114、java中实现多态的机制是什么
答:重写,重载。方法的重写Overriding和重载Overloading是Java多态性的不同表现。
重写Overriding是父类与子类之间多态性的一种表现,重载Overloading是一个类中多态性的一种表现。如果在子类中定义某方法与其父类有相同的名称和参数,我们说该方法被重写 (Overriding)。子类的对象使用这个方法时,将调用子类中的定义,对它而言,父类中的定义如同被”屏蔽”了。
如果在一个类中定义了多个同名的方法,它们或有不同的参数个数或有不同的参数类型,则称为方法的重载(Overloading)。Overloaded的方法是可以改变返回值的类型。
115、静态的多态和动态的多态的区别
答:静态的多态: 即为重载 ;方法名相同,参数个数或类型不相同。(overloading)。动态的多态: 即为重写;子类覆盖父类的方法,将子类的实例传与父类的引用调用的是子类的方法 实现接口的实例传与接口的引用调用的实现类的方法。
116、extends和implement的不同
答:extends是继承父类,只要那个类不是声明为final或者那个类定义为abstract的就能继承,JAVA中不支持多重继承,但是可以用接口来实现,这样就要用到implements,继承只能继承一个类,但implements可以实现多个接口,用逗号分开就行了,比如 class A extends B implements C,D,E。
117、适配器模式与桥梁模式的区别
答:适配器模式把一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口不匹配而无法在一起工作的两个类能够在一起工作。又称为转换器模式、变压器模式、包装模式(把已有的一些类包装起来,使之能有满足需要的接口)。适配器模式的用意是将接口不同而功能相同或者相近的两个接口加以转换,包括适配器角色补充一些源角色没有但目标接口需要的方法。就像生活中电器插头是三相的,而电源插座是两相的,这时需要一个三相变两相的转换器来满足。
比如,在Java I/O库中使用了适配器模式,象FileInputStream是一个适配器类,其继承了InputStrem类型,同时持有一个对FileDiscriptor的引用。这是将一个FileDiscriptor对象适配成InputStrem类型的对象形式的适配器模式。StringReader是一个适配器类,其继承了Reader类型,持有一个对String对象的引用。它将String的接口适配成Reader类型的接口。等等。
桥梁模式的用意是要把实现和它的接口分开,以便它们可以独立地变化。桥梁模式并不是用来把一个已有的对象接到不相匹配的接口上的。当一个客户端只知道一个特定的接口,但是又必须与具有不同接口的类打交道时,就应该使用桥梁模式。
比如,JDBC驱动器就是一个桥梁模式的应用,使用驱动程序的应用系统就是抽象化角色,而驱动器本身扮演实现化角色。应用系统和JDBC驱动器是相对独立的。应用系统动态地选择一个合适的驱动器,然后通过驱动器向数据库引擎发出指令就可以访问数据库中的数据。
118、抽象类能否被实例化 ?抽象类的作用是什么?
答:抽象类不能被实例化;抽象类通常不是由程序员定义的,而是由项目经理或模块设计人设计抽象类的原因通常是为了规范方法名 抽象类必须要继承,不然没法用,作为模块设计者,可以把让底层程序员直接用得方法直接调用,而一些需要让程序员覆盖后自己做得方法则定义称抽象方法。
120、String,StringBuffer, StringBuilder 的区别是什么?String为什么是不可变的?
答:
1、String是字符串常量,StringBuffer和StringBuilder都是字符串变量。后两者的字符内容可变,而前者创建后内容不可变。
2、String不可变是因为在JDK中String类被声明为一个final类。
3、StringBuffer是线程安全的,而StringBuilder是非线程安全的。
ps:线程安全会带来额外的系统开销,所以StringBuilder的效率比StringBuffer高。如果对系统中的线程是否安全很掌握,可用StringBuffer,在线程不安全处加上关键字Synchronize。
121、Vector,ArrayList, LinkedList的区别是什么?
答:
1、Vector、ArrayList都是以类似数组的形式存储在内存中,LinkedList则以链表的形式进行存储。
2、List中的元素有序、允许有重复的元素,Set中的元素无序、不允许有重复元素。(TreeSet 是二差树实现的,Treeset中的数据是自动排好序的,不允许放入null值,HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复)
3、Vector线程同步,ArrayList、LinkedList线程不同步。
4、LinkedList适合指定位置插入、删除操作,不适合查找;ArrayList、Vector适合查找,不适合指定位置的插入、删除操作。
5、ArrayList在元素填满容器时会自动扩充容器大小的0.5n+1,而Vector则是2n,因此ArrayList更节省空间。
122、HashTable, HashMap,TreeMap区别?
答:
1、HashTable线程同步,HashMap非线程同步。
2、HashTable不允许<键,值>有空值,HashMap允许<键,值>有空值。
3、HashTable使用Enumeration,HashMap使用Iterator。
4、HashTable中hash数组的默认大小是11,增加方式的old*2+1,HashMap中hash数组的默认大小是16,增长方式一定是2的指数倍。
5、TreeMap能够把它保存的记录根据键排序,默认是按升序排序。
123、Tomcat,Apache,JBoss,Weblogic的区别?
答:
Apache:全球应用最广泛的http服务器,免费,出自apache基金组织
Tomcat:应用也算非常广泛的web服务器,支持部分j2ee,免费,出自apache基金组织
JBoss:开源的应用服务器,比较受人喜爱,免费(文档要收费)
Weblogic:应该说算是业界第一的app server,全部支持j2ee1.4,对于开发者,有免费使用一年的许可证。
124、GET,POST区别?
答:基础知识:Http的请求格式如下。
<request line>:主要包含三个信息:1、请求的类型(GET或POST),2、要访问的资源(如\res\img\a.jif),3、Http版本(http/1.1)
<header>:用来说明服务器要使用的附加信息
<blank line>:这是Http的规定,必须空一行
[<request-body>]:请求的内容数据- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
区别:
1、Get是从服务器端获取数据,Post则是向服务器端发送数据。
2、在客户端,Get方式通过URL提交数据,在URL地址栏可以看到请求消息,该消息被编码过;Post数据则是放在Html header内提交。
3、对于Get方式,服务器端用Request.QueryString获取变量的值;对用Post方式,服务器端用Request.Form获取提交的数据值。
4、Get方式提交的数据最多1024字节,而Post则没有限制。
5、Get方式提交的参数及参数值会在地址栏显示,不安全,而Post不会,比较安全。
125、Session, Cookie区别
答:
1、Session由应用服务器维护的一个服务器端的存储空间;Cookie是客户端的存储空间,由浏览器维护。
2、用户可以通过浏览器设置决定是否保存Cookie,而不能决定是否保存Session,因为Session是由服务器端维护的。
3、Session中保存的是对象,Cookie中保存的是字符串。
4、Session和Cookie不能跨窗口使用,每打开一个浏览器系统会赋予一个SessionID,此时的SessionID不同,若要完成跨浏览器访问数据,可以使用Application。
5、Session、Cookie都有失效时间,过期后会自动删除,减少系统开销。
126、Servlet的生命周期
答:大致分为4部:Servlet类加载–>实例化–>服务–>销毁
1、Web Client向Servlet容器(Tomcat)发出Http请求。
2、Servlet容器接收Client端的请求。
3、Servlet容器创建一个HttpRequest对象,将Client的请求信息封装到这个对象中。
4、Servlet创建一个HttpResponse对象。
5、Servlet调用HttpServlet对象的service方法,把HttpRequest对象和HttpResponse对象作为参数传递给HttpServlet对象中。
6、HttpServlet调用HttpRequest对象的方法,获取Http请求,并进行相应处理。
7、处理完成HttpServlet调用HttpResponse对象的方法,返回响应数据。
8、Servlet容器把HttpServlet的响应结果传回客户端。
其中的3个方法说明了Servlet的生命周期:
1、init():负责初始化Servlet对象。
2、service():负责响应客户端请求。
3、destroy():当Servlet对象推出时,负责释放占用资源。
127、HTTP 报文包含内容
答:主要包含四部分:
1、request line
2、header line
3、blank line
4、request body
128、Statement与PreparedStatement的区别,什么是SQL注入,如何防止SQL注入
答:
1、PreparedStatement支持动态设置参数,Statement不支持。
2、PreparedStatement可避免如类似 单引号 的编码麻烦,Statement不可以。
3、PreparedStatement支持预编译,Statement不支持。
4、在sql语句出错时PreparedStatement不易检查,而Statement则更便于查错。
5、PreparedStatement可防止Sql注入,更加安全,而Statement不行。
什么是SQL注入:
通过sql语句的拼接达到无参数查询数据库数据目的的方法。
如将要执行的sql语句为 select * from table where name = “+appName+”,利用appName参数值的输入,来生成恶意的sql语句,如将[‘or’1’=’1’] 传入可在数据库中执行。
因此可以采用PrepareStatement来避免Sql注入,在服务器端接收参数数据后,进行验证,此时PrepareStatement会自动检测,而Statement不 行,需要手工检测。
129、sendRedirect, foward区别
答:转发是服务器行为,重定向是客户端行为。
转发过程:客户浏览器发送http请求->web服务器接受此请求->调用内部的一个方法在容器内部完成请求处理和转发动作->将目标资源 发送给客户;在这里,转发的路径必须是同一个web容器下的url,其不能转向到其他的web路径上去,中间传递的是自己的容器内的request。在客户浏览器路径栏显示的仍然是其第一次访问的路径,也就是说客户是感觉不到服务器做了转发的。转发行为是浏览器只做了一次访问请求。
重定向过程:客户浏览器发送http请求->web服务器接受后发送302状态码响应及对应新的location给客户浏览器->客户浏览器发现 是302响应,则自动再发送一个新的http请求,请求url是新的location地址->服务器根据此请求寻找资源并发送给客户。在这里location可以重定向到任意URL,既然是浏览器重新发出了请求,则就没有什么request传递的概念了。在客户浏览器路径栏显示的是其重定向的 路径,客户可以观察到地址的变化的。重定向行为是浏览器做了至少两次的访问请求的。
130、反射讲一讲,主要是概念,都在哪需要反射机制,反射的性能,如何优化
答:反射机制的定义:是在运行状态中,对于任意的一个类,都能够知道这个类的所有属性和方法,对任意一个对象都能够通过反射机制调用一个类的任意方法,这种动态获取类信息及动态调用类对象方法的功能称为java的反射机制。
反射的作用:
1、动态地创建类的实例,将类绑定到现有的对象中,或从现有的对象中获取类型。
2、应用程序需要在运行时从某个特定的程序集中载入一个特定的类
131、关于Cache(Ehcache,Memcached)
http://xuezhongfeicn.blog.163.com/blog/static/2246014120106144143737/
133、画出最熟悉的三个设计模式的类图
134、写代码分别使得JVM的堆、栈和持久代发生内存溢出(栈溢出)
一个死循环 递归调用就 可以栈溢出。建好多对象实例放入ArrayList里可以堆溢出。持久代溢出可以新建很多 ClassLoader 来装载同一个类文件。
因为方法区是保存类的相关信息的,所以当我们加载过多的类时就会导致方法区溢出。CGLIB同样会缓存代理类的Class对象,但是我们可以通过配置让它不缓存Class对象,这样就可以通过反复创建代理类达到使方法区溢出的目的。
package com.cdai.jvm.overflow;
import java.lang.reflect.Method;
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
public class MethodAreaOverflow2 {
static class OOMObject {
}
public static void main(String[] args) {
while (true) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(OOMObject.class);
enhancer.setUseCache(false);
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object obj, Method method,
Object[] args, MethodProxy proxy) throws Throwable {
return method.invoke(obj, args);
}
});
OOMObject proxy = (OOMObject) enhancer.create();
System.out.println(proxy.getClass());
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
堆溢出比较简单,只需通过创建一个大数组对象来申请一块比较大的内存,就可以使堆发生溢出。
package com.cdai.jvm.overflow;
public class HeapOverflow {
private static final int MB = 1024 * 1024;
SuppressWarnings("unused")
public static void main(String[] args) {
byte[] bigMemory = new byte[1024 * MB];
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
栈溢出也比较常见,有时我们编写的递归调用没有正确的终止条件时,就会使方法不断递归,栈的深度不断增大,最终发生栈溢出。
package com.cdai.jvm.overflow;
public class StackOverflow {
private static int stackDepth = 1;
public static void stackOverflow() {
stackDepth++;
stackOverflow();
}
public static void main(String[] args) {
try {
stackOverflow();
}
catch (Exception e) {
System.err.println("Stack depth: " + stackDepth);
e.printStackTrace();
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
135、hashmap的内部实现机制,hash是怎样实现的,什么时候rehash
136、java的内存管理
137、分布式缓存的内存管理,如何管理和释放不断膨胀的session,memcache是否熟悉
138、oralce的底层管理(怎样让查询快,插入慢)
139、java底层是怎样对文件操作的
140、研究了哪些框架的源码
141、并发问题,锁,怎么处理死锁,脏数据处理
141、性能问题
142、equals和hashcode这些方法怎么使用的
143、java的NIO
http://lvwenwen.iteye.com/blog/1706221
144、先从项目模块入手,详细问项目模块是怎么实现的,遇到的问题怎么解决(一定要说自己做过的,真实的情况)
145、sql语句优化怎么做的,建索引的时候要考虑什么
146、spring ioc你的理解,ioc容器启动的过程是什么样的,什么是ioc,aop 你个人的理解是什么
147、jms 你个人的理解,就是消息接收完怎么处理,介质处理(为什么重启mq就能恢复)
解答:http://setting.iteye.com/blog/1097767
148、sychronized 机制 加了static 方法的同步异同,A 调用 B,A执行完了,B没执行完,怎么解决这个同步问题
149、servlet 默认是线程安全的吗,为什么不是线程安全的
解答:不是 :url:http://westlifesz.iteye.com/blog/49511
http://jsjxqjy.iteye.com/blog/1563249
http://developer.51cto.com/art/200907/133827.htm
150、spring里面的action 默认是单列的,怎么配置成多列?
socpe =proptype?
151、socket 是用的什么协议,tcp协议连接(握手)的过程是什么样的,socket使用要注意哪些问题
解答:tcp协议,
152、数据库连接池设置几个连接,是怎么处理的,说说你的理解
153、自定义异常要怎么考虑呢,checked的异常跟 unchecked 的异常的区别
154、线程池是怎么配置的,怎么用的,要注意哪些,说下个人的理解
155、tomact 里session共享是怎么做到的,
解答:http://zhli986-yahoo-cn.iteye.com/blog/1344694
156、服务器集群有搭建过吗
解答:http://www.iteye.com/topic/1119823
157、阿里B2B北京专场java开发面试题(2011.10.29)
http://yueyemaitian.iteye.com/blog/1387901
jvm的体系结构,画了之后说各个部分的职责,并扯到运行期优化。
158、文件拷贝,把一个文件的内容拷贝到另外一个文件里
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
public class FileCopy {
public static void main(String[] args)
{
try
{
int bytesum = 0;
int byteread = 0;
File oldfile = new File( "c:/test.txt");
if ( oldfile.exists() )
{ //文件存在时
InputStream inStream = new FileInputStream( "c:/test.txt" ); //读入原文件
FileOutputStream fs = new FileOutputStream( "d:/test.txt" );
byte[] buffer = new byte[ 1444 ];
int length;
while ( ( byteread = inStream.read( buffer ) ) != -1 )
{
bytesum += byteread; //字节数 文件大小
System.out.println( bytesum );
fs.write( buffer, 0, byteread );
}
inStream.close();
}
}
catch ( Exception e )
{
System.out.println( "复制单个文件操作出错" );
e.printStackTrace();
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
159、HashMap遍历的几种方法
// 第一种:效率高,以后一定要使用此种方式!
Map map = new HashMap();
Iterator iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
Object key = entry.getKey();
Object val = entry.getValue();
}
// 第二种:效率低,以后尽量少使用!
Map map = new HashMap();
Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
Object key = iter.next();
Object val = map.get(key);
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
160、写一个类,连接数据库并执行一条sql
import java.sql.*;
public class SqlDemo{
public static void main(String[] args) {
try {
String url = "jdbc:mysql://localhost/mydb";
String user = "root";
String pwd = "123456";
//加载驱动,这一句也可写为:Class.forName("com.mysql.jdbc.Driver");
Class.forName("com.mysql.jdbc.Driver").newInstance();
//建立到MySQL的连接
Connection conn = DriverManager.getConnection(url, user, pwd);
//执行SQL语句
Statement stmt = conn.createStatement();//创建语句对象,用以执行sql语言
ResultSet rs = stmt.executeQuery("select * from student");
//处理结果集
while (rs.next()) {
String name = rs.getString("name");
System.out.println(name);
}
rs.close();//关闭数据库
conn.close();
} catch (Exception ex) {
System.out.println("Error : " + ex.toString());
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
161、JVM性能调优,都做了什么?
答:
1).控制GC的行为。GC是一个后台处理,但是它也是会消耗系统性能的,因此经常会根据系统运行的程序的特性来更改GC行为
2).控制JVM堆栈大小。一般来说,JVM在内存分配上不需要你修改,(举例)但是当你的程序新生代对象在某个时间段产生的比较多的时候,就需要控制新生代的堆大小.同时,还要需要控制总的JVM大小避免内存溢出。
3).控制JVM线程的内存分配。如果是多线程程序,产生线程和线程运行所消耗的内存也是可以控制的,需要通过一定时间的观测后,配置最优结果。
162、TCP头部都什么内容
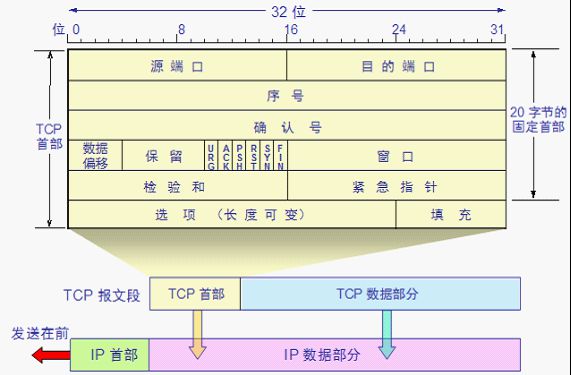
源端口和目的端口:各占2字节.端口是传输层与应用层的服务接口.传输层的复用和分用功能都要通过端口才能实现。
序号:占4字节.TCP 连接中传送的数据流中的每一个字节都编上一个序号.序号字段的值则指的是本报文段所发送的数据的第一个字节的序号
确认号:占 4 字节,是期望收到对方的下一个报文段的数据的第一个字节的序号
数据偏移/首部长度:占4位,它指出 TCP 报文段的数据起始处距离 TCP 报文段的起始处有多远.“数据偏移”的单位是32位字(以 4 字节为计算单位)
保留:占6位,保留为今后使用,但目前应置为0
紧急URG:当 URG=1 时,表明紧急指针字段有效.它告诉系统此报文段中有紧急数据,应尽快传送(相当于高优先级的数据)
确认ACK:只有当 ACK=1 时确认号字段才有效.当 ACK=0 时,确认号无效
PSH(PuSH):接收 TCP 收到 PSH = 1 的报文段,就尽快地交付接收应用进程,而不再等到整个缓存都填满了后再向上交付。
RST (ReSeT):当 RST=1 时,表明 TCP 连接中出现严重差错(如由于主机崩溃或其他原因),必须释放连接,然后再重新建立运输连接。
同步 SYN:同步 SYN = 1 表示这是一个连接请求或连接接受报文
终止 FIN:用来释放一个连接.FIN=1 表明此报文段的发送端的数据已发送完毕,并要求释放运输连接
检验和:占 2 字节.检验和字段检验的范围包括首部和数据这两部分.在计算检验和时,要在 TCP 报文段的前面加上 12 字节的伪首部
紧急指针:占 16 位,指出在本报文段中紧急数据共有多少个字节(紧急数据放在本报文段数据的最前面)
选项:长度可变.TCP 最初只规定了一种选项,即最大报文段长度 MSS.MSS 告诉对方 TCP:“我的缓存所能接收的报文段的数据字段的最大长度是 MSS 个字节.” [MSS(Maximum Segment Size)是 TCP 报文段中的数据字段的最大长度.数据字段加上 TCP 首部才等于整个的 TCP 报文段]
填充:这是为了使整个首部长度是4 字节的整数倍
其他选项:
窗口扩大:占3字节,其中有一个字节表示移位值 S.新的窗口值等于TCP 首部中的窗口位数增大到(16 + S),相当于把窗口值向左移动 S 位后获得实际的窗口大小
时间戳:占10 字节,其中最主要的字段时间戳值字段(4字节)和时间戳回送回答字段(4字节)
选择确认:接收方收到了和前面的字节流不连续的两2字节.如果这些字节的序号都在接收窗口之内,那么接收方就先收下这些数据,但要把这些信息准确地告诉发送方,使发送方不要再重复发送这些已收到的数据
163、DUP报文结构
164、HTTP报文结构
HTTP请求报文:一个HTTP请求报文由请求行(request line)、请求头部(header)、空行和请求数据4个部分组成。 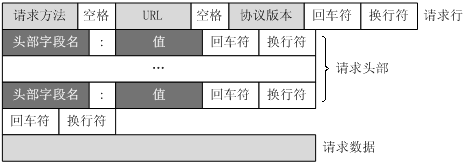
or
<request-line>
<headers>
<blank line>
[<request-body>]- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
请求行:请求行由请求方法字段、URL字段和HTTP协议版本字段3个字段组成,它们用空格分隔。
请求头部:请求头部由关键字/值对组成,每行一对,关键字和值用英文冒号“:”分隔。请求头部通知服务器有关于客户端请求的信息,典型的请求头有:
- User-Agent:产生请求的浏览器类型。
- Accept:客户端可识别的内容类型列表。
- Host:请求的主机名,允许多个域名同处一个IP地址,即虚拟主机。
- 空行:最后一个请求头之后是一个空行,发送回车符和换行符,通知服务器以下不再有请求头。
请求数据:请求数据不在GET方法中使用,而是在POST方法中使用。POST方法适用于需要客户填写表单的场合。与请求数据相关的最常使用的请求头是Content-Type和Content-Length。
HTTP响应报文:HTTP响应由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
<status-line>
<headers>
<blank line>
[<response-body>]- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
状态行格式如下:HTTP-Version Status-Code Reason-Phrase CRLF
HTTP-Version表示服务器HTTP协议的版本;
Status-Code表示服务器发回的响应状态代码;
Reason-Phrase表示状态代码的文本描述。
CRLF表示换行
状态代码由三位数字组成,第一个数字定义了响应的类别,且有五种可能取值。
1xx:指示信息–表示请求已接收,继续处理。
2xx:成功–表示请求已被成功接收、理解、接受。
3xx:重定向–要完成请求必须进行更进一步的操作。
4xx:客户端错误–请求有语法错误或请求无法实现。
5xx:服务器端错误–服务器未能实现合法的请求。
常见状态代码、状态描述的说明如下。
200 OK:客户端请求成功。
400 Bad Request:客户端请求有语法错误,不能被服务器所理解。
401 Unauthorized:请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用。
403 Forbidden:服务器收到请求,但是拒绝提供服务。
404 Not Found:请求资源不存在,举个例子:输入了错误的URL。
500 Internal Server Error:服务器发生不可预期的错误。
503 Server Unavailable:服务器当前不能处理客户端的请求,一段时间后可能恢复正常,举个例子:HTTP/1.1 200 OK(CRLF)。
165、TCP协议和UDP协议的区别
1,TCP协议面向连接,UDP协议面向非连接
2,TCP协议传输速度慢,UDP协议传输速度快
3,TCP协议保证数据顺序,UDP协议不保证
4,TCP协议保证数据正确性,UDP协议可能丢包
5,TCP协议对系统资源要求多,UDP协议要求少
166、java对象在虚拟机中怎样实例化。
首先判断对象实例化的类型信息是否已经在JVM,如果不存在就对类型信息进行装载、连接和初始化,之后就可以使用了,可以访问类型的静态字段和方法,最后再创建类型实例,为实例对象分配内存空间。对象的创建分为显示创建和隐式创建两种。
显示创建分为:
1、通过new创建;
2、通过java.lang.Class的newInstance方法创建;
3、通过clone方法创建;
4、通过java.io.ObjectInputStream的readObject方法创建。
隐式创建分为:
1、启动类的main方法的string数组参数;
2、常量池的CONSTANT_String_info表项被解析的时候会创建一个String对象;
3、每个加载的类都会创建一个java.lang.Class对象;
4、字符串+操作的时候,创建StringBuffer/StringBuilder对象。
对象在内存中的存储
非严格意义来说,对象都存储在堆上,由垃圾收集器负责回收不再被引用的对象。但是随着jvm运行期编译技术的不断进步,栈上分配对象和标量替换技术使得非逃逸对象可以分配在栈上。当然绝大多数对象都是分配在堆上的,此处我们主要讨论对象在堆中的存储。
对象的内容有:
1、实例数据;
2、指向堆中类型信息的指针;
3、对象锁相关的数据;
4、多线程协调完成同一件事情的时候wait set相关的队列;
5、垃圾收集相关的内容,如存活时间、finalize方法是否运行过。
对象在内存中存储主要有两种方式:
1、堆划分为句柄池和对象池,创建对象后的得到的引用是指向句柄池的指针,句柄池指针则指向对象池里的对象;
2、堆只分为对象池,引用直接指向对象池中的对象。
167、java连接池中连接如何收缩?
Java连接池中一般都有设置最大、最小连接数,当连接池中的连接达到最大连接数时,就不会再创建新的连接。一般来说定时检测连接池中空闲连接数,当超过一定时间没有使用的话,先判断现有连接池中的连接是否大于最小连接数,如果大于的话,就好回收这个空闲连接,否则的话,就不会进行回收。
如何确保连接池中的最小连接数呢?有动态和静态两种策略。动态即每隔一定时间就对连接池进行检测,如果发现连接数量小于最小连接数,则补充相应数量的新连接,以保证连接池的正常运转。静态是发现空闲连接不够时再去检查。

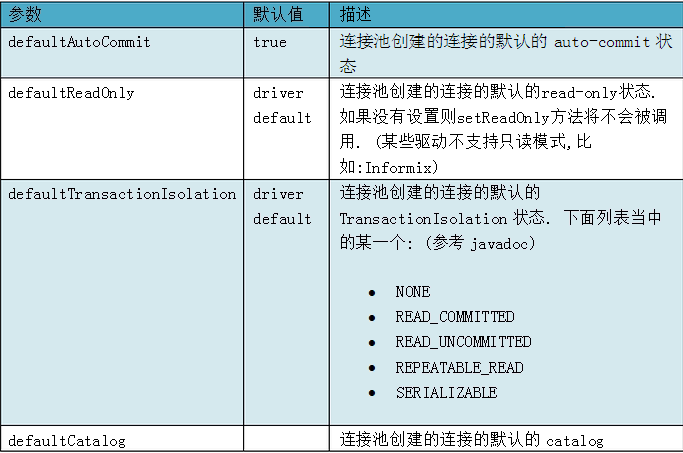
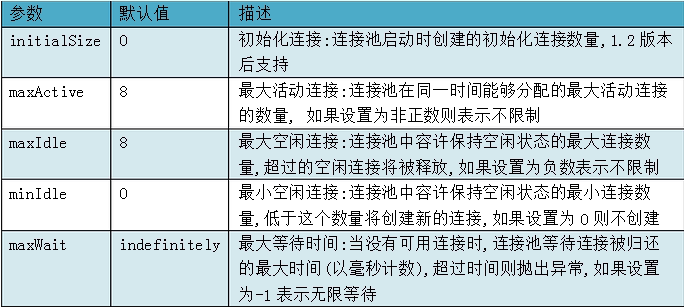
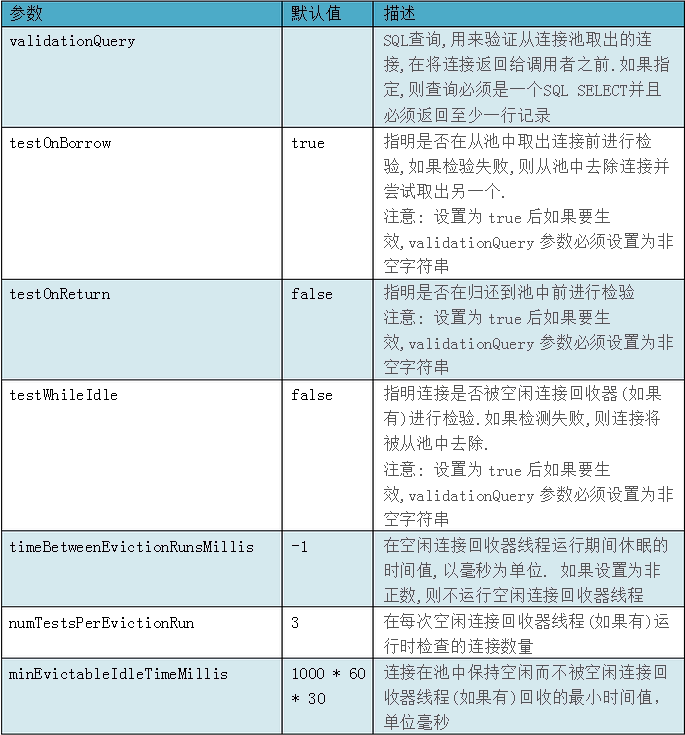
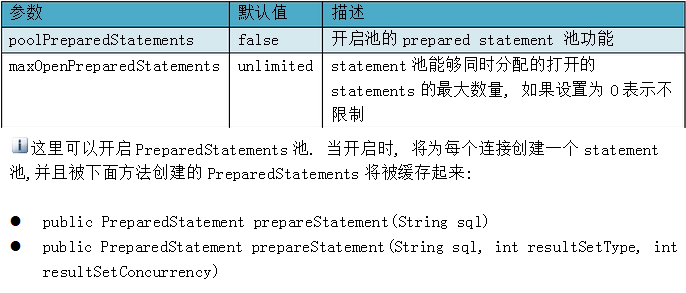

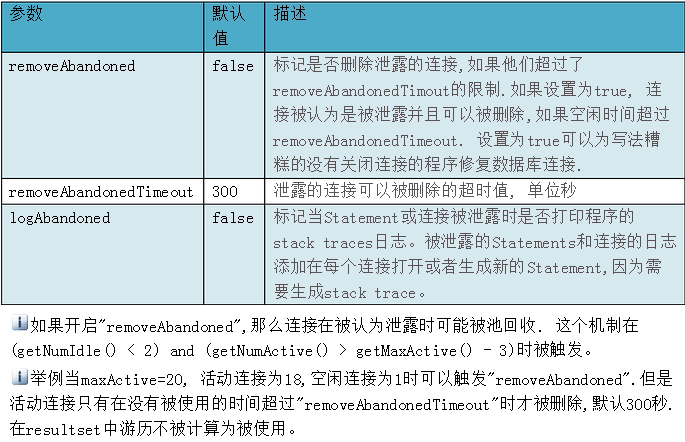
上面就是连接池的配置信息
168、Java多线程问题
有如下一个类:
public class MyStack {
private List list = new ArrayList();
public synchronized void push(String value) {
synchronized (this) {
list.add(value);
notify();
}
}
public synchronized String pop() throws InterruptedException {
synchronized (this) {
if (list.size() <= 0) {
wait();
}
return list.remove(list.size() - 1);
}
}
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
问题: 这段代码大多数情况下运行正常,但是某些情况下会出问题。什么时候会出现什么问题?如何修正?
代码分析:
从整体上,在并发状态下,push和pop都使用了synchronized的锁,来实现同步,同步的数据对象是基于List的数据;大部分情况下是可以正常工作的。
问题描述:
状况1:
1. 假设有三个线程: A,B,C. A 负责放入数据到list,就是调用push操作, B,C分别执行Pop操作,移除数据。
2. 首先B先执行,于pop中的wait()方法处,进入waiting状态,进入等待队列,释放锁。
3. A首先执行放入数据push操作到List,在调用notify()之前; 同时C执行pop(),由于synchronized,被阻塞,进入Blocked状态,放入基于锁的等待队列。注意,这里的队列和2中的waiting等待队列是两个不同的队列。
4. A线程调用notify(),唤醒等待中的线程A。
5. 如果此时, C获取到基于对象的锁,则优先执行,执行pop方法,获取数据,从list移除一个元素。
6. 然后,A获取到竞争锁,A中调用list.remove(list.size() - 1),则会报数据越界exception。
状况2:
1. 相同于状况1
2. B、C都处于等待waiting状态,释放锁。等待notify()、notifyAll()操作的唤醒。
3. 存在被虚假唤醒的可能。
何为虚假唤醒?
虚假唤醒就是一些obj.wait()会在除了obj.notify()和obj.notifyAll()的其他情况被唤醒,而此时是不应该唤醒的。
解决的办法是基于while来反复判断进入正常操作的临界条件是否满足:
synchronized (obj) {
while ()
obj.wait();
... // Perform action appropriate to condition
} - 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
如何修复问题?
1. 使用可同步的数据结构来存放数据,比如LinkedBlockingQueue之类。由这些同步的数据结构来完成繁琐的同步操作。
2. 双层的synchronized使用没有意义,保留外层即可。
3. 将if替换为while,解决虚假唤醒的问题。
168、super.getClass方法调用
先看一下程序的代码,看看最后的输出结果是多少?
import java.util.Date;
public class Test extends Date {
public void test() {
System.out.println(super.getClass().getName());
}
public static void main(String[] args) {
new Test().test();
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如果不了解,很可能得出错误的答案,其实答案是Test,是不是很奇怪,结果竟然是Test。
这道题就属于脑筋急转弯的题目,很简单的,也很容易落入陷阱中。我想大部分人之所以落入陷阱中可能是因为这个类继承了。
如果在test方法中,直接调用getClass().getName()方法的化,相当于调用this.getClass().getName(),这样返回的就是Test类名,getClass()返回对象运行时的字节码对象,当前对象是Test的实例,所以其字节码对象就是Test
由于getClass()在Object类中定义成了final,子类不能覆盖该方法,所以,Date类也是没有这个方法的,在test方法中调用getClass().getName()方法,其实就是在调用从父类继承的getClass()方法,等效于调用super.getClass().getName()方法,所以,super.getClass().getName()方法返回的也应该是Test。
如果想得到父类的名称,应该用如下代码:
getClass().getSuperClass().getName();
169、B树,B+树,B*树
170、知道哪些锁机制?(不限JAVA)什么是可重入性? synchronized的可重入性?显式锁跟synchronized对比?semaphore机制怎么实现?一个线程从wait()状态醒来是不是一定被notify()了?
171、什么情景下应用过TreeMap?TreeMap内部怎么实现的?
TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。
TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
TreeMap 实现了Cloneable接口,意味着它能被克隆。
TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fast的。
178、Java网络编程,socket描述什么的?同一端口可否同时被两个应用监听?
Socket通常也称作”套接字”,用于描述IP地址和端口,是一个通信链的句柄。网络上的两个程序通过一个双向的通讯连接实现数据的交换,这个双向链路的一端称为一个Socket,一个Socket由一个IP地址和一个端口号唯一确定。应用程序通常通过”套接字”向网络发出请求或者应答网络请求。 Socket是TCP/IP协议的一个十分流行的编程界面,但是,Socket所支持的协议种类也不光TCP/IP一种,因此两者之间是没有必然联系的。在Java环境下,Socket编程主要是指基于TCP/IP协议的网络编程。
Socket通讯过程:服务端监听某个端口是否有连接请求,客户端向服务端发送连接请求,服务端收到连接请求向客户端发出接收消息,这样一个连接就建立起来了。客户端和服务端都可以相互发送消息与对方进行通讯。
Socket的基本工作过程包含以下四个步骤:
1、创建Socket;
2、打开连接到Socket的输入输出流;
3、按照一定的协议对Socket进行读写操作;
4、关闭Socket。
在java.net包下有两个类:Socket和ServerSocket。ServerSocket用于服务器端,Socket是建立网络连接时使用的。在连接成功时,应用程序两端都会产生一个Socket实例,操作这个实例,完成所需的会话。对于一个网络连接来说,套接字是平等的,并没有差别,不因为在服务器端或在客户端而产生不同级别。不管是Socket还是ServerSocket它们的工作都是通过SocketImpl类及其子类完成的。
Socket(InetAddress address,int port);//创建一个流套接字并将其连接到指定 IP 地址的指定端口号
Socket(String host,int port);//创建一个流套接字并将其连接到指定主机上的指定端口号
Socket(InetAddress address,int port, InetAddress localAddr,int localPort);//创建一个套接字并将其连接到指定远程地址上的指定远程端口
Socket(String host,int port, InetAddress localAddr,int localPort);//创建一个套接字并将其连接到指定远程主机上的指定远程端口
Socket(SocketImpl impl);//使用用户指定的 SocketImpl 创建一个未连接 Socket
ServerSocket(int port);//创建绑定到特定端口的服务器套接字
ServerSocket(int port,int backlog);//利用指定的 backlog 创建服务器套接字并将其绑定到指定的本地端口号
ServerSocket(int port,int backlog, InetAddress bindAddr);//使用指定的端口、侦听 backlog 和要绑定到的本地 IP地址创建服务器。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
179、在多线程里面如何实现一个变量被多线程独立的访问。
1,在线程内部创建变量
2,使用threadlocal对象
180、concurrentHashMap的实现
ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术。它使用了多个锁来控制对hash表的不同部分进行的修改。ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。
有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。这里“按顺序”是很重要的,否则极有可能出现死锁,在ConcurrentHashMap内部,段数组是final的,并且其成员变量实际上也是final的,但是,仅仅是将数组声明为final的并不保证数组成员也是final的,这需要实现上的保证。这可以确保不会出现死锁,因为获得锁的顺序是固定的。
ConcurrentHashMap 类中包含两个静态内部类 HashEntry 和 Segment。HashEntry 用来封装映射表的键 / 值对;Segment 用来充当锁的角色,每个 Segment 对象守护整个散列映射表的若干个桶。每个桶是由若干个 HashEntry 对象链接起来的链表。一个 ConcurrentHashMap 实例中包含由若干个 Segment 对象组成的数组。
HashEntry 用来封装散列映射表中的键值对。在 HashEntry 类中,key,hash 和 next 域都被声明为 final 型,value 域被声明为 volatile 型。同时,HashEntry 类的 value 域被声明为 Volatile 型,Java 的内存模型可以保证:某个写线程对 value 域的写入马上可以被后续的某个读线程“看”到。在 ConcurrentHashMap 中,不允许用 unll 作为键和值,当读线程读到某个 HashEntry 的 value 域的值为 null 时,便知道产生了冲突——发生了重排序现象,需要加锁后重新读入这个 value 值。这些特性互相配合,使得读线程即使在不加锁状态下,也能正确访问 ConcurrentHashMap。
在 ConcurrentHashMap 中,在散列时如果产生“碰撞”,将采用“分离链接法”来处理“碰撞”:把“碰撞”的 HashEntry 对象链接成一个链表。由于 HashEntry 的 next 域为 final 型,所以新节点只能在链表的表头处插入。
Segment 类继承于 ReentrantLock 类,从而使得 Segment 对象能充当锁的角色。每个 Segment 对象用来守护其(成员对象 table 中)包含的若干个桶。
避免热点域:在 ConcurrentHashMap中,每一个 Segment 对象都有一个 count 对象来表示本 Segment 中包含的 HashEntry 对象的个数。这样当需要更新计数器时,不用锁定整个 ConcurrentHashMap。
ConcurrentHashMap 在默认并发级别会创建包含 16 个 Segment 对象的数组。每个 Segment 的成员对象 table 包含若干个散列表的桶。每个桶是由 HashEntry 链接起来的一个链表。如果键能均匀散列,每个 Segment 大约守护整个散列表中桶总数的 1/16。
在 ConcurrentHashMap 中,线程对映射表做读操作时,一般情况下不需要加锁就可以完成,对容器做结构性修改的操作才需要加锁。
用 Volatile 变量协调读写线程间的内存可见性。
ConcurrentHashMap 实现高并发的总结
基于通常情形而优化
在实际的应用中,散列表一般的应用场景是:除了少数插入操作和删除操作外,绝大多数都是读取操作,而且读操作在大多数时候都是成功的。正是基于这个前提,ConcurrentHashMap 针对读操作做了大量的优化。通过 HashEntry 对象的不变性和用 volatile 型变量协调线程间的内存可见性,使得大多数时候,读操作不需要加锁就可以正确获得值。这个特性使得 ConcurrentHashMap 的并发性能在分离锁的基础上又有了近一步的提高。
总结
ConcurrentHashMap 是一个并发散列映射表的实现,它允许完全并发的读取,并且支持给定数量的并发更新。相比于 HashTable 和用同步包装器包装的 HashMap(Collections.synchronizedMap(new HashMap())),ConcurrentHashMap 拥有更高的并发性。在 HashTable 和由同步包装器包装的 HashMap 中,使用一个全局的锁来同步不同线程间的并发访问。同一时间点,只能有一个线程持有锁,也就是说在同一时间点,只能有一个线程能访问容器。这虽然保证多线程间的安全并发访问,但同时也导致对容器的访问变成串行化的了。
在使用锁来协调多线程间并发访问的模式下,减小对锁的竞争可以有效提高并发性。有两种方式可以减小对锁的竞争:
1. 减小请求 同一个锁的 频率。
2. 减少持有锁的 时间。
ConcurrentHashMap 的高并发性主要来自于三个方面:
1. 用分离锁实现多个线程间的更深层次的共享访问。
2. 用 HashEntery 对象的不变性来降低执行读操作的线程在遍历链表期间对加锁的需求。
3. 通过对同一个 Volatile 变量的写 / 读访问,协调不同线程间读 / 写操作的内存可见性。
使用分离锁,减小了请求 同一个锁的频率。
通过 HashEntery 对象的不变性及对同一个 Volatile 变量的读 / 写来协调内存可见性,使得 读操作大多数时候不需要加锁就能成功获取到需要的值。由于散列映射表在实际应用中大多数操作都是成功的 读操作,所以 2 和 3 既可以减少请求同一个锁的频率,也可以有效减少持有锁的时间。
通过减小请求同一个锁的频率和尽量减少持有锁的时间 ,使得 ConcurrentHashMap 的并发性相对于 HashTable 和用同步包装器包装的 HashMap有了质的提高。
181、TCP长连接和短连接
当网络通信时采用TCP协议时,在真正的读写操作之前,server与client之间必须建立一个连接,当读写操作完成后,双方不再需要这个连接时它们可以释放这个连接,连接的建立是需要三次握手的,而释放则需要4次握手,所以说每个连接的建立都是需要资源消耗和时间消耗的。
TCP短连接
我们模拟一下TCP短连接的情况,client向server发起连接请求,server接到请求,然后双方建立连接。client向server发送消息,server回应client,然后一次读写就完成了,这时候双方任何一个都可以发起close操作,不过一般都是client先发起close操作。为什么呢,一般的server不会回复完client后立即关闭连接的,当然不排除有特殊的情况。从上面的描述看,短连接一般只会在client/server间传递一次读写操作
短连接的优点是:管理起来比较简单,存在的连接都是有用的连接,不需要额外的控制手段。
TCP长连接
接下来我们再模拟一下长连接的情况,client向server发起连接,server接受client连接,双方建立连接。Client与server完成一次读写之后,它们之间的连接并不会主动关闭,后续的读写操作会继续使用这个连接。
首先说一下TCP/IP详解上讲到的TCP保活功能,保活功能主要为服务器应用提供,服务器应用希望知道客户主机是否崩溃,从而可以代表客户使用资源。如果客户已经消失,使得服务器上保留一个半开放的连接,而服务器又在等待来自客户端的数据,则服务器将永远等待客户端的数据,保活功能就是试图在服务器端检测到这种半开放的连接。
如果一个给定的连接在两小时内没有任何的动作,则服务器就向客户发一个探测报文段,客户主机必须处于
以下4个状态之一:
客户主机依然正常运行,并从服务器可达。客户的TCP响应正常,而服务器也知道对方是正常的,服务器在两小时后将保活定时器复位。
客户主机已经崩溃,并且关闭或者正在重新启动。在任何一种情况下,客户的TCP都没有响应。服务端将不能收到对探测的响应,并在75秒后超时。服务器总共发送10个这样的探测 ,每个间隔75秒。如果服务器没有收到一个响应,它就认为客户主机已经关闭并终止连接。
客户主机崩溃并已经重新启动。服务器将收到一个对其保活探测的响应,这个响应是一个复位,使得服务器终止这个连接。
客户机正常运行,但是服务器不可达,这种情况与2类似,TCP能发现的就是没有收到探查的响应。
从上面可以看出,TCP保活功能主要为探测长连接的存活状况,不过这里存在一个问题,存活功能的探测周期太长,还有就是它只是探测TCP连接的存活,属于比较斯文的做法,遇到恶意的连接时,保活功能就不够使了。
在长连接的应用场景下,client端一般不会主动关闭它们之间的连接,Client与server之间的连接如果一直不关闭的话,会存在一个问题,随着客户端连接越来越多,server早晚有扛不住的时候,这时候server端需要采取一些策略,如关闭一些长时间没有读写事件发生的连接,这样可以避免一些恶意连接导致server端服务受损;如果条件再允许就可以以客户端机器为颗粒度,限制每个客户端的最大长连接数,这样可以完全避免某个蛋疼的客户端连累后端服务。
长连接和短连接的产生在于client和server采取的关闭策略,具体的应用场景采用具体的策略,没有十全十美的选择,只有合适的选择。
182、Java实现Socket长连接和短连接.
概念
Socket:socket实际上是对TCP/IP进行的封装,我们可以使用socket套接字通过socket来传输。首先我们需要明白的一个概念就是通道,简单地说通道就是两个对端可以随时传输数据的信道。我么常说的所谓建立socket连接,也就是建立了客户端与服务器端的通道。
长短连接:显而易见,长连接也就是这个socket连接一直保持连接,也就是通道一直保持通畅,两个对端可以随时发送和接收数据;短连接就是我们发送一次或有限的几次,socket通道就被关闭了。首先,我们必须明白的是socket连接后,如果没有任何一方关闭,这个通道是一直保持着的,换句话说,如果任何一方都不关闭连接,这个socket连接就是长连接,因此Java中的socket本身就是支持长连接的(如一个简单的实验:服务器端不关闭连接,服务器端每隔10秒发送一次数据,服务器端每次都能正确接受数据,这个实验就可以证明)。
那么既然socket本身是支持长连接的,那么为什么我们还要提短连接的概念呢?试想一个中国移动的短信网关(即通过发布socket通信接口)每时每分都有N多个连接发送短信请求,加入服务器不加任何限制地直接和客户端使用长连接那么可想而知服务器需要承受多么大的压力。所以一般的socket服务器端都是会设定超时时间的,也就是timeout,如果超过timeout服务器没有接收到任何数据,那么该服务器就会关闭该连接,从而使得服务器资源得到有效地使用。
如何实现长短连接
有了长短连接的概念,服务器如果超过timeout时间接收不到客户端的通信就会断开连接,那么假如客户端在timeout时间前一秒(或者更短的时间)发送一条激活数据来使服务器端重新计时,如此重复就能保证服务器一直不能进入timeout时间,从而一直保持连接,这就是长连接的实现原理。下面我们通过一张图说明:
由上图可见,是否是长连接完全取决于客户端是否会在timeout时间发送心跳消息,因此长短连接是和客户端相关的,服务器端没有任何区别(只不过服务器端需要设定timeout而已)。
183、适配器模式,装饰模式,代理模式异同(适配器模式和代理模式的区别答案在其中)。
适配器模式,一个适配允许通常因为接口不兼容而不能在一起工作的类工作在一起,做法是将类自己的接口包裹在一个已存在的类中。
装饰器模式,原有的不能满足现有的需求,对原有的进行增强。
代理模式,同一个类而去调用另一个类的方法,不对这个方法进行直接操作。
适配器的特点在于兼容,从代码上的特点来说,适配类与原有的类具有相同的接口,并且持有新的目标对象。就如同一个三孔转2孔的适配器一样,他有三孔的插头,可以插到三孔插座里,又有两孔的插座可以被2孔插头插入。适配器模式是在于对原有3孔的改造。在使用适配器模式的时候,我们必须同时持有原对象,适配对象,目标对象。
装饰器模式特点在于增强,他的特点是被装饰类和所有的装饰类必须实现同一个接口,而且必须持有被装饰的对象,可以无限装饰。
代理模式的特点在于隔离,隔离调用类和被调用类的关系,通过一个代理类去调用。
总的来说就是如下三句话:
1) 适配器模式是将一个类(a)通过某种方式转换成另一个类(b).
2) 装饰模式是在一个原有类(a)的基础之上增加了某些新的功能变成另一个类(b).
3) 代理模式是将一个类(a)转换成具体的操作类(b).
184、什么是可重入锁
见文章
185、volatile变量的两种特性。
可见性:volatile变量则是通过主内存完成交换,但是两者区别在于volatile变量能立即同步到主内存中,当一个线程修改变量的变量的时候,立刻会被其他线程感知到。
阻止重排序:普通变量仅仅会保证在该方法的执行过程中所依赖复制结果的地方都能获取到正确的结果,而不能保证变量复制操作的
顺序与程序代码中的执行顺序一致。
186、volatile变量详解
Volatile 变量具有 synchronized 的可见性特性,但是不具备原子特性。这就是说线程能够自动发现 volatile 变量的最新值。Volatile 变量可用于提供线程安全,但是只能应用于非常有限的一组用例:多个变量之间或者某个变量的当前值与修改后值之间没有约束。因此,单独使用 volatile 还不足以实现计数器、互斥锁或任何具有与多个变量相关的不变式(Invariants)的类(例如 “start <=end”)。此外,volatile 变量不会像锁那样造成线程阻塞,因此也很少造成可伸缩性问题。在某些情况下,如果读操作远远大于写操作,volatile 变量还可以提供优于锁的性能优势。
正确使用 volatile 变量的条件:
要使 volatile 变量提供理想的线程安全,必须同时满足下面两个条件:
对变量的写操作不依赖于当前值。
该变量没有包含在具有其他变量的不变式中。
这些条件表明,可以被写入 volatile 变量的这些有效值独立于任何程序的状态,包括变量的当前状态。
第一个条件的限制使 volatile 变量不能用作线程安全计数器。虽然增量操作(x++)看上去类似一个单独操作,实际上它是一个由读取-修改-写入操作序列组成的组合操作,必须以原子方式执行,而 volatile 不能提供必须的原子特性。实现正确的操作需要使 x 的值在操作期间保持不变,而 volatile 变量无法实现这点。(然而,如果将值调整为只从单个线程写入,那么可以忽略第一个条件。)
使用 volatile 变量的主要原因是其简易性:在某些情形下,使用 volatile 变量要比使用相应的锁简单得多。使用 volatile 变量次要原因是其性能:某些情况下,volatile 变量同步机制的性能要优于锁。
很难做出准确、全面的评价,例如 “X 总是比 Y 快”,尤其是对 JVM 内在的操作而言。(例如,某些情况下 VM 也许能够完全删除锁机制,这使得我们难以抽象地比较 volatile 和 synchronized 的开销。)就是说,在目前大多数的处理器架构上,volatile 读操作开销非常低 —— 几乎和非 volatile 读操作一样。而 volatile 写操作的开销要比非 volatile 写操作多很多,因为要保证可见性需要实现内存界定(Memory Fence),即便如此,volatile 的总开销仍然要比锁获取低。
volatile 操作不会像锁一样造成阻塞,因此,在能够安全使用 volatile 的情况下,volatile 可以提供一些优于锁的可伸缩特性。如果读操作的次数要远远超过写操作,与锁相比,volatile 变量通常能够减少同步的性能开销。
很多并发性专家事实上往往引导用户远离 volatile 变量,因为使用它们要比使用锁更加容易出错。然而,如果谨慎地遵循一些良好定义的模式,就能够在很多场合内安全地使用 volatile 变量。要始终牢记使用 volatile 的限制 —— 只有在状态真正独立于程序内其他内容时才能使用 volatile —— 这条规则能够避免将这些模式扩展到不安全的用例。
187、Sesson怎么创建和销毁。
当客户端发出第一个请求时(不管是被访问网站的任何页面)就会在此站点的服务其中开辟一块内存空间,这块内存就是session,session的销毁有两种方式,一种是session过期时间已到,会自动销毁(注意这里不是马上就会销毁,具体销毁时间由Tomcat容器所决定)。在我们项目中的web.xml中就可以配置:
<session-config>
<session-timeout>30session-timeout>
session-config>- 1
- 2
- 3
- 1
- 2
- 3
表示设置session过期时间为30分钟。值得注意的就是上面说的即使30分钟到了session不一定会马上销毁,可以通过session监听器测试得到每次session销毁的时间都不一样。如果要想安全的话就用下面第二种方法。在Tomcat的conf文件夹中的web.xml中可以找到Tomcat默认的session过期时间为30分钟。如果我们在我们的站点中配置了session过期时间Tomcat容器会以站点配置为主,如果我们没有在站点中配置session过期时间,将会以Tomcat下conf文件夹下的web.xml文件中配置的session过期时间为准。
第二种销毁方式通过手工方式销毁,这种销毁方式会立刻释放服务器端session的资源,我们手动销毁可以通过session().invalidate();实现。
188、“static”关键字是什么意思?Java中是否可以覆盖(override)一个private或者是static的方法?
“static”关键字表明一个成员变量或者是成员方法可以在没有所属的类的实例变量的情况下被访问。Java中static方法不能被覆盖,因为方法覆盖是基于运行时动态绑定的,而static方法是编译时静态绑定的。static方法跟类的任何实例都不相关,所以概念上不适用。
189、接口和抽象类的区别是什么?
Java提供和支持创建抽象类和接口。它们的实现有共同点,不同点在于:
1. 接口中所有的方法隐含的都是抽象的。而抽象类则可以同时包含抽象和非抽象的方法。
2. 类可以实现很多个接口,但是只能继承一个抽象类
3. 类如果要实现一个接口,它必须要实现接口声明的所有方法。但是,类可以不实现抽象类声明的所有方法,当然,在这种情况下,类也必须得声明成是抽象的。
4. 抽象类可以在不提供接口方法实现的情况下实现接口。
5. Java接口中声明的变量默认都是final的。抽象类可以包含非final的变量。
6. Java接口中的成员函数默认是public的。抽象类的成员函数可以是private,protected或者是public。
7. 接口是绝对抽象的,不可以被实例化。抽象类也不可以被实例化,但是,如果它包含main方法的话是可以被调用的。
190、在监视器(Monitor)内部,是如何做线程同步的?程序应该做哪种级别的同步?
监视器和锁在Java虚拟机中是一块使用的。监视器监视一块同步代码块,确保一次只有一个线程执行同步代码块。每一个监视器都和一个对象引用相关联。线程在获取锁之前不允许执行同步代码。
191、如何确保N个线程可以访问N个资源同时又不导致死锁?
使用多线程的时候,一种非常简单的避免死锁的方式就是:指定获取锁的顺序,并强制线程按照指定的顺序获取锁。因此,如果所有的线程都是以同样的顺序加锁和释放锁,就不会出现死锁了。
192、Java集合类框架的基本接口有哪些?
Java集合类提供了一套设计良好的支持对一组对象进行操作的接口和类。Java集合类里面最基本的接口有:
Collection:代表一组对象,每一个对象都是它的子元素。
Set:不包含重复元素的Collection。
List:有顺序的collection,并且可以包含重复元素。
Map:可以把键(key)映射到值(value)的对象,键不能重复
193、为什么集合类没有实现Cloneable和Serializable接口?
集合类接口指定了一组叫做元素的对象。集合类接口的每一种具体的实现类都可以选择以它自己的方式对元素进行保存和排序。有的集合类允许重复的键,有些不允许。克隆(cloning)或者是序列化(serialization)的语义和含义是跟具体的实现相关的。因此,应该由集合类的具体实现来决定如何被克隆或者是序列化。
193、Iterator和ListIterator的区别是什么?
下面列出了他们的区别:
Iterator可用来遍历Set和List集合,但是ListIterator只能用来遍历List。
Iterator对集合只能是前向遍历,ListIterator既可以前向也可以后向。
ListIterator实现了Iterator接口,并包含其他的功能,比如:增加元素,替换元素,获取前一个和后一个元素的索引,等等
194、快速失败(fail-fast)和安全失败(fail-safe)的区别是什么?
Iterator的安全失败是基于对底层集合做拷贝,因此,它不受源集合上修改的影响。java.util包下面的所有的集合类都是快速失败的,而java.util.concurrent包下面的所有的类都是安全失败的。快速失败的迭代器会抛出ConcurrentModificationException异常,而安全失败的迭代器永远不会抛出这样的异常。
195、Java中的HashMap的工作原理是什么?
Java中的HashMap是以键值对(key-value)的形式存储元素的。HashMap需要一个hash函数,它使用hashCode()和equals()方法来向集合/从集合添加和检索元素。当调用put()方法的时候,HashMap会计算key的hash值,然后把键值对存储在集合中合适的索引上。如果key已经存在了,value会被更新成新值。HashMap的一些重要的特性是它的容量(capacity),负载因子(load factor)和扩容极限(threshold resizing)。
196、hashCode()和equals()方法的重要性体现在什么地方?
Java中的HashMap使用hashCode()和equals()方法来确定键值对的索引,当根据键获取值的时候也会用到这两个方法。如果没有正确的实现这两个方法,两个不同的键可能会有相同的hash值,因此,可能会被集合认为是相等的。而且,这两个方法也用来发现重复元素。所以这两个方法的实现对HashMap的精确性和正确性是至关重要的。当equals()方法返回true时,两个对象必须返回相同的hashCode值,否则在HashMap中就会出错。
197、HashMap和Hashtable有什么区别?
HashMap和Hashtable都实现了Map接口,因此很多特性非常相似。但是,他们有以下不同点:
HashMap允许键和值是null,而Hashtable不允许键或者值是null。
Hashtable是同步的,而HashMap不是。因此,HashMap更适合于单线程环境,而Hashtable适合于多线程环境。
HashMap提供了可供应用迭代的键的集合,因此,HashMap是快速失败的。另一方面,Hashtable提供了对键的列举(Enumeration)。
一般认为Hashtable是一个遗留的类。
198、数组(Array)和列表(ArrayList)有什么区别?什么时候应该使用Array而不是ArrayList?
下面列出了Array和ArrayList的不同点:
Array可以包含基本类型和对象类型,ArrayList只能包含对象类型。
Array大小是固定的,ArrayList的大小是动态变化的。
ArrayList提供了更多的方法和特性,比如:addAll(),removeAll(),iterator()等等。
对于基本类型数据,集合使用自动装箱来减少编码工作量。但是,当处理固定大小的基本数据类型的时候,这种方式相对比较慢。
199、ArrayList和LinkedList有什么区别?
ArrayList和LinkedList都实现了List接口,他们有以下的不同点:
ArrayList是基于索引的数据接口,它的底层是数组。它可以以O(1)时间复杂度对元素进行随机访问。与此对应,LinkedList是以元素列表的形式存储它的数据,每一个元素都和它的前一个和后一个元素链接在一起,在这种情况下,查找某个元素的时间复杂度是O(n)。
相对于ArrayList,LinkedList的插入,添加,删除操作速度更快,因为当元素被添加到集合任意位置的时候,不需要像数组那样重新计算大小或者是更新索引。
LinkedList比ArrayList更占内存,因为LinkedList为每一个节点存储了两个引用,一个指向前一个元素,一个指向下一个元素。
200、Comparable和Comparator接口是干什么的?列出它们的区别。
Java提供了只包含一个compareTo()方法的Comparable接口。这个方法可以个给两个对象排序。具体来说,它返回负数,0,正数来表明输入对象小于,等于,大于已经存在的对象。
Java提供了包含compare()和equals()两个方法的Comparator接口。compare()方法用来给两个输入参数排序,返回负数,0,正数表明第一个参数是小于,等于,大于第二个参数。equals()方法需要一个对象作为参数,它用来决定输入参数是否和comparator相等。只有当输入参数也是一个comparator并且输入参数和当前comparator的排序结果是相同的时候,这个方法才返回true。
201、什么是Java优先级队列(Priority Queue)?
PriorityQueue是一个基于优先级堆的无界队列,它的元素是按照自然顺序(natural order)排序的。在创建的时候,我们可以给它提供一个负责给元素排序的比较器。PriorityQueue不允许null值,因为他们没有自然顺序,或者说他们没有任何的相关联的比较器。最后,PriorityQueue不是线程安全的,入队和出队的时间复杂度是O(log(n))。
.
202、Java集合类框架的最佳实践有哪些?
根据应用的需要正确选择要使用的集合的类型对性能非常重要,比如:假如元素的大小是固定的,而且能事先知道,我们就应该用Array而不是ArrayList。
有些集合类允许指定初始容量。因此,如果我们能估计出存储的元素的数目,我们可以设置初始容量来避免重新计算hash值或者是扩容。
为了类型安全,可读性和健壮性的原因总是要使用泛型。同时,使用泛型还可以避免运行时的ClassCastException。
使用JDK提供的不变类(immutable class)作为Map的键可以避免为我们自己的类实现hashCode()和equals()方法。
编程的时候接口优于实现。
底层的集合实际上是空的情况下,返回长度是0的集合或者是数组,不要返回null。
203、Enumeration接口和Iterator接口的区别有哪些?
Enumeration速度是Iterator的2倍,同时占用更少的内存。但是,Iterator远远比Enumeration安全,因为其他线程不能够修改正在被iterator遍历的集合里面的对象。同时,Iterator允许调用者删除底层集合里面的元素,这对Enumeration来说是不可能的。
204、HashSet和TreeSet有什么区别?
- HashSet是通过HashMap实现的,TreeSet是通过TreeMap实现的,只不过Set用的只是Map的key
- Map的key和Set都有一个共同的特性就是集合的唯一性.TreeMap更是多了一个排序的功能.
- hashCode和equal()是HashMap用的, 因为无需排序所以只需要关注定位和唯一性即可.
- a. hashCode是用来计算hash值的,hash值是用来确定hash表索引的.
- b. hash表中的一个索引处存放的是一张链表, 所以还要通过equal方法循环比较链上的每一个对象
才可以真正定位到键值对应的Entry. - c. put时,如果hash表中没定位到,就在链表前加一个Entry,如果定位到了,则更换Entry中的value,并返回旧value
- 由于TreeMap需要排序,所以需要一个Comparator为键值进行大小比较.当然也是用Comparator定位的.
- a. Comparator可以在创建TreeMap时指定
- b. 如果创建时没有确定,那么就会使用key.compareTo()方法,这就要求key必须实现Comparable接口.
- c. TreeMap是使用Tree数据结构实现的,所以使用compare接口就可以完成定位了.
HashSet是由一个hash表来实现的,因此,它的元素是无序的。add(),remove(),contains()方法的时间复杂度是O(1)。
另一方面,TreeSet是由一个树形的结构来实现的,它里面的元素是有序的。因此,add(),remove(),contains()方法的时间复杂度是O(logn)。
205、stop() 和 suspend() 方 法为何不推荐使用?
反对使用stop(),是因为它不安全。它会解除由线程获取的所有锁定,而且如果对象处于一种不连贯状态,那么其他线程能在那种状态下检查和修改它们。结果 很难检查出真正的问题所在。suspend()方法容易发生死锁。调用suspend()的时候,目标线程会停下来,但却仍然持有在这之前获得的锁定。此 时,其他任何线程都不能访问锁定的资源,除非被”挂起”的线程恢复运行。对任何线程来说,如果它们想恢复目标线程,同时又试图使用任何一个锁定的资源,就 会造成死锁。所以不应该使用suspend(),而应在自己的Thread类中置入一个标志,指出线程应该活动还是挂起。若标志指出线程应该挂起,便用wait()命其进入等待状态。若标志指出线程应当恢复,则用一个notify()重新启动线程。
206、当一个线程进入一个对象的一个 synchronized 方法后,其它线程是否可进入此对象的其它方法 ?
答:情况一:当一个线程进入一个对象的一个synchronized方法后,其它线程可以访问该对象的非同步方法。
情况二:当一个线程进入一个对象的一个synchronized方法后,其它线程不能访问该同步方法。
情况三:当一个线程进入一个对象的一个synchronized方法后,其它线程不能同时访问该对象的另一个同步方法。
207、接口:Collection
所有集合类的根类型,主要的一个接口方法:boolean add(Ojbect c)
虽返回的是boolean,但不是表示添加成功与否,因为Collection规定:一个集合拒绝添加这个元素,无论什么原因,都必须抛出异常,这个返回值表示的意义是add()执行后,集合的内容是否改了(就是元素有无数量、位置等变化)。类似的addAll,remove,removeAll,remainAll也是一样的。
用Iterator模式实现遍历集合
Collection有一个重要的方法:iterator(),返回一个Iterator(迭代子),用于遍历集合的所有元素。Iterator模式可以把访问逻辑从不同类的集合类中抽象出来,从而避免向客户端暴露集合的内部结构。
for(Iterator it = c.iterator(); it.hasNext();) {…}
不需要维护遍历集合的“指针”,所有的内部状态都有Iterator来维护,而这个Iterator由集合类通过工厂方法生成。
每一种集合类返回的Iterator具体类型可能不同,但它们都实现了Iterator接口,因此,我们不需要关心到底是哪种Iterator,它只需要获得这个Iterator接口即可,这就是接口的好处,面向对象的威力。
要确保遍历过程顺利完成,必须保证遍历过程中不更改集合的内容(Iterator的remove()方法除外),所以,确保遍历可靠的原则是:只在一个线程中使用这个集合,或者在多线程中对遍历代码进行同步。
208、JDBC:如何控制事务?
A: conn.setAutoCommit(false);
当值为false时,表示禁止自动提交。 在默认情况下,JDBC驱动程序会在每一个更新操作语句之后自动添加commit语句,如果调用了setAutoCommit(false),则驱动程序不再添加commit语句了。
B: conn.commit();
提交事务。即驱动程序会向数据库发送一个commit语句。
C: conn.rollback();
回滚事务。即驱动程序会向数据库发送一个rollback语句。
209、ArrayList总结:
-
ArrayList是基于数组实现的,是一个动态数组,其容量能自动增长,类似于C语言中的动态申请内存,动态增长内存。
-
ArrayList不是线程安全的,只能用在单线程环境下,多线程环境下可以考虑用Collections.synchronizedList(List l)函数返回一个线程安全的ArrayList类,也可以使用concurrent并发包下的CopyOnWriteArrayList类。
-
ArrayList实现了Serializable接口,因此它支持序列化,能够通过序列化传输,实现了RandomAccess接口,支持快速随机访问,实际上就是通过下标序号进行快速访问,实现了Cloneable接口,能被克隆。
-
无参构造方法构造的ArrayList的容量默认为10,带有Collection参数的构造方法,将Collection转化为数组赋给ArrayList的实现数组elementData。
-
ArrayList在每次增加元素(可能是1个,也可能是一组)时,都要调用该方法来确保足够的容量。当容量不足以容纳当前的元素个数时,就设置新的容量为旧的容量的1.5倍加1,如果设置后的新容量还不够,则直接新容量设置为传入的参数(也就是所需的容量),而后用Arrays.copyof()方法将元素拷贝到新的数组。
-
ArrayList基于数组实现,可以通过下标索引直接查找到指定位置的元素,因此查找效率高,但每次插入或删除元素,就要大量地移动元素,插入删除元素的效率低。
-
在查找给定元素索引值等的方法中,源码都将该元素的值分为null和不为null两种情况处理,ArrayList中允许元素为null。
210、CopyOnWriteArrayList
-
和ArrayList继承于AbstractList不同,CopyOnWriteArrayList没有继承于AbstractList,它仅仅只是实现了List接口。
-
ArrayList的iterator()函数返回的Iterator是在AbstractList中实现的;而CopyOnWriteArrayList是自己实现Iterator。
-
ArrayList的Iterator实现类中调用next()时,会“调用checkForComodification()比较‘expectedModCount’和‘modCount’的大小”;但是,CopyOnWriteArrayList的Iterator实现类中,没有所谓的checkForComodification(),更不会抛出ConcurrentModificationException异常!
-
CopyOnWriteArrayList不会抛ConcurrentModificationException,是因为所有改变其内容的操作(add、remove、clear等),都会copy一份现有数据,在现有数据上修改好,在把原有数据的引用改成指向修改后的数据。而不是在读的时候copy。
211、LinkedList总结
-
LinkedList是基于双向循环链表实现的,且头结点中不存放数据。除了可以当做链表来操作外,它还可以当做栈、队列和双端队列来使用。
-
LinkedList同样是非线程安全的,只在单线程下适合使用。
-
LinkedList实现了Serializable接口,因此它支持序列化,能够通过序列化传输,实现了Cloneable接口,能被克隆。
-
无参构造方法直接建立一个仅包含head节点的空链表,包含Collection的构造方法,先调用无参构造方法建立一个空链表,而后将Collection中的数据加入到链表的尾部后面。
-
在查找和删除某元素时,源码中都划分为该元素为null和不为null两种情况来处理,LinkedList中允许元素为null。
-
LinkedList是基于链表实现的,因此不存在容量不足的问题,所以这里没有扩容的方法。
-
找指定位置的元素时,先将index与长度size的一半比较,如果index
212、Vector总结
-
Vector也是基于数组实现的,是一个动态数组,其容量能自动增长。
-
Vector是JDK1.0引入了,它的很多实现方法都加入了同步语句,因此是线程安全的(其实也只是相对安全,有些时候还是要加入同步语句来保证线程的安全),可以用于多线程环境。
-
Vector没有实现Serializable接口,因此它不支持序列化,实现了Cloneable接口,能被克隆,实现了RandomAccess接口,支持快速随机访问。
-
Vector有四个不同的构造方法。无参构造方法的容量为默认值10,仅包含容量的构造方法则将容量增长量明置为0。
-
Vector在每次增加元素(可能是1个,也可能是一组)时,都要调用该方法来确保足够的容量。当容量不足以容纳当前的元素个数时,就先看构造方法中传入的容量增长量参数CapacityIncrement是否为0,如果不为0,就设置新的容量为就容量加上容量增长量,如果为0,就设置新的容量为旧的容量的2倍,如果设置后的新容量还不够,则直接新容量设置为传入的参数(也就是所需的容量),而后同样用Arrays.copyof()方法将元素拷贝到新的数组。
-
很多方法都加入了synchronized同步语句,来保证线程安全。
-
同样在查找给定元素索引值等的方法中,源码都将该元素的值分为null和不为null两种情况处理,Vector中也允许元素为null。
-
其他很多地方都与ArrayList实现大同小异,Vector现在已经基本不再使用。
HashMap总结 -
HashMap是基于哈希表实现的,每一个元素是一个key-value对,其内部通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。
-
HashMap是非线程安全的,只是用于单线程环境下,多线程环境下可以采用concurrent并发包下的concurrentHashMap。
-
HashMap 实现了Serializable接口,因此它支持序列化,实现了Cloneable接口,能被克隆。
-
HashMap共有四个构造方法。构造方法中提到了两个很重要的参数:初始容量和加载因子。这两个参数是影响HashMap性能的重要参数,其中容量表示哈希表中槽的数量(即哈希数组的长度),初始容量是创建哈希表时的容量(如果不指明,则默认为16),加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度,当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 resize 操作(即扩容)。如果加载因子越大,对空间的利用更充分,但是查找效率会降低(链表长度会越来越长);如果加载因子太小,那么表中的数据将过于稀疏(很多空间还没用,就开始扩容了),对空间造成严重浪费。如果我们在构造方法中不指定,则系统默认加载因子为0.75,这是一个比较理想的值,一般情况下我们是无需修改的。另外,无论指定的容量为多少,构造方法都会将实际容量设为不小于指定容量的2的次方的一个数,且最大值不能超过2的30次方。每次扩容也是扩大两倍,也就是容量总是2的幂次方。
-
HashMap中key和value都允许为null。
-
key为null的键值对永远都放在以table[0]为头结点的链表中,当然不一定是存放在头结点table[0]中。如果key不为null,则先求的key的hash值,根据hash值找到在table中的索引,在该索引对应的单链表中查找是否有键值对的key与目标key相等,有就返回对应的value,没有则返回null。
213、Hashtable总结
-
Hashtable同样是基于哈希表实现的,同样每个元素是一个key-value对,其内部也是通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。
-
Hashtable也是JDK1.0引入的类,是线程安全的,能用于多线程环境中。
-
Hashtable同样实现了Serializable接口,它支持序列化,实现了Cloneable接口,能被克隆。
-
HashTable在不指定容量的情况下的默认容量为11,而HashMap为16,Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂。
-
Hashtable中key和value都不允许为null,而HashMap中key和value都允许为null(key只能有一个为null,而value则可以有多个为null)。但是如果在Hashtable中有类似put(null,null)的操作,编译同样可以通过,因为key和value都是Object类型,但运行时会抛出NullPointerException异常,这是JDK的规范规定的。
-
Hashtable扩容时,将容量变为原来的2倍加1,而HashMap扩容时,将容量变为原来的2倍。
-
Hashtable计算hash值,直接用key的hashCode(),而HashMap重新计算了key的hash值,Hashtable在求hash值对应的位置索引时,用取模运算,而HashMap在求位置索引时,则用与运算,且这里一般先用hash&0x7FFFFFFF后,再对length取模,&0x7FFFFFFF的目的是为了将负的hash值转化为正值,因为hash值有可能为负数,而&0x7FFFFFFF后,只有符号外改变,而后面的位都不变。
214、TreeMap总结
-
TreeMap是基于红黑树实现的。
-
TreeMap是根据key进行排序的,它的排序和定位需要依赖比较器或覆写Comparable接口,也因此不需要key覆写hashCode方法和equals方法,就可以排除掉重复的key,而HashMap的key则需要通过覆写hashCode方法和equals方法来确保没有重复的key。
-
TreeMap的查询、插入、删除效率均没有HashMap高,一般只有要对key排序时才使用TreeMap。
-
TreeMap的key不能为null,而HashMap的key可以为null。
215、LinkedHashMap总结
-
LinkedHashMap是HashMap的子类,与HashMap有着同样的存储结构,但它加入了一个双向链表的头结点,将所有put到LinkedHashmap的节点一一串成了一个双向循环链表,因此它保留了节点插入的顺序,可以使节点的输出顺序与输入顺序相同。
-
LinkedHashMap可以用来实现LRU算法。
-
LinkedHashMap同样是非线程安全的,只在单线程环境下使用。
-
LinkedHashMap中加入了一个head头结点,将所有插入到该LinkedHashMap中的Entry按照插入的先后顺序依次加入到以head为头结点的双向循环链表的尾部。
-
LinkedHashMap由于继承自HashMap,因此它具有HashMap的所有特性,同样允许key和value为null。
-
源码中的accessOrder标志位,当它false时,表示双向链表中的元素按照Entry插入LinkedHashMap到中的先后顺序排序,即每次put到LinkedHashMap中的Entry都放在双向链表的尾部,这样遍历双向链表时,Entry的输出顺序便和插入的顺序一致,这也是默认的双向链表的存储顺序;当它为true时,表示双向链表中的元素按照访问的先后顺序排列,可以看到,虽然Entry插入链表的顺序依然是按照其put到LinkedHashMap中的顺序,但put和get方法均有调用recordAccess方法(put方法在key相同,覆盖原有的Entry的情况下调用recordAccess方法),该方法判断accessOrder是否为true,如果是,则将当前访问的Entry(put进来的Entry或get出来的Entry)移到双向链表的尾部(key不相同时,put新Entry时,会调用addEntry,它会调用creatEntry,该方法同样将新插入的元素放入到双向链表的尾部,既符合插入的先后顺序,又符合访问的先后顺序,因为这时该Entry也被访问了),否则,什么也不做。
-
构造方法,前四个构造方法都将accessOrder设为false,说明默认是按照插入顺序排序的,而第五个构造方法可以自定义传入的accessOrder的值,因此可以指定双向循环链表中元素的排序规则,一般要用LinkedHashMap实现LRU算法,就要用该构造方法,将accessOrder置为true。
-
LinkedHashMap是如何实现LRU的。首先,当accessOrder为true时,才会开启按访问顺序排序的模式,才能用来实现LRU算法。我们可以看到,无论是put方法还是get方法,都会导致目标Entry成为最近访问的Entry,因此便把该Entry加入到了双向链表的末尾(get方法通过调用recordAccess方法来实现,put方法在覆盖已有key的情况下,也是通过调用recordAccess方法来实现,在插入新的Entry时,则是通过createEntry中的addBefore方法来实现),这样便把最近使用了的Entry放入到了双向链表的后面,多次操作后,双向链表前面的Entry便是最近没有使用的,这样当节点个数满的时候,删除的最前面的Entry(head后面的那个Entry)便是最近最少使用的Entry。
216、ThreadLocal原理
首先,ThreadLocal 不是用来解决共享对象的多线程访问问题的,一般情况下,通过ThreadLocal.set() 到线程中的对象是该线程自己使用的对象,其他线程是不需要访问的,也访问不到的。各个线程中访问的是不同的对象。
另外,说ThreadLocal使得各线程能够保持各自独立的一个对象,并不是通过ThreadLocal.set()来实现的,而是通过每个线程中的new 对象 的操作来创建的对象,每个线程创建一个,不是什么对象的拷贝或副本。通过ThreadLocal.set()将这个新创建的对象的引用保存到各线程的自己的一个map中,每个线程都有这样一个map,执行ThreadLocal.get()时,各线程从自己的map中取出放进去的对象,因此取出来的是各自自己线程中的对象,ThreadLocal实例是作为map的key来使用的。
如果ThreadLocal.set()进去的东西本来就是多个线程共享的同一个对象,那么多个线程的ThreadLocal.get()取得的还是这个共享对象本身,还是有并发访问问题。
ThreadLocal不是用来解决对象共享访问问题的,而主要是提供了保持对象的方法和避免参数传递的方便的对象访问方式。归纳了两点:
-
每个线程中都有一个自己的ThreadLocalMap类对象,可以将线程自己的对象保持到其中,各管各的,线程可以正确的访问到自己的对象。
-
将一个共用的ThreadLocal静态实例作为key,将不同对象的引用保存到不同线程的ThreadLocalMap中,然后在线程执行的各处通过这个静态ThreadLocal实例的get()方法取得自己线程保存的那个对象,避免了将这个对象作为参数传递的麻烦。
如果要把本来线程共享的对象通过ThreadLocal.set()放到线程中也可以,可以实现避免参数传递的访问方式,但是要注意get()到的是那同一个共享对象,并发访问问题要靠其他手段来解决。但一般来说线程共享的对象通过设置为某类的静态变量就可以实现方便的访问了,似乎没必要放到线程中。
ThreadLocal的应用场合,我觉得最适合的是按线程多实例(每个线程对应一个实例)的对象的访问,并且这个对象很多地方都要用到。
ThreadLocal类中的变量只有这3个int型:
private final int threadLocalHashCode = nextHashCode();
private static int nextHashCode = 0;
private static final int HASH_INCREMENT = 0x61c88647;- 1
- 2
- 3
- 1
- 2
- 3
而作为ThreadLocal实例的变量只有threadLocalHashCode 这一个,nextHashCode 和HASH_INCREMENT 是ThreadLocal类的静态变量,实际上HASH_INCREMENT是一个常量,表示了连续分配的两个ThreadLocal实例的threadLocalHashCode值的增量,而nextHashCode 的表示了即将分配的下一个ThreadLocal实例的threadLocalHashCode 的值。
创建一个ThreadLocal实例即new ThreadLocal()时做了哪些操作,从构造函数ThreadLocal()里看什么操作都没有,唯一的操作是这句:
private final int threadLocalHashCode = nextHashCode();
nextHashCode()做了什么呢:
private static synchronized int nextHashCode() {
int h = nextHashCode;
nextHashCode = h + HASH_INCREMENT;
return h;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
就是将ThreadLocal类的下一个hashCode值即nextHashCode的值赋给实例的threadLocalHashCode,然后nextHashCode的值增加HASH_INCREMENT这个值。
因此ThreadLocal实例的变量只有这个threadLocalHashCode,而且是final的,用来区分不同的ThreadLocal实例,ThreadLocal类主要是作为工具类来使用,那么ThreadLocal.set()进去的对象是放在哪儿的呢?
看一下上面的set()方法,两句合并一下成为
ThreadLocalMap map = Thread.currentThread().threadLocals;- 1
- 1
这个ThreadLocalMap 类是ThreadLocal中定义的内部类,但是它的实例却用在Thread类中:
public class Thread implements Runnable {
......
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
......
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
再看这句。
if (map != null)
map.set(this, value);- 1
- 2
- 1
- 2
也就是将该ThreadLocal实例作为key,要保持的对象作为值,设置到当前线程的ThreadLocalMap 中,get()方法同样类似。
217、Static Nested Class 和 Inner Class的不同?
1 创建一个static内部类的对象,不需要一个外部类对象。创建一个非static内部类必须要一个外部类对象
2 不能从一个static内部类的一个对象访问一个外部类对象,可以从一个非static内部类访问其外部类对象。如OutterClassName.this进行访问。
218、当你在浏览器输入一个网址,比如http://www.taobao.com,按回车之后发生了什么?请从技术的角度描述,如浏览器、网络(UDP,TCP,HTTP等),以及服务器等各种参数与对象上由此引发的一系列活动。请尽可能的涉及到所有的关键技术点。
答案:答题角度有以下几个DNS域名查找,负载均衡,HTTP协议格式,HTTP下一层的TCP协议,服务器应该返回的各种网络的应答。
1、通过访问的域名找出其IP地址。DNS查找过程如下:
浏览器缓存:浏览器会缓存DNS记录,并存放一段时间。
系统缓存:如果浏览器缓存中没有找到需要的记录,浏览器会做一个系统调用。
路由器缓存:接着前面的查询请求发向路由器,它一般会有自己的DNS缓存。
ISP DNS缓存:接下来要check的就是ISP缓存的DNS服务器,在这一般都能找到相应的缓存记录
递归搜索:你的ISP的DNS服务器从根域名服务器开始进行递归搜索,从.com顶级域名服务器到叶节点服务器。
2、上述这种域名解析的方式似乎只能解析出一个ip,我们知道一般的大型网站都有好几个ip地址,这种问题如何解决?还好,有几种方法可以消除这个瓶颈:
轮叫调度(round-robin DNS):是DNS查找时返回多个IP时的解决方案。举例来说,Facebook.com实际上就对应了四个IP地址。
负载均衡:是以一个特定IP地址进行侦听并将网络请求转发到集群服务器上的硬件设备。一些大型的站点一般都会使用这种昂贵的高性能负载均衡
地理DNS:根据用户所处的地理位置,通过把域名映射到多个不同的IP地址提高可扩展性。这样不同的服务器不能够更新同步状态,但映射静态内容的话非常好。
Anycast:是一个IP地址映射多个物理主机的路由技术。美中不足,Anycast与TCP协议适应的不是很好,所以很少应用在那些方案中。大多数DNS服务器使用Anycast来获得高效低延迟的DNS查找。
3、浏览器给Web服务器发送一个Http请求
这里可以回答的更详细一点:比如说http协议的格式,http请求的头,比如说发起一个Get类型请求。
4、服务器给浏览器响应一个301永久重定向响应
为什么要有这一步,原因之一是为了便于搜索引擎优化
5、浏览器跟中重定向地址
这个时候浏览器已经知道了正确的URL地址,于是重新发送一个Get请求,请求头中的URL为重定向之后的。
6、服务器处理请求
Web服务器软件:web服务器软件(IIS和Apatch)介绍到Http请求,然后确定执行什么请求处理来处理它。请求处理就是一个能够读懂请求并且能生成HTML来进行相应的程序
请求处理:请求处理阅读请求及它的参数和cookies。它会读取也可能更新一些数据,并将数据存储在服务器上。然后,需求处理会生成一个HTML响应。
7、服务器发回一个HTML响应
8、浏览器开始渲染这个HTML
9、浏览器发送获取嵌入在HTML中的资源对象请求
一些嵌入在html中的资源,比如说图片,js,css等等
10、浏览器发送异步(AJAX)请求
在web2.0时代,在页面渲染成功之后,浏览器依然可以跟服务器进行交互,方法就是通过这个异步请求AJAX
下面这个答案说的尽管跟这道题目关系不大,但是很有意思。所以还是给出来:
你打开了www.taobao.com,这时你的浏览器首先查询DNS服务器,将www.taobao.com转换成ip地址。不过首先你会发现,你在不同的地区或者不同的网络(电信,联通,移动)的情况下,转换后的ip地址很可能是不一样的,这首先涉及到负载均衡的第一步,通过DNS解析域名时将你的访问分配到不同的入口,同时尽可能保证你所访问的入口是所有入口中可能较快的一个。
你通过这个入口成功的访问了www.taobao.com的实际的入口ip地址。这时你产生了一个PV,即Page View,页面访问。每日每个网站的总PV量是形容一个网站规模的重要指标。淘宝网全网在平日(非促销期间)的PV大概是16-25亿之间。同时作为一个独立的用户,你这次访问淘宝网的所有页面,均算作一个UV(Unique Visitor用户访问)。
因为同一时刻访问www.taobao.com的人数过于巨大,所以即便是生成淘宝首页页面的服务器,也不可能仅有一台。仅用于生成www.taobao.com首页的服务器就有可能有成百上千台,那么你的一次访问时生成页面给你看的任务便会被分配给其中一台服务器完成。这个过程要保证公平公正(也就是说这成百上千台服务器每台负担的用户数要差不多),这一很复杂的过程是由几个系统配合完成,其中最关键的便是LVS,Linux Virtual Server,世界上最流行的负载均衡系统之一。
经过一系列复杂的逻辑运算和数据处理,用于这次给你看的淘宝网的首页的HTML内容便生成成功了,对Web前端稍微有点常识的童鞋都应该知道,下一步浏览器会去加载页面中用到的css,js,图片等样式,脚本和资源文件。但是可能相对较少的同学才会知道,你的浏览器在同一个域名下并发加载的资源数量是有限制的,例如ie6-7是两个,ie8是6个,chrome个版本不大一样,一般是4-6个。我刚刚看了一下,我访问的淘宝网首页需要加载126个资源,那么如此小的并发连接数自然会加载很久。所以前端开发人员往往会将上述的这些资源文件分布在好多个域名下,变相的绕过浏览器的这个限制,同时也为下文的CDN工作做准备。
据不可靠消息,在双十一当天高峰,淘宝的访问流量达到最巅峰达到871GB/S。这个数字意味着需要178万个4mb带宽的家庭带宽才能负担的起,也完全有能力拖垮一个中小城市的全部互联网带宽。那么显然,这些访问流量不可能集中在一起。并且大家都知道,不同地区不同网络(电信,联通等)之间互访会非常缓慢,但是你却发现很少发现淘宝网访问缓慢。这便是CDN,Content Delivery Network,即内容分发网络的作用。淘宝在全国各地建立了上百个CDN节点,利用一些手段保证你的访问的(这里主要指js、css、图片等)地方是离你最近的CDN节点,这样便保证了大流量分散已经在各地访问的加速。
这便出现了一个问题,那就是假如一个卖家发布了一个新宝贝,上传了几张新的宝贝图片,那么淘宝网如何保证全国各地的CDN节点中都会同步的存在这几张图片供用户使用呢?这里边就涉及到大量的内容分发与同步的相关技术。淘宝开发了分布式文件系统TFS来处理这类问题。
219、进程间通信的方法主要有以下几种:
-
管道(Pipe):管道可用于具有亲缘关系进程间的通信,允许一个进程和另一个与它有共同祖先的进程之间进行通信。
-
命名管道(named pipe):命名管道克服了管道没有名字的限制,因此,除具有管道所具有的功能外,它还允许无亲缘关系进程间的通信。命名管道在文件系统中有对应的文件名。命名管道通过命令mkfifo或系统调用mkfifo来创建。
-
信号(Signal):信号是比较复杂的通信方式,用于通知接受进程有某种事件发生,除了用于进程间通信外,进程还可以发送信号给进程本身;linux除了支持Unix早期信号语义函数sigal外,还支持语义符合Posix.1标准的信号函数sigaction(实际上,该函数是基于BSD的,BSD为了实现可靠信号机制,又能够统一对外接口,用sigaction函数重新实现了signal函数)。
-
消息(Message)队列:消息队列是消息的链接表,包括Posix消息队列system V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺
-
共享内存:使得多个进程可以访问同一块内存空间,是最快的可用IPC形式。是针对其他通信机制运行效率较低而设计的。往往与其它通信机制,如信号量结合使用,来达到进程间的同步及互斥。
-
内存映射(mapped memory):内存映射允许任何多个进程间通信,每一个使用该机制的进程通过把一个共享的文件映射到自己的进程地址空间来实现它。
-
信号量(semaphore):主要作为进程间以及同一进程不同线程之间的同步手段。
-
套接字(Socket):更为一般的进程间通信机制,可用于不同机器之间的进程间通信。起初是由Unix系统的BSD分支开发出来的,但现在一般可以移植到其它
类Unix系统上:Linux和System V的变种都支持套接字。而在java中我们实现多线程间通信则主要采用”共享变量”和”管道流”这两种方法
- 方法一 通过访问共享变量的方式(注:需要处理同步问题)
- 方法二 通过管道流
其中方法一有两种实现方法,即
- 通过内部类实现线程的共享变量
- 通过实现Runnable接口实现线程的共享变量
210、什么是trie树(单词查找树、字典树)?
1.Trie树 (特例结构树)
Trie树,又称单词查找树、字典树,是一种树形结构,是一种哈希树的变种,是一种用于快速检索的多叉树结构。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
Trie树也有它的缺点,Trie树的内存消耗非常大.当然,或许用左儿子右兄弟的方法建树的话,可能会好点.
2. 三个基本特性:
-
1)根节点不包含字符,除根节点外每一个节点都只包含一个字符。
-
2)从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
-
3)每个节点的所有子节点包含的字符都不相同。
3 .说明:和二叉查找树不同,在trie树中,每个结点上并非存储一个元素。trie树把要查找的关键词看作一个字符序列。并根据构成关键词字符的先后顺序构造用于检索的树结构。在trie树上进行检索类似于查阅英语词典。 一棵m度的trie树或者为空,或者由m棵m度的trie树构成。
查找分析
在trie树中查找一个关键字的时间和树中包含的结点数无关,而取决于组成关键字的字符数。而二叉查找树的查找时间和树中的结点数有关O(log2n)。
如果要查找的关键字可以分解成字符序列且不是很长,利用trie树查找速度优于
二叉查找树。如:
若关键字长度最大是5,则利用trie树,利用5次比较可以从26^5=11881376个可能的关键字中检索出指定的关键字。而利用二叉查找树至少要进行 次比较。
trie树的应用:
- 字符串检索,词频统计,搜索引擎的热门查询。
- 字符串最长公共前缀。
- 排序。
- 作为其他数据结构和算法的辅助结构。如后缀树,AC自动机等。
221、在25匹马中,挑出速度最快的3匹。每场比赛只能有5马一起跑。所需要的最少比赛次数是多少
至少7次
先分为5组,每组5匹。
首先全部5组分别比赛;
其次,每组的第一名进行第六次比赛:这样可淘汰最后两名及其所在组的全部马匹(共10匹),同时可淘汰第三名所在组排名靠后的其余4匹马,以及第二名所在组的排名最后的3匹,再加上第一名所在小组的最后2名,共计淘汰19名,同时产生25匹中的冠军(即本轮的第一名)。
最后,剩余的5匹进行第7次比赛,前两名为25匹中的亚军和季军。
转自:http://blog.csdn.net/derrantcm/article/details/46658823