最新多模态生成模型 MM-Interleaved 开源
转自机器之心
过去几个月中,随着 GPT-4V、DALL-E 3、Gemini 等重磅工作的相继推出,「AGI 的下一步」—— 多模态生成大模型迅速成为全球学者瞩目的焦点。
想象一下,AI 不仅会聊天,还长了「眼睛」,能看懂图片,甚至还会通过画画来表达自己!这意味着,你可以和它们谈天说地,分享图片或视频,它们也同样能用图文并茂的方式回应你。
最近,上海人工智能实验室联合香港中文大学多媒体实验室(MMLab)、清华大学、商汤科技、多伦多大学等多家高校、机构,共同发布了一个多才多艺的最强开源多模态生成模型 MM-Interleaved,借助全新提出的多模态特征同步器刷新多项任务 SOTA。它拥有对高分辨率图像细节和微妙语义的精准理解能力,支持任意穿插的图文输入和输出,带来了多模态生成大模型的崭新突破。

论文地址:https://arxiv.org/pdf/2401.10208.pdf
项目地址(点击“阅读原文”直达):https://github.com/OpenGVLab/MM-Interleaved
模型地址:https://huggingface.co/OpenGVLab/MM-Interleaved/tree/main/mm_interleaved_pretrain
MM-Interleaved 可以轻松编写引人入胜的旅游日志和童话故事,准确理解机器人操作,就连分析电脑和手机的 GUI 界面、创作独特风格的精美图片都不在话下。甚至,它还能教你做菜,陪你玩游戏,成为随时听候指挥的个人助理!话不多说,直接看效果:
轻松理解复杂多模态上下文
MM-Interleaved 可以根据图文上下文自主推理生成符合要求的文本答复,它既能算水果数学题:

也能结合常识推理出 Logo 图像对应的公司并进行介绍:

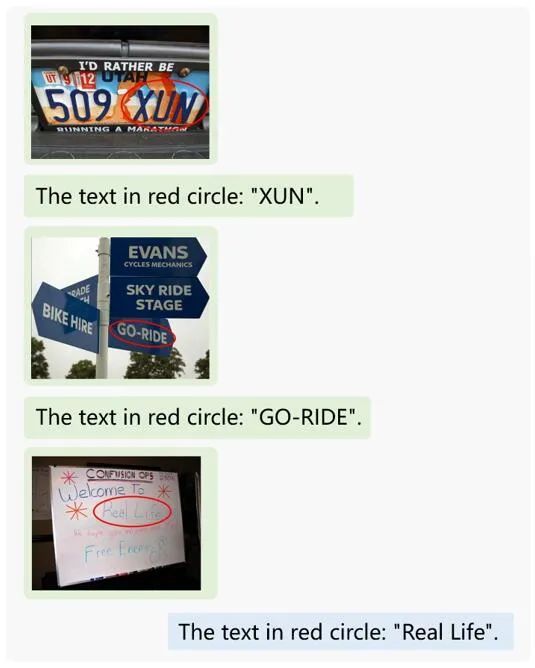
还能精确识别用红色圆圈标注出的手写文字内容:
此外,模型也能直接理解通过序列图像表示的机器人动作:

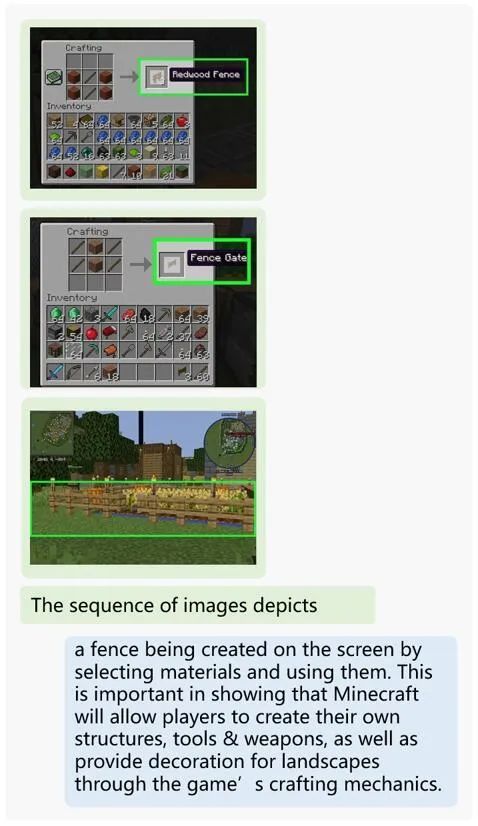
以及在 Minecraft 中如何建造围栏这样的游戏操作:
甚至能结合上下文,手把手地教用户如何在手机 UI 界面上配置灰度:

以及精准定位找到那架藏在后面的小飞机:

脑洞全开生成不同风格图像
MM-Interleaved 模型同样可以出色地完成各种复杂的图像生成任务。比如根据用户提供的详细描述生成一张三角钢琴的剪影:

或者当用户以多种形式指定所需生成的图像应当包含的物体或风格时,MM-Interleaved 框架也可轻松应对。
比如生成一张水彩风格的大象:

按照狗的风格生成一张猫的画:

在向日葵花丛里的一座木房子:

以及在生成海浪图像时,根据上下文智能推断相应的风格。
图像生成兼顾空间一致性
更令人惊喜的是,MM-Interleaved 还具备根据输入的分割图和对应的文本描述生成图像的能力,并确保生成的图像与分割图在空间布局上保持一致。

这一功能不仅展示了模型在图文生成任务中的卓越表现,同时也为用户提供了更加灵活和直观的操作体验。
自主生成图文并茂的文章
此外,只需提供一个简单的开头,MM-Interleaved 就能自主进行续写,生成语义连贯、图文并茂的文章,题材多样。
无论是关于一朵玫瑰的童话故事:

教你制作苹果汁的教程指南:

还是卡通动漫中的情节片段:
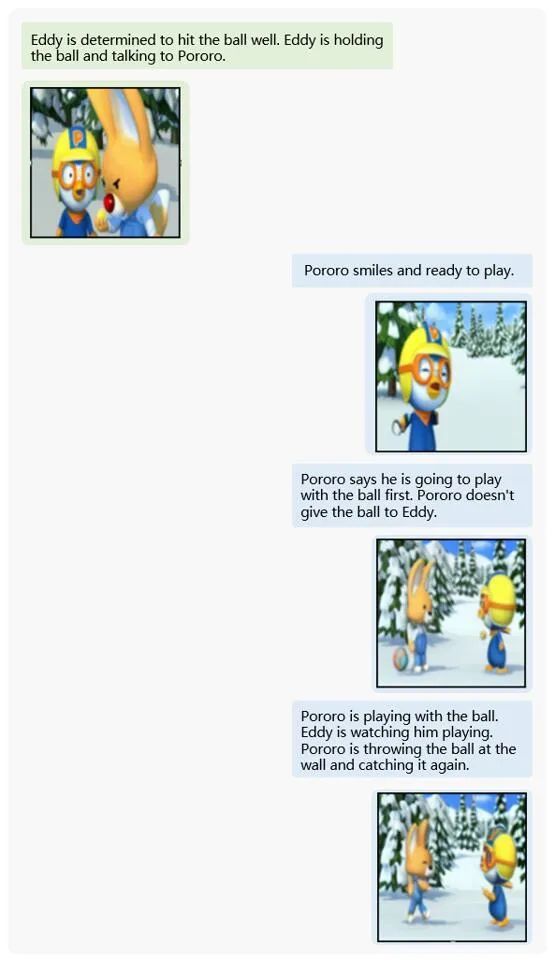
MM-Interleaved 框架都展现出了卓越的创造力。这使得 MM-Interleaved 框架成为了一个无限创意的智能合作者,能够帮助用户轻松打造引人入胜的图文作品。
MM-Interleaved 致力于解决图文交错多模态大模型训练中的核心问题,通过深入研究提出了一种全新的端到端预训练框架。
基于 MM-Interleaved 训练的模型,在参数量更少、不使用私有数据的情况下,不仅在多个零样本多模态理解任务上表现优越,领先于国内外最新研究工作,如 Flamingo、Emu2 等。
还能进一步通过监督微调的方式,在视觉问答(VQA),图像描述(image caption)、指代理解(referring expression comprehension)、图生图(segment-to-image generation)、视觉故事生成(visual storytelling)等多个下游任务上取得更为优异的综合性能。
目前模型的预训练权重及相应代码实现均已在 GitHub 开源。
多模态特征同步器携手全新端到端训练框架
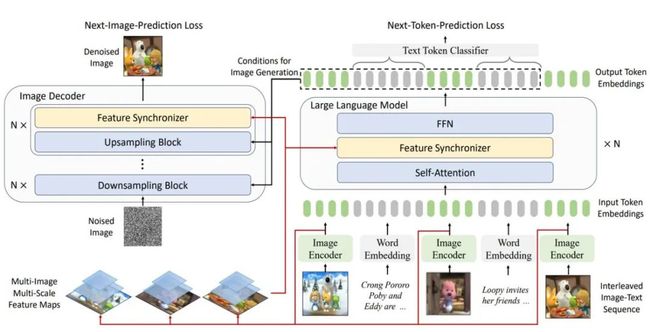
MM-Interleaved 提出了一种全新的端到端训练框架,专门面向图文交错数据。
该框架支持多尺度的图像特征作为输入,不对图像和文本的中间特征添加任何额外约束,而是直接采用预测下一个文本 token 或下一张图像的自监督训练目标,实现单阶段的统一预训练范式。
与以往方法相比,MM-Interleaved 不仅支持交错生成文本和图像,还能高效捕捉图像中更多的细节信息。
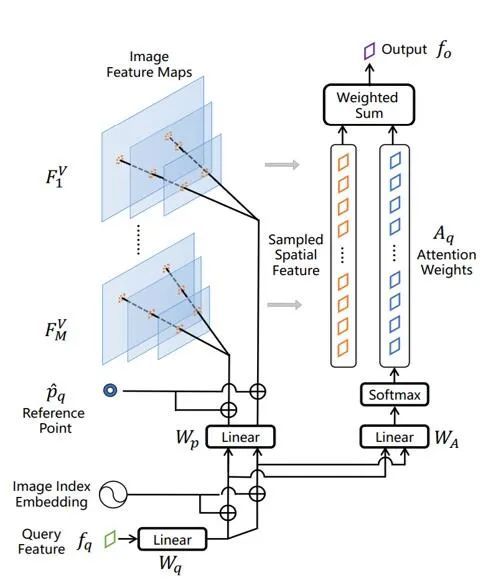
此外,MM-Interleaved 的关键实现还包括一个通用的多模态特征同步器(Multi-modal Feature Synchronizer)。
该同步器能够动态注入多张高分辨率图像的细粒度特征到多模态大模型和图像解码器中,实现了对文本和图像的解码生成的同时进行跨模态的特征同步。
这一创新设计使得 MM-Interleaved 为多模态大模型领域的发展注入了新的活力。
多项任务性能领先

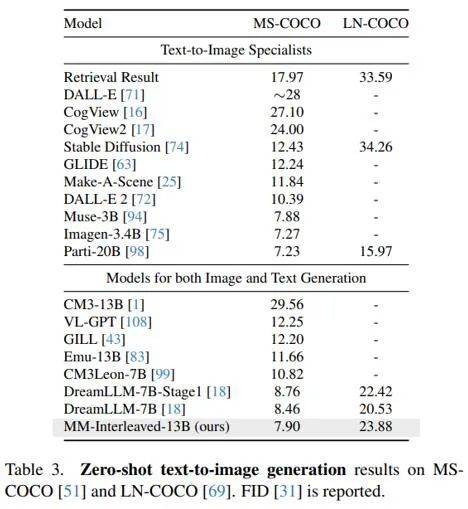
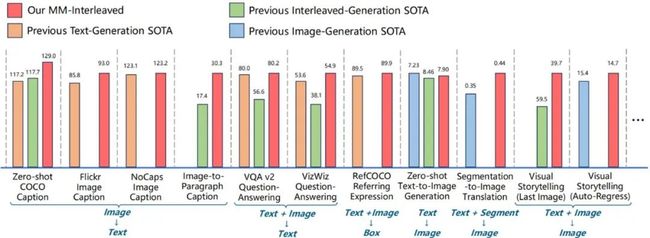
如表 1 和表 3 所示,MM-Interleaved 在零样本多模态理解和生成任务上均取得了卓越的性能。这一成就不仅证明了该框架的强大能力,也突显了其在应对多样化任务时的强大通用性。


表 2 和表 4 展现了 MM-Interleaved 在进行进一步微调后的实验结果,其在指代理解、基于分割图生成图像、图文交错生成等多个下游任务上的性能也十分优异。
这表明 MM-Interleaved 不仅在预训练阶段表现出色,而且在具体任务微调后依然能够保持领先地位,从而为多模态大模型的广泛应用提供了可靠的支持。
结论
MM-Interleaved 的问世标志着多模态大模型的发展朝着实现全面端到端的统一建模和训练迈出了关键一步。
这一框架的成功不但体现在其预训练阶段所展现的卓越性能,而且还体现在微调后在各个具体下游任务上的全面表现。
其独特的贡献不仅在于展示了强大的多模态处理能力,更为开源社区构建新一代多模态大模型开启了更为广阔的可能性。
MM-Interleaved 也为未来图文交错数据的处理提供了新的思路和工具,为实现更加智能、灵活的图文生成和理解奠定了坚实基础。
我们期待看到这一创新为更多领域相关应用带来更多惊喜。
论文地址:
https://arxiv.org/pdf/2401.10208.pdf
https://github.com/OpenGVLab/MM-Interleaved
模型地址:
https://huggingface.co/OpenGVLab/MM-Interleaved/tree/main/mm_interleaved_pretrain
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
不是一杯奶茶喝不起,而是我T M直接用来跟进 AIGC+CV视觉 前沿技术,它不香?!
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!
经典GAN不得不读:StyleGAN
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!
最新最全100篇汇总!生成扩散模型Diffusion Models
ECCV2022 | 生成对抗网络GAN部分论文汇总
CVPR 2022 | 25+方向、最新50篇GAN论文
ICCV 2021 | 35个主题GAN论文汇总
超110篇!CVPR 2021最全GAN论文梳理
超100篇!CVPR 2020最全GAN论文梳理
拆解组新的GAN:解耦表征MixNMatch
StarGAN第2版:多域多样性图像生成
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 |《计算机视觉中的数学方法》分享
《基于深度学习的表面缺陷检测方法综述》
《零样本图像分类综述: 十年进展》
《基于深度神经网络的少样本学习综述》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击跟进 AIGC+CV视觉 前沿技术,真香!,加入 AI生成创作与计算机视觉 知识星球!