ClickHouse常用表引擎
表引擎
表引擎(表的类型)决定了:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据
- 支持哪些查询以及如何支持
- 并发数据访问
- 索引的使用
- 是否可以多线程请求
- 数据复制参数
TinyLog
最简单的表引擎。存储在磁盘中,不支持索引,没有并发控制。
TinyLog支持并发读,但是不支持并发写与并发读写,所以TinyLog表适合存放一些静态信息或者变化缓慢的信息。有点像数仓中的缓慢变化维度。
创建TinyLog引擎表只需要在创建语句最后加上engine=TinyLog

这时在ClickHouse中保存default数据库数据的目录/var/lib/clickhouse/data/default下会多一个t目录
添加两条数据,同时在存放数据的目录可以看到这样的数据结构:

也可以很清晰的看到列式存储的特征,每一个字段存储成一个文件,还有一个存储元数据的文件。
Memory
TinyLog引擎的内存版。性能可以达到秒级10GB,主要用于测试。
Merge
合并查询引擎,主要用于同时并行查询多张表。Merge引擎本身不存数据,类似于关系型数据库的视图。
先创建三张表,分别插入一条记录:
create table t1(id UInt16,name String) engine = TinyLog
create table t2(id UInt16,name String) engine = TinyLog
create table t3(id UInt16,name String) engine = TinyLog
insert into t1(id,name) values(1,'first')
insert into t2(id,name) values(2,'second')
insert into t3(id,name) values(3,'zhangsan')
然后使用merge对他们合并查询
create table t4 (id UInt16,name String) engine = Merge(currentDatabase(),'^t')

MergeTree
合并树引擎,MergeTree引擎(及其系列)是ClickHouse引擎最重要的重点。
他的特点:
- 数据按主键排序
- 可以使用分区
- 支持数据副本
- 支持数据采样
MergeTree会把数据库中有同样表结构的表进行合并,减少文件冗余,提高健壮性。
接下来是俄罗斯人的奇妙比喻:
我们会定期将一些固定格式的数据存到ClickHouse中,而ClickHouse会对每次记录单独创建一个目录和三个文件。这就好像一颗没有人管理的大树,枝丫繁多看起来很茂盛,但是树枝都很纤细,缺乏健壮性,然后MergeTree引擎会将有统一格式的数据合并到一起(分区合并),让小树枝变成枝干,提高健壮性。
语法:
ENGINE=MergeTree() 指定使用哪个引擎
[PARTITION BY expr] 分区键,只能按照日期分区
[ORDER BY expr] 排序键,如果不指定排序键,排序键就是主键,不可指定与主键相同的列
[PRIMARY KEY expr] 主键,如果不指定主键,主键就是排序键,不可指定与排序键的列
[SAMPLE BY expr] 用于抽样的表达式,主键必须包含这个表达式
[SETTNGS name=XXX] 一些其他影响性能的参数
index_granularity:索引粒度。即索引中相邻[标记]间的数据行数,默认是8192
use_minimalistic_part_header_in_zookeeper:数组片段在zookeeper中的存储方法
min_merge_bytes_to_use_drect_io:使用I/O来操作磁盘的合并操作时要求的最小数据量
实例:
CREATE TABLE me_table
(
`date` Date,
`id` UInt8,
`name` String
)
ENGINE = MergeTree()
PARTITION BY date
ORDER BY (id, name)
SETTINGS index_granularity = 8192
INSERT INTO me_table VALUES ('2020-01-01',1,'zhangsan') ('2020-05-01',2,'lisi') ('2020-06-01',3,'wangwu')

插入一条记录就会多一个目录,上面是插入三条记录后表中存储的目录。最后的插入命令可以多执行几次。
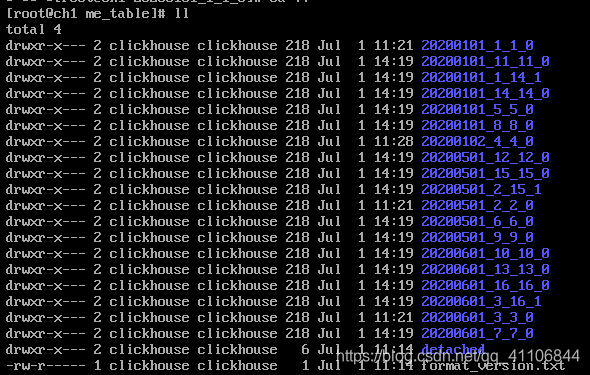
我们可以等一段时间让ClickHouse自动触发merge进行合并,也可以使用optimize table XX手动触发merge进行合并,但是对触发大量读写操作造成服务器宕机。
等了三分钟后自动触发了合并


ReplacingMergeTree
ReplacingMergeTree引擎是MergeTree引擎的延伸,他比MergeTree多了一个Replacing的描述,也就是替换,或者叫做去重–他会在合成过程中删除主键重复的记录,确保主键唯一性。
语法:
ENGINE=ReplacingMergeTree([ver]) var表示的列只能是UInt*,Date和DateTime。
合并的时候会选择var中最大的版本或最后一条保留,有点类似HBASE的裂变
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTNGS name=XXX]
实例:
CREATE TABLE rme_table
(
`date` Date,
`id` UInt8,
`name` String,
`point` UInt8
)
ENGINE = ReplacingMergeTree(point)
PARTITION BY date
ORDER BY (id, name)
INSERT INTO rme_table VALUES ('2020-01-01',1,'zhangsan',10) ('2020-01-01',1,'zhangsan',20) ('2020-06-01',1,'zhangsan',20)('2020-06-01',1,'zhangsan',30)('2020-06-01',1,'zhangsan',30)
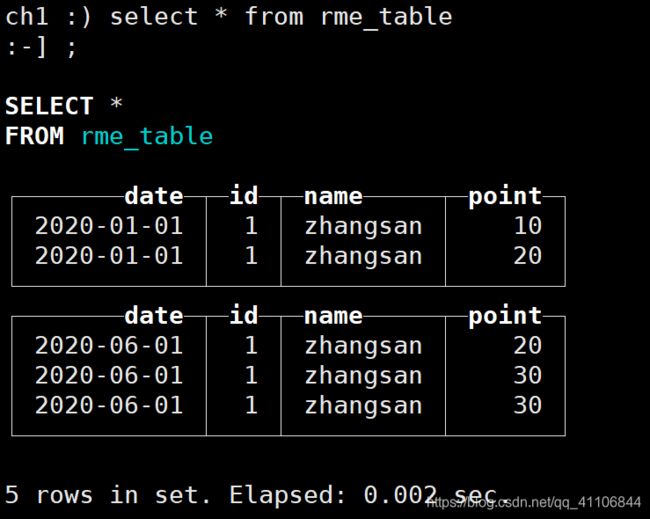
SummingMergeTree
SummingMergeTree做出的延伸是合并,是可加列的累加,不可加列选择第一次输入的值。
语法:
ENGINE=SummingMergeTree([columns])
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTNGS name=XXX]
实例:
CREATE TABLE sme_table
(
`date` Date,
`name` String,
`sum` UInt16,
`not_sum` UInt16
)
ENGINE = SummingMergeTree(sum)
PARTITION BY date
ORDER BY (date, name)
INSERT INTO sme_table VALUES ('2020-01-01','a',1,2)('2020-01-01','b',2,1)('2020-01-02','a',3,4)('2020-01-03','c',10,22)('2020-01-04','d',11,20)('2020-01-05','e',11,2)

注意:MergeTree的合并并不能保证绝对合并完成,有可能没有合并,有可能去重时没有去处干净,累加时没有累加干净。正常。
Distributed
分布式引擎,上面所有的操作虽然说是在ClickHouse集群中进行的,但是实际上是在ch1中单独操作的,与ch2,ch3无关。
使用分布式引擎声明的表才可以在其他节点访问与操作。
Distributed引擎和Merge引擎类似,本身不存放数据。
语法:
Distributed(cluster name,database,table [, sharding_key])
cluster name 集群的名称,在/etc/metrika.xml中clickhouse_remote_servers标签下的第一个标签就是集群的名称
database 数据库名称
table 表明
sharding_key 分区

在三台机器上分别创建一个表d:
create table d(id UInt16,name String) engine=TinyLog
都插入两条数据:
insert into d values(1,'zs')(2,'ls')
然后创建一个分布式表
CREATE TABLE dis_table
(
`id` UInt16,
`name` String
)
ENGINE = Distributed(perftest_3shards_1replicas, default, d,id)
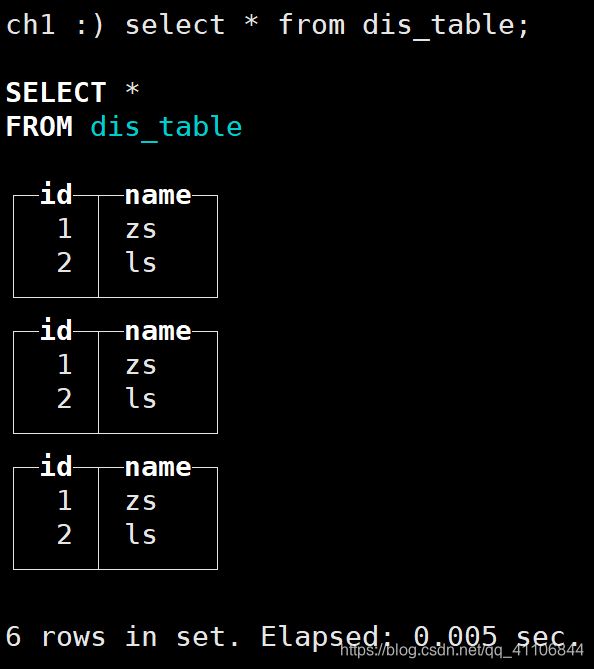
然后插入一条记录:
insert into dis_table values (3,'ww');

再插入一条:
insert into dis_table values (4,'nl') ;

插入的数据会分配到不同的节点上。