Linux:信号的处理
文章目录
- 信号处理
本篇总结的是关于信号的处理
信号处理
在之前有这样的观点:信号在合适的时候被处理好,当进程收到信号后,当前进程可能在做优先级更高的事,所以它来不及处理这个信号,那么就会把这个信号暂时保存起来,在后续需要进行处理这个信号的时候,就会对这个信号进行处理,那么现在的问题是,它是要在什么时候进行处理?这个合适的时候是值什么时候?
通俗来说,这个合适的时候指的是从内核态返回用户态的时候,这个过程中进行信号的检测和处理
对于信号的处理,用户可能会定义有对应的自定义方法,自定义方法的存储位置就在用户空间内,而对应的进程控制块,pending表,还有handler表等等内容,这些数据结构都是在操作系统中进行存储的,未来对于进程来说,上述内容都是进程中的一部分,而和这些内容相关的代码存储位置并不在用户空间中,所以在未来的代码执行中,可能会执行到和这些内容相关的时候,就会需要进入操作系统内部,之后操作系统内部把重要的事处理结束之后,返回的时候,就会从内核态切换为用户态,而在这个过程中就会对信号进行检测,去查看处理的结果是什么结果,这里想突出的一点是,信号的处理是一个宏观的过程,它本质上是从内核态返回到用户态,从而进行信号的检测和处理
用下图来简单表示这个过程
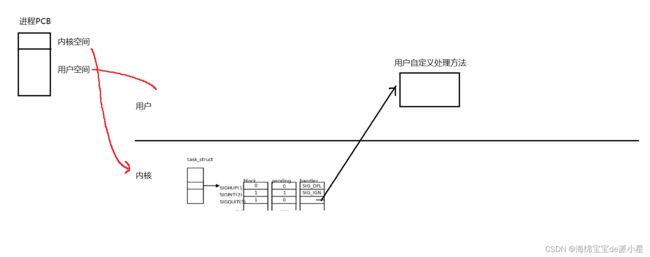
有了上面的初步结论,先引入第一个问题,关于用户态和内核态的问题
用户态和内核态
- 用户态是一种受控的状态,能够访问的资源是有限的
- 内核态是一种操作系统的工作状态,能够访问大部分系统资源
对于用户态来说,在进行一些操作的时候会有权限约束,这就表现出了一定的受控,同时从代码的角度来讲,在访问野指针空指针等等内容的时候会报错,其实这也是一种权限受限的问题,操作系统不允许用户访问某些区域,这就叫做用户是处于一种受控的状态
对于内核态来说,内核态是一种操作系统,可以理解为让操作系统处于一种操作系统级别的工作状态,能够访问系统中的绝大部分资源,由此又引出了系统调用的概念,在日常的使用库函数中,绝大部分其实内部都封装了系统调用,只要涉及到对于硬件的访问,就必然会有封装底层的系统调用,这是毋庸置疑的,只有操作系统才有资格对于硬件进行操作,所以在日常使用的大部分的操作系统,其实都是借助系统调用来进行使用的,而在系统调用这个层次其实就包含了一定的身份变化
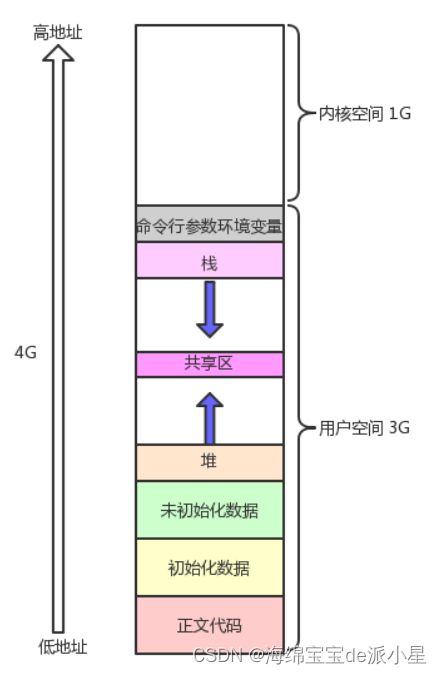
还是沿用之前的这张图,从这张图中可以看出,每一个进程都有一个对应的地址空间,其中分成0-3GB这个空间以及3-4GB这个空间,这两个空间分别对应的就是用户空间和内核空间,在之前的内容中也有过这样的基础,大部分讲述的都是对于用户空间的使用,比如有动态库的加载,以及其他的变量定义和代码调用,大多都是在用户空间进行跳转,而又由于这是虚拟地址空间,所以对应的用户空间和页表等对于每一个进程来说都要私有一份,这是用户空间的定义
但是对于内核空间来说,就有些不一样了,例如操作系统是需要提前加载的,操作系统的代码和数据加载要更早一些,操作系统的内部也有各种的代码和跳转的,例如有进程管理内存管理等等,那么操作系统也有对应的数据,并且操作系统对于资源的管理基本都是用数据来体现的,所以操作系统中必定会有相当庞大的数据
所以问题就来了,CPU是如何对于操作系统中的这些代码和数据有认识的?其实每一个进程都有对应的用户空间,用户空间的内容是私有的,但是对于内核空间来说,却是公共的,内核级别的页表其实只需要一张就足够了,所有进程对于操作系统的代码也都是共享的,数据也是共享的,只需要一个内核级的页表,就能把虚拟地址的内容和物理地址建立一个映射,所以这个过程非常简单,而CPU就可以直接通过虚拟地址和内核页表进行映射,进而找到操作系统的代码和数据,而每一个进程的内核空间都是一样的,因为都是由操作系统来管理的,所以不管如何进行进程的切换,CPU访问操作系统的位置都是一样的,所以CPU可以随时任意的找到操作系统
那前面有这样的知识基础,操作系统的驱动,其实就是借助一些硬件,通过CPU来执行时钟中断,最后找到中断对应的处理方法,就有了一个调度的方法,这也就是相当于完成了一个调度,那么本质上来说操作系统就是一个死循环,这也就意味着当进行时钟中断的时候,CPU可以直接通过当前进程对应的地址空间,快速的找到操作系统进行代码的执行,那么也就意味着,系统可以在硬件层面上随时随地的找到操作系统,这就是上述要得出的一个结论
总结一下前面的结论:
- 用户态只能访问0-3GB空间,而内核态可以让用户以操作系统的身份访问其余空间内的内容
- 无论进程如何调度,CPU可以直接访问操作系统中的代码和数据
- 所有代码的执行都可以在地址空间的方式进行函数的调用和返回
- 操作系统内部提供了一些重要的方法集,就叫做系统调用,不管是如何进行代码跳转,本质上都是在进程自己的地址空间内进行的跳转,所以在软件层面上,地址空间内可以来回跳转,就可以快速的实现从正文到任何地方,从代码的任何位置到自己想要跳转的地方
- 跳转的位置大概有共享区和内核区,其中对于内核区的跳转会涉及到权限约束的问题
内核态和用户态如何标识?
前面只说,内核态可以做什么,用户态不能做什么,但是这有什么用呢?操作系统是如何认识到这一点的,它是如何知道现在是处于什么状态呢?
结论是回归到CPU的硬件上,在CPU的硬件上伴随着有对应的工作级别,操作系统本身是一个软硬件结合起来设计的一款软件,那么在其本质上,是CPU内存中存在寄存器,其中主要包含有CR系列寄存器和CS系列寄存器
代码段寄存器(Code Segment Register):
CS:代码段寄存器,存储了当前代码段的段选择子。在x86架构中,CS寄存器是一个16位的寄存器,用于存储代码段的段选择子,其中包括段的基地址和访问权限等信息。CS寄存器的内容在不同特权级别下有不同的值,用于指示CPU当前执行的代码所处的特权级别
所以不管怎么说,用户态还是内核态,其实本质就是借助两个比特位进行身份的识别,而这样的识别机制在很多种情况下都被广泛的使用和借鉴
控制寄存器(Control Registers):
CR0:控制处理器的运行模式和特性。其中的一位(位0)用于控制保护模式(Protected Mode)和实模式(Real Mode)之间的切换。当该位被设置为1时,处理器处于保护模式,可以使用分段和分页机制,允许多任务处理和内存保护等特性;当该位被清除为0时,处理器处于实模式,不支持分段和分页,是最初的x86处理器模式
CR3:页目录基址寄存器(Page Directory Base Register),用于存储页目录的物理地址,用于虚拟地址到物理地址的转换
CR4:包含了一系列处理器特性的标志位,如页大小、物理地址扩展等
CR3寄存器是用来保存当前进程的页表信息的,比如现在CPU内部是如何知道当前进程的位置和页表的呢?其实,都是有对应的寄存器来保存的,比如说这个CR3寄存器中保存的就是用户级的页表,而这个当中存储的数据,其实本质上就是物理地址,这样做的目的就是为了快速找到页表的物理地址,进而通过这个机制找到页表中
操作系统是最早启动的软件,所以操作系统可以加载到物理内存的最低处,这也就使得可以很方便的快速找到操作系统中的代码和数据
但是在自己的地址空间中,代码用到的地址都是虚拟地址,而CPU真正读取到的地址是物理地址,所以CPU才会进行虚拟地址到物理地址的转换,也就是MMU这个硬件,这个硬件就是专门负责进行转换的,一旦转换完成之后,CPU中拿到的就是物理地址了,就可以进行访问对应的代码和数据了
CR2寄存器:当访问地址空间中的一个地址不存在的时候,操作系统就会触发缺页中断,而触发了缺页中断后就会重新开辟和申请物理内存,建立新的映射,当内存重新申请建立映射关系之后,当用户重新访问历史上曾经引发缺页中断的这个地址,那这个地址就被存储在这个寄存器中,再比如说当访问程序遇到野指针的时候,在进行debug遇到野指针的时候,会提示访问到野指针,提示当前地址是不可以被写入的,为什么会提示呢?因为这个地址一旦被访问,它所访问的目标地址就不存在,不存在就会有缺页中断,而此时会发现这个地址不能被归属于缺页中断的范畴中,而是用户的这次访问属于非法访问,所以就直接报错了,操作系统向目标进程发送信号,发送信号后进程要终止,但是终止的原因也是需要知道的,所以就让当前对应的系统去读取CR2寄存器,里面保存的就是引发异常的地址,这样就能看到因为访问哪个地址所以导致异常了
本质上有了上述的概念,对于系统调用,本质上就进入到3-4GB这个范围的地址空间内,但是操作系统是如何识别到可以让一个不明身份的人进入操作系统级别的地址空间?本质上就是有寄存器上的两个比特位的帮助,如果要将用户态切换到内核态,就把对应的比特位从3换成0即可,就完成了用户内核态的转变
用户内核态转变的细节问题
用户态和内核态的转变,必然不是随便进行转变的,在执行到系统调用的时候,就相当于是要在系统调用的起始地点来进行用户到内核态的转换
CPU有针脚这样的结构,它可以使得CPU可以接收各种各样的外部中断,那么收到了对应的外部中断后,就有对应的中断号,再结合对应的中断号去找中断向量表,即可执行对应的函数方法,这套过程是硬件帮助完成的,而最终执行的工作肯定是由软件完成,但整个这一套的接收信息处理等等,实际上是由硬件驱动软件来完成的,在CPU的工作模式中,除了一些能够接受外部的中断,还有一些来自内部的中断,这些来自内部的中断就叫做陷阱,实际上CPU内部有各种各样的例如int类型的指令,这些指令有对应的中断号,而其中的部分指令就负责了对身份的转变
所以回到最开始的问题,信号是在什么时候被处理的?其实就是从内核态返回到用户态的时候会进行检测,当准备进行返回的时候,又会有一次从内核态到用户态的转变,而检测到对应的信号后,首先要对pending位图进行标记,其次在合适的时候要对信号进行处理了,要看这个信号对应的block表是否被阻塞,如果没有阻塞就在这个时候执行对应的handler方法,对信号进行处理
系统调用和用户库函数
在之前的使用中,将open/fork这些都归为是系统调用,其实也并不是,在底层也是封装过才有的这些函数,真正的底层函数其实是sys_fork()等
综上,有了上面的这些理论基础,就可以画出下面的这个信号捕捉流程图:

信号的捕捉流程大致就是如上所示的流程,如图所示,当操作系统执行结束一个内核级的任务,处理结束之后在返回的过程中就要进行信号的检测,紧接着就是执行用户的自定义的捕捉方法,执行结束之后就可以返回到用户态了,以红线为界,上面是用户态,下面是内核态,在这之间一共会涉及到四次状态转换,每一次切换都是寄存器中数据的改变,进而引起权限改变,最终导致的是当前工作模式的状态变换
sigaction函数

上述是sigaction函数的相关信息,这个函数的作用主要是可以读取和修改与指定信号相关联的处理动作,它本质上也是一种和signal一样的函数,只是可以掌控的信息更多