手撕yolo3系列——详解train训练代码(详细注释)
完整代码百度云直达链接(包含预训练权重)(小白注释)
https://pan.baidu.com/s/1US6e93OaCYOghmF21v0UIA
提取码:z8at
参考链接
【注】代码是大神的代码,在此基础上添加了详细的小白注释,方便我以后阅读。
上一节:详解yolo3整体网络代码
本节代码所在文件pytorch_yolo3/train.py主程序
pytorch_yolo3/nets/yolo_training.py子程序
文章目录
- 回顾
- 编码
- 编码成什么样
- 怎么编
- 计算loss
-
- loss的产生
- YOLOLoss类内容
回顾
这节不再一行行的按顺序读代码了(大型的程序一般都是一层一层地往里剥),讲解代码时我会尽量配相应的图来加以说明整套流程的思路,对!主要是思路。
先把程序放一边,回顾历史,然后想想当下该干嘛。前面两节主要在搭建网络(模型),搭建好了只要输入一张图片就可以得到了一个预测。接下来想训练,是不是该拿一个正确的结果与网络输出对比,然后指引着网络向正确的方向前进(优化)。这个正确的结果就是标签,或者target啥说法都行,这个过程实际上就是反向传播,最终得到使得网络输出得到正确的结果,或者足够接近能让我们接受的结果。
总结上述步骤:输入训练图片–>网络得到预测–>获取该图片标签–>标签与预测结果对比得到loss–>反向传播–>优化器优化权值
前两步已经可以完成了,只要第三步做好,后续工作也就容易了,都已经有现成的了。(反传调用backward函数,优化调用optim库即可)。
编码
有人这里会感到疑惑:第三步应该更简单啊。制作好数据集不就有标签了吗,框的信息还有类别信息都有了,直接拿来当做标签就好了呀。但你有没有发现,yolo3网络最终输出的并不是简简单单由几个值构成的张量,而是(batch_size,3x(classes+5),13,13)、(batch_size,3x(classes+5),26,26)、(batch_size,3x(classes+5),52,52),所以标签得跟网络的输出匹配得上才能对比。
如果是分类任务的话那可能只需要输出一个类别就够了,那么用一个代表类别的值作标签就行,不必那么麻烦。检测任务的话面临着一张图片可能包含好几个物体,前提是你根本不知道会有几个物体,因此不能像分类任务用的那种方法指定输出维度。这也是检测任务难度的所在,不仅要分类,还要知道有几个,分别在哪。
因此检测任务的标签要有一种特殊的形式,因此yolo3网络的输出会采取那样的格式,并且yolo3采用了分而治之(后面会讲解)的思想。将原本数据集里的标签转化成训练网络需要的标签,这个过程就是编码。就连手写数字识别那个入门任务也要将图片的标签:0、1、2…转化成独热编码不是吗?
编码成什么样
上面说了我们要将标签编码,那么究竟想编成什么样的数据呢?
【注】实际上特征图size是(batch_size,3,13,13),看图的时候先忽略前两个维度
yolo3设置了9个anchor box,分为三组,每组3个,每组框分别从属于一个特定的feature map。好比下图中蓝框,黄框,红框就属于13x13这个维度的feature map。
下图中蓝色是标签框(Ground Truth),先读取batch_size张图片进来,遍历每张图片的原始标签,size为(batch_size,n,5),n是某图片含有真实物体的数量,最后一维5包括了x、y、w、h、cls这5个信息。将每张图的所有标签框分别与9个anchor box(不止图片上的这三个)进行IOU(交并比)计算,找出IOU结果最大的那个anchor box所属于的特征层,该标签框也属于该特征层,它所有的编码操作都在这个层里进行。

【注:上述IOU计算是把anchor box和标签框移到坐标原点计算,不用考虑它们的真实位置,只考虑尺寸(形状)关系】
例如,蓝色标签框分别与9个anchor box计算完IOU,发现与红框的IOU最大,红框又属于13x13这个特征层,那么蓝色标签框也属于这个特征层。
我们需要学习的东西就是框的信息x、y、w、h、cls,因此需要编码的也是它们,但yolo3还多了一个指标,叫做confident,置信度,代码中简写为conf,有物体的地方conf=1,否则等于0。
首先是x、y,它是标签框在原图上的中心坐标值,将其转化为特征图上的坐标值(9个anchor box的尺寸也是基于原图的,也要转化成特征图上的尺寸),然后进行向下取整floor就可以得到这个框的坐标所属于的网格(cell)的坐标了。
例如,标签框在特征图上的坐标是蓝点,它属于红色这个网格,红色这个网格的坐标是以左上角绿点为参考点,那么蓝点和绿点坐标的差值tx,ty就是编码后的结果,也就是可用于训练的标签。(t是target缩写)
作者希望每个网格做好自己分内的事情,框中心落到网格里,该网格就负责学习它,学习的目标也只是[0,1]范围内的偏移量,比直接学习原始坐标值更容易收敛。这就是分而治之思想的体现。
接下来就是w、h。同样,为了更好地收敛,作者不想直接用标签框的真实w、h作为学习目标(target),而是通过先验框来过渡,让网络来以先验框与标签框的偏差(比值)作为学习目标。即:
其中前缀g代表标签框的属性,a代表先验框的属性
tw = log(g_w/a_w)
th = log(g_h/a_h)
【看不懂直接跳过】因为gw,gh是基于特征图尺寸的,解码得到预测的w、h乘以特征图的下采样倍率即可。解码的时候注意anchors也是基于特征图尺寸的,实际上是scaled_anchors。代码注释有说明,解码操作以后说,这里只是提醒一下。
可以参考一下这篇目标检测——理解Anchor box的作用
剩下的cls和conf就比较简单了,cls采用one hot编码,属于哪个类别就置1,其余全为0。标签框落在哪个cell里面,那个cell的conf属性就置1,否则置0。
怎么编
确定了编码的结果,最后就是实现,这个过程怎么编。
如下图:batch_size就是每次送进网络训练的图片数量,我们暂且把它忽略,或者看做1。之前说需要编码的信息有x、y、w、h、conf、cls。我以x的编码信息tx为例,其他类似。
首先,根据前面确定好标签框与哪个anchor box最匹配,属于哪个特征层。如果该标签框与13*13这个特征层中的蓝色anchor box最匹配,然后找到属于哪个网格(cell),然后计算相对于网格坐上角点的偏移tx,并将tx储存在该网格中,[b,0,5,5] = 0.9,如下图:(这些操作在yolo_training.py的YOLOLoss类中的get_target函数里进行)
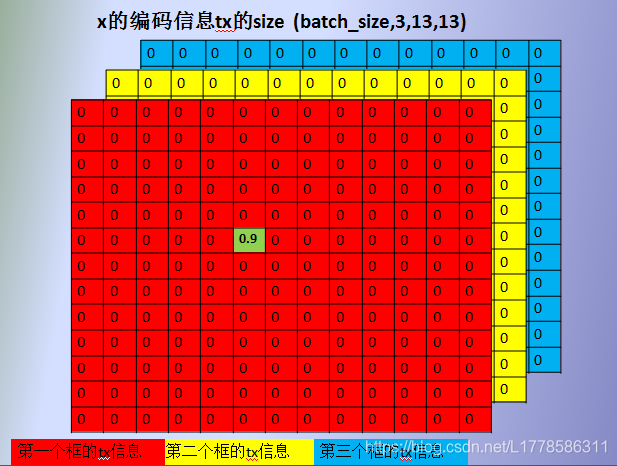
【注】b是图片的索引,0是anchor box的索引(每个anchor box都有自己的索引号),编码信息三个通道的索引与该特征层三个anchor box的索引一一对应,相当于绑定了anchor box的信息,方便后面解码工作。(编码tw、th的时候用到了anchor box 的信息,解码也要用到anchor box的信息)。最后,(5,5)就是特征图上的坐标索引了。
不同的标签框匹配不同的anchor box分配到不同的地方,又是分而治之。其实之前看到的yolo网络三路输出也是分而治之思想的体现,不同特征层检测特定尺寸范围的目标。
刚才那张图那样表达三个框只是为了方便观看而已,其实一个特征图的三个框是应该按照上图那样存在的,每个通道各代表一个框。因此可以在同一个位置(网格),预测多个框(同一个位置,不同通道),它们互不干扰。需要注意的是一个框的tx、ty、tw、th、conf、cls是分开储存、联合使用,共同表达,但是位置以及通道要一一对应。此外,除了cls,其他size都是
(batch_size,3,feature_map_w,feature_map_h),而cls的size多了一个维度储存类别信息,类别不止一个(利用one hot编码)
(batch_size,3,feature_map_w,feature_map_h,num_class)
详情请看代码。
计算loss
loss的产生
loss就是将完成编码的标签与网络的输出值比较得到的。主程序train.py中的训练函数是
def fit_ont_epoch(net,yolo_losses,epoch,epoch_size,epoch_size_val,gen,genval,Epoch,cuda):
将yolo_losses传给这个函数即可训练,于是再找找yolo_losses的来源:
yolo_losses = []
for i in range(3):
yolo_losses.append(YOLOLoss(np.reshape(Config["yolo"]["anchors"],[-1,2]),
Config["yolo"]["classes"], (Config["img_w"], Config["img_h"]), Cuda))
经过3次遍历是因为上节说了yolo3网络三路输出,final_out1,final_out2,final_out3。
首先,实例化三个YOLOLoss类的对象并加入列表里,YOLOLoss类初始化需要四个参数:anchors(reshape成(9,2)), num_classes, img_size, cuda,如上面代码所示。然后将这些对象传给fit_ont_epoch函数 。
YOLOLoss类继承nn.Module,并改写forward函数,它需要两个参数:yolo3模型的输出以及数据集原始的标签。
在函数fit_ont_epoch内部使用三个YOLOLoss类的对象并传参(调用forward)计算各自结果(损失),最后再加起来。如下所示:
for i in range(3):
# 分别对三个对象传参计算各自结果(损失)
loss_item = yolo_losses[i](outputs[i], targets)
losses.append(loss_item[0])
loss = sum(losses)
fit_ont_epoch函数部分内容:
def fit_ont_epoch(net,yolo_losses,epoch,epoch_size,epoch_size_val,gen,genval,Epoch,cuda):
total_loss = 0
val_loss = 0
start_time = time.time()
# tqdm.pos = 0
with tqdm(total=epoch_size,desc=f'Epoch {epoch + 1}/{Epoch}',postfix=dict,mininterval=0.3) as pbar:
for iteration, batch in enumerate(gen):
if iteration >= epoch_size:
break
images, targets = batch[0], batch[1]
with torch.no_grad():
if cuda:
images = Variable(torch.from_numpy(images).type(torch.FloatTensor)).cuda()
targets = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)) for ann in targets]
else:
images = Variable(torch.from_numpy(images).type(torch.FloatTensor))
targets = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)) for ann in targets]
optimizer.zero_grad()
# yolo3输出的final_out1, final_out2, final_out3
outputs = net(images)
losses = []
for i in range(3):
# 分别对三个对象计算各自结果(损失)
loss_item = yolo_losses[i](outputs[i], targets)
losses.append(loss_item[0])
loss = sum(losses)
loss.backward()
optimizer.step()
total_loss += loss
waste_time = time.time() - start_time
# print('\nEpoch:'+str(epoch+1)+'/'+str(Epoch))
# print('iter:'+str(iteration)+'/'+str(epoch_size)+'||Total Loss: %.4f || %.4fs/step'%(total_loss/(iteration+1),waste_time))
pbar.set_postfix(**{'total_loss': total_loss.item() / (iteration + 1),
'lr' : get_lr(optimizer),
'step/s' : waste_time})
pbar.update(1)
start_time = time.time()
YOLOLoss类内容
所以,现在所有编码以及损失计算的过程都是在YOLOLoss类里,它位于yolo_training.py这个子程序里面。接下来看看这个类里面的内容。
首先,定义好所有需要的属性:
class YOLOLoss(nn.Module):
def __init__(self, anchors, num_classes, img_size, cuda):
super(YOLOLoss, self).__init__()
self.anchors = anchors # (9,2)
self.num_anchors = len(anchors) # 9
self.num_classes = num_classes
self.bbox_attrs = 5 + num_classes
self.feature_length = [img_size[0]//32,img_size[0]//16,img_size[0]//8] # 13,26,52
self.img_size = img_size
self.ignore_threshold = 0.5
self.lambda_xy = 1.0
self.lambda_wh = 1.0
self.lambda_conf = 1.0
self.lambda_cls = 1.0
self.cuda = cuda
接着改写继承自nn.Module的forward函数
def forward(self, input, targets=None):
# input前后分别为YoloBody网络的输出final_out1,final_out2,final_out3,每次输入一个
# shape为batchsize,3*(5+num_classes),13,13
# 每次训练的图片数量,batch_size简写bs
bs = input.size(0)
# 特征层的高
# final_out1:13; final_out2:26; final_out3:52
in_h = input.size(2)
# 特征层的宽(同上)
in_w = input.size(3)
# 计算步长
# 每一个特征点对应原来的图片上多少个像素点
# 如果特征层为13x13的话,一个特征点就对应原来的图片上的32个像素点
# 或者说是该特征层下采样倍率
stride_h = self.img_size[1] / in_h
stride_w = self.img_size[0] / in_w
# 把先验框的尺寸调整(缩小)成适应特征层的大小
# 即计算出先验框在特征层上对应的宽高
scaled_anchors = [(a_w / stride_w, a_h / stride_h) for a_w, a_h in self.anchors]
# bs,3*(5+num_classes),13,13 -> bs,3,(5+num_classes),13,13 -> bs,3,13,13,(5+num_classes)
prediction = input.view(bs, int(self.num_anchors/3),
self.bbox_attrs, in_h, in_w).permute(0, 1, 3, 4, 2).contiguous()
# 对prediction预测进行调整
# [..., 0],[...,-1]这种只索引一个值得到的结果会少了最后一个维度,(bs, 3, 13, 13)
# 将网络的x、y输出限制在(0,1)区间
x = torch.sigmoid(prediction[..., 0]) # Center x
y = torch.sigmoid(prediction[..., 1]) # Center y
w = prediction[..., 2] # Width
h = prediction[..., 3] # Height
# 将置信度限制在(0,1)区间
conf = torch.sigmoid(prediction[..., 4]) # Conf
# [..., 5:]这种索引多个值(哪怕5:这个范围内只有一个值)得到的结果维度也不变,(bs, 3, 13, 13,num(5:))
# 最终5:索引出来几个数,最后一维就是几
pred_cls = torch.sigmoid(prediction[..., 5:]) # Cls pred.
# 找到哪些先验框内部包含物体
mask, noobj_mask, tx, ty, tw, th, tconf, tcls, box_loss_scale_x, box_loss_scale_y =\
self.get_target(targets, scaled_anchors,
in_w, in_h,
self.ignore_threshold)
noobj_mask = self.get_ignore(prediction, targets, scaled_anchors, in_w, in_h, noobj_mask)
if self.cuda:
box_loss_scale_x = (box_loss_scale_x).cuda()
box_loss_scale_y = (box_loss_scale_y).cuda()
mask, noobj_mask = mask.cuda(), noobj_mask.cuda()
tx, ty, tw, th = tx.cuda(), ty.cuda(), tw.cuda(), th.cuda()
tconf, tcls = tconf.cuda(), tcls.cuda()
box_loss_scale = 2 - box_loss_scale_x*box_loss_scale_y # 大物体系数小,小物体系数大,平衡系数
# losses.
loss_x = torch.sum(BCELoss(x, tx) / bs * box_loss_scale * mask)
loss_y = torch.sum(BCELoss(y, ty) / bs * box_loss_scale * mask)
loss_w = torch.sum(MSELoss(w, tw) / bs * 0.5 * box_loss_scale * mask) # 希望更注重x、y的损失,所以在w、h损失前面乘以0.5
loss_h = torch.sum(MSELoss(h, th) / bs * 0.5 * box_loss_scale * mask)
loss_conf = (torch.sum(BCELoss(conf, mask) * mask / bs) + # 将有物体的地方网络输出的conf与mask上的1对比
torch.sum(BCELoss(conf, mask) * noobj_mask / bs)) # 将没有物体的地方网络输出的conf与mask上的0相比
loss_cls = torch.sum(BCELoss(pred_cls[mask == 1], tcls[mask == 1])/bs) # 有物体的地方计算类别cls损失
loss = loss_x * self.lambda_xy + loss_y * self.lambda_xy + \
loss_w * self.lambda_wh + loss_h * self.lambda_wh + \
loss_conf * self.lambda_conf + loss_cls * self.lambda_cls # 所有损失相加
# print(loss, loss_x.item() + loss_y.item(), loss_w.item() + loss_h.item(),
# loss_conf.item(), loss_cls.item(), \
# torch.sum(mask),torch.sum(noobj_mask))
return loss, loss_x.item(), loss_y.item(), loss_w.item(), \
loss_h.item(), loss_conf.item(), loss_cls.item()