GDC2023 Photon Water System Reading Note
It is an reading note of Photon Water System in GDC2023, related about usage of flow map baking, shallow water equation solving for water surface propagation.
The article can’t cover all details, it just a reading note. Implementation details are so complex that it is recommended to have a look on original source.
GDCVault Photon Water System
Outline
Water System:
-
Procedural tools for river, lake, and ocean
-
Offline flow map baking
-
Runtime fluid simulation
-
Buoyancy and boat physics
-
Underwater volumetric lighting
-
Adaptive water mesh tessellation
Fluid simulation
Offline Flow map baking
Flowmap is pre-computed texture using physical-based simulation tool in existing third party software, such as Houdini.
Details about usage see:
Water Flow in Portal 2
The velocity field is stored as a 2d vector map and fetch at runtime.
However, the existing tool is still inconvenience for artists to use and cannot support turbulent flow.
LightSpeed use lattice Boltzmann method for the solution of shallow water equations (LBMSWE) to bake the flow map. The method has severval advantages:
-
Support turbulence flow
-
Simple to implement
-
Highly parallelizable
-
Conservative
Details about LBM see other tutorial.
Solving
The basic LBMSWE algorithm has four steps:
-
Update the equilibrium distribution f α e q f_{\alpha}^{eq} fαeq
-
Streaming and collision
-
Boundary handling
-
Compute macroscopic variables
In fact, after reading, I just review the theroy of LBM but have no idea about baking.
Summarize
To summarize, LBMSWE:
Pros:
-
Support turbulence flow turbulent flow
-
Simple to implement
-
Highly parallelizable
-
Conservative
Cons:
-
Large memory usage
Each cell needs to store 3 distribution values for nine directions
-
Not good for real-time waterfront propagation
Runtime fluid simulation
LightSpeed uses Shallow Water Equation (SWE) to implement height-field based 2.5D fluid simulation.
To solve classic NS equation based on the shallow water assumption:
D h D t + h ∇ ⋅ u = 0 D u D t = − g ∇ ( h + H ) \begin{aligned} & \dfrac{Dh}{Dt}+h\nabla \cdot u = 0 \\ & \dfrac{Du}{Dt} = -g \nabla (h+H) \end{aligned} DtDh+h∇⋅u=0DtDu=−g∇(h+H)
 Fig: Height Field
Fig: Height Field
They split world into grid. Water depth h h h are stored at cell centers, velocities are stored at edge centers.
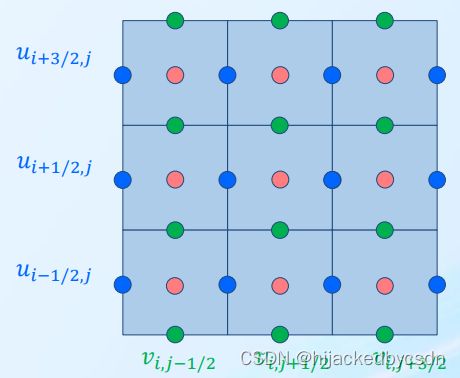 Fig: SWE Grid
Fig: SWE Grid
Solving
The solving is split into 3 steps:
-
Height integration ∂ h ∂ t = − h ∇ ⋅ u \frac{\partial{h}}{\partial{t}} = -h\nabla \cdot u ∂t∂h=−h∇⋅u
-
Velocity advection ∂ u ∂ t = − u ⋅ ∇ u \frac{\partial{u}}{\partial{t}} = -u \cdot \nabla u ∂t∂u=−u⋅∇u
-
Apply water pressure ∂ u ∂ t = − g ∇ ( h + H ) \frac{\partial{u}}{\partial{t}} = -g \nabla (h+H) ∂t∂u=−g∇(h+H)
step 1 and step 3 are using discrete format of first order differential.
step 2 uses classic idea of Semi-Lagrangian Method, which see center of grid as particle, backtrace this particle position p l a s t p_{last} plast at last time, sample at p l a s t p_{last} plast and set it as field value at next time.
The way to get p l a s t p_{last} plast is simply regarding velocity doesn’t change over time, so p l a s t = p c u r r − v c u r r Δ t p_{last} = p_{curr} - v_{curr} \Delta t plast=pcurr−vcurrΔt
To summarize: A n e w ( p c u r r ) = A c u r r ( p l a s t ) A_{new}(p_{curr}) = A_{curr}(p_{last}) Anew(pcurr)=Acurr(plast)
It is just my personal conclusion, you can see famous paper Stable Fluid to get more details.
Stable Fluid
And the paper author also gave details about implementation of Stable Fluid:
Real-Time Fluid Dynamics for Games
SWE + Particles System
Problem: SWE does not support discontinuous terrain, such as waterfall
Solution: additional particle system, in which each particle carries water
mass and velocity
Steps:
1. Create particles
Go over all edges to determine whether and how many water particles
needs to be created.
-
Determine whether should create waterfall edge based on the difference between neighboring terrain heights and water levels
-
Determine the particle number
Flux Φ = u i + 1 / 2 , j ∗ Δ t ∗ Δ x ∗ h \Phi = u_{i+1/2, j}*\Delta t * \Delta x * h Φ=ui+1/2,j∗Δt∗Δx∗h
Spawn particle number = total flux / particle volume
-
Determine the particle locations
Randomly place within the cell
-
Use atomic to write into the particle buffer
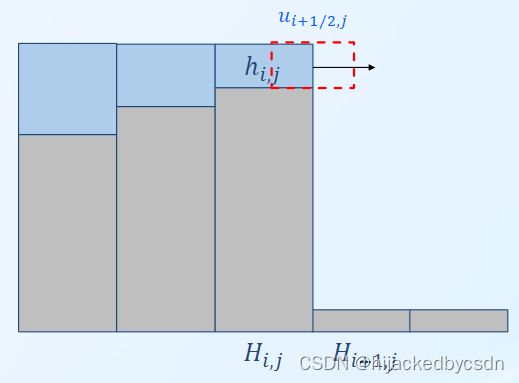 Fig: Water Particles Creation
Fig: Water Particles Creation
2. Advance particles
Apply gravity
 Fig: Apply gravity
Fig: Apply gravity
3. Delete particles
Go over each particle. If it hits the water surface or terrain, its water mass and velocity need to be written back to SWE
 Fig: Delete Particles and Move their Mass and Velocity to Grid
Fig: Delete Particles and Move their Mass and Velocity to Grid
The update formula is:
u i + 1 / 2. j = u i + 1 / 2 , j h i , j Δ x 2 + ∑ u p V p h i , j Δ x 2 + ∑ V p u_{i+1/2. j} = \dfrac{u_{i+1/2,j}h_{i,j}\Delta x^2 + \sum u_p V_p}{h_{i,j} \Delta x^2 + \sum V_p} ui+1/2.j=hi,jΔx2+∑Vpui+1/2,jhi,jΔx2+∑upVp
Where u i + 1 / 2 , j h i , j Δ x 2 u_{i+1/2,j}h_{i,j}\Delta x^2 ui+1/2,jhi,jΔx2 is original momentum of grid, ∑ u p V p \sum u_p V_p ∑upVp is momentum of particles deleted, h i , j Δ x 2 h_{i,j} \Delta x^2 hi,jΔx2 is original mass of grid, ∑ V p \sum V_p ∑Vp is mass of particles. Here volume shoule represents mass.
So new velocity = total momentum / total mass.
However, velocity and height are stored at different location, so we have to accumulate ∑ u p V p \sum u_p V_p ∑upVp, ∑ w p V p \sum w_p V_p ∑wpVp, ∑ V p \sum V_p ∑Vp for u, w, and h using atomic respectively.
 Fig: Horizontal Velocity u, Vertical Velocity w, Water Height h are Stored at different position of Grid
Fig: Horizontal Velocity u, Vertical Velocity w, Water Height h are Stored at different position of Grid
Use less texture storing physical values
I think he means he need five textures to store ∑ u p V p \sum u_p V_p ∑upVp, ∑ w p V p \sum w_p V_p ∑wpVp, ∑ V p \sum V_p ∑Vp, u u u, w w w, regardless of h h h. But if you couple u u u, w w w into h h h, now you only considering ∑ u p V p \sum u_p V_p ∑upVp, ∑ w p V p \sum w_p V_p ∑wpVp, ∑ V p \sum V_p ∑Vp, then you only need three textures.
Conclusion
-
Compute boundary conditions
-
Create particles
-
Integrate height
-
Advect velocity and apply pressure
-
Advance and delete particles
-
Update height and velocity
-
Copy and compact particles
-
Goto 1
 Fig: Input and output of each step
Fig: Input and output of each step
To save the memory usage, use one persistent buffer and one temporary buffer to replace the double buffer. So, each frame the temporary buffer can be obtained from the texture pool.
Optimization
1. Use one persistent and one temporary to replace double buffers to save memory
2. Use f16 and uint16 instead of f32
-
N+1 x N+1 texture buffers x 4, including
-
PF_R16G16_FLOAT x 1 – velocity u & v
-
PF_G16_FLOAT x 1 – water depth h
-
PF_G16_UINT x 1 – boundary condition
-
PF_G16_FLOAT x 1 – terrain height H
-
-
3 x 65536 texture buffers x 2, including
-
PF_R16G16B16_FLOAT x 1 – particle position
-
PF_R16G16B16_FLOAT x 1 – particle velocity
-
PF_G16_FLOAT x 1 – particle lifetime
-
Here I can’t understand where ∑ u p V p \sum u_p V_p ∑upVp, ∑ w p V p \sum w_p V_p ∑wpVp, ∑ V p \sum V_p ∑Vp is? I thought they are temporary variables from the beginning, but before he says that he would reduce the five textures to three. He seems to mean that these variables were stored in textures. And now when he conclude the textures he uses, there are not textures for ∑ u p V p \sum u_p V_p ∑upVp, ∑ w p V p \sum w_p V_p ∑wpVp, ∑ V p \sum V_p ∑Vp, weird.
3. Merge passes to reduce data read & write
Velocity advection pass
-
V i , j t = ( u , v ) V_{i,j}^{t} = (u,v) Vi,jt=(u,v)
-
x i , j n e w = x i , j − Δ t V i , j t x_{i,j}^{new} = x_{i,j} - \Delta t V_{i,j}^t xi,jnew=xi,j−ΔtVi,jt
-
u i , j t + 1 = u t ( x i , j n e w ) u_{i,j}^{t+1} = u_{t}(x_{i,j}^{new}) ui,jt+1=ut(xi,jnew)
Applying water pressure pass
u i + 1 / 2 , j − = g Δ t Δ x ( h i + 1 , j + H i + 1 , h − h i , j − H i , j ) u_{i+1/2, j} -= g\dfrac{\Delta t}{\Delta x}(h_{i+1,j}+H_{i+1,h}-h_{i,j}-H_{i,j}) ui+1/2,j−=gΔxΔt(hi+1,j+Hi+1,h−hi,j−Hi,j)
Merge them as one pass
4. Use shared memory
Considering Height integration:
h i , j + = − h Δ t Δ x ( ( h ˉ u ) i + 1 / 2 , j − ( h ˉ u ) i − 1 / 2 , j + ( h ˉ w ) i , j + 1 / 2 − ( h ˉ w ) i , j − 1 / 2 ) h_{i,j} += -h\dfrac{\Delta t}{\Delta x}((\bar{h}u)_{i+1/2,j}-(\bar{h}u)_{i-1/2,j}+(\bar{h}w)_{i,j+1/2}-(\bar{h}w)_{i,j-1/2}) hi,j+=−hΔxΔt((hˉu)i+1/2,j−(hˉu)i−1/2,j+(hˉw)i,j+1/2−(hˉw)i,j−1/2)
For example, ( h ˉ u ) i + 1 / 2 , j (\bar{h}u)_{i+1/2,j} (hˉu)i+1/2,j is shared by two h i , j h_{i,j} hi,j
Using working group to fetch neighboring data together, before the computing
 Fig: Input and output of each step
Fig: Input and output of each step
It is about compute shader
5. Infrequency particles compact
Compact active particles every five iterations
Ideally, we should compact the particle list every frame to save the memory. However, compacting particle is a very expensive operation. So, we compact active particles every five iterations
6. Indirect dispatch
To avoid waster threads on inactive particles, we keep tracking the Track the active particle number particles, and launch shader with same number of threads as active particles have using unreal indirect dispatch feature(FRDGBufferRef IndirectArgsBuffer).
7. Early exit
-
Skip the cell without water
-
Skip inactive particles
8. Use intrinsic operation, such as MAD
9. Reduce peak register usage
Profile the shader code to locate when is peak register usage and reduce the usage to increase number of warps launched
10. Profile and profile again, such as Renderdoc, stat GPU in UE, profiler in UE, Nsight
Conclusion
| SWE | LBMSWE | |
|---|---|---|
| Pros | 1. Easy to parallelize 2. Very fast 3. Handle dynamic terrain editing 4. Suitable for real-time applications |
1. Support turbulence flow turbulent flow 2. Simple to implement 3. Highly parallelizable 4. Conservative |
| Cons | 1. Lack of details 2. Does not support turbulent flow |
1. Large memory usage 2. Not good for real-time waterfront propagation |
Combine the real-time SWE and offline LBMSWE?
Grid-based foam simulation
-
Foam propagation
Quite similar with Stable Fluid.
The advent value is foam value.
-
Rendering
Use velocity field as flowmap to drive foam texture and foam value determines the foam texture transparency.
Open world water rendering
Rendering pipeline
Data Creation
Before dive into the rendering, just a quick introduction about the production pipeline, without data we can not run any simulation or rendering.
-
Artists can use spline tools to create rivers and lakes, or generate water procedurally using external tools like Houdini.
-
Alternatively, they can assign the water material to any mesh.
-
At the end. all the water meshes will be baked into height maps.
-
For ocean, we just need to set the ocean level, and some exclusion zone to avoid some area get flooded.
Once the desired water sources have been added, the fluid simulation can be initiated with the click of a button.
The simulation results are saved as water height, flow maps, material id maps, and distance field will also be generated for rendering.
This process can be repeated until get a good result
Decouple Rendering
Water Rendering decoupled into 2 parts:
-
Pre-pass
-
Depth pre-pass
-
Screen space displacement, normal, foam
-
-
Lighting Pass
Single Layer Water Material
Pre-pass
Depth pre-pass
A depth-only pre-pass is first rendered with the water quadtree and height map.
It uses a simplified VS to render a flat water surface.
The pre-pass is rendered with a wider FOV to avoid the gap on the screen border after displacement is applied.
After the depth pre-pass, we can un-project the depth to get world position for the following passes.
Screen space FBM wave
We use FBM wave to simulate the detailed waves
FBM stands for Fractional Brownian Motion, which is a random motion wave computed by multiple iterations
the wave can be tweaked by amplitude, frequency, and speed to represent calm lake or rapid water
We store the FBM wave parameter in the water material data buffer
We can use the world position to get the material id from the material id map, then use it to index from the material data buffer to get the material properties
Flow map is used to control the global movement of the fbm waves
Displacement particle
We added a new material type in the Unreal Niagara particle system.
It will render particles to a specified displacement buffer instead of a color buffer.
This buffer will be combined with FBM displacement as the final displacement.
Normal is generated from the final displacement buffer.
Foam
Foam is also de-coupled and rendered to a separate buffer.
The pre-pass buffer size does not need to be a one-to-one match with the GBuffer size.
This is the biggest reason we chose to de-couple the wave computation from the lighting pass. We can selectively use a smaller buffer size for the low-end platform.
 Fig: Pre-pass
Fig: Pre-pass
Single Layer Water
A custom vertex factory is created for the CDLOD mesh tessellation, we applied height map and the displacement on it
The material shader will sample from the screen space normal and foam, with FOV corrected of course
As we use the single layer water, we can easily get benefit from the Lumen lighting and reflection.
We also support the lightspeed studio internal tech Surfel GI which provided a similar real-time GI as Lumen but at a lower cost.
Fig: Single Layer WaterCreating a Custom Mesh Component in UE4 | Part 1: An In-depth Explanation of Vertex Factories
Water Mesh Tessellation
CDLOD is one of the popular methods used for rendering height maps.
It pre-generated multiple LODs of the mesh patch and organized the meshes in a quadtree.
At runtime, it selects the LOD based on the distance to the camera, so the high-density mesh is used close to the camera and lower LOD is used in distance.
Morph
-
No stitching between LODs
-
Just uses a 0 to 1 morph value to morph between LOD levels.
-
The cost of the vertex shader is just like regular mesh rendering plus height map sampling
CDLOD limit
Compare to the stitching method used in farcy 5 terrain, CDLOD is simpler but has its limit.
With CDLOD, the connected LODs can only have one level difference, while the stitching method allows more than 2 levels of difference, so the LOD level can drop faster.
With CDLOD, it may get unnecessary high mesh density at a very far distance which we will address later.
CDLOD Terrain | svnte.se
GDC Vault - Terrain Rendering in ‘Far Cry 5’
 Fig: CDLOD
Fig: CDLOD
CDLOD Mesh Clip
Unlike terrain height map rendering, a water height map only covers a part of the land and needs to be clipped at the shoreline.
We use a bilinear filter to sample the water height map to get smooth results on the slope, but it will be wrong on the edge when filtered with an invalid height value, in our case is 0.
We use a gather4 to do a manual filter which excludes the 0 value pixels. If the height value is 0, we use the divide-by-zero trick to create a nan on the vertex position, the whole triangle will be clipped. It is an undocumented feature but works surprisingly well and it works everywhere, even on the mobile platform.
The water mesh needs to be expanded so it will not leave a gap near the shore in low LOD.
float4 Height4 = HeightMapVT.GatherRed(Sampler, UV);
// count pixels with value 0
float4 ZeroPixelMask = step(Height4, 0);
float ZeroPixelCount = dot(ZeroPixelMask, 1);
if (ZeroPixelCount < 4)
{
ManualBilinearSampleHeight
}
else
{
// Use Nan to clip non-water triangles
OutputPos /= 0;
}
CDLOD Quadtree Traversal
Quadtree traversal is done in GPU
We traverse the quadtree in one compute shader dispatch.
It uses a loop method to traverse one level per iteration,
-
In each iteration, it compute the visible nodes and store into the group shared memory buffer for the next iteration,
-
After all the quadtree level is visited, the group shared memory will be copied to the output node buffer, the indirect draw argument will be updated as well.
//assuming no more than 256 nodes per level
groupshared uint g_nodeBuffer[2][16*16];
void BuildVisibleNodesList(uint3 ThreadIdx)
{
InitFirstLevel();
GroupMemoryBarrierWithGroupSync();
VisitOneLevel(dispatchThreadId);
GroupMemoryBarrierWithGroupSync();
for (uint i = 0; i < (MaxQTLevel - 1); i++)
{
PrepareNextLevel(ThreadIdx);
GroupMemoryBarrierWithGroupSync();
VisitOneLevel(ThreadIdx);
GroupMemoryBarrierWithGroupSync();
}
if (ThreadIdx.x == 0 && ThreadIdx.y == 0)
{
StoreNodes();
}
}
Per level Node Limit
-
This compute-shader has a group size of 16x16 with only one group
-
Each thread can access all the group shared memory
-
But there is a hardware limit of group memory size per thread, which becomes the limit of the max node count that can be written into the buffer, per level.
-
In our test with 12k x 12k world, the visible node buffer never runs out
-
We added a fallback solution that once the node buffer is overflowed, the system will use CPU traversal in the next frame
Water Virtual Texture
To support a large open world, we can not store the height map or flow map textures in one large texture,
Tile Texture
We cut all the textures into 128x128 tile textures. Actually, store them as 130x130 textures with added one-pixel border, so the bilinear filter on the border of the tile texture not will go across the tile border.
The resolution of the texture is one pixel per square meter at the highest LOD. Lower LOD texture is also exported in 128x128 textures but covers the bigger area, like LOD1 texture will cover 4 squared meters per pixel
Tiles without water will be skipped
Flat water tile, if all the pixel in the tile has the same height, only a height
value will be stored.
Runtime
The tile textures will be selected based on the distance to the camera, then they are composed into the virtual texture pool
The texture pool size can be scaled from 1k to 8k depending on the project requirement
Virtual Address Table
Since the actual tile texture is 130x130 which is not the power of 2, there is empty space in the pool texture on the right and the bottom part. We use this space to store the virtual address table which maps world space position to VT Pool texture UV
Tile allocator
We implement a very fast and simple tile allocator.
It assumes there are up to 64x64 tiles. We use a 64x 64bits bit array to store if a tile is used or not.
And another uint64 is used to store the row bits.
The bit array is initialized as all 1, which means free. The allocation always happens on the least significant non-zero bit.
We can use 2 intrinsics like _BitScanForward64 to get the address quickly, then mark the bit as 0(occupied) and return the address.
Each allocation will only allocate one tile.
By this way, we can guarantee all the allocations can find the first available tile.
To Free the tile, just mark the bit to 1.
Runtime simulation pipeline
To make the runtime simulation work, we need to first capture the height map for the simulation, then output the simulation results to the rendering engine.
Height Map Capture
We wrote a custom height map capture shader instead of using the unreal scene capture which is very expensive.
A top-down view rendering pass is used to render the water and terrain.
Then render all the static meshes that intersecting water to cut holes on water, a regular top-down view rendering will not work for the case that water goes under bridge or cave, it will be occluded completely.
We do a software depth clip to discard all the pixels above the water and render the scene mesh’s back face to get the precise cut.
A second pass is rendered for the below water part of the object.
Static scene will only be rendered once, movable objects will be rendered every frame
The runtime quadtree is duplicated from the baked quadtree but with all the nodes inside simulation domain removed.
We do a pixel counting on the height map to get the valid quadtree nodes, and update the quadtree dynamically, in GPU.
The height map and flow map are exported into the virtual texture pool directly.
We pre-allocate VT tiles for the whole simulation domain to make things easier as VT allocator runs on CPU.
And use a secondary page table, so we can change back to the baked water at any time and blend the runtime and the baked water at the border.
The quadtree update, VT table update, VT texture write out are all done in one compute shader pass with group shared memory optimization.
The Height Map and flow map are copied to staging texture for readback in the next frame, in tile mode, empty tiles will be skipped.
Surface wave
Take out all the time-consuming parts from the SWE, and only solve the pressure function to create an interactive wave
The wave simulation will only create a height map to displace the existing water surface visually, it will not change water height or flow map
h t = D a m p i n g ∗ ( h t − 1 + β ( h t − 1 − h t − 2 ) + α ( h N t − 1 − 4 h t − 1 ) ) h^t = Damping * (h^{t-1} + \beta (h^{t-1} - h^{t-2}) + \alpha (h^{t-1}_{N} - 4 h^{t-1})) ht=Damping∗(ht−1+β(ht−1−ht−2)+α(hNt−1−4ht−1))
Where β \beta β is viscosity contant, α \alpha α is SWE constant, h N t − 1 h^{t-1}_{N} hNt−1 is height sum of the nearest 4 points, t t t is the iteration number.
The original implement will do multiple iterations in one frame to get a stable
result. But to get better performance, we only perform one cycle per frame to minimize computational cost and employ an additional damping factor for quick fading and to prevent explosion.
Boundary Conditions
// Object boundary condition
float WaterHeight = WaterPrevHeight.Load(uint3(Index, 0)).x;
return IsBoundary(WaterHeight) ? BoundaryWaterHeight : WaterHeight;
Infinite Simulation Domain
#if LOCAL_SIMULATION
uint2 SimulationIndex = ThreadId.xy;
#else
// Get the simulation texel pos from a tiling pattern
uint2 SimulationIndex = (ThreadId.xy + PlayerOffset) % SimDomainSize;
#endif
The boundary is easy to handle in surface wave simulation. The surface wave simulation use neumann boundary conditions to make waves bounce back. A neumann boundary condition specifies the values of the derivative applied at the boundary of the domain, which mean there should be no water exchange though the boundaries. When computing h N t − 1 h^{t-1}_{N} hNt−1 , if the pixel is outside the boundary, make its value to h t − 1 h^{t-1} ht−1 to negate the water exchange.
We support two types of simulation domain. One is a fixed simulation domain, another is the tiling simulation domain that always attached to the player. We just need to map the player’s position to the UV in the simulation texture in a tiling pattern.
Buffer Usage
Three R16F textures for holding t-1, t-2 and current frame water height.
Two R8 texture for dynamic object and boundary information
1024x1024 texture for 80x80 meters simulation domain, tweakable
Rendered into screen space displacement buffer
Tessellation
More Tessellation Methods:
-
Screen space tessellation
-
Adaptive subdivision
Height Map Water Limitation
One layer Water can’t render water over water
Solution is Screen space tessellation for small pieces of water
 Fig: Single Layer Water Problem
Fig: Single Layer Water Problem
Branislav Grujic & Cristian Cutocheras. “Water Rendering in Far Cry 5”, GDC 2018
Screen Space Tessellation
The pipeline looks similar to the water quadtree rendering in the pre-pass
Click to show new pipeline:
-
Instead of using quadtree, we render the coarse water mesh into the pre-pass.
-
In the lighting pass, full-screen grids are rendered instead of CDLOD quadtree mesh.
-
The rest part remains the same.
The screen space grids contain many pixel-size quads. Each quad is as big as 4 pixels.
In the vertex shader, each vertex will sample the depth from pre-pass to get the world position and sample the screen space displacement buffer to get the final position.
The pixel shader remains the same.
One thing to be noted. As both coarse mesh and quadtree mesh are rendered into the same pre-pass depth, we need an extra bit to mark each pixel if they are used for screen space or not, the final screen space grids will only pick up the pixel with a right mask.
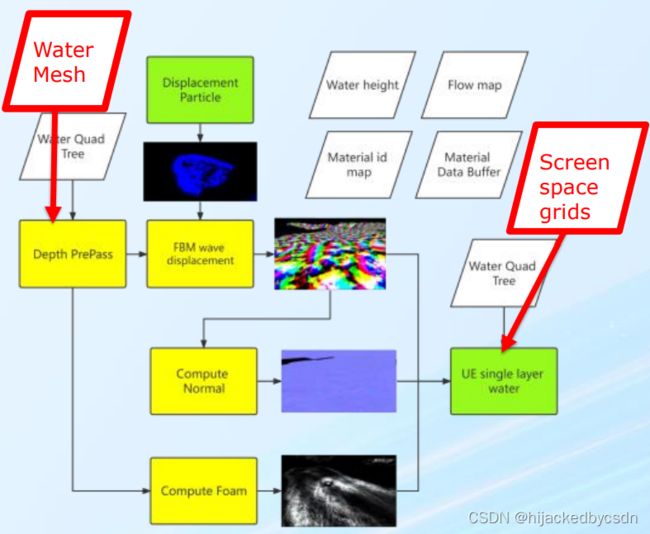 Fig: Screen Space Tessellation
Fig: Screen Space Tessellation
Instance draw without vertex buffer
We render the grids with instance draw without a vertex buffer
Each draw contains a row of the grids. The instance count will be the grids height.
float GridX = VertexId / 2 + ((VertexId & 0x2) >> 1);
float GridY = InstanceId + (VertexId & 0x1);
float3 WorldPos;
float IsValidPos = GetWorldPos(GridX, GridY, WaterPrePassDepth, WorldPos);
WorldPos /= IsValidPos;
This is the mesh view from rendering doc capture, each grid looks like a pixel.
 Fig: Grid View
Fig: Grid View
In VS, we use the same divide-by-zero trick to remove non-water pixels.
A tile categorization pass will be dispatched to filter out tiles containing no water.
We could also use SV_PrimitveID here, but it is not supported on all platforms, especially mobile.
Ocean mesh tessellation
We use FFT waves for ocean. This tech is covered by many previous papers and game talks, we will focus on the tessellation method this time.
Ocean is basically a very big mesh that extends to the horizon with big waves.
CDLOD is not suitable for rendering a super large water body, the quadtree nodes count will be huge, and the mesh density is still high in the distance.
Screen space tessellation looks perfect when looking from the top, but when we apply the displacement from big ocean waves in screen space, and the camera is close to the ocean surface, it scrambled the vertices and connected them in the wrong order. Some pixels in the middle distance are connected with pixels in the far distance and form stretched triangles.
Adaptive Subdivision on GPU
Khoury, Jad, Jonathan Dupuy, and Christophe Riccio. “Adaptive GPU Tessellation with Compute Shaders.” GPU Zen: Advanced Rendering Techniques 2 (2019): 3-17.
The algorithm is based on a binary triangle subdivision rule
Subdivision Key
The rule splits a triangle into two sub-triangles 0 and 1, each sub-triangle has its own barycentric space transformation matrices (M0 and M1) that can be used to compute its vertex position from the parent triangle.
Any sub-triangle can be represented via concatenations of binary words, which we call a key.
We retrieve the subdivision matrix for each key through successive matrix multiplications with the same sequence as the binary key concatenates.
For example, the transformation matrix for key 0100 denotes as M0100, it can be concatenated as M0100 = M0 * M1 *M0 * M0.
Subdivision Level
Natively, the length of the key represents the subdivision level that a triangle is applied. For example, key 0101 means the triangle is subdivided 4 times from the original triangle.
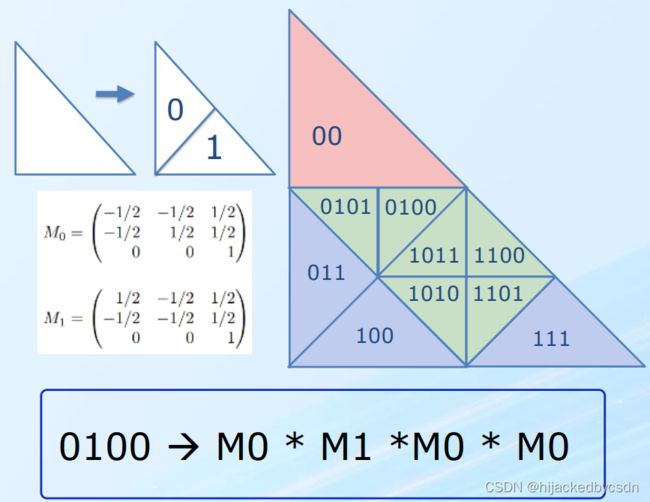 Fig: Adaptive Subdivision
Fig: Adaptive Subdivision
Performance issue
It looks like a performance issue that a triangle with 10 subd level will do 10 matrix concatenation, but in reality, it is not that slow as the highly detailed mesh only exist in a small range close to the camera.
We have also tried pre-cache the matrix for each key, it doesn’t improve the performance but only used more memory.
Merge, Subdivide, Keep
The subdivision starts from a coarse mesh which represents the entire ocean plane.
For each frame, we process each key in the working buffer based on its distance to the camera to compute its target subdivision level.
There are 3 cases:
1. Merge
If the target subdivision level is smaller than the current subdivision level, we will abandon this triangle but write the key to its parent triangle to the output buffer.
The key of the parent triangle can be simply gotten by removing the right most bit.
For example, key 0101 has parent key 010
During the merge, only the keys ending with 0 will output its parent key, keys ending with 1 will be removed.
So only one parent key is outputted from the 2 children after the merge
2. Subdivide
If the target level is bigger then current level, we will need to subdivide current triangle and output 2 sub-triangles to the output buffer
It can be done by simply appending 0 and 1 on current key.
For example, key 00 can be split into 000 and 001.
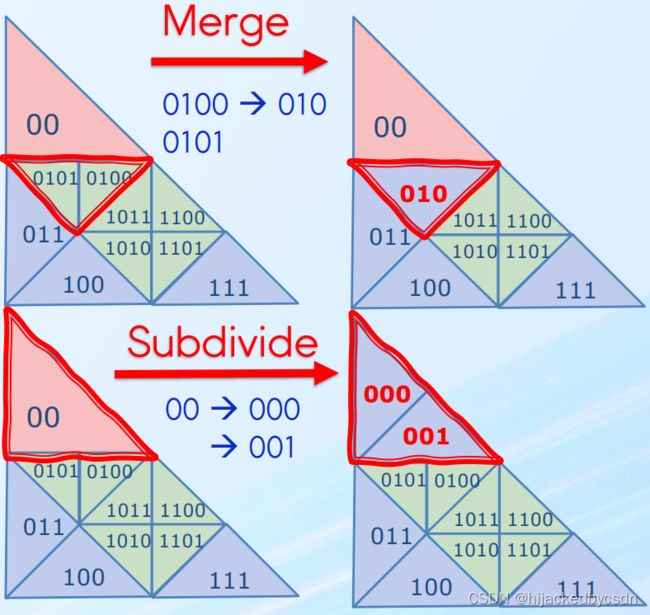 Fig: Merge and Subdivide
Fig: Merge and Subdivide
3. Keep
If target subdivision level is the same as the current level, simply write it to the
output buffer.
In the implementation , the root key is 1, so the most significant bit is always 1.
Subdivision Flickering Issues
We found that when the camera is moving fast, some random mesh flickering can be observed, and even worse, sometimes it leaves a permanent hole on the water mesh
We dump all the key buffers, sort them, check the diff, and found the reason.
In most cases, both sibling keys will get the same operation code as merge or subdivide, but there are cases they got a different operation, and then the next merge command will be an issue.
-
When a key (ending with 0) tries to merge, but the sibling key does not exist(subdivided), it will generate duplicated keys
-
When a key (ending with 1) tries to merge, it rely on the sibling key to merge, but the sibling key does not exist, the key will be removed and leave a hole
Fix:
Merge is only allowed if
-
Both sibling keys exist
-
Both have MERGE op
Otherwise, MERGE op will be changed to KEEP
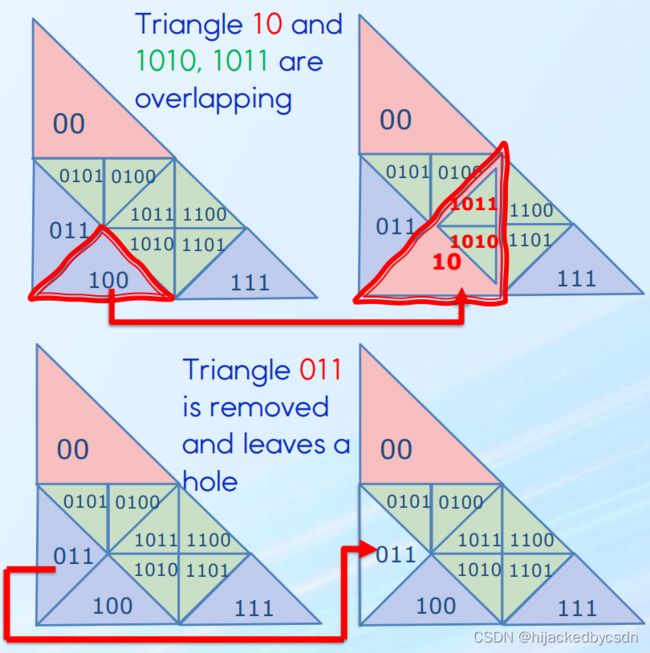 Fig: Merge and Subdivide
Fig: Merge and Subdivide
Subdivision Key Buffer Sorting
We realize that if the key is sorted, the siblings must be located beside each other. As the keys are output from the computer shader in random order. we need a GPU sorting algorithm.
Prefix sum is a popular algorithm for parallel GPU sorting
There was a Unity talk in 2021, they are using the same subvision algorithm on terrain, with concurrent binary tree.
We haven’t tried that method, but prefix sum sorting in group share memory is very fast, it only took less than 0.1ms for both subdivision and sorting on PS5.
Our implementation uses the in-place up/down sweep in LDS,
The total is 3 passes of prefix sum and 2 passes of block sum add.
Each pass uses a group size of 64 and it can support up to 262,144 items
Under 0.1ms for subdivision and sorting.
Chapter 39. Parallel Prefix Sum (Scan) with CUDA
Subdivision Memory Issues
After implemented the subdivision, we quickly runs into memory issues.
We use 32bits key and double buffered, allow it to subdivide up to 30 times. The ocean will cover 20km x 20km, the mesh center will keep following the player/camera.
It can quickly run out of the buffer.
Two Solutions:
-
Limit the max subdivision level
-
Limit the maximum subdivision level to 20
Keep the subdivision buffers under 100k keys. ( 2 x 3.2M)
-
Pre-subdivided triangle mesh is used for higher mesh density
-
-
Reduce the ocean mesh size
Use screen space tessellation to fill the gap between horizon
As we will fade out the displacement at the horizon anyway, only normal is applied, there is no displacement
 Fig: Gap
Fig: Gap
Tessellation methods comparison
CDLOD is fast for rendering rivers and lakes, but not suitable for large water bodies like oceans.
Screen-space tessellation is flexible without requiring a quad tree but can cause artifacts in the mid-distance with large displacement.
Adaptive subdivision is elegant in its algorithm, but one needs to experiment with different combinations to find a balance between quality and memory usage.
Using adaptive subdivision in ocean rendering is a relatively easier problem to solve if compared to terrain rendering
-
No height map
-
No Lod tweak for slope or mountain
-
Ocean mesh can be attached to the player, so we can render a much smaller mesh than the terrain
Final Thoughts
When creating a system that can be scaled from mobile to high-end pc, break the rendering pass to multiple passes gives us more freedom to tweak the LOD.
We tried our best to put all the code in the Unreal plugin. All the engine modifications are wrapped with a MACRO.
Plane
We plan to add more tools like custom wave, painting foam or algae layers, and paint a river channel to control the SWE simulation.
Current SWE simulation runs at the resolution of 1 square meter per pixel, any objects small than this size will be ignored, we will try to increase the resolution to get more detailed waves.
We have tried blending between SWE and baked water where they are connected, but the result it not good. We will try to get momentum from the baked height map and flow map for more realistic effects.
We have tested moving the water source up and down to create a shoreline wave, but still need more optimization and figuring out how to extend it to a large area.
Reference
Branislav Grujic & Cristian Cutocheras. “Water Rendering in Far Cry 5”, GDC 2018
Jeremy Moore . “Terrain Rendering in Far Cry 5”, GDC 2018
Strugar, Filip. “Continuous distance-dependent level of detail for rendering heightmaps.” Journal of graphics, GPU, and game tools 14.4 (2009): 57-74.
vante Lindgren . “Continuous Distance-Dependent Level of Detail” 2020-06-13
Tessendorf, Jerry. “Simulating ocean water.” Simulating nature: realistic and interactive techniques. SIGGRAPH 1.2 (2001): 5.
Khoury, Jad, Jonathan Dupuy, and Christophe Riccio. “Adaptive GPU Tessellation with Compute Shaders.”
Macklin, Miles, and Matthias Müller. “Position based fluids.” ACM Transactions on Graphics (TOG) 32.4 (2013): 1-12.
Wu, Kui, et al. “Fast fluid simulations with sparse volumes on the GPU.” Computer Graphics Forum. Vol. 37. No. 2. 2018.
Yuksel, Cem, Donald H. House, and John Keyser. “Wave particles.” ACM Transactions on Graphics (TOG) 26.3 (2007): 99-es.
Chentanez, Nuttapong, and Matthias Müller. “Real-time Simulation of Large Bodies of Water with Small Scale Details.” Symposium on Computer Animation. 2010.
Kass, Michael, and Gavin Miller. “Rapid, stable fluid dynamics for computer graphics.” Proceedings of the 17th annual conference on
Computer graphics and interactive techniques. 1990.
Zhou, Jian Guo. ”Lattice Boltzmann methods for shallow water flows”. Vol. 4. Berlin: Springer, 2004.