data science 相关问题(part 2)
1. What are important functions used in Data Science?
Within the realm of data science, various pivotal functions assume critical roles across diverse tasks. Among these, two foundational functions are the cost function and the loss function.
Cost function: Also referred to as the objective function, the cost function holds substantial utility within machine learning algorithms, especially in optimization scenarios. Its purpose is to quantify the disparity between predicted values and actual values. Minimizing the cost function entails optimizing the model’s parameters or coefficients, aiming to achieve an optimal solution.
Loss function: Loss functions possess significant significance in supervised learning endeavors. They evaluate the discrepancy or error between predicted values and actual labels. The selection of a specific loss function depends on the problem at hand, such as employing mean squared error (MSE) for regression tasks or cross-entropy loss for classification tasks. The loss function guides the model’s optimization process during training, ultimately bolstering accuracy and overall performance.
Loss Function 是定义在单个样本上的,算的是一个样本的误差。
Cost Function 是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。
2. There exist various types of Neural Networks, including:
- Feedforward Neural Networks: These networks facilitate a unidirectional information flow, progressing from input to output. They find frequent application in tasks involving pattern recognition and classification.
- Convolutional Neural Networks (CNNs): Specifically tailored for grid-like data, such as images or videos, CNNs leverage convolutional layers to extract meaningful features. Their prowess lies in tasks like image classification and object detection.
- Recurrent Neural Networks (RNNs): RNNs are particularly adept at handling sequential data, wherein the present output is influenced by past inputs. They are extensively utilized in domains such as language modeling and time series analysis.
- Long Short-Term Memory (LSTM) Networks: This variation of RNNs addresses the issue of vanishing gradients and excels at capturing long-term dependencies in data. LSTM networks find wide-ranging applications in areas like speech recognition and natural language processing.
- Generative Adversarial Networks (GANs): GANs consist of a generator and a discriminator that is trained in a competitive manner. They are employed to generate new data samples and are helpful for tasks like image generation and text synthesis.
3. What is the ROC curve?
It stands for Receiver Operating Characteristic. It is basically a plot between a true positive rate and a false positive rate, and it helps us to find out the right tradeoff between the true positive rate and the false positive rate for different probability thresholds of the predicted values. So, the closer the curve to the upper left corner, the better the model is. In other words, whichever curve has greater area under it that would be the better model. You can see this in the below graph:
4.What is the F1 score and how to calculate it?
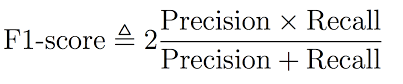
F1 score helps us calculate the harmonic mean of precision and recall that gives us the test’s accuracy. If F1 = 1, then precision and recall are accurate. If F1 < 1 or equal to 0, then precision or recall is less accurate, or they are completely inaccurate. See below for the formula to calculate the F1 score:
5. What is a p-value?
P-value is the measure of the statistical importance of an observation. It is the probability that shows the significance of output to the data. We compute the p-value to know the test statistics of a model. Typically, it helps us choose whether we can accept or reject the null hypothesis.
6. What is the difference between an error and a residual error?
An error occurs in values while the prediction gives us the difference between the observed values and the true values of a dataset. Whereas, the residual error is the difference between the observed values and the predicted values. The reason we use the residual error to evaluate the performance of an algorithm is that the true values are never known. Hence, we use the observed values to measure the error using residuals. It helps us get an accurate estimate of the error.
7. How can we deal with outliers?
Outliers can be dealt with in several ways. One way is to drop them. We can only drop the outliers if they have values that are incorrect or extreme. For example, if a dataset with the weights of babies has a value 98.6-degree Fahrenheit, then it is incorrect. Now, if the value is 187 kg, then it is an extreme value, which is not useful for our model.
In case the outliers are not that extreme, then we can try:
- A different kind of model. For example, if we were using a linear model, then we can choose a non-linear model
- Normalizing the data, which will shift the extreme values closer to other data points
- Using algorithms that are not so affected by outliers, such as random forest, etc.
8. recommander system
Collaborative filtering methods
Collaborative methods for recommender systems are methods that are based solely on the past interactions recorded between users and items in order to produce new recommendations. These interactions are stored in the so-called “user-item interactions matrix”.
Then, the main idea that rules collaborative methods is that these past user-item interactions are sufficient to detect similar users and/or similar items and make predictions based on these estimated proximities.
Content based methods
Unlike collaborative methods that only rely on the user-item interactions, content based approaches use additional information about users and/or items. If we consider the example of a movies recommender system, this additional information can be, for example, the age, the sex, the job or any other personal information for users as well as the category, the main actors, the duration or other characteristics for the movies (items).
Then, the idea of content based methods is to try to build a model, based on the available “features”, that explain the observed user-item interactions. Still considering users and movies, we will try, for example, to model the fact that young women tend to rate better some movies, that young men tend to rate better some other movies and so on.
9.
这篇文章主要讲解集成学习三种方法。集成学习(Emsemble Learning)是通过结合几个模型的元算法(meta-algorithm),使得最后的表现比任何一个模型好。在Kaggle,集成学习是取得高排名的不二法宝。本文介绍集成学习的三种模式,以便帮助读者对自己的最后模型进行决策。这三种方法以及他们的效果分别是:
- Bagging:减少 variance
- boosting: 减少 bias
- stacking:增强预测效果
10. What is batch normalization?
One method for attempting to enhance the functionality and stability of the neural network is batch normalization. To do this, normalize the inputs in each layer such that the mean output activation stays at 0 and the standard deviation is set to 1.
11. What do you understand from cluster sampling and systematic sampling?
Cluster sampling is also known as the probability sampling approach where you can divide a population into groups, such as districts or schools, and then select a representative sample from among these groups at random. A modest representation of the population as a whole should be present in each cluster.
A probability sampling strategy called systematic sampling involves picking people from the population at regular intervals, such as every 15th person on a population list. The population can be organized randomly to mimic the benefits of simple random sampling.
12. What is the Computational Graph?
A directed graph with variables or operations as nodes is a computational graph. Variables can contribute to operations with their value, and operations can contribute their output to other operations. In this manner, each node in the graph establishes a function of the variables.
13. Batch gradient descent takes longer to converge since it computes the gradient using the entire training dataset in each iteration. Stochastic gradient descent, on the other hand, can converge faster since it updates the model parameters after processing each example, which can lead to faster convergence.
14.How Do You Build a random forest model?
The steps for creating a random forest model are as follows:
- Choose n from a dataset of k records.
- Create distinct decision trees for each of the n data values being taken into account. From each of them, a projected result is obtained.
- Each of the findings is subjected to a voting mechanism.
- The final outcome is determined by whose prediction received the most support.
15. What is variance in Data Science?
Variance is a type of error that occurs in a Data Science model when the model ends up being too complex and learns features from data, along with the noise that exists in it. This kind of error can occur if the algorithm used to train the model has high complexity, even though the data and the underlying patterns and trends are quite easy to discover. This makes the model a very sensitive one that performs well on the training dataset but poorly on the testing dataset, and on any kind of data that the model has not yet seen. Variance generally leads to poor accuracy in testing and results in overfitting.
16.What information is gained in a decision tree algorithm?
When building a decision tree, at each step, we have to create a node that decides which feature we should use to split data, i.e., which feature would best separate our data so that we can make predictions. This decision is made using information gain, which is a measure of how much entropy is reduced when a particular feature is used to split the data. The feature that gives the highest information gain is the one that is chosen to split the data.
Let’s consider a practical example to gain a better understanding of how information gain operates within a decision tree algorithm. Imagine we have a dataset containing customer information such as age, income, and purchase history. Our objective is to predict whether a customer will make a purchase or not.
To determine which attribute provides the most valuable information, we calculate the information gain for each attribute. If splitting the data based on income leads to subsets with significantly reduced entropy, it indicates that income plays a crucial role in predicting purchase behavior. Consequently, income becomes a crucial factor in constructing the decision tree as it offers valuable insights.
17.What is reinforcement learning?
Reinforcement learning is a kind of Machine Learning, which is concerned with building software agents that perform actions to attain the most cumulative rewards.
A reward here is used for letting the model know (during training) if a particular action leads to the attainment of or brings it closer to the goal. For example, if we are creating an ML model that plays a video game, the reward is going to be either the points collected during the play or the level reached in it.
Reinforcement learning is used to build these kinds of agents that can make real-world decisions that should move the model toward the attainment of a clearly defined goal.
18.. What is a Transformer in Machine Learning?
Within the realm of machine learning, the term “Transformer” denotes a neural network architecture that has garnered significant acclaim, primarily in the domain of natural language processing (NLP) tasks. Its introduction occurred in the seminal research paper titled “Attention Is All You Need,” authored by Vaswani et al. in 2017. Since then, the Transformer has emerged as a fundamental framework in numerous applications within the NLP domain.
The Transformer architecture is purposefully designed to overcome the limitations encountered by conventional recurrent neural networks (RNNs) when confronted with sequential data, such as sentences or documents. Unlike RNNs, Transformers do not rely on sequential processing and possess the ability to parallelize computations, thereby facilitating enhanced efficiency and scalability.