【Spring源码分析】循环依赖的底层源码剖析
循环依赖的底层源码剖析
- 一、预知知识
- 二、循环依赖的底层源码剖析
-
- 1. Spring 是如何存储半成品Bean的?
-
- getEarlyBeanReference 方法的源码分析
- 2. Spring 是如何解决的循环依赖呢?
-
- 测试
- 3. 哪些循环依赖 Spring 是无法解决的呢?
-
- @Async 引起的循环依赖
-
- 解决方案
- 单构造注入引起的循环依赖
-
- 解决方案
- 三、总结
| 阅读此需阅读下面这些博客先 |
|---|
| 【Spring源码分析】Bean的元数据和一些Spring的工具 |
| 【Spring源码分析】BeanFactory系列接口解读 |
| 【Spring源码分析】执行流程之非懒加载单例Bean的实例化逻辑 |
| 【Spring源码分析】从源码角度去熟悉依赖注入(一) |
| 【Spring源码分析】从源码角度去熟悉依赖注入(二) |
| 【Spring源码分析】@Resource注入的源码解析 |
这篇博客不想阐述循环依赖是啥,只是想从源码的角度分析Spring如何解决的循环依赖?哪种循环依赖Spring自身是解决不了的?(源码分析这玩意每个人看)
一、预知知识
在 getBean->doGetBean 中,如果在单例池中找不到对应的实例的话,就会去尝试创建(这里指的是单例),下面是单例作用域的创建代码(重复阐述这块代码是为了引出一个重要的集合——singletonsCurrentlyInCreation):
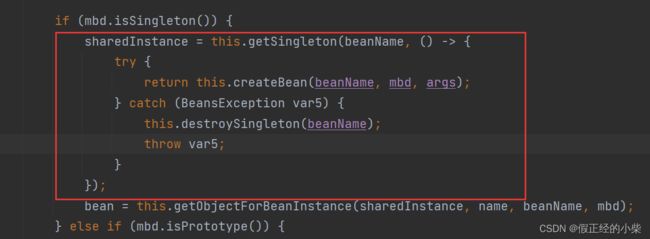
public Object getSingleton(String beanName, ObjectFactory singletonFactory)
singletonFactory 参数对应的就是那个 Lambda 表达式,本质就是创建Bean。
在 getSingleton 方法中,在 singletonFactory.getObject() 调用前(创建Bean),会调用 beforeSingletonCreation(beanName),在那之后又会调用 afterSingletonCreation(beanName),其实就是将 beanName 放入到 singletonsCurrentlyInCreation 集合中和从集合中移除,表示在创建中,和创建后的逻辑。
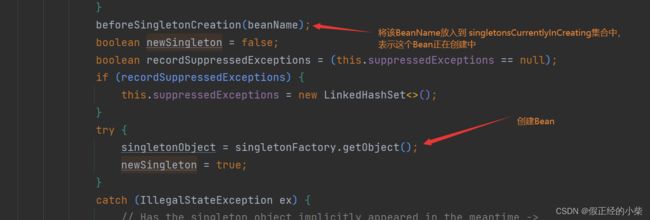
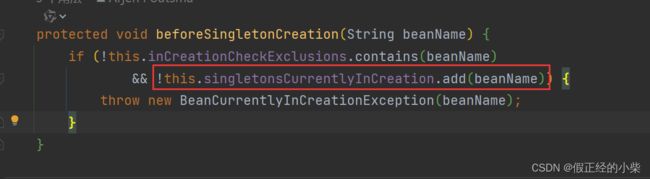
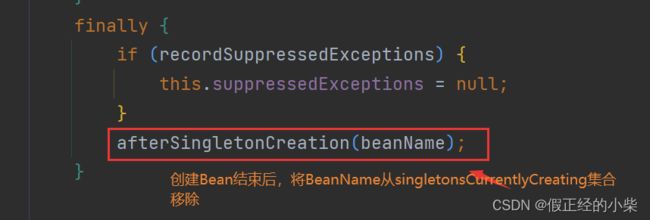

经过了实例化、属性注入、初始化后的Bean最后通过 addSingleton 加入到单例池中。
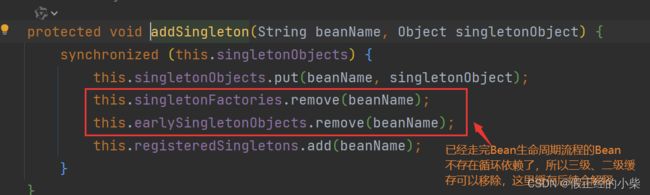
在属性注入阶段,针对一般情况,排除掉 @Value->autowireCandidate->@Qualifier->@Primary->@Priority 这六步筛选…然后其去找Bean注入时,要么就是单例池已经存在,那么直接使用,要么就是不存在,调用getBean方法去获取,也就是会去走创建逻辑,也就是走上面阐述的流程,创建前会将其放入到那个 singletonsCurrentlyInCreating 集合中,表示在创建。
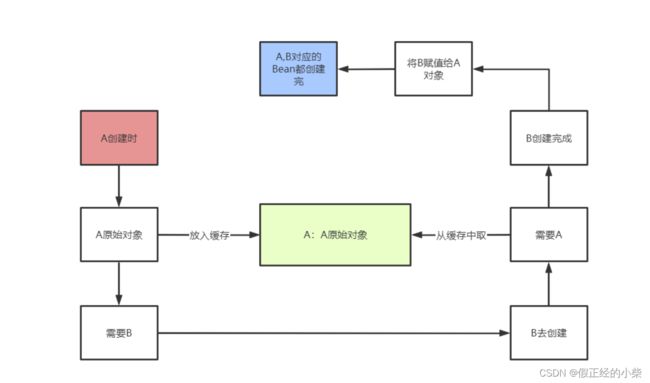
那么可以分析得出,如果当前创建的Bean,在进行属性注入时,属性注入的这个Bean也是在创建中(意思就是在 singletonCurrentlyInCreating集合中),那么就是发生了循环依赖。
下面画个简图:
 循环依赖主要问题就是属性注入的时候出现了循环,那么出现循环的Bean就不能完成真正的实例化(这里的真正的实例化是指已经进行完了属性注入和初始化最终的Bean,不是说单纯的经过了JVM对象创建出来的过程)。
循环依赖主要问题就是属性注入的时候出现了循环,那么出现循环的Bean就不能完成真正的实例化(这里的真正的实例化是指已经进行完了属性注入和初始化最终的Bean,不是说单纯的经过了JVM对象创建出来的过程)。
想要解决这个问题,很简单,就是咱推断构造然后通过反射得到的Bean(就是经过了JVM规范对象创建流程的)将其注入属性,这样就不会阻塞得到真正的Bean了。那 Spring 是如何实现的将这个半成品Bean可以在属性注入阶段拿出来然后注入进去呢? 下面进行源码分析。
在此之前有提,属性注入的时候,是先尝试从单例池中拿,这个从单例池中拿,在调用的 getSingleton 方法,如果没找到再去 getBean 方法。
二、循环依赖的底层源码剖析
其实有关 Spring 对循环依赖问题的解决代码不多的。
1. Spring 是如何存储半成品Bean的?
在 Spring 生命周期的实例化->MergedBeanDefinitionPostProcessor操作完后,会有下面这么一操作:
// 为了解决循环依赖提前缓存单例创建工厂
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
// 只要当前创建的实例是单例的,earlySingletonExposure 一般情况下都为true,这里的 allowCircularReferences默认是true
boolean earlySingletonExposure = (mbd.isSingleton()
&& this.allowCircularReferences
&& isSingletonCurrentlyInCreation(beanName));
// 那既然 earlySingletonExposure 是true,那就会尝试向三级缓存中添加一个ObjectFactory实例
// 这个 ObjectFactory 是一个函数式接口
if (earlySingletonExposure) {
// 循环依赖-添加到三级缓存
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
- 只要咱当前创建的实例是单例的,那么 singletonCurrentlyInCreating 集合中就有这个 beanName,而 allowCircularReferences 默认初始化是 true 的,所以说咱要是当前Bean是单例的话,那么
earlySingletonExposure这个标志变量就是 true。 - earlySingletonExposure 为 true 那就会调用 addSingletonFactory 方法,添加啥东东,咱看看:
private final Mapprotected void addSingletonFactory(String beanName, ObjectFactory singletonFactory) { synchronized (this.singletonObjects) { if (!this.singletonObjects.containsKey(beanName)) { this.singletonFactories.put(beanName, singletonFactory); this.earlySingletonObjects.remove(beanName); this.registeredSingletons.add(beanName); } } }- ObjectFactory 是一个函数是接口,从传递的 Lambda 来看,其内部的 getObject 的实现就对应着 getEarlyBeanReference 方法。最后将这个放入到一个叫
singletonFactories的一个 HashMap 中。
这样做有什么意义呢?咱根据上面的分析进行这里的回答:上述说要解决循环依赖,不就可以在它需要这个Bean的实例,不要进行完整的Bean的生命周期,而是把这个还没进行属性注入前的Bean就直接返回给那个需要这个Bean的Bean。这样就话就不影响它最终Bean的创建,从而解决这个问题。
那这个Bean无非就是指实例化后的Bean,而这个 singletonFactories 的 Map 集合就是为了缓存这个半成品Bean,要是后续出现循环依赖了好使用这个Bean,这样就不影响最终Bean的生成了(最终成品的Bean是否创建完成是判断有无在单例池中,而要想进入到单例池中就应该先进行完整个Bean的生命周期(这里不包括销毁))。
那为啥传这个 ObjectFactory 这个对象,而不是直接缓存刚实例化后的对象呢?
咱先看一下 getEarlyBeanReference 方法的实现:
getEarlyBeanReference 方法的源码分析
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}
- 哦吼~又是遍历BeanPostProcessor,而这次遍历的是
SmartInstantiationAwareBeanPostProcessor#getEarlyBeanReference- getEarlyBeanReference 方法的默认实现就是将 Bean 直接返回
default Object getEarlyBeanReference(Object bean, String beanName) throws BeansException { return bean; } - 但是它有一个地方进行了重写:
- getEarlyBeanReference 方法的默认实现就是将 Bean 直接返回


现在可以知道,不直接传递Bean,而是传递 ObjectFactory 的原因了,就是除了考虑普通Bean的情况下,还需要考虑 AOP 的情况,因为咱不能属性注入需要的是经过 AOP 动态代理的代理Bean,而我们且给普通Bean。
AOP 是在初始化后进行的,所以应该在此之前就应该把 AOP 代理Bean给交出去进行属性注入的,不然也不符合单例Bean的设计了。
我们知道打开 AOP 是需要加个 @EnableAspectJAutoProxy 注解的。
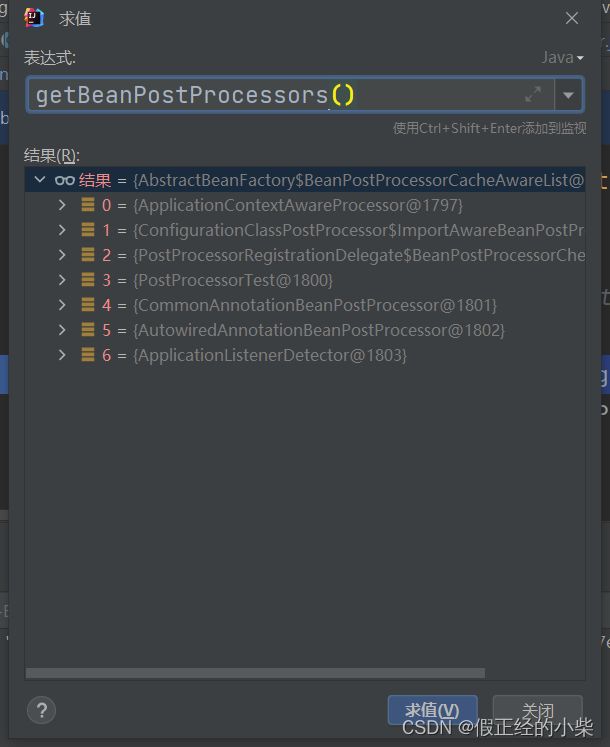
在没有开启 @EnableAspectJAutoProxy 注解时,容器里的 BeanPostProcessor 只有六个(其中一个PostProcessorTest是我自己瞎写的):
 开启后(有七个,多了个
开启后(有七个,多了个 AnnotationAwareAspectJAutoProxyCreator):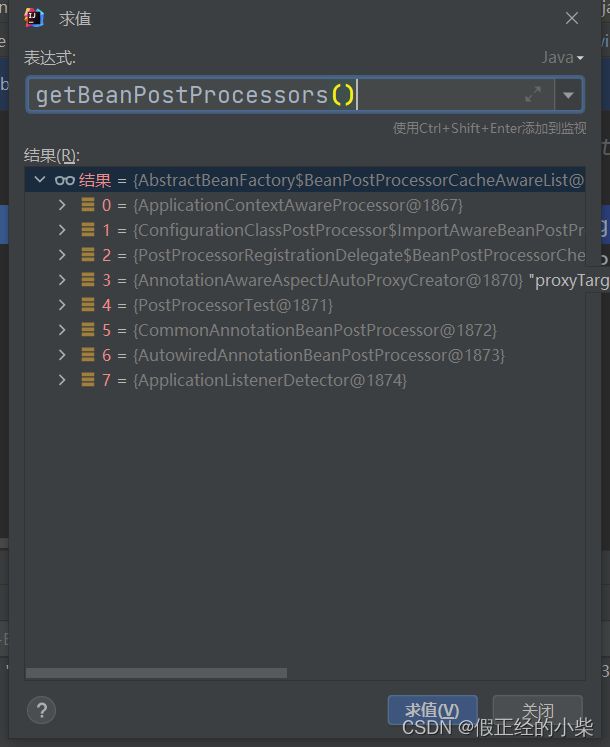
分析它的关系图,咱可以知道它是继承自 AbstractAutoProxyCreator 的
 了解到这就可以了,后面就是阐述 AOP 时该阐述的了,反正你只要知道这个Bean进行AOP返回后,会有标志位进行记录,初始化后判断了在之前进行过了 AOP,那就直接返回原型 Bean 就可以了。
了解到这就可以了,后面就是阐述 AOP 时该阐述的了,反正你只要知道这个Bean进行AOP返回后,会有标志位进行记录,初始化后判断了在之前进行过了 AOP,那就直接返回原型 Bean 就可以了。
2. Spring 是如何解决的循环依赖呢?
首先需要知道在进行属性注入的时(不考虑一个类型容器内出现多个Bean哈,为了统一点),先进行的是 @Lazy 的判断,若有就直接返回了对应代理了(这也是很多Spring没发解决然后使用@Lazy注解可以解决的原因)-> getSingleton 去获取对应 Bean -> getBean 方法去创建Bean。
出现循环依赖了,我们肯定不能让它走创建逻辑啊,那么循环依赖的解决肯定是在 DefaultSingletonBeanRegistry#getSingleton 中获取 Bean 的时候了。
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Quick check for existing instance without full singleton lock
Object singletonObject = this.singletonObjects.get(beanName);
// 单例池中没有,且在SingletonCurrentlyInCreating集合中
// 表示在创建中,说明存在循环依赖
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 从 earlySingletonObjects Map 中获取对应的Bean,这主要是 Spring 修改之前的一个死锁bug
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
// Consistent creation of early reference within full singleton lock
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 调用之前传入Lambda表达式实现的ObjectFactory的getObject()方法获取对应半成品Bean
singletonObject = singletonFactory.getObject();
// 将半成品Bean放入到 earlySingletonObjects 中
this.earlySingletonObjects.put(beanName, singletonObject);
// 将其从 singletonFactories 中移除
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
- 主要逻辑就是如果单例池中存在就直接返回;
- 单例池中不存在,且这个beanName是在创建中,就说明存在循环依赖,那么就会从 singletonFactories 中获取对应的 ObjectFactory 实例调用 getObject 方法去获取半成品Bean;
- 然后将这个半成品Bean放入到 earlySingletonObjects 这个 Map 中,最后将这个半成品Bean进行返回。
以上的逻辑就解决了循环依赖问题了,可以解决循环依赖最关键的一步还是在 singletonFactories 上,因为是它缓存了半成品的Bean,不管是普通Bean还是AOP代理Bean出现循环依赖都可以得到解决。
测试
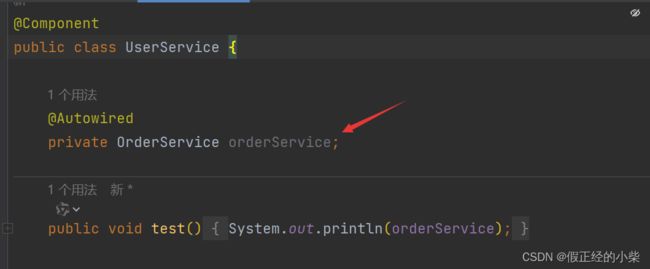


不管开不开 AOP 都没啥子问题滴,这种循环依赖 Spring 都会给俺们解决滴。
3. 哪些循环依赖 Spring 是无法解决的呢?
上面阐述了在开启了 AOP 然后产生了循环依赖的话会提前对其进行创建(也不是说提前吧,就是出现循环依赖那个注入调用getSingleton的时候,就是在属性注入阶段,相对真正AOP初始化后阶段肯定是提前了的),若提前了的话那初始化后操作就不会进行 AOP 了,而是直接返回的 Bean,那它是怎么最后返回的代理对象的呢?
对应着下面这段代码:
if (earlySingletonExposure) {
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
// beanName被哪些bean依赖了,现在发现beanName所对应的bean对象发生了改变,那么则会报错
String[] dependentBeans = getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet<>(dependentBeans.length);
for (String dependentBean : dependentBeans) {
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName,
"Bean with name '" + beanName + "' has been injected into other beans [" +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
"] in its raw version as part of a circular reference, but has eventually been " +
"wrapped. This means that said other beans do not use the final version of the " +
"bean. This is often the result of over-eager type matching - consider using " +
"'getBeanNamesForType' with the 'allowEagerInit' flag turned off, for example.");
}
}
}
}
就是如果存在循环依赖,那么后面调用 getSingleton 获取到的 earlySingletonReference 实例对象就不会为空,这个 earlySingletonReference 可能是普通Bean也可能是 AOP 的代理Bean。
但是在赋值给需要暴露的exposedObject之前,还经过了一个 exposedObject == bean ,这样是去保证循环依赖的出现应该最终得到的Bean也应该和最初反射得到的Bean是指向同一个堆内存的,意思就是同一个对象,这样的话就允许赋值,否则会抛出 BeanCurrentlyInCreationException 异常,表示循环依赖导致出错。
@Async 引起的循环依赖
通过 @EnableAsync 注解开启 @Async 的使用,就相当于向容器中添加了 AsyncAnnotationBeanPostProcessor 这个 BeanPostProcessor。也是在初始化后进行的操作,若用了 @Async 的话会给 Bean 生成一个代理。
 就是说当这个Bean存在循环依赖,又开启并使用了 @Async 注解,那么就会出现暴露出来的Bean和原先反射的实例Bean并不是指向同一个堆内内存。这样的话就会报错咯~
就是说当这个Bean存在循环依赖,又开启并使用了 @Async 注解,那么就会出现暴露出来的Bean和原先反射的实例Bean并不是指向同一个堆内内存。这样的话就会报错咯~
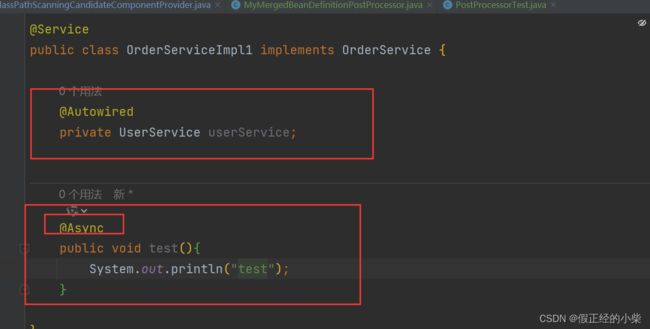

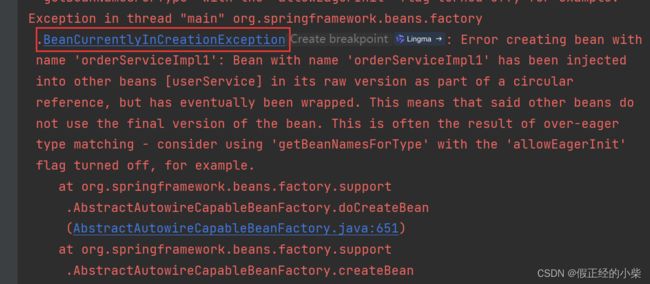
当然这个还和本身加载的顺序有关,比如这里是先创建的 OrderService,然后去属性注入 UserService,UserService就会出现循环依赖,那么注入OrderService时候就会使用三级缓存,然后把OrderService会放入二级缓存,然后OrderService又使用了@Async注解,那在初始化后那个exposedBean就会是一个代理Bean且OrderService在二级缓存中是存在的,所以抛出了异常。
所以我们需要尽量避免这种存在循环依赖的代码,有的时候加载Bean的顺序不同会有着不一样的效果,遍历是遍历 beannames集合,而存储 beanName 是 Set 集合,所以是无序的。
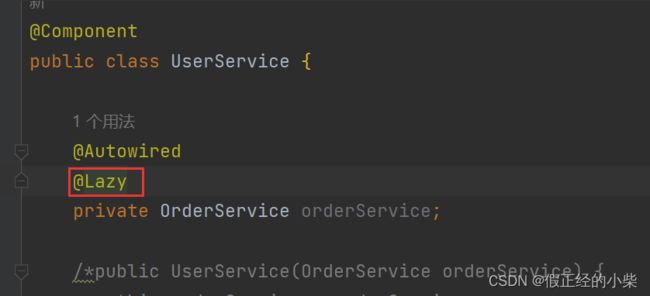
解决方案
注入 OrderService 的时候加上个 @Lazy 注解,那 UserService Bean 创建的时候注入 OrderService 的时候就不需要去调用 getSingleton 方法,Bean就不会到二级缓存中,那么最后就不会有 exposedBean 和 原Bean == 对比。

单构造注入引起的循环依赖
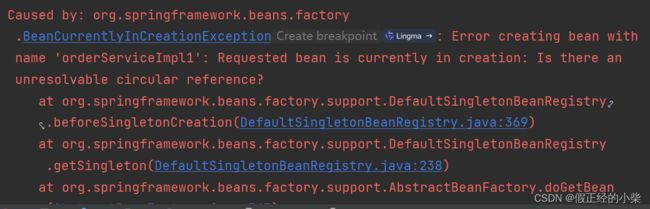
这边将 OrderService 改成构造注入 UserService,也会产生异常(也是和顺序有关,上面说了,我这里的例子是先注入的OrderService):

 这里还是得和生命周期联系在一起,需要知道将半成品Bean放入三级缓存是在实例化Bean和MergedBeanDefinition之后的。
这里还是得和生命周期联系在一起,需要知道将半成品Bean放入三级缓存是在实例化Bean和MergedBeanDefinition之后的。
那么先创建 OrderService,实例化Bean的时候需要注入 UserService,此时 OrderService 已在 singletonsCurrentlyInCreation 集合中,在注入UserService时,需要填充 OrderService,首先 OrderService 没被 @Lazy 修饰,getSingleton 方法也返回的是null,虽存在循环依赖,但三级缓存中是不存在这个的,因为OrderService还在实例化阶段。所以这里填充 OrderService 只能走 getBean 逻辑,那么又得尝试放入 singletonsCurrentlyInCreation 集合中。所以会抛出异常:

解决方案
在注入 OrderService 的时候加上个 @Lazy 注解,这样的话 UserService Bean 就可以创建出来了。那么 OrderService 自然是可以创建出来的。


三、总结
-
普通用法和AOP引起的循环依赖,Spring都自动给咱解决了,但扔存在一些用法的时候引起的循环依赖需要我们注意。在写代码的时候,咱尽量别写存在循环依赖的代码。
-
像 @Async 注解和构造注入引起的循环依赖,执行顺序不同的时候可能会抛出异常,使用 @Lazy 注解也是可以解决的,但是尽量注意不要写。
-
Spring解决循环依赖靠的就是三级和二级缓存,那咱来总结下三级缓存在 Spring 的作用都是啥:
singletonObjects:缓存所有经过完成整个生命周期的单例Bean。earlySingletonObjects:缓存未经过完整生命周期的Bean,如果某个Bean出现了循环依赖,就会提前把这个暂时未经过完整生命周期的Bean放入 earlySingletonObjects 中,这个 Bean 如果要经过 AOP,那么就会把代理对象放入到 earlySingletonObjects 中,否则就是把原始对象放入 earlySingletonObjects,但是不管怎样,就算是代理对象,代理对象所代理的原始对象也是没有经过完整生命周期的,所以放入 earlySingletonObjects 我们就可以统一认为是未经过完整生命周期的 Bean。singletonFactories:缓存的是一个 ObjectFactory,也就是一个 Lambda 表达式。在每个Bean生成的过程中,实例化Bean和MergedBeanDefinition之后,就会提前基于原始对象暴露出一个Lambda表达式,并保存到三级缓存中,这个Lambda表达式可能用到可能用不到,如果当前Bean没有出现循环依赖,那么这个Lambda表达式没用,当前Bean按照自己的生命周期正常执行就行,执行完后会直接把Bean放入singletonObjects 中,如果当前Bean在依赖注入的时候发现出现了循环依赖(当前正在创建的Bean被其他Bean依赖了),则从三级缓存中拿到Lambda表达式,并执行Lambda表达式得到一个对象,并把得到的对象放入到二级缓存(如果当前Bean需要AOP,那么执行Lambda表达式得到的对象就是对应的代理对象,如果无需AOP,则直接得到一个原始对象)。