C++笔记:string 类的模拟实现
文章目录
- 一、string 类的成员变量
- 二、string 类的成员函数
-
- 1. 构造、析构、与输出
-
- 构造
- 析构
- 遍历相关的访问接口
-
- size + operator
- 迭代器:begin + end
- 插入元素与扩容
-
- reserve + capacity
- push_back
- append
- operator+=
- insert
- 删除元素 erase + npos
- 查找元素 find
- 获取子串 + 拷贝构造 + 赋值重载
- swap + 拷贝构造和赋值重载的现代写法
- 重载流插入与流提取
- 容量相关接口:empty 和 resize
- 字符串比较:运算符重载
- 模拟实现的全部代码
首先创建两个文件:
string.h用于实现 string 类。test.cpp用于测试 string 类的接口。
一、string 类的成员变量
库中的 string 是一个管理字符数组的顺序表,可以通过提供的接口对数组进行增删查改,所以自己实现的 string 的成员变量应该要有一个指向字符数组的指针、一个记录当前有效字符长度的变量、一个记录当前字符数组可容纳的最大有效字符个数的变量,它们都是私有的,类外不许直接访问。
为了不与库中的 string 类发生冲突,自己实现的 string 类会放到自定义命名空间
ljh中。
string 类初步设计如下:
namespace ljh
{
class string
{
public:
// ...
private:
char* _str; // 指向字符数组的指针
size_t _size; // 记录当前有效字符长度
size_t _capacity;// 记录可容纳最大有效字符个数
};
}
二、string 类的成员函数
模拟实现是为了更好的了解 string 的细节,所以只会选择实现库中的 string 类的常用接口,不会全部实现;此外,有些成员函数的实现会调用C语言库中的相关字符串函数,不会直接手搓。(
#include);实现的顺序不会严格按照库中对成员函数的分类。
1. 构造、析构、与输出
要能够创建一个对象,销毁对象时能够对象内部的资源空间,对于创建的对象能够初步获取对象内部的资源。
构造
string 类中最常用的构造函数有两个,一是无参构造函数;二是类型为 const char* 的单参数构造函数。
无参构造函数
无参构造函数的结果是一个空 string 对象,即 _size 为0、capacity 为0,那 _str 是 nullptr 吗?
先来看看库里是怎么实现的
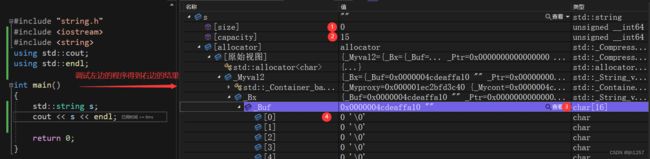
左边的代码很简单,就是调用库里的无参构造函数构造一个对象,而调试之后得到的结果就很有意思了。
- 对象
s的size为 0,这不出意料。 - 对象
s的capacity是 15,这个也没有什么大问题,C++标准没有对构造时字符数组该开辟多大空间做出规定,具体的实现得看编译器本身。 - 有意思的来了,
capacity是 15,但是看具体的空间大小时却发现字符数组实际开辟了16个字节大小的空间,这是为什么?
其实前面有指出过,“capacity指的是当前字符数组可容纳的最大的有效字符的个数 ”,而不是字符数组的实际大小,比capacity多开一个字节是为了给 C++ 字符串对象预留一个空字符 (即\0) 的位置,这也是为了遵循 C 语言中字符串的约定。 - 可以看到,下标为 0 的位置放的是
\0,所以我们设计的无参构造_str不应该是nullptr;
但是有个疑问,会不会是编译器多开空间的缘故?
库里有个函数const char* c_str() const;它的作用是返回 const 修饰的_str
仔细想一下就可以知道,自己实现的版本中,此时s.c_str是nullptr,而流提取 (cout) 在输出字符串时会将指针解引用,这时候就恍然大悟了,崩溃的原因在于 对nullptr解引用。
因此,哪怕是空 string 对象,其_str也不是nullptr,最低限度也是一个1字节的字符数组,里面放了一个\0。
综上所述,无参构造函数暂时如下:
string()
{
_size = 0;
_capacity = _size;
_str = new char('\0');
}
类型为 const char* 的单参数构造函数
一个C语言的常量字符串会被编译器理解为 const char* 类型,因此类型为 const char* 的单参数构造函数就是拷贝常量字符串然后构造一个新的 string 对象。
首先,我们的选择方案就有两种:一是初始化列表;二是函数体内赋值。
假设选择初始化列表,我们来看看这样能不能实现:
string(const char* str)
: _str(str)
{}
很遗憾,答案是不能。
str的类型为const char*,_str的类型为char*,首先二者类型不一致,其次const对象赋值给非const对象属于权限扩大的行为,权限只能平移或者缩小,但是不能扩大,所以会编译报错。
如果把_str改成const char*倒是能够初始化了,但是这是个扯淡的行为,这样子还怎么进行增删查改了,这个行为很显然和模拟实现的预期不符。
那改成下面这个版本是不是可以完成构造了:
string(const char* str)
: _size(strlen(str))
, _capacity(_size)
, _str(new char[_capacity + 1])
{ strcpy(_str, str); }
答案是,也不一定。初始化列表有一点容易被我们忽略,初始化列表的初始化顺序是严格按照成员变量的声明顺序执行的,如果按照上面成员变量声明的设计顺序来说,一定会出问题。的确,如果成员变量的声明顺序调整为
_size、_capacity、_str可以解决 bug,但是这个程序的容错率是不是太低了?
定义时一定要用初始化列表赋初值的成员变量有以下三种:1. 引用成员变量;2. const成员变量;3. 自定义类型成员(且该类没有默认构造函数时)。而_size、_capacity、_str这三个成员变量很明显不属于必要的范畴,而且使用初始化列表不仅不会有很大的性能提升,反而会带来一堆坑,所以,选择用初始化列表的方式来实现这个构造函数显然不合适。
接下来,选用函数体内赋值的形式来编写的代码如下:
string(const char* str)
{
_size = strlen(str);
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
构造函数进展到这里就写好了吗?
答案是否定的,我们来思考一个问题,“无参构造和类型为 const char* 的单参数构造函数有必要分开写吗?”
对于 string s; 这句代码,编译器会自动调用默认构造函数,什么是默认构造函数——我们不写编译器自己生成的构造函数、无参构造函数、全缺省构造函数。
无参构造的坑就在于,即使看起来使空的 string 的,它也是有内容的,所以能不能考虑给单参数构造函数加一个缺省值,缺省值为 "",它会被自动解释 const char* 类型,正好类型匹配,而且也是默认构造函数了,一石二鸟!
根据上面思路,最终版的构造函数实现如下:
string(const char* str = "")
{
_size = strlen(str);
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
析构
对于内置类型来说,析构函数不用显式地写出来,写出来了也没有什么意义,但是对于类中存在动态分配的资源,即如果在类的构造函数或成员函数中使用了 new、malloc 或其他分配内存的方法来动态分配资源(如堆内存、文件句柄等),则需要编写析构函数来释放这些资源,以避免内存泄漏或资源泄漏。
析构函数实现如下:
~string()
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
遍历相关的访问接口
上面已经创建好的对象还要能够做到对其内部的数组元素一一遍历,这个实现的就是遍历相关的成员函数。
size + operator
前面提到过,遍历 string 有三种方法,第一种就是 “ 下标 + [] ”。
下面是调用库里的接口进行遍历,接下来要自己实现接口完成一样的功能。
int main() {
std::string s("abcdef");
for (size_t i = 0; i < s.size(); ++i) {
cout << s[i] << " ";
}
// 输出:a b c d e f
return 0;
}
既然要用下标来遍历,就要知道起始和结束的下标,C语言中还要调用 strlen 来获取,但是 string 类有 _size。虽然 _size 无法直接访问,但是可以用一个接口来获取,size() 就是这个接口。
通过上面的思考可以得到 size() 的实现如下:
size_t size()
{
return _size;
}
学习 string 类时,我们将它理解为字符数组,这么一想,s 用 [] 能够遍历数组内容是不是没什么毛病 (s[i])?但是仔细想想的话,s是数组吗?它不是。那它怎么使用 [] ?答案是通过 string 类内部实现的 operator[] 运算符重载成员函数来模拟数组操作。
[] 的作用是能够访问甚至修改下标指向的元素,operator[] 函数需要接收一个参数来接收下标,然后返回一个值,修改这个值要能够影响数组内部的元素,这么想的话,返回值类型应该是引用类型。
根据上面思考,operator[] 的模拟实现如下:
char& operator[](size_t index)
{
// 断言确保index是一个合法下标,要包头文件 cassert
// = 表示 对 象征结束的 \0 进行访问修改也是合规的
assert(index <= _size);
return _str[index];
}
那么上面设计的函数就没有问题了吗?
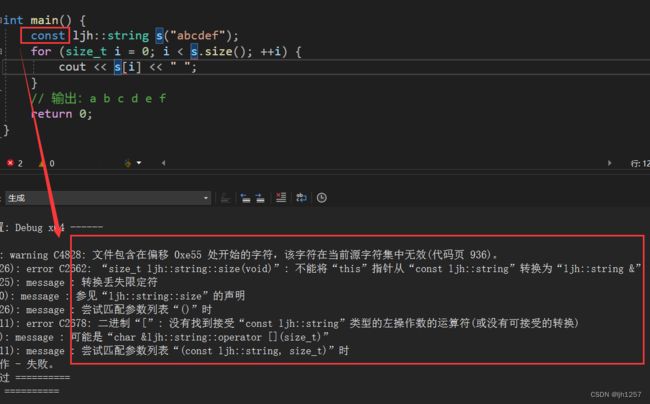
我们看到仅仅是用 const 修饰了一下就报了一堆错误,所以接下就排错过程,来看一下是哪里出错或者说哪里做的不够好。
被 const 修饰后,s 的类型从 string 转成成 const string,
&s 得到的指针的类型从 string* 转成成 const string*,
对于成员函数,它们都有一个隐藏的第一参数,this 指针,目前来说 size()、operator[] 的 this 指针都是 string* 类型的,传参的时候 const 变量赋值给非 const 变量会导致权限放大,这就是导致报错的根本原因!
因此,operator[] 需要重载一个 const 版本,但是 size() 需要重载吗?答案是不需要的,那直接用回原来那个?那个也不行,一开始已经明确了,成员 _size 是不允许直接访问的,上面实现的 size() 还有一个缺点就是,函数里面可以修改成员 _size,这是一个隐患,函数就会返回一个错误的 _size,所以最好的做法就是,成员函数 size() 一开始就设计成 const 版本就好了。
最终的operator[]、size()设计如下:
char& operator[](size_t index)
{
assert(index <= _size);
return _str[index];
}
const char& operator[](size_t index) const
{
assert(index <= _size);
return _str[index];
}
size_t size() const
{
return _size;
}
现在对于两个版本写的程序都能够很好的执行了。

迭代器:begin + end
遍历 string 的三种方法之其二 “ 迭代器 ”。
老规矩,先来看看直接调用库里的接口是如何遍历的:

虽然不完全了解迭代器的本质原理,但是这里认识到 iterator、const_iterator 是 string 类里提供的两个类型就足够了。
begin() 的作用是返回指向第一个字符的迭代器,end() 的作用是返回指向结束字符的迭代器,根据该迭代器可以访问到 _str 的元素,根据上面的例子看到,两个函数每个函数根据迭代器类型不同都要重载成两个版本,共计4个成员函数。
这里选用指针的方式实现迭代器底层:
public:
// 定义类型iterator、const_iterator
typedef char* iterator;
typedef const char* const_iterator;
// 定义四个成员函数
iterator begin()
{
return _str;
}
const_iterator begin() const
{
return _str;
}
iterator end()
{
return _str + _size;
}
const_iterator end() const
{
return _str + _size;
}

其实 string 类的迭代器的底层就是这么简单,有没有迭代器看起来很高大上实际也就那样的感觉?至少在这里是的。
这里只对正向迭代器做了模拟实现,库里还有反向迭代器,但是它们都是类似,模拟实现的目的是了解底层实现,突破知识的神秘面纱,所以迭代器就到这里了。
插入元素与扩容
截至目前,现有接口能够做到创建、销毁、遍历,但是字符数组的增删查改接口也只有 “改” 的 operator[]。
接下来模拟实现库中常用的添加内容 的接口,有尾插一个字符的 push_back、有尾插一段字符串的 append、任意位置插入任意长度字符串的 insert、还有最常用的 operator+=。
但是不断往容器里添加内容,容器终归是要满的,所以插入接口绕不开的一个话题就是 “ 扩容 ”。
reserve + capacity
库里有一个函数:void reserve (size_t n = 0);,它的作用是改变_str指向的数组的 _capacity,当 n > _capacity 时,作用为扩容,新的_capacity 大于等于 n;当 n < _capacity 时,标准只规定了不得影响字符长度,_capacity的变化得具体看编译器的实现,个人实现为了减少麻烦,采用不缩容的操作。
实现如下:
void reserve(size_t n = 0)
{
// n > _capacity 才扩容,否则不进行任何操作
if (n > _capacity)
{
char* temp = new char[n + 1];
strcpy(temp, _str);
delete[] _str;
_str = temp;
_capacity = n;
}
}
注意:char* temp = new char[n + 1]; 中的 n+1 十分值得注意,n 和 _capacity 一样都指的是最多可容纳的有效字符个数,而实际的容量要比 _capacity 至少大1。
实现了这个接口之后,再实现返回当前字符数组容量的capacity(),这两个函数配合测试看实现是否有问题。
返回字符数组容量的函数capacity()的模拟实现如下:
size_t capacity() const
{
return _capacity;
}
对比运行结果如下(没看过源码不知道VS是怎么实现的,但是预期目标已经达成):
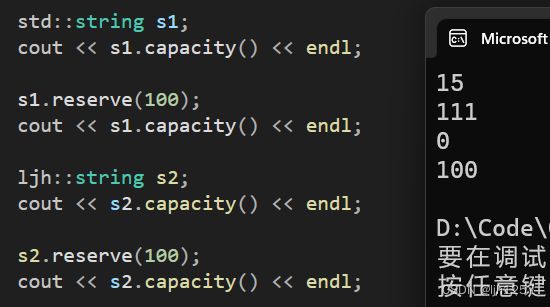
接下来改模拟实现的元素插入相关接口的扩容操作就可以直接复用 reserve() 了。
push_back
push_back() 的作用很简单就是尾插一个字符。
void push_back(char c)
{
// 一个一个插入是不会有 _size > _capacity 的情况出现的
if (_size == _capacity)
{
size_t newCapacity = _capacity == 0 ? 16 : _capacity * 2;
reserve(newCapacity);
}
_str[_size++] = c;
_str[_size] = '\0';
}
注意: 这里扩容采取的是2倍扩容的做法,这种写法下有个情况需要额外处理,就是 空 string 对象(即_capacity == 0),0的2倍依旧是0,所以要给一定的初始值,参考上面提到的VS2022初始容量为15的情况下,这里设置为16。
append
append() 的作用尾插一段字符串。
这个与 push_back() 的实现是类似的,同样也需要扩容,但插入的字符串的长度是未知,所以就需要判断插入之后的 _size 会不会越界,会就扩容,扩容之后再将字符串拷贝进来就可以了。
尾部插入一段字符串的函数模拟实现如下:
void append(const char* str)
{
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
strcpy(_str + _size, str);
_size += len;
}
operator+=
这里要实现的 operator+=() 有两个版本,一是 += 一个字符c,一个是 += 一个字符串,这里的实现非常简单就是复用上面写好的两个接口。
// += 字符c
string& operator+=(char c)
{
push_back(c);
return *this;
}
// += 字符串str
string& operator+=(const char* str)
{
append(str);
return *this;
}
接下来就是验证了,如果两个+=函数没有问题,那么上面两个函数也没有问题了。
成功编译,成功运行,验证成功!

insert
insert() 这里要模拟实现两个版本,分别是任意未知插入一个字符和任意位置插入一个字符串。
首先来实现插入一个字符,这个其实不难,只要先挪动数据将位置腾出来然后再插入即可。
第一版本代码实现如下:
string& insert(size_t index, char c)
{
// 保证下标要规范
assert(0 <= index && index <= _size);
// 容量检测
if (_size == _capacity)
{
size_t newCapacity = _capacity == 0 ? 16 : _capacity * 2;
reserve(newCapacity);
}
// 挪动数据进行插入
size_t end = _size;
while (end >= index)
{
_str[end + 1] = _str[end];
--end;
}
_str[index] = c;
++_size;
return *this;
}
测试发现程序有bug
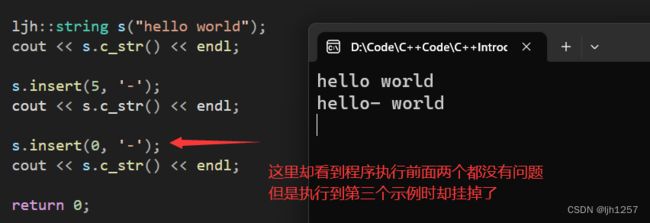
程序分析发现问题

按照平时应该是这样子的,会这么认为的都是下意识的把
end当作了int类型的变量,但是很遗憾,这里的end是无符号整型,当end永远不可能是负数,也就是说如果在下标为0的位置插入一个字符就会造成死循环。
既然 end 是 size_t 不行,那把 end 改成 int 类型那不就可以了吗?
针对第一版本的 end 的改动如下:int end = _size;
然而运行之后发现依旧是死循环,这次没办法只能走调试,得到结果如下:

其实这次错误的根源依旧是在类型上面,在 C/C++ 中,双目运算符的左右操作数的类型不一致时,会发生类型提升,是指将较低级别的操作数转换成较高级别的操作数的过程。
那还怎么改?将 end 和 index 都改成 int ?其实也不用,会发生bug就是因为end最后会越界而已,只要保证end不会越界那就没事了。
最后的模拟实现如下:
string& insert(size_t index, char c)
{
// 保证下标要规范
assert(0 <= index && index <= _size);
// 容量检测
if (_size == _capacity)
{
size_t newCapacity = _capacity == 0 ? 16 : _capacity * 2;
reserve(newCapacity);
}
// 挪动数据进行插入
for (size_t end = _size + 1; end > index; --end)
{
_str[end] = _str[end - 1];
}
_str[index] = c;
++_size;
return *this;
}
这次测试正常执行!
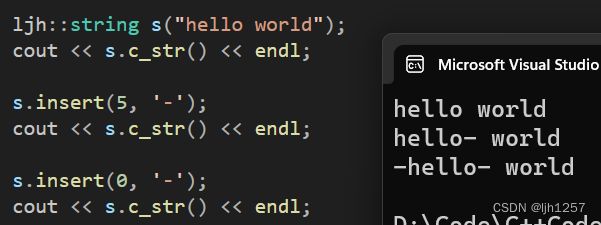
接下来模拟实现任意位置插入一个字符串的。
有了上面数据挪动的教训,这里就不会犯错了。插入一个字符串和插入一个字符的区别在于插入一个字符是需要向后挪动一个位置,插入一个字符串需要向后挪动待插入字符串长度的位置。
模拟实现如下:
string& insert(size_t index, const char* str)
{
// 保证下标要规范
assert(0 <= index && index <= _size);
// 容量检测
size_t len = strlen(str);
if (_size + len > _capacity)
{
size_t newCapacity = _capacity == 0 ? 16 : _capacity * 2;
reserve(newCapacity);
}
// 挪动数据插入字符串
for (size_t end = _size + len; end > index; --end)
{
_str[end] = _str[end - len];
}
strncpy(_str + index, str, len);
_size += len;
return *this;
}
测试结果:
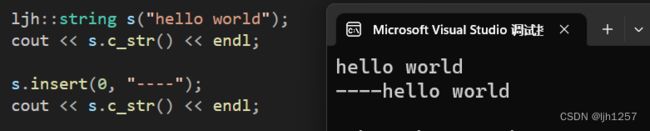
删除元素 erase + npos
有任意位置的插入函数,自然不能缺少任意位置的删除函数,库里的 erase() 的声明如下:string& erase (size_t pos = 0, size_t len = npos);。
这时候就开始好奇了,npos 是什么?
库里给出的说明是,“ npos 是一个静态成员常量值,具有 size_t 类型元素的最大可能值 ”,它的声明是这样的,static const size_t npos = -1;,直接用这个声明编译,可以通过,但是疑问来了。
- “ 声明为static的类成员称为类的静态成员,用static修饰的成员变量,称之为静态成员变量,静态成员变量只能类内声明、类外定义 ”,库里的声明明显与这个有冲突。
- 前面也提到了,对于
const修饰的成员在定义的之后一定要给一个值,作为初始化列表的参数,可是这里的模拟实现不采取初始化列表的方式,按道理来说,编译会报错,可神奇的是,编译成功通过了。
所以 static const size_t npos = -1; 到底算是声明还是定义?
经过查证,这个只能说是一种特殊处理,仅支持整型,C++委员会为了方便定义出来的(个人表示挠头)。
模拟实现如下:
string& erase(size_t index = 0, size_t len = npos)
{
// 保证下标合法
assert(0 <= index && index <= _size);
if (len == npos || len + index >= _size)
{
_str[index] = '\0';
_size = index;
}
else
{
strcpy(_str + index, _str + index + len);
_size -= len;
}
return *this;
}
len == npos || len + index >= _size 这个条件里面,len + index >= _size 看着好像可以覆盖 len == npos,可是为什么还要特地分开写?
这是因为,当 len 接近 npos 时,len + index 就会溢出,会导致删除出现异常。
改成
len + index >= _size后测试删除下标为5及其后面的字符,但是却出现了奇怪的结果:

查找元素 find
查找元素这里模拟实现库中的 find(),主要有两个版本:
size_t find(char c, size_t index = 0) const
size_t find(const char* s, size_t index = 0) const
默认从下标为0的位置开始查找,找到返回下标,找不到npos。
查找字符c的模拟实现如下:
size_t find(char c, size_t index = 0) const
{
for (size_t i = index; i < _size; ++i)
{
if (_str[i] == c)
{
return i;
}
}
return npos;
}
查找字符串的模拟实现如下:
size_t find(const char* s, size_t index = 0) const
{
const char* ptr = strstr(_str + index, s);
if (ptr == nullptr)
{
return npos;
}
else
{
return ptr - _str;
}
}
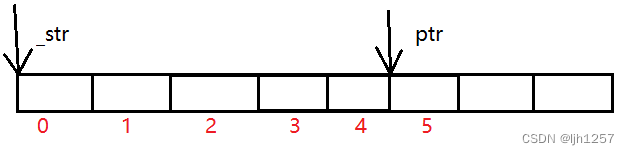
ptr - _str比较有意思的地方是这里,strstr函数找到后不会返回下标,而是字符串在原数组当中的起始位置的地址,通过两个地址怎么知道下标?
其实,下标更准确说法是 “ 偏移量 ”,_str向右偏移五个字节能够找到ptr,那反过来,ptr - _str为什么不能得到偏移量?
模拟实现函数的实际验证如下:

获取子串 + 拷贝构造 + 赋值重载
库中的 substr() 的作用是返回一个新构造的对象,其值初始化为此对象的子字符串的副本,子字符串是对象的一部分,它从字符位置开始并跨越字符(或直到字符串的末尾,以先到者为准)。
库的声明如下:
string substr (size_t pos = 0, size_t len = npos) const;
根据参数的不同,拷贝的边界也有所不同,主要有三种情况:
len = npos,从pos开始拷贝到\0。len大于等于pos后面字符的长度,从pos开始拷贝到\0。len小于pos后面字符的长度,从pos开始拷贝到pos + len的位置。
模拟实现如下:
string substr(size_t index = 0, size_t len = npos) const
{
// 保证下标合法
assert(index < _size);
// 确定边界
size_t end = index + len;
if (len == npos || index + len >= _size)
{
end = _size;
}
// 新对象插入数据
string s;
s.reserve(end - index);
for (size_t i = index; i < end; ++i)
{
s += _str[i];
}
return s;
}
模拟实现测试运行结果:

我们看到程序运行崩溃了,这是为什么?
使用调试一步一步运行代码,可以看到新建对象 s 的确成功插入数据,但是程序为什么崩溃了呢? 
在我们的直观感觉上,s 应该会被返回,然后被 main 函数的 s2 接收,然而问题就在这里。

本来应该是临时对象将内容返回给主函数的s2的,但是由于临时对象是调用拷贝构造函数生成的,但是拷贝构造函数先前没有写,这里用了编译器自动生成的拷贝构造函数,它的拷贝是浅拷贝,最后当函数栈帧销毁时,临时对象指向的数组的内容(s._str)由于析构函数被回收了,临时对象拷贝给s2之后也要调用析构函数,还要对本来不存在的数组再一次进行回收(s._str)。
所以程序崩溃的原因就是由于浅拷贝导致的同一块空间被析构两次。
这里要做的事情就是去把拷贝构造和赋值重载给完善好。
拷贝构造和赋值重载的模拟实现如下:
// 拷贝构造
string(const string& s)
{
_str = new char[s._capacity + 1];
_capacity = s._capacity;
_size = s._size;
strcpy(_str, s.c_str());
}
// 赋值重载
string& operator=(const string& s)
{
// 避免 s = s
if (this != &s)
{
// 释放旧空间
delete[] _str;
// 建立新空间
char* temp = new char[s._capacity + 1];
// 指向新空间
_str = temp;
strcpy(_str, s._str);
_capacity = s._capacity;
_size = s._size;
}
return *this;
}
然后再次测试原来的代码,测试结果如下:

swap + 拷贝构造和赋值重载的现代写法
上面提到的拷贝构造和赋值重载的实现方式是传统的实现方式,这两个成员函数还有一种现代写法,现代写法主要是靠 swap() 成员函数来实现的。
交换是将两个对象的内容进行交换,但是这个实现起来其实非常简单,只需要同时该边两个对象的_str指针指向的内容即可,而且C++库里提供了一个swap函数的函数模板,可供直接调用,但是使用是要包含头文件(#include )。
swap() 的模拟实现如下:
void swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
基于成员函数 swap() 实现的现代写法:
string(const string& s)
{
string temp(s.c_str()); // 构造
swap(temp); // this->swap(temp);
}
string& operator=(string s)
{
swap(s); // this->swap(temp);
return *this;
}
这个写法的精髓在于压榨编译器!
我们之前的写法可以说是我们亲历亲为,新空间我们自己开的,旧空间我们自己释放的,数据改动也是我们自己改的,但是现在不同了,任劳任怨的编译器帮我们全干了。
不过现在这个写法还有个缺点,就是拷贝构造时用新对象的空间换走了 temp 的空间,但是新对象什么都没有,这个容易引发析构时出现错误。
因此,为了保险,这里把成员变量的缺省值都给加上,这样就可以保证,构造的新对象一开始都会被初始化成以下内容。
private:
char* _str = nullptr;
size_t _size = 0;
size_t _capacity = 0;
重载流插入与流提取
库里的 string 类可以直接使用流提取和流插入直接输入和输出,十分便捷,但是目前为止,个人自己实现的 string 类里只能够调用 c_str() 输出,也无法做到自由输入,所以接下来就重载流插入和流提取这两个函数。
为了保证流插入对象和流提取对象作为第一参数,这两个函数重载成员全局函数而非类的成员函数,声明如下。
std::ostream& operator<<(std::ostream& _cout, const string& s);
std::istream& operator>>(std::istream& _cin, string& s);
流提取的功能十分简单,就是遍历数组内容然后输出,上面提到了遍历有两种方法,1. 是下标+[];2. 是迭代器;这里选用迭代器来实现。
最终模拟实现的代码如下:
ostream& operator<<(ostream& _cout, const string& s)
{
auto it = s.begin();
while (it != s.end())
{
_cout << *it;
++it;
}
return _cout;
}
相交于流插入的简单,流提取就有许多要注意的东西了
- 输入的 string 对象内容可以已经有内容,需要提前清空。
- 流提取默认在遇到空格或者换行时就会停止,换言之,流提取不会读取空格或者换行,因此,读取空格或者换行要使用 get() 函数。
- 一个字符一个字符地读取,当输入字符数量大时,需要多次扩容,这会带来不必要的消耗,因此自定义一个buffer数组来作为缓冲区,当buffer数组满了或者循环退出才将数据插入给对象。
// 清空 string 对象内容
void clear()
{
_size = 0;
_str[_size] = '\0';
}
// 流提取重载
istream& operator>>(istream& _cin, string& s)
{
s.clear();
char ch = _cin.get();
char buffer[128] = { 0 };
int i = 0;
while (ch != ' ' && ch != '\n')
{
if (i == 127)
{
s += buffer;
i = 0;
}
buffer[i++] = ch;
ch = _cin.get();
}
if (i > 0)
{
buffer[i] = '\0';
s += buffer;
}
return _cin;
}
容量相关接口:empty 和 resize
成员函数 empty 的作用非常简单,就是判断当前 string 的长度(_size)是否为0
bool empty() const
{
return _str[0] == '\0' ? true : false;
}
而 resize 可以修改当前 string 的 _size。
void resize (size_t n, char c = '\0');
n <= _size时,保留前 n 个字符;_size < n <= _capacity时,尾插n - _size个字符 c;_capacity < n时,扩容到 n,同时新开辟的空间全部初始化为字符 c;
实现如下:
void resize(size_t n, char ch = '\0')
{
if (n <= _size)
{
_str[n] = '\0';
_size = n;
}
else
{
if (n > _capacity)
reserve(n);
for (size_t i = _size; i < n; i++)
{
_str[i] = ch;
}
_size = n;
_str[n] = '\0';
}
}
字符串比较:运算符重载
bool operator>(const string& s)
{
return strcmp(_str, s._str) > 0;
}
bool operator==(const string& s)
{
return strcmp(_str, s._str) == 0;
}
bool operator!=(const string& s)
{
return !(*this == s);
}
bool operator<=(const string& s)
{
return !(*this > s);
}
bool operator>=(const string& s)
{
return ((*this > s) || (*this == s));
}
bool operator<(const string& s)
{
return !((*this > s) || (*this == s));
}
模拟实现的全部代码
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1 // VS下用C语言库函数要加这一句
#include