Part I, vol. 8218, pp. 363–378, 2013.
[177] Z. Chen and M. J. Cafarella, “Automatic web spreadsheet data extraction,” in 3RD International Workshop on Semantic Search over the Web, SSW ’13, 2013, pp. 1:1–1:8, 2013.
[178] J. Zhu, Z. Nie, X. Liu, B. Zhang, and J. Wen, “Statsnowball: a statistical approach to extracting entity relationships,” in Proc. WWW, 2009, pp. 101–110, 2009.
[179] S. Brin, “Extracting patterns and relations from the world wide web,” in The World Wide Web and Databases, International Workshop WebDB’98 , 1998, Selected Papers, vol. 1590, pp. 172–183, 1998.
[180] E. Agichtein and L. Gravano, “Snowball: extracting relations from large plain-text collections,” in Proc. ACM, 2000, pp. 85–94, 2000.
[181] M. Jiang, J. Shang, T. Cassidy, X. Ren, L. M. Kaplan, T. P. Hanratty, and J. Han, “Metapad: Meta pattern discovery from massive text corpora,” in KDD, 2017, pp. 877–886, 2017.
[182] Y. Ahmad, T. Antoniu, S. Goldwater, and S. Krishnamurthi, “A type system for statically detecting spreadsheet errors,” in ASE , 2003, pp. 174–183, 2003.
[183] Y. A. Sekhavat, F. D. Paolo, D. Barbosa, and P. Merialdo, “Knowledge base augmentation using tabular data,” in Proc. WWW, 2014, vol. 1184 of CEUR Workshop Proceedings, 2014.
[184] E. Muñoz, A. Hogan, and A. Mileo, “Using linked data to mine RDF from wikipedia’s tables,” in WSDM, 2014, pp. 533–542, 2014.
[185] S. Krause, H. Li, H. Uszkoreit, and F. Xu, “Large-scale learning of relation-extraction rules with distant supervision from the web,” in ISWC, 2012, Proceedings, Part I, vol. 7649, pp. 263–278, 2012.
[186] L. Cui, F. Wei, and M. Zhou, “Neural open information extraction,” in Proc. ACL, 2018, Volume 2: Short Papers, pp. 407–413, 2018.
[187] K. Kolluru, S. Aggarwal, V. Rathore, Mausam, and S. Chakrabarti, “Imojie: Iterative memory-based joint open information extraction,” in Proc. ACL,2020, pp. 5871–5886, 2020.
[188] R. Wu, Y. Yao, X. Han, R. Xie, Z. Liu, F. Lin, L. Lin, and M. Sun, “Open relation extraction: Relational knowledge transfer from supervised data to unsupervised data,” in Proc. EMNLP-IJCNLP, 2019, pp. 219–228, 2019.
[189] X. Han, P. Yu, Z. Liu, M. Sun, and P. Li, “Hierarchical relation extraction with coarse-to-fine grained attention,” in Proc. EMNLP, 2018, pp. 2236–2245, 2018.
[190] B. Luo, Y. Feng, Z. Wang, Z. Zhu, S. Huang, R. Yan, and D. Zhao, “Learning with noise: Enhance distantly supervised relation extraction with dynamic transition matrix,” in ACL, 2017, Volume 1: Long Papers, pp. 430–439, 2017.
[191] Y. Huang and J. Du, “Self-attention enhanced cnns and collaborative curriculum learning for distantly supervised relation extraction,” in Proc. EMNLP-IJCNLP, 2019, pp. 389–398, 2019.
[192] P. Qin, W. Xu, and W. Y. Wang, “Robust distant supervision relation extraction via deep reinforcement learning,” in Proc. ACL, 2018, Volume 1: Long Papers, pp. 2137–2147, 2018.
[193] P. Qin, W. Xu, and W. Y. Wang, “DSGAN: generative adversarial training for distant supervision relation extraction,” in Proc. ACL, 2018, Volume 1: Long Papers, pp. 496–505, 2018.
[194] X. Jiang, Q. Wang, P. Li, and B. Wang, “Relation extraction with multi-instance multi-label convolutional neural networks,” in COLING, 2016 Proceedings of the Conference: Technical Papers, pp. 1471–1480, 2016.
[195] G. Ji, K. Liu, S. He, and J. Zhao, “Distant supervision for relation extraction with sentence-level attention and entity descriptions,” in Proc. AAAI-17, 2017, pp. 3060–3066, 2017.
[196] Y. Lin, S. Shen, Z. Liu, H. Luan, and M. Sun, “Neural relation extraction with selective attention over instances,” in Proc. ACL, 2016, Volume 1: Long Papers, 2016.
[197] Z. Ye and Z. Ling, “Distant supervision relation extraction with intra-bag and inter-bag attentions,” in Proc. NAACL-HLT , 2019, Volume 1 (Long and Short Papers), pp. 2810–2819, 2019.
[198] Y. Yuan, L. Liu, S. Tang, Z. Zhang, Y. Zhuang, S. Pu, F. Wu, and X. Ren, “Cross-relation cross-bag attention for distantly-supervised relation extraction,” in AAAI, IAAI, EAAI , 2019, pp. 419–426, 2019.
[199] N. Zhang, S. Deng, Z. Sun, G. Wang, X. Chen, W. Zhang, and H. Chen, “Long-tail relation extraction via knowledge graph embeddings and graph convolution networks,” in Proc. NAACL-HLT, 2019, Volume 1 (Long and Short Papers), pp. 3016–3025, 2019.
[200] S. Vashishth, R. Joshi, S. S. Prayaga, C. Bhattacharyya, and P. P. Talukdar, “RESIDE: improving distantly-supervised neural relation extraction using side information,” in Proc. EMNLP, 2018, pp. 1257–1266, 2018.
[201] W. Xiong, M. Yu, S. Chang, X. Guo, and W. Y. Wang, “One-shot relational learning for knowledge graphs,” in Proc. EMNLP, 2018, pp. 1980–1990, 2018.
[202] J. Snell, K. Swersky, and R. S. Zemel, “Prototypical networks for few-shot learning,” in NeurIPS, 2017, pp. 4077–4087, 2017.
[203] M. Fan, Y. Bai, M. Sun, and P. Li, “Large margin prototypical network for few-shot relation classification with fine-grained features,” in Proc. CIKM, 2019, pp. 2353–2356, 2019.
[204] T. Gao, X. Han, Z. Liu, and M. Sun, “Hybrid attention-based prototypical networks for noisy few-shot relation classification,” in AAAI, IAAI, EAAI, 2019, pp. 6407–6414, 2019.
[205] O. Vinyals, C. Blundell, T. Lillicrap, K. Kavukcuoglu, and D. Wierstra, “Matching networks for one shot learning,” in NeurIPS, 2016, pp. 3630–3638, 2016.
[206] T. Gao, X. Han, R. Xie, Z. Liu, F. Lin, L. Lin, and M. Sun, “Neural snowball for few-shot relation learning,” in AAAI, IAAI, EAAI, 2020, pp. 7772–7779, 2020.
[207] Z. Ye and Z. Ling, “Multi-level matching and aggregation network for few-shot relation classification,” in Proc. ACL, 2019, Volume 1: Long Papers, pp. 2872–2881, 2019.
[208] C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” in Proc. ICML, 2017, vol. 70, pp. 1126–1135, 2017. [209] T. Munkhdalai and H. Yu, “Meta networks,” in ICML, 2017, vol. 70, pp. 2554–2563, 2017.
[210] T. Wu, X. Li, Y. Li, G. Haffari, G. Qi, Y. Zhu, and G. Xu, “Curriculum-meta learning for order-robust continual relation extraction,” in AAAI, IAAI, EAAI, 2021, pp. 10363–10369, 2021.
[211] O. Levy, M. Seo, E. Choi, and L. Zettlemoyer, “Zero-shot relation extraction via reading comprehension,” in Proc. CoNLL, ACL, 2017, pp. 333–342, 2017.
[212] L. B. Soares, N. FitzGerald, J. Ling, and T. Kwiatkowski, “Matching the blanks: Distributional similarity for relation learning,” in Proc. ACL, 2019, Volume 1: Long Papers, pp. 2895–2905, 2019.
[213] V. G. Satorras and J. B. Estrach, “Few-shot learning with graph neural networks,” in ICLR, 2018, Conference Track Proceedings, 2018.
[214] M. Qu, T. Gao, L. A. C. Xhonneux, and J. Tang, “Few-shot relation extraction via bayesian meta-learning on relation graphs,” in Proc. ICML, 2020, vol. 119, pp. 7867–7876, 2020.
[215] T. Gao, X. Han, H. Zhu, Z. Liu, P. Li, M. Sun, and J. Zhou, “Fewrel 2.0: Towards more challenging few-shot relation classification,” in Proc. EMNLP-IJCNLP, 2019, pp. 6249–6254, 2019.
[216] D. Roth and W. Yih, “A linear programming formulation for global inference in natural language tasks,” in HLT-NAACL, 2004, pp. 1–8, 2004.
[217] Q. Li and H. Ji, “Incremental joint extraction of entity mentions and relations,” in ACL, 2014, Volume 1: Long Papers, pp. 402–412, 2014.
[218] S. Pawar, P. Bhattacharyya, and G. K. Palshikar, “End-to-end relation extraction using neural networks and markov logic networks,” in Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2017, Valencia, Spain, April 3-7, 2017, Volume 1: Long Papers (M. Lapata, P. Blunsom, and A. Koller, eds.), pp. 818–827, Association for Computational Linguistics, 2017.
[219] S. Zheng, Y. Hao, D. Lu, H. Bao, J. Xu, H. Hao, and B. Xu, “Joint entity and relation extraction based on a hybrid neural network,” Neurocomputing, vol. 257, pp. 59–66, 2017.
[220] T. Fu, P. Li, and W. Ma, “Graphrel: Modeling text as relational graphs for joint entity and relation extraction,” in Proc. ACL, 2019, Volume 1: Long Papers, pp. 1409–1418, 2019.
[221] S. Zheng, F. Wang, H. Bao, Y. Hao, P. Zhou, and B. Xu, “Joint extraction of entities and relations based on a novel tagging scheme,” in Proc. ACL 2017, Volume 1: Long Papers, pp. 1227–1236, 2017.
[222] Z. Wei, J. Su, Y. Wang, Y. Tian, and Y. Chang, “A novel cascade binary tagging framework for relational triple extraction,” in Proc. ACL, 2020, pp. 1476–1488, 2020.
[223] Y. Wang, B. Yu, Y. Zhang, T. Liu, H. Zhu, and L. Sun, “Tplinker: Single-stage joint extraction of entities and relations through token pair linking,” in Proc. COLING, 2020, pp. 1572–1582, 2020.
[224] G. Bekoulis, J. Deleu, T. Demeester, and C. Develder, “Joint entity recognition and relation extraction as a multi-head selection problem,” Expert Syst. Appl., vol. 114, pp. 34–45, 2018.
[225] X. Li, F. Yin, Z. Sun, X. Li, A. Yuan, D. Chai, M. Zhou, and J. Li, “Entity-relation extraction as multi-turn question answering,” in Proc. ACL, 2019, Volume 1: Long Papers, pp. 1340–1350, 2019.
[226] H. Chen, C. Zhang, J. Li, P. S. Yu, and N. Jing, “Kggen: A generative approach for incipient knowledge graph population,” IEEE Trans. Knowl. Data Eng., vol. 34, no. 5, pp. 2254–2267, 2022.
[227] X. Ren, Z. Wu, W. He, M. Qu, C. R. Voss, H. Ji, T. F. Abdelzaher, and J. Han, “Cotype: Joint extraction of typed entities and relations with knowledge bases,” in Proc. WWW, 2017, pp. 1015–1024, 2017.
[228] A. Bordes, N. Usunier, A. García-Durán, J. Weston, and O. Yakhnenko, “Translating embeddings for modeling multi-relational data,” in NeurIPS, Proceedings , 2013, pp. 2787–2795, 2013.
[229] N. Peng, H. Poon, C. Quirk, K. Toutanova, and W. Yih, “Cross-sentence n-ary relation extraction with graph lstms,” Trans. Assoc. Comput. Linguistics, vol. 5, pp. 101–115, 2017.
[230] L. Song, Y. Zhang, Z. Wang, and D. Gildea, “N-ary relation extraction using graph-state LSTM,” in Proc. EMNLP, 2018, pp. 2226–2235, 2018.
[231] S. K. Sahu, F. Christopoulou, M. Miwa, and S. Ananiadou, “Inter-sentence relation extraction with document-level graph convolutional neural network,” in Proc. ACL, 2019, Volume 1: Long Papers, pp. 4309–4316, 2019.
[232] F. Christopoulou, M. Miwa, and S. Ananiadou, “Connecting the dots: Document-level neural relation extraction with edge-oriented graphs,” in Proc. EMNLP-IJCNLP , 2019, pp. 4924–4935, 2019.
[233] H. Zhu, Y. Lin, Z. Liu, J. Fu, T. Chua, and M. Sun, “Graph neural networks with generated parameters for relation extraction,” in Proc. ACL, 2019, Volume 1: Long Papers, pp. 1331–1339, 2019.
[234] G. Nan, Z. Guo, I. Sekulic, and W. Lu, “Reasoning with latent structure refinement for document-level relation extraction,” in Proc. ACL, 2020, pp. 1546–1557, 2020.
[235] W. Xu, K. Chen, and T. Zhao, “Document-level relation extraction with reconstruction,” in AAAI, IAAI, EAAI, 2021, pp. 14167–14175, 2021.
[236] S. Zeng, R. Xu, B. Chang, and L. Li, “Double graph based reasoning for document-level relation extraction,” in Proc. EMNLP, 2020, pp. 1630–1640, 2020.
[237] Z. Zhang, B. Yu, X. Shu, M. Xue, T. Liu, and L. Guo, “From what to why: Improving relation extraction with rationale graph,” in Findings of the Association for Computational Linguistics: ACL/IJCNLP , 2021, vol. ACL/IJCNLP 2021, pp. 86–95, 2021.
[238] Y. Luan, D. Wadden, L. He, A. Shah, M. Ostendorf, and H. Hajishirzi, “A general framework for information extraction using dynamic span graphs,” in Proc. NAACL-HLT, 2019, Volume 1 (Long and Short Papers), pp. 3036–3046, 2019.
[239] W. Xu, K. Chen, and T. Zhao, “Discriminative reasoning for document-level relation extraction,” in ACL/IJCNLP , 2021, pp. 1653–1663, 2021.
[240] A. Bosselut, H. Rashkin, M. Sap, C. Malaviya, A. Celikyilmaz, and Y. Choi, “COMET: commonsense transformers for automatic knowledge graph construction,” in Proc. ACL, 2019 , Volume 1: Long Papers, pp. 4762–4779, 2019.
[241] N. Zhang, X. Chen, X. Xie, S. Deng, C. Tan, M. Chen, F. Huang, L. Si, and H. Chen, “Document-level relation extraction as semantic segmentation,” in Proc. IJCAI ,2021, pp. 3999–4006, 2021.
[242] W. Zhou, K. Huang, T. Ma, and J. Huang, “Document-level relation extraction with adaptive thresholding and localized context pooling,” in AAAI, IAAI, EAAI, 2021, pp. 14612–14620, 2021.
[243] Y. Lin, Z. Liu, M. Sun, Y. Liu, and X. Zhu, “Learning entity and relation embeddings for knowledge graph completion,” in Proc. AAAI-15, 2015, pp. 2181–2187, 2015.
[244] Z. Wang, J. Zhang, J. Feng, and Z. Chen, “Knowledge graph embedding by translating on hyperplanes,” in Proc. AAAI-14, 2014, pp. 1112–1119, 2014.
[245] G. Ji, K. Liu, S. He, and J. Zhao, “Knowledge graph completion with adaptive sparse transfer matrix,” in Proc. AAAI-16, 2016, pp. 985–991, 2016.
[246] M. Nickel, V. Tresp, and H. Kriegel, “A three-way model for collective learning on multi-relational data,” in Proc. ICML, 2011, pp. 809–816, 2011.
[247] I. Balazevic, C. Allen, and T. M. Hospedales, “Tucker: Tensor factorization for knowledge graph completion,” in Proc. EMNLP-IJCNLP, 2019, pp. 5184–5193, 2019.
[248] B. Yang, W. Yih, X. He, J. Gao, and L. Deng, “Embedding entities and relations for learning and inference in knowledge bases,” in ICLR, 2015, Conference Track Proceedings, 2015.
[249] R. Socher, D. Chen, C. D. Manning, and A. Y. Ng, “Reasoning with neural tensor networks for knowledge base completion,” in NeurIPS, 2013, Proceedings, pp. 926–934, 2013.
[250] Z. Zhang, J. Cai, Y. Zhang, and J. Wang, “Learning hierarchy-aware knowledge graph embeddings for link prediction,” in AAAI, IAAI, EAAI, 2020, pp. 3065–3072, 2020.
[251] G. Niu, B. Li, Y. Zhang, and S. Pu, “CAKE: A scalable commonsense-aware framework for multi-view knowledge graph completion,” in Proc. ACL, 2022.
[252] L. Wang, W. Zhao, Z. Wei, and J. Liu, “Simkgc: Simple contrastive knowledge graph completion with pre-trained language models,” in Proc. ACL, 2022.
[253] K. Wang, Y. Liu, and Q. Z. Sheng, “Swift and sure: Hardness-aware contrastive learning for low-dimensional knowledge graph embeddings,” in WWW ’22: The ACM Web Conference 2022, Virtual Event, Lyon, France, April 25 - 29, 2022 (F. Laforest, R. Troncy, E. Simperl, D. Agarwal, A. Gionis, I. Herman, and L. Médini, eds.), pp. 838–849, ACM, 2022.
[254] A. Borrego, D. Ayala, I. Hernández, C. R. Rivero, and D. Ruiz, “CAFE: knowledge graph completion using neighborhoodaware features,” Eng. Appl. Artif. Intell., vol. 103, p. 104302, 2021.
[255] J. Wu, W. Shi, X. Cao, J. Chen, W. Lei, F. Zhang, W. Wu, and X. He, “Disenkgat: Knowledge graph embedding with disentangled graph attention network,” in CIKM , 2021, pp. 2140–2149, 2021.
[256] N. Lao and W. W. Cohen, “Relational retrieval using a combination of path-constrained random walks,” Mach. Learn., vol. 81, no. 1, pp. 53–67, 2010.
[257] M. Gardner, P. P. Talukdar, J. Krishnamurthy, and T. M. Mitchell, “Incorporating vector space similarity in random walk inference over knowledge bases,” in Proc. EMNLP, 2014, A meeting of SIGDAT, a Special Interest Group of the ACL, pp. 397–406, 2014.
[258] Q. Wang, J. Liu, Y. Luo, B. Wang, and C. Lin, “Knowledge base completion via coupled path ranking,” in Proc. ACL, 2016, Volume 1: Long Papers, 2016.
[259] W. Xiong, T. Hoang, and W. Y. Wang, “Deeppath: A reinforcement learning method for knowledge graph reasoning,” in Proc. EMNLP, 2017, pp. 564–573, 2017.
[260] X. V. Lin, R. Socher, and C. Xiong, “Multi-hop knowledge graph reasoning with reward shaping,” in Proc. EMNLP, 2018, pp. 3243–3253, 2018.
[261] Z. Li, X. Jin, S. Guan, Y. Wang, and X. Cheng, “Path reasoning over knowledge graph: A multi-agent and reinforcement learning based method,” in ICDM Workshops, 2018, pp. 929–936, 2018.
[262] Y. Shen, J. Chen, P. Huang, Y. Guo, and J. Gao, “M-walk: Learning to walk over graphs using monte carlo tree search,” in NeurIPS, 2018, pp. 6787–6798, 2018.
[263] A. Neelakantan, B. Roth, and A. McCallum, “Compositional vector space models for knowledge base completion,” in ACL, 2015, Volume 1: Long Papers, pp. 156–166, 2015.
[264] R. Das, A. Neelakantan, D. Belanger, and A. McCallum, “Chains of reasoning over entities, relations, and text using recurrent neural networks,” in Proc. EACL, 2017, Volume 1: Long Papers, pp. 132–141, 2017.
[265] Y. Zhang, H. Dai, Z. Kozareva, A. J. Smola, and L. Song, “Variational reasoning for question answering with knowledge graph,” in AAAI, IAAI, EAAI, 2018, pp. 6069–6076, 2018.
[266] S. Kardani-Moghaddam, R. Buyya, and K. Ramamohanarao, “ADRL: A hybrid anomaly-aware deep reinforcement learning-based resource scaling in clouds,” IEEE Trans. Parallel Distributed Syst., vol. 32, no. 3, pp. 514–526, 2021.
[267] H. Wang, S. Li, R. Pan, and M. Mao, “Incorporating graph attention mechanism into knowledge graph reasoning based on deep reinforcement learning,” in Proc. EMNLP-IJCNLP, 2019, pp. 2623–2631, 2019.
[268] M. Zheng, Y. Zhou, and Q. Cui, “Hierarchical policy network with multi-agent for knowledge graph reasoning based on reinforcement learning,” in KSEM, 2021, Proceedings, Part I, vol. 12815, pp. 445–457, 2021.
[269] P. Tiwari, H. Zhu, and H. M. Pandey, “Dapath: Distance-aware knowledge graph reasoning based on deep reinforcement learning,” Neural Networks, vol. 135, pp. 1–12, 2021.
[270] S. Li, H. Wang, R. Pan, and M. Mao, “Memorypath: A deep reinforcement learning framework for incorporating memory component into knowledge graph reasoning,” Neurocomputing, vol. 419, pp. 273–286, 2021.
[271] L. A. Galárraga, C. Teflioudi, K. Hose, and F. M. Suchanek, “AMIE: association rule mining under incomplete evidence in ontological knowledge bases,” in WWW , 2013, pp. 413–422, 2013.
[272] P. G. Omran, K. Wang, and Z. Wang, “Scalable rule learning via learning representation,” in Proc. IJCAI, 2018, pp. 2149–2155, 2018.
[273] C. Meilicke, M. Fink, Y. Wang, D. Ruffinelli, R. Gemulla, and H. Stuckenschmidt, “Fine-grained evaluation of rule- and embedding-based systems for knowledge graph completion,” in ISWC, 2018, Proceedings, Part I, vol. 11136, pp. 3–20, 2018.
[274] S. Guo, Q. Wang, L. Wang, B. Wang, and L. Guo, “Jointly embedding knowledge graphs and logical rules,” in Proc. EMNLP, 2016, pp. 192–202, 2016.
[275] S. Guo, Q. Wang, L. Wang, B. Wang, and L. Guo, “Knowledge graph embedding with iterative guidance from soft rules,” in AAAI, IAAI, EAAI, 2018, pp. 4816–4823, 2018.
[276] F. Yang, Z. Yang, and W. W. Cohen, “Differentiable learning of logical rules for knowledge base reasoning,” in NeurIPS, 2017, pp. 2319–2328, 2017.
[277] M. Qu and J. Tang, “Probabilistic logic neural networks for reasoning,” in NeurIPS, 2019, pp. 7710–7720, 2019.
[278] Y. Zhang, X. Chen, Y. Yang, A. Ramamurthy, B. Li, Y. Qi, and L. Song, “Efficient probabilistic logic reasoning with graph neural networks,” in ICLR, 2020.
[279] T. Miller, “Explanation in artificial intelligence: Insights from the social sciences,” Artif. Intell., vol. 267, pp. 1–38, 2019.
[280] V. I. S. Carmona, T. Rocktäschel, S. Riedel, and S. Singh, “Towards extracting faithful and descriptive representations of latent variable models,” in AAAI Spring Symposia, 2015.
[281] Y. Nandwani, A. Gupta, A. Agrawal, M. S. Chauhan, P. Singla, and Mausam, “Oxkbc: Outcome explanation for factorization based knowledge base completion,” in AKBC, 2020.
[282] Z. Ying, D. Bourgeois, J. You, M. Zitnik, and J. Leskovec, “Gnnexplainer: Generating explanations for graph neural networks,” in NeurIPS, 2019, pp. 9240–9251, 2019.
[283] P. Pezeshkpour, Y. Tian, and S. Singh, “Investigating robustness and interpretability of link prediction via adversarial modifications,” in Proc. NAACL-HLT, 2019, Volume 1 (Long and Short Papers), pp. 3336–3347, 2019.
[284] R. Xie, Z. Liu, F. Lin, and L. Lin, “Does william shakespeare REALLY write hamlet? knowledge representation learning with confidence,” in AAAI, IAAI, EAAI, 2018, pp. 4954–4961, 2018.
[285] T. Dong, Z. Wang, J. Li, C. Bauckhage, and A. B. Cremers, “Triple classification using regions and fine-grained entity typing,” in AAAI , IAAI, EAAI, 2019, pp. 77–85, 2019.
[286] E. Amador-Domínguez, E. Serrano, D. Manrique, P. Hohenecker, and T. Lukasiewicz, “An ontology-based deep learning approach for triple classification with out-of-knowledge-base entities,” Inf. Sci., vol. 564, pp. 85–102, 2021.
[287] D. Q. Nguyen, T. Nguyen, and D. Phung, “A relational memory-based embedding model for triple classification and search personalization,” in Proc. ACL, 2020, pp. 3429–3435, 2020.
[288] T. Sun, J. Zhai, and Q. Wang, “Novea: A novel model of entity alignment using attribute triples and relation triples,” in KSEM , 2020, Proceedings, Part I, vol. 12274, pp. 161–173, 2020.
[289] F. He, Z. Li, Q. Yang, A. Liu, G. Liu, P. Zhao, L. Zhao, M. Zhang, and Z. Chen, “Unsupervised entity alignment using attribute triples and relation triples,” in DASFAA , 2019, Proceedings, Part I, vol. 11446, pp. 367–382, 2019.
[290] H. Yang, Y. Zou, P. Shi, W. Lu, J. Lin, and X. Sun, “Aligning cross-lingual entities with multi-aspect information,” in Proc. EMNLP-IJCNLP , 2019, pp. 4430–4440, 2019.
[291] Z. Sun, W. Hu, and C. Li, “Cross-lingual entity alignment via joint attribute-preserving embedding,” in ISWC, 2017, Proceedings, Part I, vol. 10587, pp. 628–644, 2017.
[292] B. D. Trisedya, J. Qi, and R. Zhang, “Entity alignment between knowledge graphs using attribute embeddings,” in AAAI, IAAI, EAAI, 2019, pp. 297–304, 2019.
[293] W. Tan, “Technical perspective: Entity matching with magellan,” Commun. ACM, vol. 63, no. 8, p. 82, 2020.
[294] M. S. Schlichtkrull and H. M. Alonso, “Msejrku at semeval-2016 task 14: Taxonomy enrichment by evidence ranking,” in Proc. SemEval@NAACL-HLT, 2016, pp. 1337–1341, 2016.
[295] S. Mudgal, H. Li, T. Rekatsinas, A. Doan, Y. Park, G. Krishnan, R. Deep, E. Arcaute, and V. Raghavendra, “Deep learning for entity matching: A design space exploration,” in Proc. SIGMOD, 2018, pp. 19–34, 2018.
[296] D. Jurgens and M. T. Pilehvar, “Semeval-2016 task 14: Semantic taxonomy enrichment,” in Proc. SemEval@NAACL-HLT, 2016, pp. 1092–1102, 2016.
[297] B. T. McInnes, “VCU at semeval-2016 task 14: Evaluating definitional-based similarity measure for semantic taxonomy enrichment,” in Proc. SemEval@NAACL-HLT, 2016, pp. 1351–1355, 2016.
[298] L. E. Anke, F. Ronzano, and H. Saggion, “TALN at semeval-2016 task 14: Semantic taxonomy enrichment via sensebased embeddings,” in Proc. SemEval@NAACL-HLT, 2016, pp. 1332–1336, 2016.
[299] K. S. Jones, “A statistical interpretation of term specificity and its application in retrieval,” J. Documentation, vol. 60, no. 5, pp. 493–502, 2004.
[300] G. Stoilos, G. B. Stamou, and S. D. Kollias, “A string metric for ontology alignment,” in ISWC , 2005, Proceedings, vol. 3729, pp. 624–637, 2005.
[301] N. Vedula, P. K. Nicholson, D. Ajwani, S. Dutta, A. Sala, and S. Parthasarathy, “Enriching taxonomies with functional domain knowledge,” in SIGIR, 2018, pp. 745–754, 2018.
[302] D. Frolov, S. Nascimento, T. I. Fenner, and B. G. Mirkin, “Using taxonomy tree to generalize a fuzzy thematic cluster,” in FUZZ-IEEE , 2019, pp. 1–6, 2019.
[303] F. Scharffe, Y. Liu, and C. Zhou, “Rdf-ai: an architecture for rdf datasets matching, fusion and interlink,” in Proc. IJCAI workshop on IR-KR, 2019, p. 23, 2009.
[304] A. N. Ngomo and S. Auer, “LIMES - A time-efficient approach for large-scale link discovery on the web of data,” in Proc. IJCAI, 2011, pp. 2312–2317, 2011.
[305] M. Pershina, M. Yakout, and K. Chakrabarti, “Holistic entity matching across knowledge graphs,” in IEEE BigData, 2015, pp. 1585–1590, 2015.
[306] M. Berrendorf, E. Faerman, and V. Tresp, “Active learning for entity alignment,” in ECIR, 2021, Proceedings, Part I, vol. 12656, pp. 48–62, 2021.
[307] Z. Sun, W. Hu, Q. Zhang, and Y. Qu, “Bootstrapping entity alignment with knowledge graph embedding,” in Proc. IJCAI, 2018, pp. 4396–4402, 2018.
[308] H. Zhu, R. Xie, Z. Liu, and M. Sun, “Iterative entity alignment via joint knowledge embeddings,” in Proc. IJCAI , 2017, pp. 4258–4264, 2017.
[309] Q. Zhang, Z. Sun, W. Hu, M. Chen, L. Guo, and Y. Qu, “Multi-view knowledge graph embedding for entity alignment,” in Proc. IJCAI, 2019, pp. 5429–5435, 2019.
[310] M. Chen, Y. Tian, M. Yang, and C. Zaniolo, “Multilingual knowledge graph embeddings for cross-lingual knowledge alignment,” in Proc. IJCAI, 2017, pp. 1511–1517, 2017.
[311] Z. Huang, Z. Li, H. Jiang, T. Cao, H. Lu, B. Yin, K. Subbian, Y. Sun, and W. Wang, “Multilingual knowledge graph completion with self-supervised adaptive graph alignment,” in Proc. ACL, 2022.
[312] X. Liu, H. Hong, X. Wang, Z. Chen, E. Kharlamov, Y. Dong, and J. Tang, “Selfkg: Self-supervised entity alignment in knowledge graphs,” in WWW ’22: The ACM Web Conference 2022, Virtual Event, Lyon, France, April 25 - 29, 2022 (F. Laforest, R. Troncy, E. Simperl, D. Agarwal, A. Gionis, I. Herman, and L. Médini, eds.), pp. 860–870, ACM, 2022.
[313] M. Chen, Y. Tian, K. Chang, S. Skiena, and C. Zaniolo, “Co-training embeddings of knowledge graphs and entity descriptions for cross-lingual entity alignment,” in Proc. IJCAI, 2018, pp. 3998–4004, 2018.
[314] B. Chen, J. Zhang, X. Tang, H. Chen, and C. Li, “Jarka: Modeling attribute interactions for cross-lingual knowledge alignment,” in PAKDD, 2020, Proceedings, Part I, vol. 12084, pp. 845–856, 2020.
[315] Z. Wang, Q. Lv, X. Lan, and Y. Zhang, “Cross-lingual knowledge graph alignment via graph convolutional networks,” in Proc. EMNLP, 2018, pp. 349–357, 2018.
[316] Y. Zhu, H. Liu, Z. Wu, and Y. Du, “Relation-aware neighborhood matching model for entity alignment,” in AAAI, IAAI, EAAI, 2021, pp. 4749–4756, 2021.
[317] Y. Wu, X. Liu, Y. Feng, Z. Wang, R. Yan, and D. Zhao, “Relation-aware entity alignment for heterogeneous knowledge graphs,” in Proc. IJCAI, 2019, pp. 5278–5284, 2019.
[318] K. Xu, L. Wang, M. Yu, Y. Feng, Y. Song, Z. Wang, and D. Yu, “Cross-lingual knowledge graph alignment via graph matching neural network,” in Proc. ACL, 2019, Volume 1: Long Papers, pp. 3156–3161, 2019.
[319] Z. Liu, Y. Cao, L. Pan, J. Li, and T. Chua, “Exploring and evaluating attributes, values, and structures for entity alignment,” in Proc. EMNLP, 2020, pp. 6355–6364, 2020.
[320] Y. Cao, Z. Liu, C. Li, Z. Liu, J. Li, and T. Chua, “Multi-channel graph neural network for entity alignment,” in Proc. ACL, 2019, Volume 1: Long Papers, pp. 1452–1461, 2019.
[321] S. Jiang, T. Nie, D. Shen, Y. Kou, and G. Yu, “Entity alignment of knowledge graph by joint graph attention and translation representation,” in WISA, 2021, Proceedings, vol. 12999, pp. 347–358, 2021.
[322] T. Jiang, T. Zhao, B. Qin, T. Liu, N. V. Chawla, and M. Jiang, “The role of ̈ condition ̈: A novel scientific knowledge graph representation and construction model,” in KDD, 2019, pp. 1634–1642, 2019.
[323] T. Zheng, Z. Xu, Y. Li, Y. Zhao, B. Wang, and X. Yang, “A novel conditional knowledge graph representation and construction,” in CICAI , 2021, Proceedings, Part II, vol. 13070, pp. 383–394, 2021.
[324] F. Cheng and Y. Miyao, “Classifying temporal relations by bidirectional LSTM over dependency paths,” in Proc. ACL, 2017, Volume 2: Short Papers, pp. 1–6, 2017.
[325] Y. Meng, A. Rumshisky, and A. Romanov, “Temporal information extraction for question answering using syntactic dependencies in an lstm-based architecture,” in Proc. EMNLP, 2017, pp. 887–896, 2017.
[326] S. Vashishtha, B. V. Durme, and A. S. White, “Fine-grained temporal relation extraction,” in Proc. ACL, 2019, Volume 1: Long Papers, pp. 2906–2919, 2019.
[327] P. Mathur, R. Jain, F. Dernoncourt, V. I. Morariu, Q. H. Tran, and D. Manocha, “TIMERS: document-level temporal relation extraction,” in Proc. ACL/IJCNLP, 2021, Volume 2: Short Papers, pp. 524–533, 2021.
[328] J. Leblay and M. W. Chekol, “Deriving validity time in knowledge graph,” in WWW, 2018, pp. 1771–1776, 2018.
[329] S. S. Dasgupta, S. N. Ray, and P. P. Talukdar, “Hyte: Hyperplane-based temporally aware knowledge graph embedding,” in Proc. EMNLP, 2018, pp. 2001–2011, 2018.
[330] A. García-Durán, S. Dumancic, and M. Niepert, “Learning sequence encoders for temporal knowledge graph completion,” in Proc. EMNLP, 2018, pp. 4816–4821, 2018.
[331] Y. Liu, W. Hua, K. Xin, and X. Zhou, “Context-aware temporal knowledge graph embedding,” in WISE , 2019, Proceedings, vol. 11881, pp. 583–598, 2019.
[332] L. Lin and K. She, “Tensor decomposition-based temporal knowledge graph embedding,” in ICTAI, 2020, pp. 969–975, 2020.
[333] T. Lacroix, G. Obozinski, and N. Usunier, “Tensor decompositions for temporal knowledge base completion,” in ICLR, 2020.
[334] P. Shao, D. Zhang, G. Yang, J. Tao, F. Che, and T. Liu, “Tucker decomposition-based temporal knowledge graph completion,” Knowl. Based Syst., vol. 238, p. 107841, 2022.
[335] W. Radstok, M. Chekol, and Y. Velegrakis, “Leveraging static models for link prediction in temporal knowledge graphs,” in ICTAI , 2021, pp. 1034–1041, 2021.
[336] J. Jung, J. Jung, and U. Kang, “Learning to walk across time for interpretable temporal knowledge graph completion,” in KDD, 2021, pp. 786–795, 2021.
[337] H. Liu, S. Zhou, C. Chen, T. Gao, J. Xu, and M. Shu, “Dynamic knowledge graph reasoning based on deep reinforcement learning,” Knowl. Based Syst., vol. 241, p. 108235, 2022.
[338] T. Jiang, T. Liu, T. Ge, L. Sha, S. Li, B. Chang, and Z. Sui, “Encoding temporal information for time-aware link prediction,” in Proc. EMNLP, 2016, pp. 2350–2354, 2016.
[339] K. Yu, X. Guo, L. Liu, J. Li, H. Wang, Z. Ling, and X. Wu, “Causality-based feature selection: Methods and evaluations,” ACM Comput. Surv., vol. 53, no. 5, pp. 111:1–111:36, 2020.
[340] R. Trivedi, H. Dai, Y. Wang, and L. Song, “Know-evolve: Deep temporal reasoning for dynamic knowledge graphs,” in Proc. ICML 2017, vol. 70, pp. 3462–3471, 2017.
[341] W. Jin, C. Zhang, P. A. Szekely, and X. Ren, “Recurrent event network for reasoning over temporal knowledge graphs,” CoRR, vol. abs/1904.05530, 2019.
[342] X. Li, L. Liu, X. Wang, Y. Li, Q. Wu, and T. Qian, “Towards evolutionary knowledge representation under the big data circumstance,” Electron. Libr., vol. 39, no. 3, pp. 392–410, 2021.
[343] Z. Han, P. Chen, Y. Ma, and V. Tresp, “Dyernie: Dynamic evolution of riemannian manifold embeddings for temporal knowledge graph completion,” in EMNLP, 2020, pp. 7301–7316, 2020.
[344] T. Gracious, S. Gupta, A. Kanthali, R. M. Castro, and A. Dukkipati, “Neural latent space model for dynamic networks and temporal knowledge graphs,” in AAAI, IAAI, EAAI, 2021, pp. 4054–4062, 2021.
[345] Y. Yan, L. Liu, Y. Ban, B. Jing, and H. Tong, “Dynamic knowledge graph alignment,” in AAAI , IAAI, EAAI, 2021, pp. 4564–4572, 2021.
[346] B. Momjian, PostgreSQL: introduction and concepts, vol. 192. Addison-Wesley New York, 2001.
[347] B. Shao, H. Wang, and Y. Li, “Trinity: a distributed graph engine on a memory cloud,” in SIGMOD, 2013, pp. 505–516, 2013.
[348] J. C. Anderson, J. Lehnardt, and N. Slater, “Couchdb: The definitive guide time to relax,” 2010.
[349] L. Zou, J. Mo, L. Chen, M. T. Özsu, and D. Zhao, “gstore: Answering SPARQL queries via subgraph matching,” Proc. VLDB Endow., vol. 4, no. 8, pp. 482–493, 2011.
[350] J. Webber, “A programmatic introduction to neo4j,” in SPLASH, Proceedings , 2012, pp. 217–218, 2012.
[351] T. Miller, C. Hempelmann, and I. Gurevych, “Semeval-2017 task 7: Detection and interpretation of english puns,” in Proc. SemEval@ACL, 2017, pp. 58–68, 2017.
[352] C. Wang, S. Liang, Y. Jin, Y. Wang, X. Zhu, and Y. Zhang, “Semeval-2020 task 4: Commonsense validation and explanation,” in Proc. SemEval@COLING, 2020, pp. 307–321, 2020.
[353] Y. Liu, H. Li, A. García-Durán, M. Niepert, D. Oñoro-Rubio, and D. S. Rosenblum, “MMKG: multi-modal knowledge graphs,” in ESWC, 2019, Proceedings, vol. 11503, pp. 459–474, 2019.
[354] S. Dost, L. Serafini, M. Rospocher, L. Ballan, and A. Sperduti, “Aligning and linking entity mentions in image, text, and knowledge base,” Data Knowl. Eng., vol. 138, p. 101975, 2022.
[355] H. Peng, H. Li, Y. Song, V. W. Zheng, and J. Li, “Differentially private federated knowledge graphs embedding,” in CIKM , 2021, pp. 1416–1425, 2021. [356] M. Chen, W. Zhang, Z. Yuan, Y. Jia, and H. Chen, “Fede: Embedding knowledge graphs in federated setting,” in IJCKG, 2021, pp. 80–88, 2021.
[357] Y. Xie, J. Shen, S. Li, Y. Mao, and J. Han, “Eider: Evidence-enhanced document-level relation extraction,” CoRR, vol. abs/2106.08657, 2021.
[358] H. Weld, X. Huang, S. Long, J. Poon, and S. C. Han, “A survey of joint intent detection and slot-filling models in natural language understanding,” CoRR, vol. abs/2101.08091, 2021.