C++进阶——智能指针(C++11)
一、为什么要用智能指针
简单来说,由于异常会使得程序的执行流乱跳,因此就会容易产生内存泄漏等问题。因此就要智能指针来解决了。
二、智能指针原理
简单来说,智能指针就是一个类,但我们使用时可以把这个类的对象像指针一样使用。而也正是因为智能指针是一个自定义类型的类,因此无论程序正常结束还是因为抛异常的原因跳到其他栈帧里去,只要程序离开了当前的栈帧,那么该栈帧里的所有自定义类型对象都会调用其析构函数,智能指针也不意外,于是当智能指针调用析构函数时,就会顺便把自己管理的内存也给释放了。因此无论程序的执行流怎么跳,被智能指针管理的内存都会在程序离开栈帧时被智能指针自动释放。于是我们再也不用担心程序内存泄漏啦!
三、智能指针类型
1、auto_ptr(C++98)
(1)auto_ptr 丐版实现
namespace mcz
{
template
class auto_ptr
{
public:
auto_ptr(T* ptr = nullptr)
:_ptr(ptr)
{}
auto_ptr(const auto_ptr& ap)
:_ptr(ap._ptr)
{
ap._ptr = nullptr; // ap 被置空了
}
~auto_ptr()
{
if (_ptr != nullptr) delete _ptr;
}
auto_ptr& operator=(const auto_ptr& ptr)
{
_ptr = ap._ptr;
ap._ptr = nullptr; // ap 被置空了
return *this;
}
T& operator*() const
{
return *_ptr;
}
T* operator->() const
{
return _ptr;
}
private:
T* _ptr;
};
} (2)auto_ptr 的缺陷2——指针置空
由于 auto_ptr 只是简单模仿指针,因此如果构造函数和赋值重载函数不置空 ptr 的话,就会导致两个指针同时管理同一块内存,就会导致析构时同一块内存被析构两次,程序崩溃。于是 auto_ptr 就在赋值重载函数和拷贝构造函数中把 ptr 置空了。可是,这又引起了一个大问题:就是当一个 auto_ptr A 拷贝给另一个 auto_ptr B ,或赋值给另一个 auto_ptr C 时,那么 auto_ptr A 就会神不知鬼不觉地被置空了,如果再访问就会报错了。因此我个人非常不建议用 auto_ptr,就算用的话也要注意拷贝和赋值后的 auto_ptr A 的置空问题。
auto_ptr p1 = new int(1);
auto_ptr p2 = p1; // p1 被置空了,再访问 p1 就会报错 2、unique_ptr(C++11)
(1)unique_ptr 原理
为了解决 auto_ptr 引起的两个指针管理一个内存的情况,unique_ptr 用了最粗暴的方式——在 auto_ptr 的基础上把构造函数和赋值重载函数给禁了。但显然,这是不能满足我们的使用场景的。
(2)unique_ptr 丐版实现
namespace mcz
{
template
class unique_ptr
{
public:
unique_ptr(T* ptr)
:_ptr(ptr)
{}
unique_ptr(const unique_ptr& ptr) = delete;
unique_ptr& operator=(const unique_ptr& ptr) = delete;
~unique_ptr()
{
if (_ptr != nullptr) delete _ptr;
}
T& operator*() const
{
return *_ptr;
}
T* operator->() const
{
return _ptr;
}
private:
T* _ptr;
};
} 3、shared_ptr(C++11)
(1)引用计数
i.引用计数原理
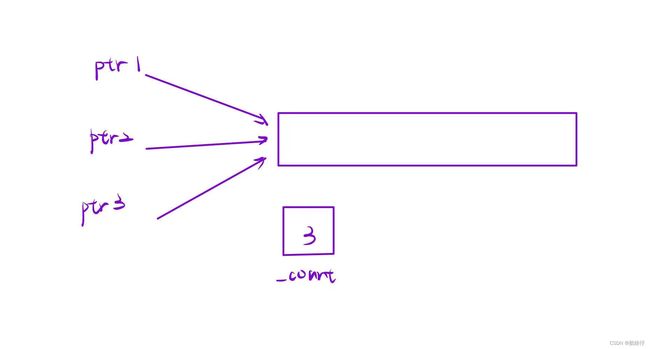
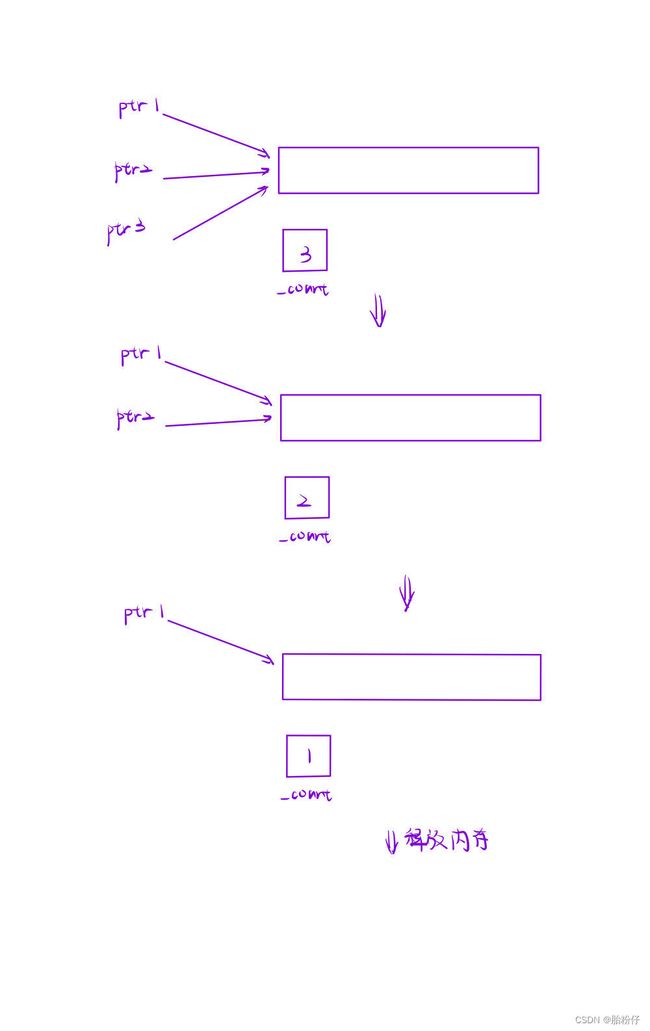
这是解决 auto_ptr 的另一种方案,也是比较好的一种,就是给每块被 shared_ptr 管理的内存加一个动态的 _count 变量,来记录当前这块内存有多少个指针指向它。而这个记录有多少个指针指向内存的方法,就叫做“引用计数”。
ii.引用计数优点
有了引用计数,那我们就可以解决 95% 的多个指针指向同一块内存的问题了。就是当 _count 变量为 1(即当前只剩 1 个指针管理内存)时,析构时才释放掉这块内存,但 _count 不为 1(即不只一个指针管理这块内存)时,析构时就不要释放这块内存。
(2)shared_ptr 丐版实现
namespace mcz
{
template
class shared_ptr
{
public:
shared_ptr(T* ptr)
:_ptr(ptr), _count(new int(1))
{}
shared_ptr(const shared_ptr& ptr)
:_ptr(ptr._ptr), _count(ptr._count++)
{}
~shared_ptr()
{
if (*count == 1)
{
delete _ptr; delete _count;
}
(*_count)--;
}
shared_ptr& operator=(const shared_ptr& ptr);
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
private:
T* _ptr;
int* _count;
};
template
shared_ptr& shared_ptr::operator=(const shared_ptr&ptr)
{
if (ptr._ptr == _ptr || _count == ptr._count) return *this;
if ((*_count)-- == 1)
{
delete _count;
delete _ptr;
}
_ptr = ptr._ptr;
_count = ptr._count;
(*ptr._count)++;
return *this;
}
}; (3)shared_ptr 的缺陷:循环引用
当我们像下面的例子一样构建一个双向链表时,就会遇到一个“死循环”:

而这个“死循环”就会使程序在跳出栈帧时调不出析构函数,进而导致内存泄漏。
4、weak_ptr(C++11)
(1)weak_ptr 原理
为了解决 shared_ptr 的循环引用问题,于是 weak_ptr 就站出来了。在这种双向链表中,我们可以把 next 和 prev 指针的类型换成 weak_ptr

(2)weak_ptr 丐版实现
namespace mcz
{
template
class weak_ptr
{
public:
weak_ptr(T* ptr = nullptr)
:_ptr(ptr)
{}
weak_ptr(const weak_ptr& wp)
:_ptr(wp._ptr)
{}
weak_ptr(const shared_ptr& sp)
:_ptr(sp.get())
{}
~weak_ptr()
{
if (_ptr != nullptr) delete _ptr;
}
weak_ptr& operator=(const weak_ptr& wp)
{
_ptr = wp._ptr;
return *this;
}
T& operator*() const
{
return *_ptr;
}
T* operator->() const
{
return _ptr;
}
private:
T* _ptr;
};
} 四、总结
所以,总的来说,如果我们要用智能指针的话,一般用 shared_ptr 和 weak_ptr 搭配用就可以解决程序因为抛异常而导致执行流乱跳,进而造成内存泄漏等问题了。