人脸追踪案例及机器学习认识
1.人脸追踪机器人初制
用程序控制舵机运动的方法与机械臂项目完全相同。 由于摄像头的安装方式为上下倒转安装,我们在编写程序读取图像时需使用 flip 函数将图像上下翻转。
由于摄像头的安装方式为上下倒转安装,我们在编写程序读取图像时需使用 flip 函数将图像上下翻转。 现在,只需要使用哈尔特征检测得到人脸在图像中的位置,再指示舵机运动,进行追踪即可。由于一次只能追踪一张人脸,我们可以在 detectMultiScale 函数中使用 cv2.CASCADE_FIND_BIGGEST_OBJECT(寻找最大的人脸位置)作为 flags 参数的值。
现在,只需要使用哈尔特征检测得到人脸在图像中的位置,再指示舵机运动,进行追踪即可。由于一次只能追踪一张人脸,我们可以在 detectMultiScale 函数中使用 cv2.CASCADE_FIND_BIGGEST_OBJECT(寻找最大的人脸位置)作为 flags 参数的值。 该程序段中,faces 虽然仍是一个元组,但由于只有一张人脸,其长度始终为 1,因此 for 循环至多只会遍历一次。循环中,通过左上角坐标和宽、高,即可以计算出人脸所在位置的中心坐标。当摄像头正对人脸时,人脸位置的中心坐标应该在整个图像的正中,即(320, 240) 位置。要实现对人脸的实时追踪,只需要让图像中的人脸始终趋于图像正中心即可,即始终让 人脸中心坐标(x0, y0)向 (320, 240) 靠近。 当图像中人脸中心 x 坐标大于 320 时,说明人脸在图像中的右侧,云台应向左转;反 之云台应向右转(注意,我们的摄像头是倒置安装的,flip 函数只将图像的上下翻转了过来, 左右还是反的)。当图像中人脸中心 y 坐标大于 240 时,说明人在图像中的下方,云台应 向下转;反之云台应向上转。控制舵机转向的方式和控制机械臂找物体位置的方式类似,需根据人脸的实时坐标对两个舵机的 PWM 值进行增减。若用 pwm1 和 pwm2 分别表示两个舵机的 PWM 值,则可以这样编写程序:
该程序段中,faces 虽然仍是一个元组,但由于只有一张人脸,其长度始终为 1,因此 for 循环至多只会遍历一次。循环中,通过左上角坐标和宽、高,即可以计算出人脸所在位置的中心坐标。当摄像头正对人脸时,人脸位置的中心坐标应该在整个图像的正中,即(320, 240) 位置。要实现对人脸的实时追踪,只需要让图像中的人脸始终趋于图像正中心即可,即始终让 人脸中心坐标(x0, y0)向 (320, 240) 靠近。 当图像中人脸中心 x 坐标大于 320 时,说明人脸在图像中的右侧,云台应向左转;反 之云台应向右转(注意,我们的摄像头是倒置安装的,flip 函数只将图像的上下翻转了过来, 左右还是反的)。当图像中人脸中心 y 坐标大于 240 时,说明人在图像中的下方,云台应 向下转;反之云台应向上转。控制舵机转向的方式和控制机械臂找物体位置的方式类似,需根据人脸的实时坐标对两个舵机的 PWM 值进行增减。若用 pwm1 和 pwm2 分别表示两个舵机的 PWM 值,则可以这样编写程序: 但每次都调整一个固定值,效果并不理想:若调整值取值太大,容易在中心附近发生剧烈的晃动;若调整值取值太小,当人脸远离中心时,调整速度又太慢。为了解决这一问题,一个较简单的方法是让每次的调整值与实际坐标偏离中心的幅度成正比。
但每次都调整一个固定值,效果并不理想:若调整值取值太大,容易在中心附近发生剧烈的晃动;若调整值取值太小,当人脸远离中心时,调整速度又太慢。为了解决这一问题,一个较简单的方法是让每次的调整值与实际坐标偏离中心的幅度成正比。 这里,我们让调整值与偏离幅度相关且比值为 6。该值仅供参考,应该根据实际情况进行调整,最终使云台能较快速地追踪目标,并且尽量减少在中心附近的晃动。为了避免云台的小幅晃动现象,我们可以划定 (320, 240) 附近的一个小范围均为“中心”,只要目标处于这一区间,云台就不响应。例如:
这里,我们让调整值与偏离幅度相关且比值为 6。该值仅供参考,应该根据实际情况进行调整,最终使云台能较快速地追踪目标,并且尽量减少在中心附近的晃动。为了避免云台的小幅晃动现象,我们可以划定 (320, 240) 附近的一个小范围均为“中心”,只要目标处于这一区间,云台就不响应。例如: 至此,我们已经将哈尔特征检测人脸坐标与舵机运动的控制关联起来了,在完整的程序中,应在图像处理的循环中加入调整舵机位置的语句。
至此,我们已经将哈尔特征检测人脸坐标与舵机运动的控制关联起来了,在完整的程序中,应在图像处理的循环中加入调整舵机位置的语句。 人脸追踪机器人是一个典型的控制系统,系统通过计算摄像头中人脸的测量位置(输入值)与中心点坐标(目标值)的误差值调整不同的 PWM 值(输出值),控制舵机运动,进而使得图像中的人脸向目标位置趋近并反复循环这一过程。这种输入值跟随输出值变化并可以重新调整输出的控制系统被称为闭环控制系统。优秀的闭环控制系统是自动控制的关键。
人脸追踪机器人是一个典型的控制系统,系统通过计算摄像头中人脸的测量位置(输入值)与中心点坐标(目标值)的误差值调整不同的 PWM 值(输出值),控制舵机运动,进而使得图像中的人脸向目标位置趋近并反复循环这一过程。这种输入值跟随输出值变化并可以重新调整输出的控制系统被称为闭环控制系统。优秀的闭环控制系统是自动控制的关键。

2. 什么是机器学习
计算机如何识别一只猫
首先我们要知道,对人工智能系统而言,其核心的工作过程可以被简化为给定一个输入,经过人工智能的判断,得到一个输出。例如,常见的指纹解锁中,我们将输入的指纹信息交给人工智能系统,人工智能系统经过比对判断给出一个通过或不通过的输出结果。那么人工智能是依据什么进行判断的呢?在简单的情形下,我们可以通过程序给定一套规则(算法),人工智能系统只需要依据这个规则进行判定就行了。例如在避障小车中,我们设定当探测到障碍物距离小于特定值时转向 90°,否则保持直行。这就是一个极其简单的人工智能判定规则。由于计算机具有高速运算能力,人工智能可以快速完成很多对于人类来说很麻烦的事情。但是人类可以轻而易举完成的一些事情,对于计算机来说却有着巨大的障碍,例如从一张图片中识别一只猫 那么机器该怎么分辨一只图片中的猫呢?在现在的人工智能系统中,人们常常会通过一定的方式令机器来“学习”从而自行获得一套进行判断的规则。这种方法被称为“机器学习”,是人工智能的一个重要分支领域。例如在识别猫的例子,人们会给计算机提供大量的图片告诉它这是猫或者不是猫,给它一个模型让它自己去学习、分析,自主形成“猫”的概念。经过一定量的训练后,再给它一张图,它就可以判断图中到底是不是猫了。
那么机器该怎么分辨一只图片中的猫呢?在现在的人工智能系统中,人们常常会通过一定的方式令机器来“学习”从而自行获得一套进行判断的规则。这种方法被称为“机器学习”,是人工智能的一个重要分支领域。例如在识别猫的例子,人们会给计算机提供大量的图片告诉它这是猫或者不是猫,给它一个模型让它自己去学习、分析,自主形成“猫”的概念。经过一定量的训练后,再给它一张图,它就可以判断图中到底是不是猫了。
机器学习的分类
在机器学习领域,有几种主要的学习方式:监督学习 (supervised learning)、无监督学习 (unsupervised learing)、半监督学习(semi-supervised learning)、强化学习(reinforcement learning) 等。监督学习是指给定有对应关系的输入、输出数据,让人工智能算法找出两组数据之间的对应关系。例如在猫狗分类问题中,我们给出多张猫、狗的图片,并完全告诉人工智能系统这些图片中是猫还是狗,再令系统学习它们的分类模式,这是一种典型的监督学习。在哈尔特征检测中,我们曾提到,可以依靠计算机训练的方式找到人脸与非人脸图像的哈尔特征差异,从而实现对人脸的检测。这种训练便是机器学习中的监督学习,它需要我们提供大量事先标注好的人脸或非人脸的照片。无监督学习 是指只提供输入数据而没有对应的输出数据,让人工智能系统自行寻找数据的关系。例如我们只给出猫、狗的图片却不告诉系统它们的分类,便是无监督学习。通常来说,无监督学习的难度远高于监督学习,但监督学习却需要付出更多的成本(需要人工标注大量的数据)。在实际的人工智能项目中,可以根据实际情况选择采用两种方法中的一个或是混合使用,而这种混合使用又称为“半监督学习”。例如我们既提供已知分类的猫、狗图片,又提供没有分类的图片,便是半监督学习。但是在某些情况下,人们以人工智能为核心系统操控机器人解决实际的复杂问题时,往往只知道需要完成的目标,并不能直接提供输入 / 输出值。此时,我们可以令机器人随机地自行控制动作得到相对应的目标反馈结果。人工智能系统将判断其控制的动作与反馈结果间的关联,进而做出合理的调整,最终不断优化其动作,得到更好的结果。例如训练让机器人投篮入筐或是射门入网,先让它随机做动作,然后根据一定的反馈得知投篮是否进筐或射门是否入网,然后不断调整、优化动作,最终达到百发百中。这种机器自主学习的方式被称为“强化学习”,它可以在自主行动的基础上,根据正负反馈的情况不断强化自身
3.认识人工神经网络
借助机器学习的方法,我们可以经过训练得到人脸的哈尔特征。这些特征虽然足以区分
人脸与非人脸,却难以区分不同人的人脸——它们的相似性远高于人脸和其他图像的相似性。
要识别特定的人脸,使用预先设定的数学方法配合机器学习已经难以完成。为解决这一问题,
一个典型的方法是使用人工神经网络工具
人工智能机器学习机制的本质是根据多组已知的输入值(例如不同人脸的照片)和输
出值(例如它们对应的人的名字)来自行找出它们之间的对应关系,从而通过其他输入值
预测出新的对应输出值。多数情况下,影响输出值的输入值都有多个,只要我们找到所有
的输入值以及它们各自的权重系数,理论上我们就可以预测任意一次输入情况下对应的输
出值。例如:
输出值 = 权重 1 × 输入值 1+ 权重 2 × 输入值 2+……+ 权重n × 输入值n
这里,每一个输入值都按照一定的比值影响输出值,它们的影响程度表现为各自对应的
权重。采用这种方式归纳的输入 / 输出关系被称为多元线性回归。之所以称
为线性,是因为在这里输入值都被直接乘以一个常数而没有采用平方、立方或是正弦、对数
等数学变换 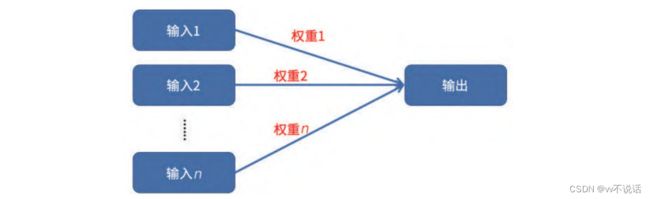
多元线性回归的数学计算比较简单,但它往往不能用于描述绝大多数真实的问题。基于
多元线性回归,计算机科学家们在 20 世纪中叶基于生物神经细胞提出了一种名为感知器的
模型,它是人工神经网络的雏形。
在介绍人工神经网络之前,我们先来简单了解一下人类的神经元(神经细胞)的结构。
神经元可以简单分为细胞体、树突、轴突几部分。经过细胞体处理的神经信号经由轴突传递
到突触结构,再通过大量的突触传递给其他神经细胞的树突

神经信号在传递过程中被突触以不同强度处理后传递给树突,大量树突接收的信号结合
起来就构成了细胞体接收到的神经信号。细胞体最终决定以怎样的强度输出该信号。
而模拟生物神经细胞结构的感知器的结构如图 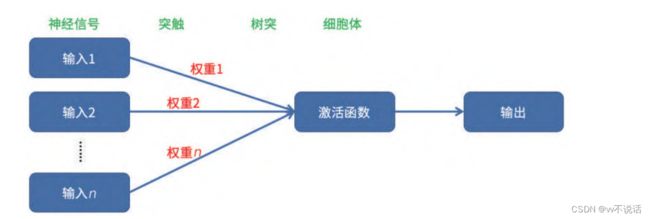
输入值相当于神经信号,这些神经信号经过突触依照不同的权重处理后被这个神经元的
树突接收。大量树突接收到的信号被细胞体获得后,它将根据一个“激活函数”来决定最终
输出的强度。激活函数通常是一个非线性的函数,它将可以使得我们用多元线性回归得到的
取值非线性化。因此,感知器模型可以处理一些简单的非线性问题,比普通的多元线性回归
适用性更广。
但单一的感知器仍不能处理许多复杂的问题,计算机科学家们于是将多个感知器(神经
元)结合到一起,构成一个简单的人工神经网络,在计算机科学领域也可简称为神经网络。
在最简单的人工神经网络系统中,每个神经元在接收信号后,根据不同的权重生成一系
列“输出值”,这些值又作为输入值生成最终的输出值。这些处于原始输入值和最终输出值
之间的值通常也被称为中间值。
我们常用“层”的概念来描述人工神经网络中的数据,原始输入数据构成输入层,最终
的输出数据构成输出层,而中间所有起到中介作用的数据构成隐藏层,它们
一般是由计算机通过机器学习机制自主训练得到的,我们可以将其视为一个隐藏起来的“黑
箱”。 
从输入层到隐藏层的每一个中间值节点或是从隐藏层到输出层的转换事实上都构成了一
个感知器(神经元),这便是人工神经网络名称的由来。由于每一个感知器中均包含了一个
非线性的激活函数,最终的输出值受到了多个激活函数的影响,这使得人工神经网络模型从
理论上来说可以完成任何情形下的现实模拟。
需要注意的是,基本的人工神经网络虽然在结构上非常类似于生物神经网络,但其中信
号传递的过程事实上与生物神经网络差异巨大。因此,人工神经网络并不是生物神经网络在
计算机中的再现,二者只存在结构上的相似性。
如果一个系统中包含多个层次的中间值,每层中间值之间都由不同权重序列和激活函数
串联,就构成了一个深度神经网络 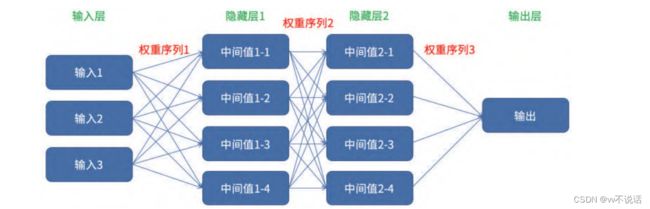
深度神经网络在解决部分复杂问题时被证明很有效果。包括人脸识别在内的大量图像识
别技术、语音识别技术、机器翻译及大家熟知的 AlphaGo 都是应用深度神经网络进行训练
的典范。运用深度神经网络进行机器学习也被称为深度学习。
回到识别人脸的问题上,若将大量不同人脸的图像信息视为输入值,将区分不同人脸的
结果作为输出值,只要可供学习的图像足够多,人工神经网络就可以准确地区分不同人脸。
为了实际使用方便,我们可以从人工神经网络的训练过程中得到它用于区分不同人脸的特征
信息以及它们的计算方法,再在实时检测中直接计算出图像的特征信息进行比较即可 
需要注意的是,人工智能得到的特征信息并不是我们用来区分人脸的眼睛大小、鼻子高
低等特征,而往往是一些数学信息。利用人工神经网络工具识别人脸并不需要知道这些计算
出来的特征信息所代表的现实意义。
人工神经网络,尤其是深度神经网络存在着一个巨大的缺点:运算量极大,因此运算极
慢。这也是这项提出超过大半个世纪的技术直到近年来随着计算机运算能力的不断提升才逐
渐发展起来的根本原因。
为了减少运算量、提升运行的效率,人们发展出了一些有效的辅助方法。诸如卷积神经
网络、递归神经网络等方法被证明在图像识别领域、机器翻译领域等方面有着出色表现。
此外,人工神经网络还有另一个缺点——效果极大程度上依赖于输入数据的数量和质量,
也导致了没有巨量数据的个人很难得到有效的结果。但从另一个角度来说,恰恰因为这个原
因,人工神经网络近年来的快速发展推动了大数据概念的火爆,数据量成为了科技巨头公司
争抢的关键
4.识别特定的人脸
人脸识别的问题也是人工智能领域的热门问题,Python 第三方包 FaceRecognition 便利用了开源的训练成果,可以直接将人脸图像转换为 128 个特征信息并用于区分不同人脸。在编写程序之前,首先需要导入一张包含已知人物面部的图片以供检测对比,导入的图片最好只包含一张人脸。如果没有照片,可以先用 OpenCV 拍一张自己的正脸照片。
imwrite 函数可以将图像保存到指定地址,参数分别为存储地址和图像信息。存储地址应包含文件的名称和格式,通常选择 jpg 或 png 格式即可。上面的程序可以实现按下键盘s 键则将当前摄像头帧存储到指定地址。接下来,我们先提取这张图片的人脸特征。使用下面的语句可以非常轻松地对一张图像的信息进行面部检索与编码
OpenCV 中内置的 imread 函数可以读取出一张图片中的图像信息,其参数为图片的存储位置。 face_recognition 包中的 face_encodings 函数可以对图像信息中的人脸进行检索并 转化为前面提到的 128 个特征信息数据,这个转化过程可以被称为编码。face_encodings 函数接受的图像信息需要按照 RGB 的顺序排列,这与 OpenCV 默认的 BGR 顺序不同,因此可以先用 cvtColor 函数进行转换(参数设定为 cv2.COLOR_BGR2RBG)。face_encodings 函数的返回值是一个列表,其包括从图像上找到的所有人脸对应的特征信息序列。在载入已知人脸图像的特征信息后,我们就可以将实时摄像头中捕获到的人脸信息与之对比。在实时检测中,如果对每一帧都使用 face_encodings 函数进行编码,这个进程将非常缓慢,完全失去实时性。为了提高检测速度,我们仍可以先用 HAAR 特征检测找到人脸的位置,再直接对这个区域进行编码 这里,为方便起见,我们假定需要比对的人脸只有一个,因此 detectMultiScale 函数使用了 cv2.CASCADE_FIND_BIGGEST_OBJECT(寻找最大目标)参数,并返回其位置信息,依序由左上角 x 坐标、左上角 y 坐标、宽度、高度构成。face_encodings 函数可以接受第二个参数:人脸的位置。设定这个参数后,face_encodings 函数将不再检测人脸位置而是直接计算出这个位置人脸的特征信息。需要注意的是,face_encodings 函数接受的位置信息需要按照左上角 y 坐标、右下角 x 坐标、右下角 y 坐标、左上角 x 坐标的顺序排列。这些信息可以是一组或多组(即可以指定多个人脸的位置信息)。因此我们需要先把 HAAR 特征人脸检测得到的人脸位置信息转换成 face_encodings 函数能接受的位置信息
这里,为方便起见,我们假定需要比对的人脸只有一个,因此 detectMultiScale 函数使用了 cv2.CASCADE_FIND_BIGGEST_OBJECT(寻找最大目标)参数,并返回其位置信息,依序由左上角 x 坐标、左上角 y 坐标、宽度、高度构成。face_encodings 函数可以接受第二个参数:人脸的位置。设定这个参数后,face_encodings 函数将不再检测人脸位置而是直接计算出这个位置人脸的特征信息。需要注意的是,face_encodings 函数接受的位置信息需要按照左上角 y 坐标、右下角 x 坐标、右下角 y 坐标、左上角 x 坐标的顺序排列。这些信息可以是一组或多组(即可以指定多个人脸的位置信息)。因此我们需要先把 HAAR 特征人脸检测得到的人脸位置信息转换成 face_encodings 函数能接受的位置信息 注意,这里传入 face_encodings 函数的位置序列处于一个长度为 1 的列表 face_locations 中,我们对它使用 append 函数将需要的位置序列加入其中。此外,传入的位置信息必须为整数型,需先用 int 函数强制转换。现在,我们已经完成了人工智能识别人脸的第三个步骤:特征提取,接下来只需要将特征与已知信息比较,完成特征的匹配与识别即可
注意,这里传入 face_encodings 函数的位置序列处于一个长度为 1 的列表 face_locations 中,我们对它使用 append 函数将需要的位置序列加入其中。此外,传入的位置信息必须为整数型,需先用 int 函数强制转换。现在,我们已经完成了人工智能识别人脸的第三个步骤:特征提取,接下来只需要将特征与已知信息比较,完成特征的匹配与识别即可 face_recognition 包中预置了一个 compare_faces 函数,可以非常方便地进行比较判断,例如:
face_recognition 包中预置了一个 compare_faces 函数,可以非常方便地进行比较判断,例如: 函数可接收 3 个参数:预置的已知人脸特征信息(可以是一组或多组信息)、待比较的人脸特征信息(只能是一组)、容忍率。已知人脸信息就是我们此前保存的照片编码后得到的信息,待比较的人脸信息则是摄像头实时检测并编码的人脸信息。不过,在我们前面的程序中,face_encodings 函数的返回值是一个长度为 1 的列表,将它传入 compare_faces 函数之前还需要用 for 循环取出其中的元素。容忍率则表示判断的标准,值越大,判断越宽松,但也越可能错判;值越小,判断越严苛,但也越可能漏判。0.5 是针对东亚人脸的参考值,但也可根据实际情况调整。函数的返回值是一个列表,它依序将待比较人脸与所有设定的已知人脸相比较并得到True 或 False 的结果,表示判断是或不是同一个人。本例中,由于已知人脸只有一张,该返回值的长度为 1,若要判断是否是同一人,只需要判断返回之中是否存在 True 即可。在Python 中,“某值 in 某列表或元组”将返回这个列表或元组中是否包含某值的逻辑判断结果。
函数可接收 3 个参数:预置的已知人脸特征信息(可以是一组或多组信息)、待比较的人脸特征信息(只能是一组)、容忍率。已知人脸信息就是我们此前保存的照片编码后得到的信息,待比较的人脸信息则是摄像头实时检测并编码的人脸信息。不过,在我们前面的程序中,face_encodings 函数的返回值是一个长度为 1 的列表,将它传入 compare_faces 函数之前还需要用 for 循环取出其中的元素。容忍率则表示判断的标准,值越大,判断越宽松,但也越可能错判;值越小,判断越严苛,但也越可能漏判。0.5 是针对东亚人脸的参考值,但也可根据实际情况调整。函数的返回值是一个列表,它依序将待比较人脸与所有设定的已知人脸相比较并得到True 或 False 的结果,表示判断是或不是同一个人。本例中,由于已知人脸只有一张,该返回值的长度为 1,若要判断是否是同一人,只需要判断返回之中是否存在 True 即可。在Python 中,“某值 in 某列表或元组”将返回这个列表或元组中是否包含某值的逻辑判断结果。 这里,我们对实时图像中的人脸与已知人脸进行比较,如果成功,则用 face_locations[0] 直接取出该人脸的坐标并绘制矩形框。识别特定人脸的完整的程序如下。
这里,我们对实时图像中的人脸与已知人脸进行比较,如果成功,则用 face_locations[0] 直接取出该人脸的坐标并绘制矩形框。识别特定人脸的完整的程序如下。import cv2 import face_recognition # 载入包含你面部的图片并对它编码 my_image = cv2.imread("/home/pi/photos/1.jpg") my_image = cv2.cvtColor(my_image, cv2.COLOR_BGR2RGB) my_face_encoding = face_recognition.face_encodings(my_image) # 载入人脸分类器 face_cascade = cv2.CascadeClassifier('/home/pi/cascade/haarcascade_ frontalface_default.xml') cap = cv2.VideoCapture(0) # 开始读取摄像头信号 while cap.isOpened(): (ret, frame) = cap.read() # 读取每一帧视频图像为 frame frame = cv2.flip(frame, 0) # 将图像上下镜像翻转 gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 将图像转换为灰度图 faces = face_cascade.detectMultiScale(gray, minSize=(100, 100), flags=cv2.CASCADE_FIND_BIGGEST_OBJECT) # 检测人脸的位置 face_locations = [] # 定义一个列表存储人脸的位置信息 for (left, top, width, height) in faces: # 遍历找到的人脸的位置信息 # 计算出右下角的坐标 right = left + width bottom = top + height # 为 face_locations 添加一个人脸的位置信息,注意需要强制转换为 int 类型 face_locations.append((int(top), int(right), int(bottom), int(left))) rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # 得到每一帧的 RGB 图像信息 face_encodings = face_recognition.face_encodings(rgb_frame, face_ locations) # 计算特定位置的人脸特征信息 for face_encoding in face_encodings: # 遍历得到的所有人脸特征信息 matches = face_recognition.compare_faces(my_face_encoding, face_encoding, tolerance=0.5) # 将它与已知的人脸进行比较 if True in matches: # 如果检测成功 (top, right, bottom, left) = face_locations[0] # 获得该人脸的 位置信息 cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2) # 绘制矩形框 cv2.imshow("Recognition", frame) # 预览图像 cv2.waitKey(5) # 每帧等待 5 毫秒 cap.release() cv2.destroyAllWindows()

