Transformer的PyTorch实现之若干问题探讨(二)
在《Transformer的PyTorch实现之若干问题探讨(一)》中探讨了Transformer的训练整体流程,本文进一步探讨Transformer训练过程中teacher forcing的实现原理。
1.Transformer中decoder的流程
在论文《Attention is all you need》中,关于encoder及self attention有较为详细的论述,这也是网上很多教程在谈及transformer时候会重点讨论的部分。但是关于transformer的decoder部分,他的结构上与encoder实际非常像,但其中有一些巧妙的设计。本文会详细谈谈。首先给出一个完整transformer的结构图:
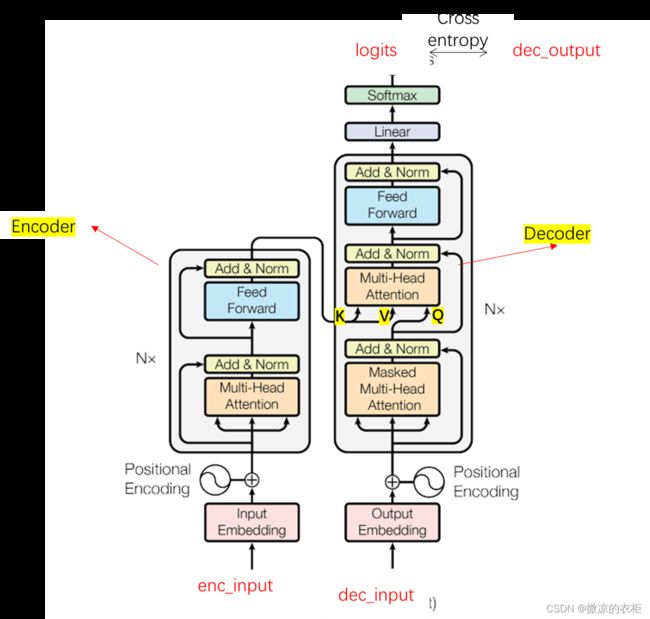
上图左侧为encoder部分,右侧为decoder部分。对于decoder部分,将enc_input经过multi head attention后得到的张量,以K,V送入decoder中。而decoder阶段的masked multi head attention需要解决如何将dec_input编码成Q。最终输出的logits实际是与Q的维度一致。对于Scaled Dot-Product Attention,其公式如下:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
在《Transformer的PyTorch实现之若干问题探讨(一)》中,decoder阶段,Q的维度为[2,8,6,64](2为batch size,8为head数,6为句子长度,64为向量长度),K的维度为[2,8,5,64],V的维度为[2,8,5,64]。其中, Q K T QK^T QKT的维度为[2,8,6,5] 的,可以理解每个查询张量Q对每个键值张K的注意力权重。之后乘以V,维度为[2,8,6,64]。可以看到最终的维度是根据查询张量Q来加权值向量V。Q就是dec_input经过masked multi head attention得来。那么,dec_input中实际是包含了所有的标签的。那么dec_input是如何mask掉不需要的token的呢?
2.Decoder中的self attention mask
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs):
'''
这三个参数对应的不是Q、K、V,dec_inputs是Q,enc_outputs是K和V,enc_inputs是用来计算padding mask的
dec_inputs: [batch_size, tgt_len]
enc_inpus: [batch_size, src_len]
enc_outputs: [batch_size, src_len, d_model]
'''
dec_outputs = self.tgt_emb(dec_inputs)#词序号编码成向量
dec_outputs = self.pos_emb(dec_outputs).cuda()#位置编码
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs).cuda() #[2, 6, 6]
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs).cuda() #[2, 6, 6],上三角矩阵
# 将两个mask叠加,布尔值可以视为0和1,和大于0的位置是需要被mask掉的,赋为True,和为0的位置是有意义的为False
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask +
dec_self_attn_subsequence_mask), 0).cuda()
# 这是co-attention部分,为啥传入的是enc_inputs而不是enc_outputs:enc_outputs是向量,这儿是需要通过词编码来判断是否需要mask掉
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) #[2, 6, 5]
for layer in self.layers:
dec_outputs = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
return dec_outputs # dec_outputs: [batch_size, tgt_len, d_model]
上述代码为Decoder部分。可以看到有两个mask:dec_self_attn_pad_mask(用于将dec_inputs中的P mask掉)与dec_self_attn_subsequence_mask(用于实现decoder的self attention)。这两个mask在后面会相加合并。这儿可以分别展示二者的值,其中:
dec_self_attn_pad_mask:
tensor([[[False, False, False, False, False, False],
[False, False, False, False, False, False],
[False, False, False, False, False, False],
[False, False, False, False, False, False],
[False, False, False, False, False, False],
[False, False, False, False, False, False]],
[[False, False, False, False, False, False],
[False, False, False, False, False, False],
[False, False, False, False, False, False],
[False, False, False, False, False, False],
[False, False, False, False, False, False],
[False, False, False, False, False, False]]], device='cuda:0')#[2, 6, 6]
dec_self_attn_subsequence_mask:
tensor([[[0, 1, 1, 1, 1, 1],
[0, 0, 1, 1, 1, 1],
[0, 0, 0, 1, 1, 1],
[0, 0, 0, 0, 1, 1],
[0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0]],
[[0, 1, 1, 1, 1, 1],
[0, 0, 1, 1, 1, 1],
[0, 0, 0, 1, 1, 1],
[0, 0, 0, 0, 1, 1],
[0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0]]], device='cuda:0', dtype=torch.uint8)#[2, 6, 6]
可以看到,dec_self_attn_pad_mask全为false,这是因为dec_input中不包含P,而dec_self_attn_subsequence_mask为上三角矩阵,对于每个token,需要mask掉它之后的token(本代码中,为1或True的位置会被mask掉)。接下来进一步追问,为什么上三角矩阵就可以mask掉该token之后的token?具体是如何实现的呢?
对于前文的Scaled Dot-Product Attention公式,代码中的表述实际为:
def forward(self, Q, K, V, attn_mask):
'''
Q: [batch_size, n_heads, len_q, d_k]
K: [batch_size, n_heads, len_k, d_k]
V: [batch_size, n_heads, len_v(=len_k), d_v] 全文两处用到注意力,一处是self attention,另一处是co attention,前者不必说,后者的k和v都是encoder的输出,所以k和v的形状总是相同的
attn_mask: [batch_size, n_heads, seq_len, seq_len]
'''
# 1) 计算注意力分数QK^T/sqrt(d_k)
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores: [batch_size, n_heads, len_q, len_k]
# 2) 进行 mask 和 softmax
# mask为True的位置会被设为-1e9
scores.masked_fill_(attn_mask, -1e9) # 把True设为-1e9
attn = nn.Softmax(dim=-1)(scores) # attn: [batch_size, n_heads, len_q, len_k]
# 3) 乘V得到最终的加权和
context = torch.matmul(attn, V) # context: [batch_size, n_heads, len_q, d_v], [2, 8, 5, 64]
'''
得出的context是每个维度(d_1-d_v)都考虑了在当前维度(这一列)当前token对所有token的注意力后更新的新的值,
换言之每个维度d是相互独立的,每个维度考虑自己的所有token的注意力,所以可以理解成1列扩展到多列
返回的context: [batch_size, n_heads, len_q, d_v]本质上还是batch_size个句子,
只不过每个句子中词向量维度512被分成了8个部分,分别由8个头各自看一部分,每个头算的是整个句子(一列)的512/8=64个维度,最后按列拼接起来
'''
return context # context: [batch_size, n_heads, len_q, d_v]
其中,Q,K,V的维度都是[2, 8, 6, 64], score的维度为[2, 8, 6, 6],即每个token之间的注意力分数。这儿取出一个batch中的一个head下的注意力分数a为例,a的维度为[6, 6],如图所示:
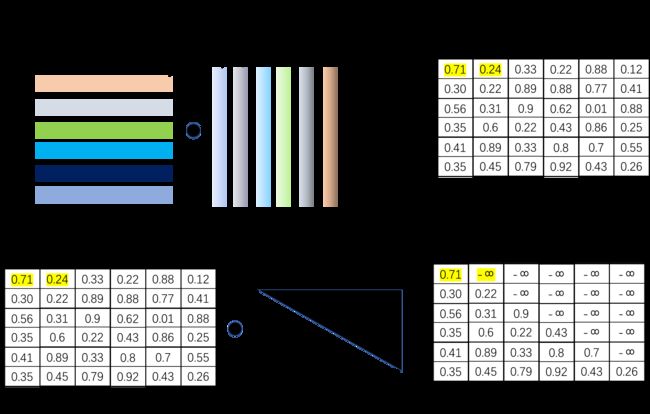
如上图所示,在得分score中,标黄的0.71和0.24分别是S与S,以及S与I的词向量相乘得到。由于I在S后面,所以需要通过mask将其置为负无穷大,而0.71需要保留,因为是S与S在同一个位置上。因此这个mask矩阵为上三角矩阵。